

讲解视频:可以在bilibili搜索“MATLAB教程新手入门篇——数学建模清风主讲”。


首先,我们介绍 fileread 函数 的使用方法,它的用法非常简单:
text = fileread(filename) 以字符向量形式返回文件 filename 的内容。
filename参数是要读取的文本文件的名称(注意:低版本MATLAB中请使用字符向量指定文件名,使用字符串类型会报错)。根据文件所在的位置,我们通常会遇到以下两种情况:
(1 )文件存在于当前文件夹或搜索路径上的某个文件夹中(忘记搜索路径的同学可以看第二章复习),此时,filename 就可以直接设置为文件的名称(需要带上文件的后缀)。
请大家先将MATLAB的当前文件夹切换到本章配套的代码文件夹中(配套代码请看本书第一页下载),里面包含了一个名为“测试的文本”的txt文件,大家可以使用Windows系统自带的记事本打开这个文件,它包含三行文本内容。
请特别注意记事本界面的右下角,这里显示了文件的编码格式(右下角显示UTF-8,在上一章的第一节中我们介绍过,UTF-8意味着该文件的编码是Unicode编码)。
了解文件的编码非常重要,如果在MATLAB 中使用了与文件实际编码不匹配的编码格式,就可能出现乱码的问题。这是处理文本数据时需要特别留意的细节。


fileread函数返回的变量c就是txt文件中对应的文本内容,它是字符向量类型。注意, 大家使用同样的代码可能得到乱码的内容,我们将在后续的内容中介绍如何解决这一问题。
(2 )直接将 filename 指定为绝对路径或者相对路径。
绝对路径 是指文件在硬盘上的具体位置,它从盘符(如C盘、D盘)开始,一直到文件名,形成一条完整的路径。例如,在我的电脑上,“测试的文本.txt”的绝对路径是:
F:\BaiduSyncdisk\matlab课程\分章word\第6章配套代码\测试的文本.txt

因此,我们也可以使用以下代码读取这个文本文件:

相对路径 用于表示文件相对于当前工作目录(即MATLAB中的“当前文件夹”)的位置。它不从盘符开始,而是以当前工作目录或其上层目录作为参照。在使用相对路径时,我们经常用到两个特殊的符号:
-
.表示当前文件夹。
-
..表示当前文件夹的父文件夹(即上一级文件夹)。
让我们通过两个实例来深入理解相对路径的使用:
例1:假设MATLAB的当前文件夹是“F:\BaiduSyncdisk\matlab课程\分章word\第6章配套代码”。如果我们想将当前文件夹切换到其父文件夹“F:\BaiduSyncdisk\matlab课程\分章word”,我们可以使用以下命令:

如果你再次调用上面的命令,MATLAB的当前文件夹会被切换到更上一级的文件夹,即“F:\BaiduSyncdisk\matlab课程”。
例2:请大家先将MATLAB的当前文件夹重新修改成本章代码所在的文件夹,在我的电脑上是“F:\BaiduSyncdisk\matlab课程\分章word\第6章配套代码”。在当前文件夹中,存在一个名为“西游记数据”的文件夹,该文件夹下存在一个名为“《西游记》章回内容梗概”的txt文件。
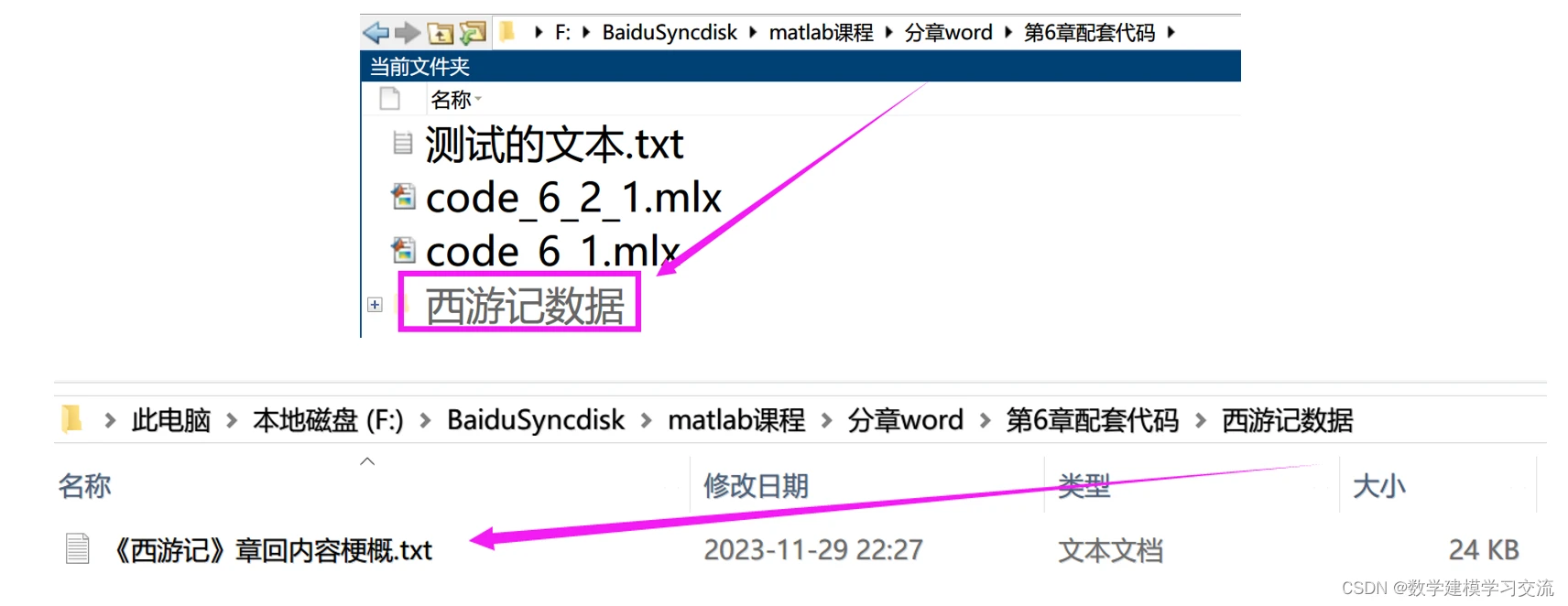
我们可以通过以下两种方法读取该txt文件中的文本:

通过这些实例,我们深入理解了如何在MATLAB中有效地使用绝对路径和相对路径来读取文本文件。
现在,让我们转向一个常见但棘手的问题:文件读取过程中可能出现的字符乱码问题。
这种情况通常发生在MATLAB使用了与文本文件实际编码不匹配的字符编码来读取文件时。字符乱码问题尤其常见于包含中文等非ASCII字符的文本文件。解决这一问题的关键在于正确地识别和指定文件的编码格式。
我们先快速回顾一下字符编码的基础知识。最初的字符编码是ASCII编码,它只包括128个字符,主要用于表示英文字符。然而,ASCII编码无法满足其他语言,因此不同国家和地区开发了自己的字符编码标准。例如,我国最初推出了GB2312编码,主要用于表示常用的中文字符。随后,为了包含更多的字符,又相继推出了GBK编码和GB18030编码。这些编码能够表示更多的字符,并且向下兼容GB2312编码。为了统一不同语言的字符表示,Unicode编码应运而生。Unicode提供了一个统一的编码方案,可以表示全世界所有语言的字符。Unicode编码最常见的实现形式有UTF-8、UTF-16和UTF-32,而UTF-8又是最常用的Unicode编码,它的存储效率较高。
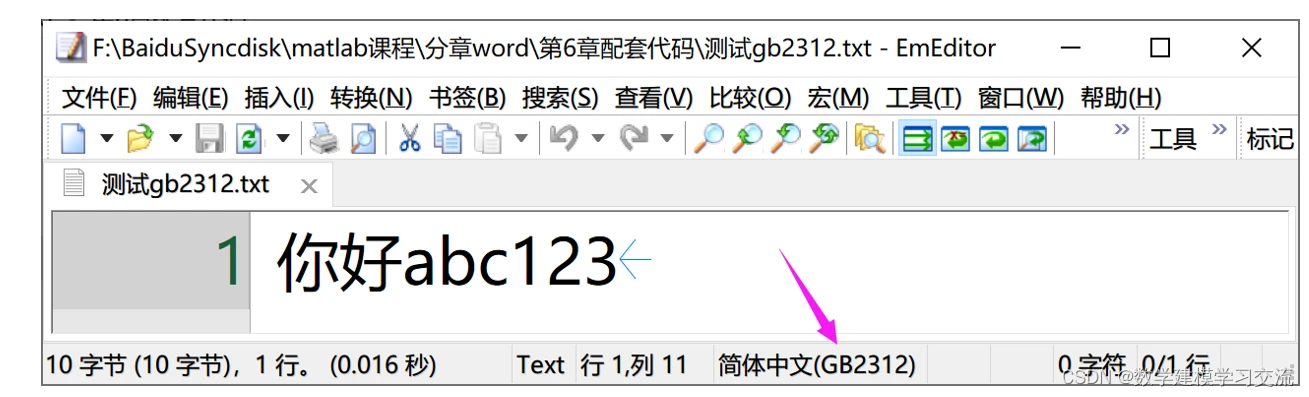
在本章配套的代码文件中,我准备了两个txt文件,它们的内容完全相同,都只有一句话:“你好abc123”,但它们的字符编码分别是GB2312和UTF-8。

在记事本中,“测试gb2312.txt”显示的编码是ANSI。注意,ANSI编码并不是指一个具体的编码标准,而是根据不同地区可能代表不同的编码。在中文Windows系统中,“ANSI编码”通常指的是GB2312编码或GBK编码。如果你要查看准确的编码,可以使用第三方的文本编辑软件,例如EmEditor软件上显示的文件编码为GB2312.
下面请大家打开MATLAB,运行下面这行命令:

该命令会显示MATLAB在读取文本文件时使用的默认字符编码。值得注意的是,这一默认编码可能因电脑系统、MATLAB版本等因素而有所不同。例如,在我同一台电脑的测试中,MATLAB2017a版本返回的是'GBK',而在MATLAB2023a版本中,返回的是'UTF-8'。
接下来,请大家尝试运行以下两段代码来导入这两个不同编码的txt文件。在此之前,请确保这两个文件位于MATLAB的当前文件夹下。 (注意:下面的结果来自我的电脑上运行的 MATLAB 2017a 版本,你的电脑上运行这些代码可能会得到不同的结果。)

(注意:在较高版本的MATLAB中, c1和c2都不会乱码,后面会介绍原因)
在这个例子中,我们可以清楚地看到,当导入UTF-8编码的文件时,c1中的中文内容出现了乱码,'你好'被错误地显示为了'浣犲ソ'。这是因为在我电脑的MATLAB 2017a版本中,默认的字符编码是'GBK',与文件的实际编码不匹配。 在这种情况下,我们可以使用下面的代码来临时指定 MATLAB 使用的默认字符编码:

请注意,使用feature('DefaultCharacterSet', 'utf-8')来更改默认字符编码是临时的。这意味着它只对当前MATLAB会话有效,一旦关闭并重新打开MATLAB,这一设置将会丢失。此外,更改默认编码可能会影响MATLAB会话中其他文件的读取。例如,在设置了默认编码为'UTF-8'之后,如果尝试重新导入使用'GB2312'编码的文本文件,就可能会遇到乱码问题:

为了避免这样的乱码问题,正确的做法是在每次导入不同编码的文本文件之前,都适当地重新设置MATLAB的默认编码。这样即便是在同一个MATLAB会话中处理不同编码的文本文件,我们也能保证文本内容被正确读取和显示,避免了乱码问题。

此外,一些使用较新版本MATLAB的同学可能已经注意到:即使不手动设置默认编码,也能正确无误地读取文本文件,而且没有出现乱码问题。这是因为 MATLAB 自2020b 版本开始,对字符编码的处理机制得到了重大提升,MATLAB 引入了自动字符集检测功能,当打开文件进行读取时,它能自动识别文件的编码类型。 这一改进极大地提高了文件读取的准确性和稳定性,显著降低了因编码不匹配而导致的乱码风险。
尽管从MATLAB 2020b版本开始,自动字符集检测功能大大提高了读取文件时编码的准确性,但并非所有情况下自动检测都能百分百准确。此外,鉴于用户的MATLAB版本可能有所不同,明确指定文件编码仍是确保代码兼容性和稳定性的可靠做法。因此,在处理文本文件时,建议明确指定文件的编码,确保代码在不同环境中的稳定运行和准确读取。
拓展:fileread 函数的新用法
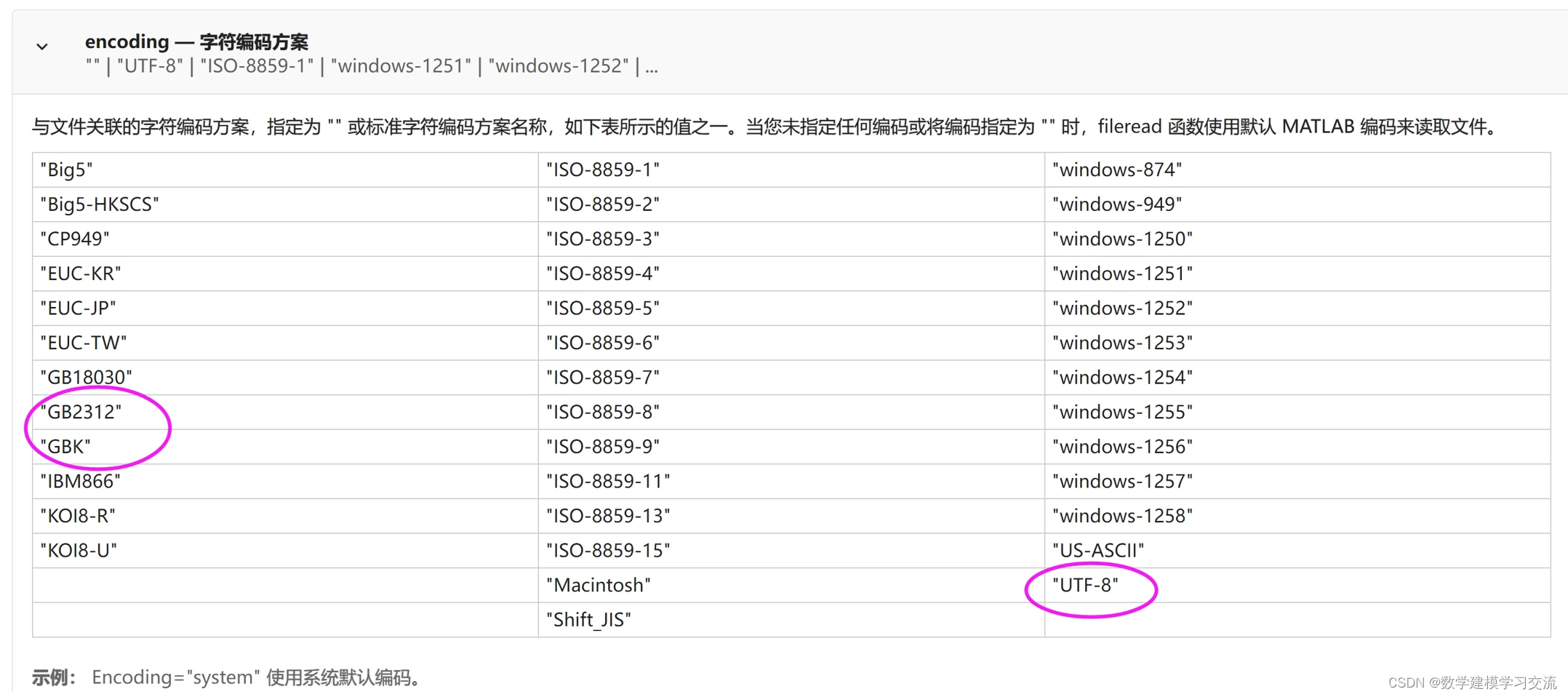
自MATLAB 2022b版本起,fileread函数增加了一项新功能(下图截取自官网):

这里的encoding可以指定为以下值,下图圈住的三个编码最常用:
这一新特性提升了fileread函数读取文本文件时的灵活性,用户可以根据实际需要明确指定文件编码,进一步避免了由于编码不匹配而引发的乱码问题。
值得注意的是,在上一章中我们讨论过名称-值参数的表示方式。官方文档中的text = fileread(filename, Encoding=encoding)是从2021a版本才开始支持的语法,为了代码的清晰性,建议大家使用更一般的text = fileread(filename, 'Encoding', encoding)的形式。

接下来,我们将深入了解fileread函数的内部工作原理。想要探究这一点,最直接的方法是查看函数的源代码。在MATLAB中,我们可以通过使用edit fileread命令来查看fileread函数的源码。下面是来自不同版本的MATLAB(2017a和2023a)的fileread函数的核心源码片段对比:

通过对比这两段源码,我们可以观察到:在新版本中,fopen函数的输入参数有所增加,而在旧版本中只有一个输入参数。
另外,正如我们从fileread函数的源码中看到的,fopen、fread以及fclose函数是文件读取过程中至关重要的函数。了解这些函数如何工作,可以帮助我们更好地理解MATLAB在数据读取操作中的内部机制,以及如何有效利用这些工具来满足我们对数据处理的需求。
接下来,我们将介绍这三个函数的用法和特点。
(1 )fopen 函数和fclose 函数
在MATLAB中,fopen函数用于打开文件进行读取或写入操作。它不仅为fileread函数提供了底层支持,而且也是许多其他内置函数的核心组成部分。下面,我们将介绍fopen函数的一些常用用法,这些用法在文件I/O操作中非常实用。
首先,我们来学习fopen函数的基本用法:
fid = fopen(filename, permission)
这里的filename是要打开或创建的文件的名称(建议使用字符向量类型,字符串类型在低版本中会报错);permission指定了文件要被如何使用,最常用的有以下三种模式:
-
'r' : 以只读的方式打开文件,这也是默认情况,即fopen(filename, 'r')可以直接简写成fopen(filename)。我们通常在只需要读取文件内容时使用该参数。
-
'w' :打开或创建要写入的新文件,如果文件中存在内容,则会先删除文件中的内容后再进行写入操作(主要用于下一小节要介绍的文本文件的导出)。
-
'a' :打开或创建要写入的新文件,如果文件中存在内容,则会在原内容的末尾继续写入新的内容。
变量fid是 fopen函数的返回值,它是一个整数标量,用于表示文件的标识符。当指定的文件无法打开时,fid的值为-1。这个特性可用作错误处理:我们可以检查fid的值是否为-1来判断操作是否成功,并根据需要来处理错误情况,例如:

如果fopen函数成功的打开了指定的文件,返回值文件标识符fid就是一个大于等于3的整数,它是MATLAB此次会话中匹配该打开文件的标识。(拓展:为什么从3开始,这是因为MATLAB保留了文件标识符0、1和2分别用于标准输入、标准输出和标准错误。)
例如,以下代码展示了如何打开一个文件并获取其fid:

在上面这个例子中,如果连续多次运行这段代码,每次都会得到不同的fid值,这些不同的fid值均能用于匹配该文件。

在上述示例中,我们学会了如何打开文件并获取其文件标识符fid。但重要的是,每个打开的文件都应该在不被需要时被正确关闭。未及时关闭文件可能导致系统资源的浪费,并可能引发不可预测的问题,例如文件被锁定或内存泄漏等。
当然,在关闭文件之前,我们通常会利用fid值进行一系列的文件读写操作。例如,上述fileread函数的源码中就展示了这样的流程:首先使用fopen函数获得文件标识符fid,然后通过fread函数读取文件内容,最终通过fclose函数关闭文件。
一个完整且安全的文件操作流程应包含错误处理逻辑,如下所示:

此外,在进行大量文件操作时(例如我们使用了循环语句来打开多个文件时),可能会忘记关闭某些文件。MATLAB提供了 fclose('all') 或 fclose all 的命令,用于一次性关闭所有打开的文件(通常,我们会在行末尾加上分号来不显示fclose函数的输出结果)。
另外,如果要读写文本文件,fopen函数还支持指定文本的编码,使用方法如下:
fid = fopen(filename, permission, machinefmt, encodingIn)
在这里,machinefmt参数用于指定读写文件中字节或位的顺序,这里涉及到非常底层的知识,感兴趣的同学可以查阅相关资料,我们这里不进行展开讲解,大家只需要知道该参数通常指定为'n',表示数据的读写将遵循系统默认的字节排序方式;而encodingIn参数则用于指定文件的字符编码方案,完整的编码列表可参考fileread函数的介绍,最常用的编码为'GBK'和'UTF-8'。例如:

(2 )fread 函数
在MATLAB中,fread函数是一个功能强大但用法复杂的工具,它主要用于从二进制文件中读取数据。值得注意的是,在计算机内部,所有的文件类型——无论是文本或数据格式文件、图像、视频,还是其他文件——都以二进制形式存储。这使得fread函数在某种程度上能够读取几乎任意类型的文件。
在简单的文件读取操作中,我们通常不会直接使用fread函数,但了解它的存在和作用是有益的。fread函数是MATLAB中许多高级文件读取函数的实现基础,例如:
-
我们前面介绍的fileread函数,它用于读取整个文本文件的内容。
-
后续章节要介绍的dlmread函数,它用于从文本文件中读取数据并保存到数值矩阵中(注意:在MATLAB 2019a版本之后,它被功能更为强大的readmatrix函数所取代)。
-
后续章节要介绍的importdata函数,它用于读取更一般的数据文件,支持更多种类的数据格式。
由于fread函数用法的复杂性,本书不会在这里详细展开讲解。大家只需要知道fileread函数中fread函数的用法即可:

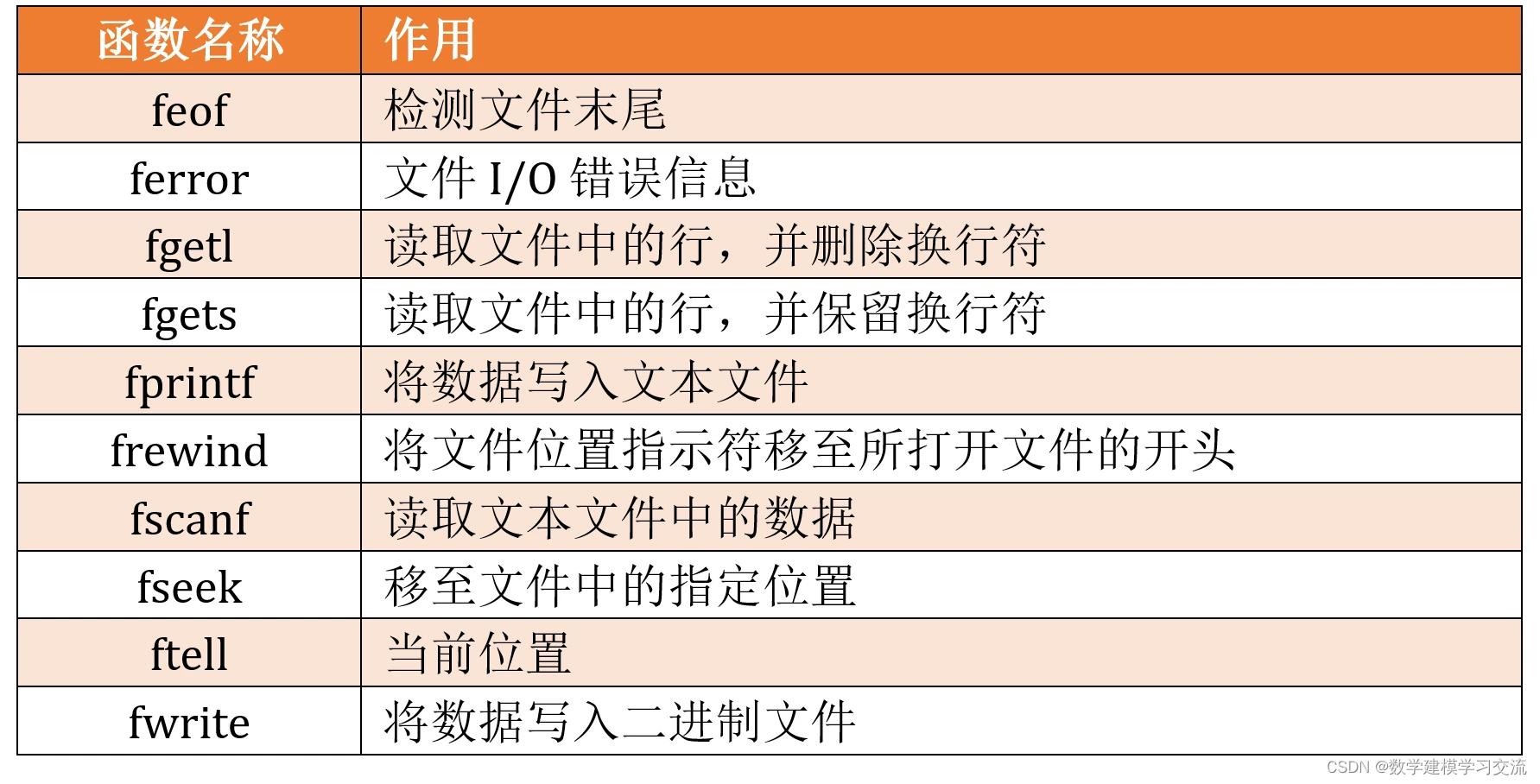
拓展: 本节我们介绍的几个函数在MATLAB官网被称为 低级文件 I/O 函数 。这些函数提供了字节或字符级别的读取和写入操作。下表给出了一些功能类似的函数,表中除了下一小节要介绍的fprintf函数之外,其余函数的使用频率相对较低,但它们在特定情况下依然非常有用。感兴趣的同学可以查阅官方文档,学习这些函数的具体用法。
练习题:三维团簇的数据读取 (本题很重要,一定要学会)
本题数据源自2021年MathorCup数学建模挑战赛B题《三维团簇的能量预测》。在材料科学和化学领域,了解和预测分子或团簇的能量对于理解其稳定性和反应活性非常重要。
在本章配套的代码文件夹中,有一个名为Au20_OPT的子文件夹,该文件夹内包含了6个后缀为.xyz的文本文件。这些文件记录了6个金团簇的结构。大家可以使用记事本、Word或其他文本编辑器打开这6个.xyz文件。以第一个文件为例,打开后可以看到该文件由多行构成,其中第一行是原子数,第二行是能量,后面行是原子的三维坐标。本题要求大家从这六个文件中提取上述信息,并存储到MATLAB的变量中。
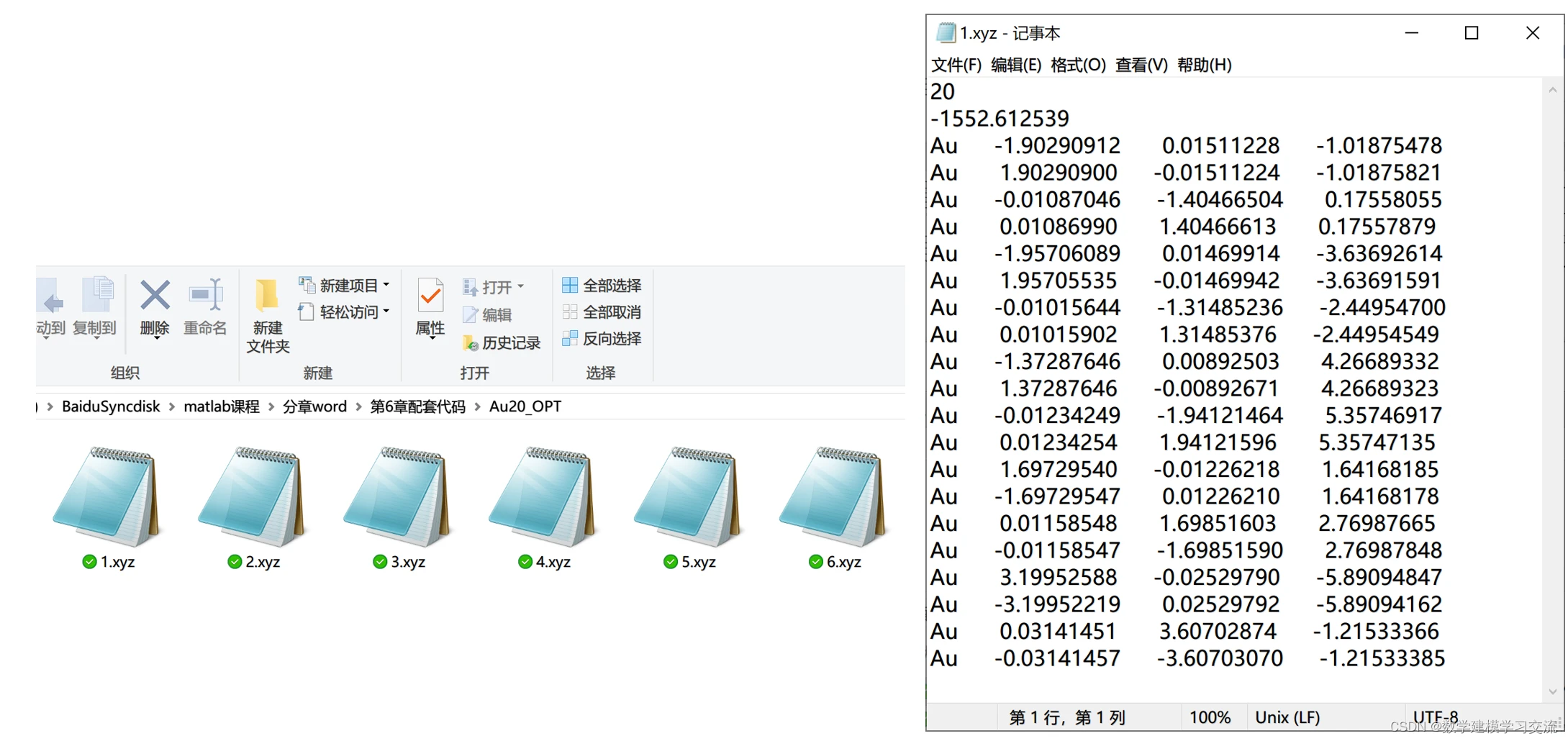

注意:在本练习中,数据文件的命名具有一定的规律性,即文件按照数字递增的方式进行命名。因此,我们可以在循环体内直接构建每个文件的文件名。然而,在实际应用中,文件的命名可能没有这样的规律性。在这种情况下,直接构建文件名可能不再适用。
为了处理这种情况,我们可以使用MATLAB的dir函数来获取文件夹下的所有文件名,该函数的具体使用方法和案例将在下一章讲解结构体数组的应用中进行介绍。

更多文章可点击下方合辑:
