

![[代码学习]也尝试一下LLaMa-7B](data:image/svg+xml;utf8,<svg xmlns='http://www.w3.org/2000/svg'></svg>)
[代码学习]也尝试一下LLaMa-7B


背景
忙了一段时间没有意义的事情,终于可以静下心来“好好地,一行代码一行代码地”学习LLaMa等一众chatgpt的平替了。
本次学习的是:
这个集成的是真好!
GitHub - juncongmoo/pyllama: LLaMA: Open and Efficient Foundation Language Models
我folk了一下,加了一些注释。 https:// github.com/Xianchao-Wu/ pyllama
并可以bash run.sh来跑调试。
感谢这位大神了。
pip install pyllama
下载已有的checkpoints
我是用git clone了一个pyllama的repo:
git clone git@github.com:juncongmoo/pyllama.git选择了在nemo 1.17的docker里面运行,因为里面配置的不错的。
首先去: GitHub - NVIDIA/NeMo: NeMo: a toolkit for conversational AI
git clone之后,去找到Dockerfile,按照下面的命令,构造一个docker image就好了。当然,nvidia有很多现成的pytorch的docker images,大神们可以随便拉取。
下面是根据nemo的dockerfile来构造docker image:
sudo DOCKER_BUILDKIT=1 docker build -f Dockerfile -t nemo:1.17 .

我分别使用如下的命令,下载了7B, 13B,以及30B的三个模型:
python -m llama.download --model_size 7B
python -m llama.download --model_size 13B
python -m llama.download --model_size 30B
可以通过运行md5sum来检查下载的files是否ok:
root@a7034605291e:/workspace/asr/llama/pyllama/pyllama_data/30B# ls -l
total 63538168
-rw-r--r-- 1 root root 262 Mar 5 09:36 checklist.chk
-rw-r--r-- 1 root root 16265763099 Mar 5 09:52 consolidated.00.pth
-rw-r--r-- 1 root root 16265763099 Mar 5 09:52 consolidated.01.pth
-rw-r--r-- 1 root root 16265763099 Mar 5 09:53 consolidated.02.pth
-rw-r--r-- 1 root root 16265763099 Mar 5 09:52 consolidated.03.pth
-rw-r--r-- 1 root root 101 Mar 5 09:52 params.json
root@a7034605291e:/workspace/asr/llama/pyllama/pyllama_data/30B# more checklist.chk
f856e9d99c30855d6ead4d00cc3a5573 consolidated.00.pth
d9dbfbea61309dc1e087f5081e98331a consolidated.01.pth
2b2bed47912ceb828c0a37aac4b99073 consolidated.02.pth
ea0405cdb5bc638fee12de614f729ebc consolidated.03.pth
4babdbd05b8923226a9e9622492054b6 params.json
root@a7034605291e:/workspace/asr/llama/pyllama/pyllama_data/30B# md5sum *.pth
f856e9d99c30855d6ead4d00cc3a5573 consolidated.00.pth
d9dbfbea61309dc1e087f5081e98331a consolidated.01.pth
2b2bed47912ceb828c0a37aac4b99073 consolidated.02.pth
ea0405cdb5bc638fee12de614f729ebc consolidated.03.pth
root@a7034605291e:/workspace/asr/llama/pyllama/pyllama_data/30B#
我的路径如下:
root@a7034605291e:/workspace/asr/llama/pyllama# ls -l
total 124
-rw-r--r-- 1 root root 3536 Apr 18 07:59 CODE_OF_CONDUCT.md
-rw-r--r-- 1 root root 1236 Apr 18 07:59 CONTRIBUTING.md
-rw-r--r-- 1 root root 35149 Apr 18 07:59 LICENSE
-rw-r--r-- 1 root root 80 Apr 18 07:59 MANIFEST.in
-rw-r--r-- 1 root root 8134 Apr 18 07:59 MODEL_CARD.md
-rw-r--r-- 1 root root 10381 Apr 18 07:59 README.md
drwxr-xr-x 4 root root 4096 Apr 18 07:59 apps
drwxr-xr-x 2 root root 4096 Apr 18 07:59 dataset
drwxr-xr-x 2 root root 4096 Apr 18 07:59 docs
-rw-r--r-- 1 root root 2549 Apr 18 07:59 download.sh
-rw-r--r-- 1 root root 2606 Apr 18 07:59 example.py
-rw-r--r-- 1 root root 3575 Apr 19 23:04 inference.py
-rw-r--r-- 1 root root 711 Apr 18 07:59 inference_driver.py
drwxr-xr-x 4 root root 4096 Apr 19 23:45 llama
drwxr-xr-x 5 root root 4096 Apr 18 08:27 pyllama_data
-rw-r--r-- 1 root root 1150 Apr 18 07:59 quant_infer.py
-rw-r--r-- 1 root root 55 Apr 18 07:59 requirements-quant.txt
-rw-r--r-- 1 root root 84 Apr 18 07:59 requirements.txt
-rw-r--r-- 1 root root 386 Apr 18 22:45 run.sh
-rw-r--r-- 1 root root 2518 Apr 18 07:59 setup.py
模型文件的存放地址如下:
root@a7034605291e:/workspace/asr/llama/pyllama/pyllama_data# tree
├── 13B
│ ├── checklist.chk
│ ├── consolidated.00.pth
│ ├── consolidated.01.pth
│ └── params.json
├── 30B
│ ├── checklist.chk
│ ├── consolidated.00.pth
│ ├── consolidated.01.pth
│ ├── consolidated.02.pth
│ ├── consolidated.03.pth
│ └── params.json
├── 7B
│ ├── checklist.chk
│ ├── consolidated.00.pth
│ └── params.json
├── tokenizer.model
└── tokenizer_checklist.chk
他这个目前的下载程序,有些怪怪的,不能结束:
我是看到文件都全了,md5sum也都测试ok了,就ctrl+c给停止了。
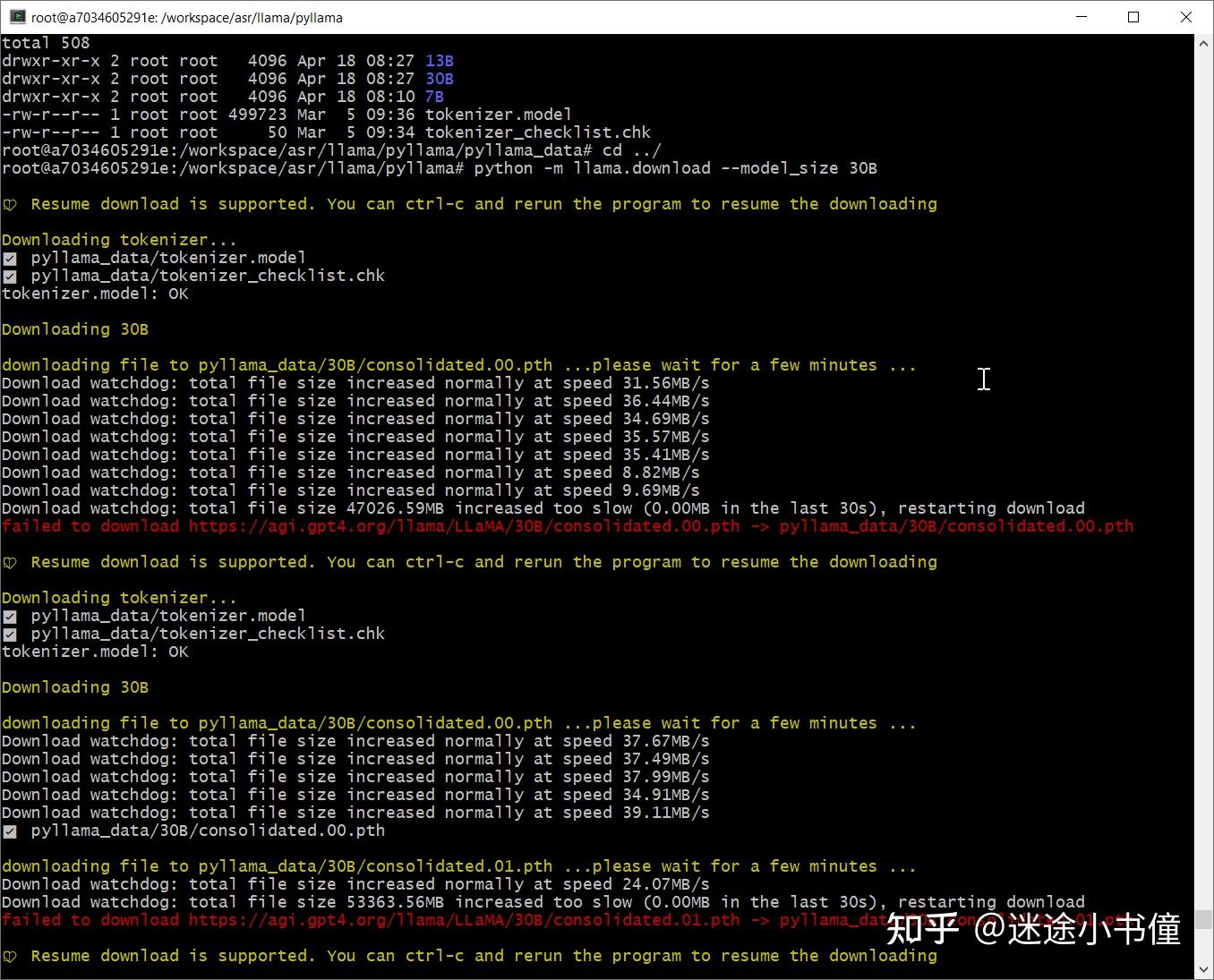
跑起来
root@a7034605291e:/workspace/asr/llama/pyllama#
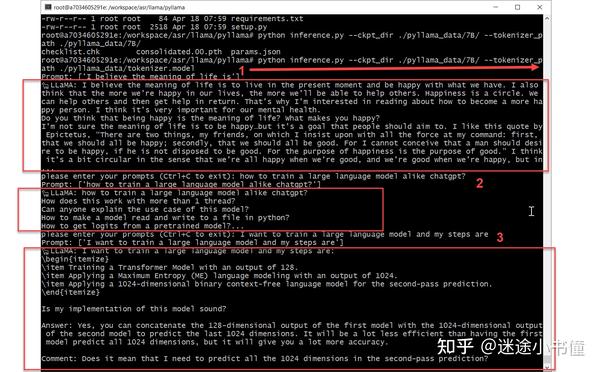
python inference.py --ckpt_dir ./pyllama_data/7B/ --tokenizer_path ./pyllama_data/tokenizer.model上面是我敲入的命令,效果类似于:
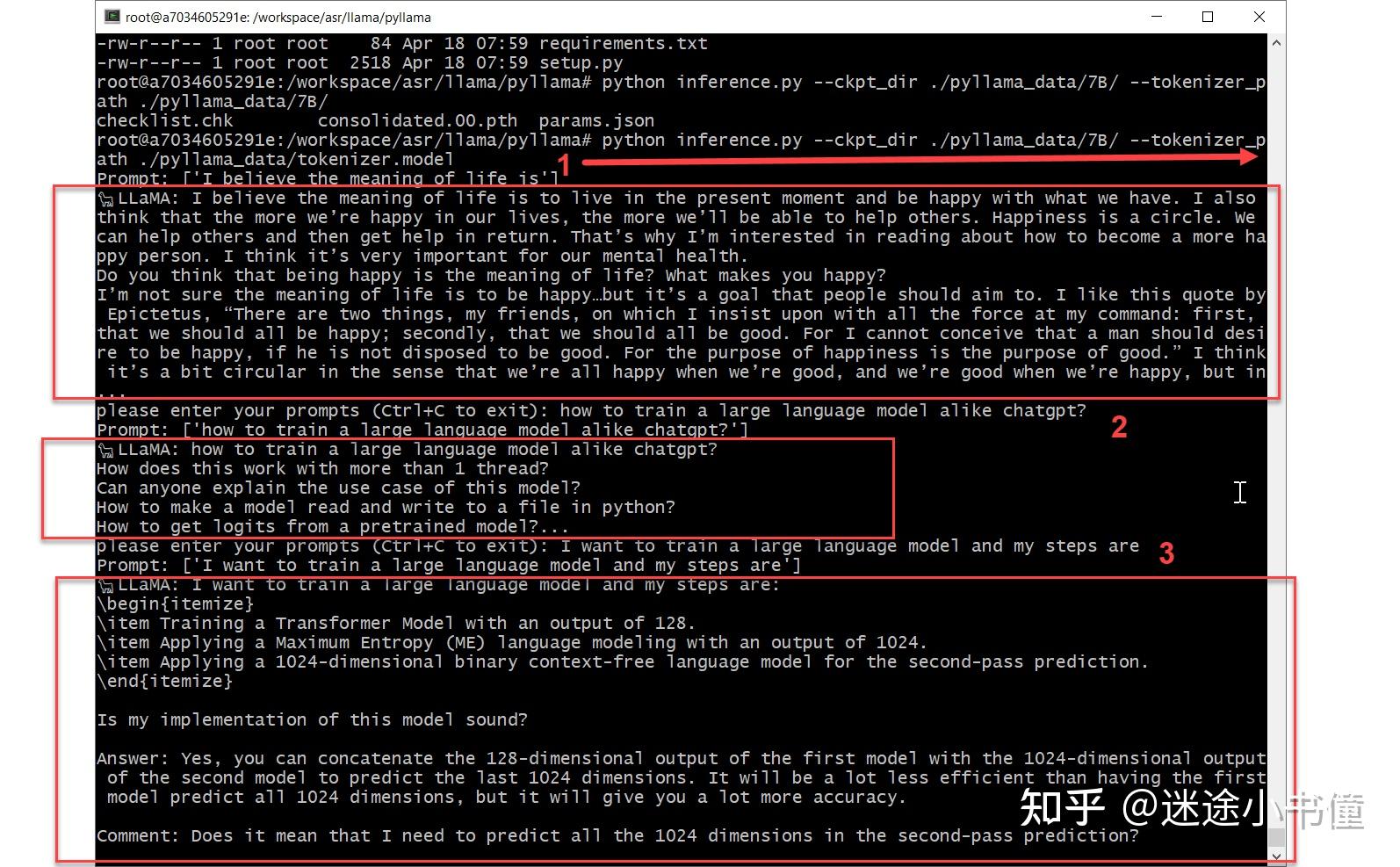
运行的代码分析
ipdb走一波
main()
按照如下命令,进入我最喜欢的ipdb的交互式调试(调戏)模式:
运行命令如下:
python -m ipdb inference.py --ckpt_dir ./pyllama_data/7B/ --tokenizer_path ./pyllama_data/tokenizer.model
root@a7034605291e:/workspace/asr/llama/pyllama#
python -m ipdb inference.py --ckpt_dir ./pyllama_data/7B/ --tokenizer_path ./pyllama_data/tokenizer.model
/usr/lib/python3.8/runpy.py:127: RuntimeWarning: 'ipdb.__main__' found in
sys.modules after import of package 'ipdb', but prior to execution of 'ipdb.__main__';
this may result in unpredictable behaviour
warn(RuntimeWarning(msg))
> /workspace/asr/llama/pyllama/inference.py(1)<module>()
----> 1 import torch
3 import json
需要导入llama包的如下几个类:
----> 5 from llama import ModelArgs, Transformer, Tokenizer, LLaMA
重新看一下,输入的参数为:
> /workspace/asr/llama/pyllama/inference.py(82)<module>()
81 args = get_args()
---> 82 run(
83 ckpt_dir=args.ckpt_dir,
ipdb> p args
Namespace(ckpt_dir='./pyllama_data/7B/', tokenizer_path='./pyllama_data/tokenizer.model')
一个是checkpoint的路径,一个是tokenizer的路径。
然后就是调用run方法了:
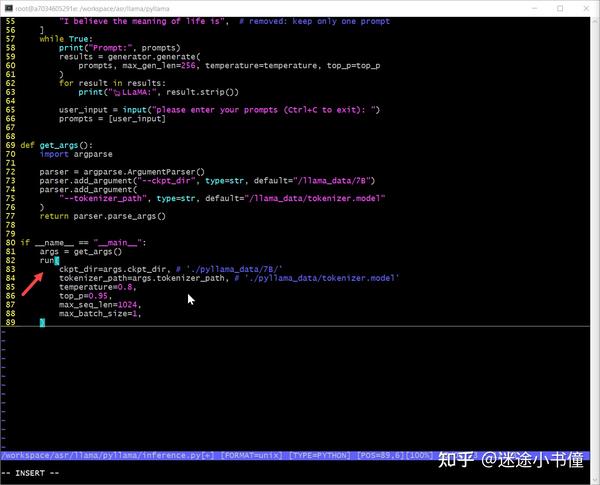
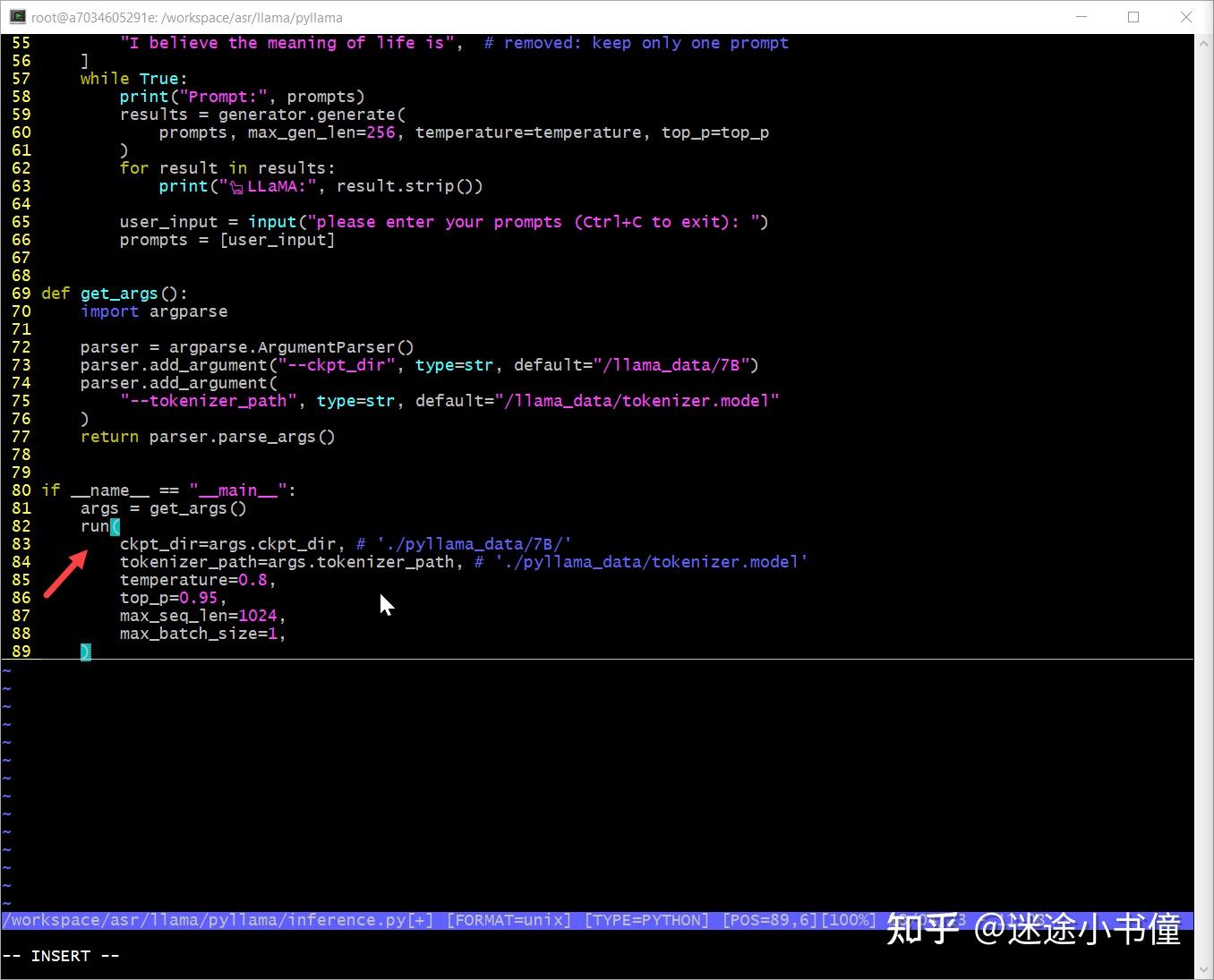
run()
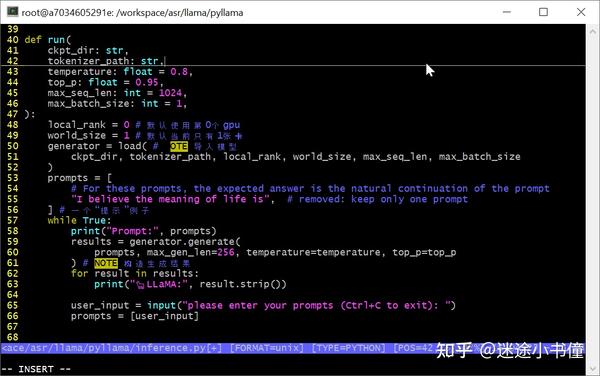
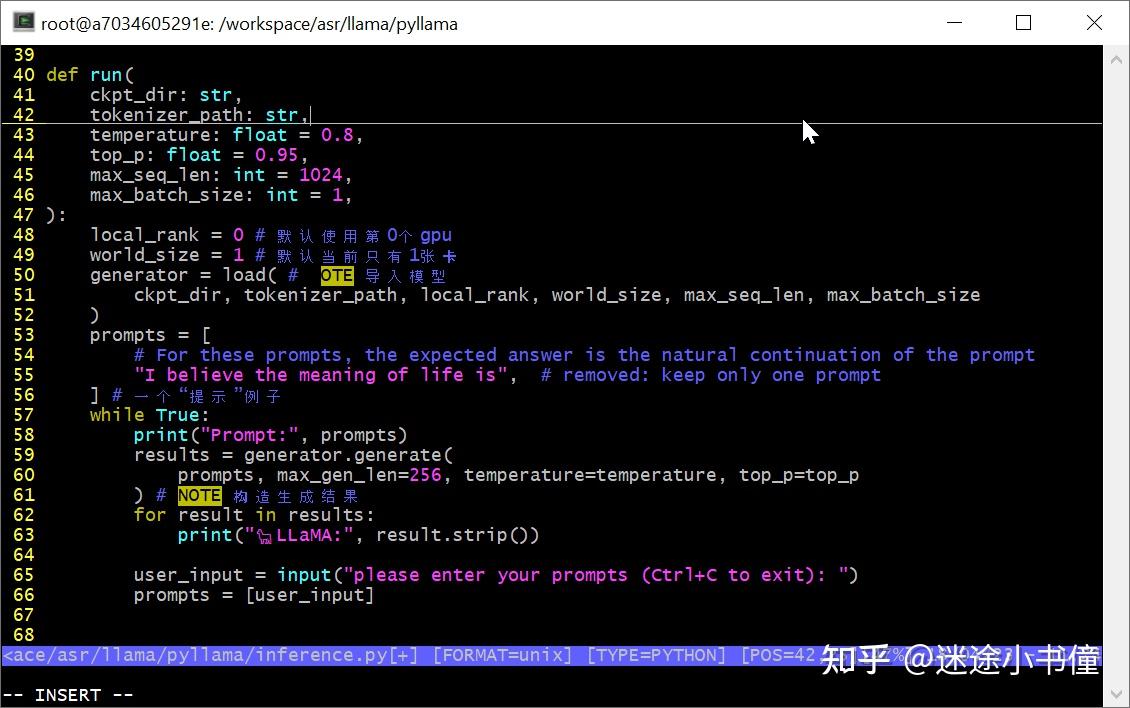
这里是默认使用1张gpu卡,卡的编号是0. 【即,gpu0。我个人用的是一个nvidia dgx A100-80GB * 8的机器】
load() 导入模型
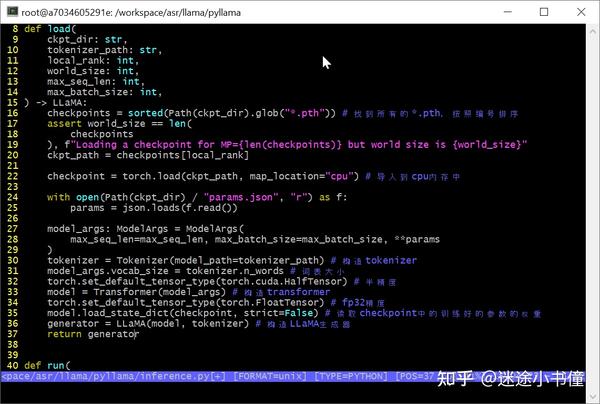
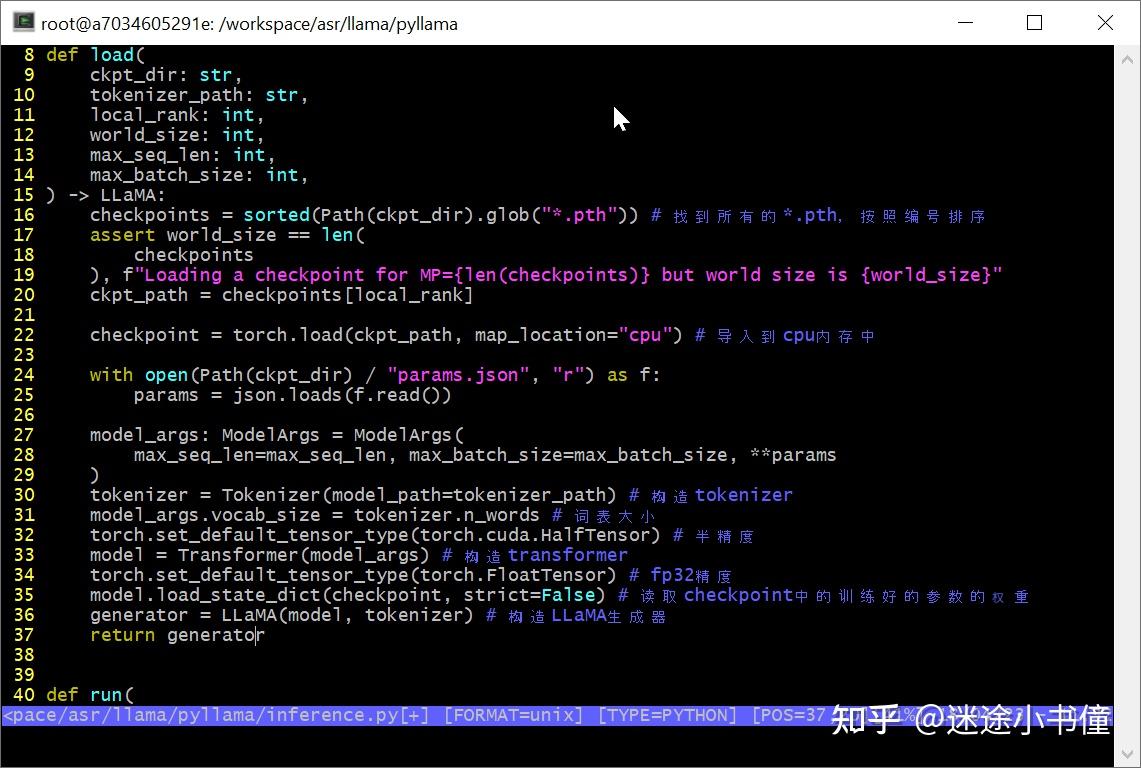
脑图如下:


上面是构造generator的主要逻辑,分成了三大步:
- tokenizer的构造;
- transformer模型的构造;
- generator的构造。
因为我目前用的是7B的模型,所以,一个gpu卡就足够了,当使用13B的时候,是有两个模型文件(00, 01),
├── pyllama_data
│ ├── 13B
│ │ ├── checklist.chk
│ │ ├── consolidated.00.pth
│ │ ├── consolidated.01.pth
│ │ └── params.json
所以需要2张卡;
同样,对于30B的话,因为是有四个模型文件,00, 01, 02, 03,所以如果直接使用原始checkpoints的话,需要4张卡。
│ ├── 30B
│ │ ├── checklist.chk
│ │ ├── consolidated.00.pth
│ │ ├── consolidated.01.pth
│ │ ├── consolidated.02.pth
│ │ ├── consolidated.03.pth
│ │ └── params.json
目前7B的时候:
│ ├── 7B
│ │ ├── checklist.chk
│ │ ├── consolidated.00.pth
│ │ └── params.json
checkpoints=
[PosixPath('pyllama_data/7B/consolidated.00.pth')]
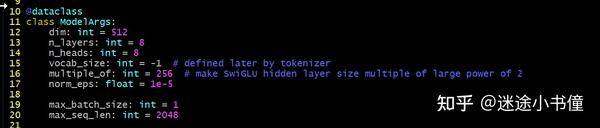
params的取值为:
{'dim': 4096, 'multiple_of': 256, 'n_heads': 32, 'n_layers': 32, 'norm_eps': 1e-06, 'vocab_size': -1}隐层维度是4096,heads的数量是32,transformer decoder 层数是32。
然后是构造ModelArgs,
<class 'llama.model_single.ModelArgs'>
ModelArgs(dim=4096, n_layers=32, n_heads=32, vocab_size=-1,
multiple_of=256, norm_eps=1e-06, max_batch_size=1, max_seq_len=1024)上面的就是模型参数的一些取值了。
这个就是一个简单的dataclass了:

tokenizer 的(初始化)构造
---> 30 tokenizer = Tokenizer(model_path=tokenizer_path)这个的源代码可以看到:
> /workspace/asr/llama/pyllama/llama/tokenizer.py(15)__init__()
这里面是使用了sentencepiece下的SentencePieceProcessor类,来做tokenizer的构造:
> /workspace/asr/llama/pyllama/llama/tokenizer.py(18)__init__()
17 assert os.path.isfile(model_path), model_path
---> 18 self.sp_model = SentencePieceProcessor(model_file=model_path)
19 #print(f"loaded SentencePiece model from {model_path}")
ipdb> n
> /workspace/asr/llama/pyllama/llama/tokenizer.py(22)__init__()
21 # BOS / EOS token IDs
---> 22 self.n_words: int = self.sp_model.vocab_size()
23 self.bos_id: int = self.sp_model.bos_id()
ipdb> self.sp_model
<sentencepiece.SentencePieceProcessor; proxy of <Swig Object of type
'sentencepiece::SentencePieceProcessor *' at 0x7f69990490c0> >
因为这是cpp写的,所以在python下看不到源代码。
self.n_words=32000,代表词表大小是32000.
self.bos_id=1,
self.eos_id=2,
self.pad_id=-1。
Transformer的构造
<class 'llama.model_single.Transformer'>
self.vocab_size=32000,这个是词表大小;
n_layers=32,一共32层transformer decoder
然后就是构造32个 TransformerBlock了:
> /workspace/asr/llama/pyllama/llama/model_single.py(198)__init__()
197 self.layers = torch.nn.ModuleList()
--> 198 for layer_id in range(params.n_layers):
199 self.layers.append(TransformerBlock(layer_id, params))
得到的结果如下:
ipdb> p model
Transformer(
(tok_embeddings): Embedding(32000, 4096) # token embedding 矩阵
(layers): ModuleList(
(0): TransformerBlock(
(attention): Attention(
(wq): Linear(in_features=4096, out_features=4096, bias=False)
(wk): Linear(in_features=4096, out_features=4096, bias=False)
(wv): Linear(in_features=4096, out_features=4096, bias=False)
(wo): Linear(in_features=4096, out_features=4096, bias=False)
(feed_forward): FeedForward(
(w1): Linear(in_features=4096, out_features=11008, bias=False)
(w2): Linear(in_features=11008, out_features=4096, bias=False)
(w3): Linear(in_features=4096, out_features=11008, bias=False)
(attention_norm): RMSNorm()
(ffn_norm): RMSNorm()
(1)... (30) # 构造都一样
(31): TransformerBlock(
(attention): Attention(
(wq): Linear(in_features=4096, out_features=4096, bias=False)
(wk): Linear(in_features=4096, out_features=4096, bias=False)
(wv): Linear(in_features=4096, out_features=4096, bias=False)
(wo): Linear(in_features=4096, out_features=4096, bias=False)
(feed_forward): FeedForward(
(w1): Linear(in_features=4096, out_features=11008, bias=False)
(w2): Linear(in_features=11008, out_features=4096, bias=False)
(w3): Linear(in_features=4096, out_features=11008, bias=False)
(attention_norm): RMSNorm()
(ffn_norm): RMSNorm()
(norm): RMSNorm()
(output): Linear(in_features=4096, out_features=32000, bias=False)
)
上面的RMSNorm,来自root mean square layer norm,论文在:
Root Mean Square Layer Normalization
单层TransformerBlock里面,包括了一个attention: Attention,以及一个feed_forward: FeedForward。
另外,还有两个layer normalization,一个是attention_norm,一个是ffn_norm。
下面是,Transformer类的构造函数的内容:
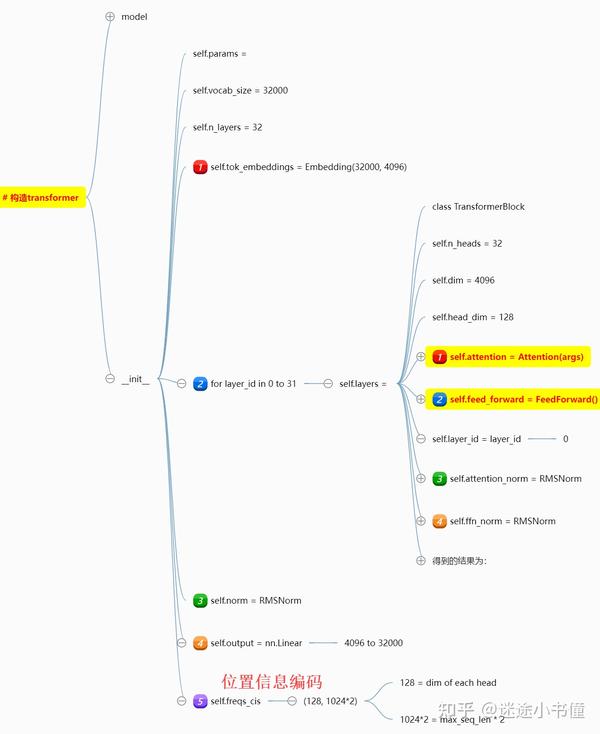
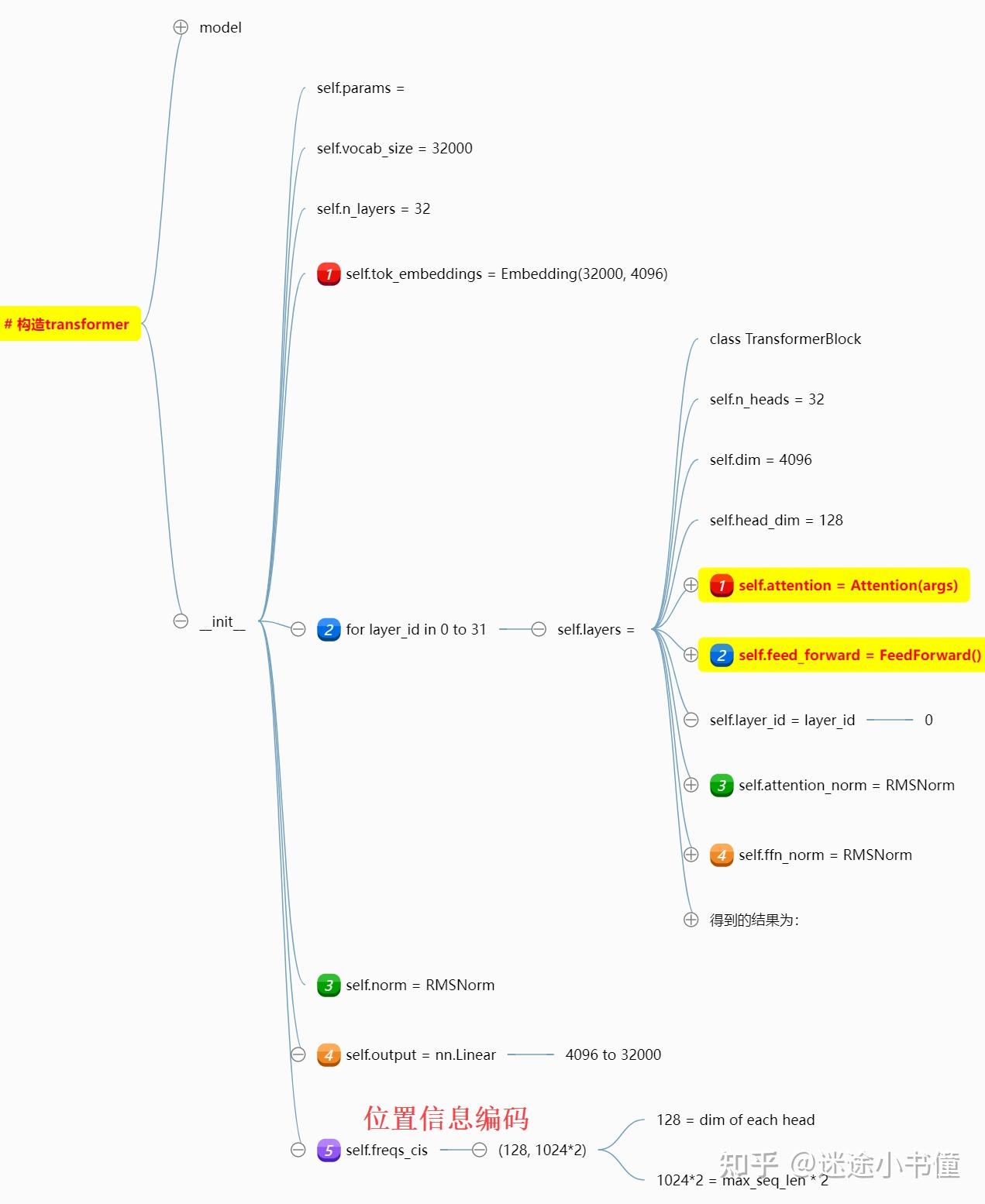
可以看到,五个点:
- token embedding矩阵;词表大小是32000,不大啊,每个token被表示成一个4096维度的向量;
- 一共32层TransformerBlock,每个block里面是包括了,一个Attention(里面四个线性层),一个FeedForward(有意思的是,里面是三层linear layers);以及两个RMS Layer norm;
- self.norm,这个也是rms norm;
- 输出线性层,从4096到32000;
- 位置编码相关的,其中128=4096/32;1024*2是最大序列长度*2。
继续看
Attention构造
这个就是一个带causal masking的self-attention的模块,包括了四个线性层。
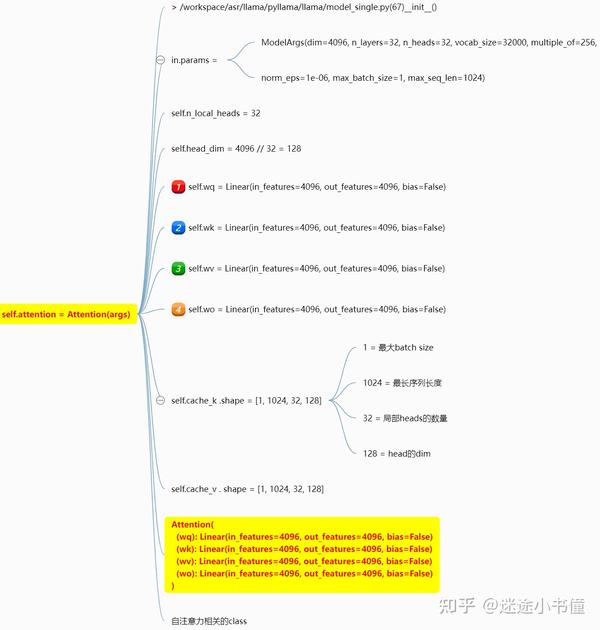

这个的细节就没有必要说了。
ffn有三个线性层!
这个有意思一些,是用了三个线性层,结果还发现,这三个线性层的参数量,比原来的h -> 4h -> h的还多了一些。。。
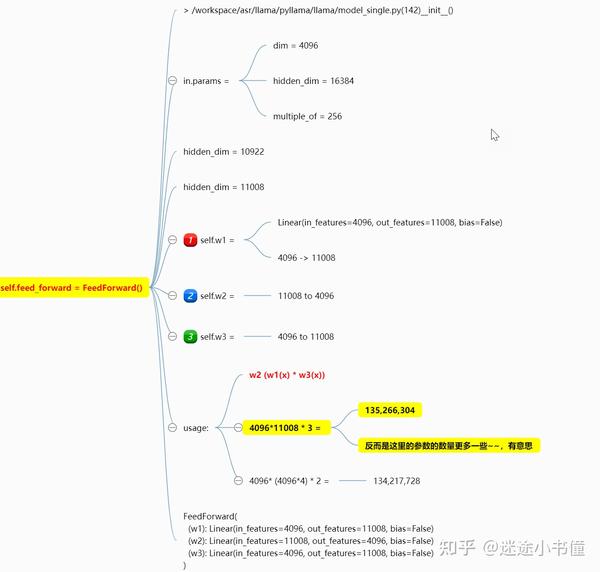
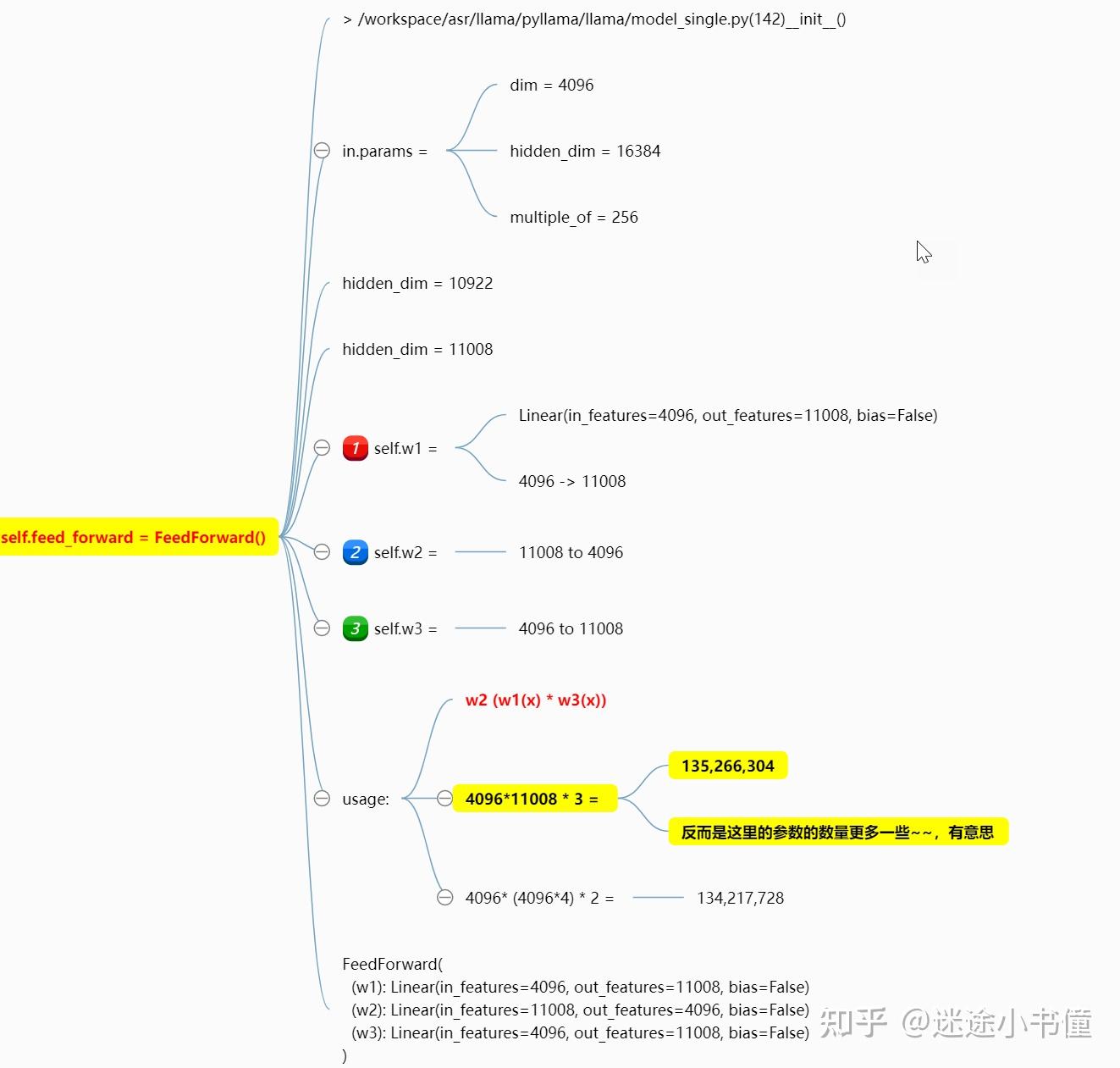
这是先分别用w1和w3来处理输入x,两者的结果相乘,然后用w2再处理一遍。
倒是第一次见到这样的处理方法。
后面的LLaMa的构造函数,就简单粗暴了:
> /workspace/asr/llama/pyllama/llama/generation.py(13)__init__()
12 def __init__(self, model, tokenizer: Tokenizer):
---> 13 self.model = model
14 self.tokenizer = tokenizer
如此,就得到了generator了。
generate生成
这里给定了一个缺省的prompt:
---> 55 "I believe the meaning of life is", # removed: keep only one prompt“生成”的逻辑为:
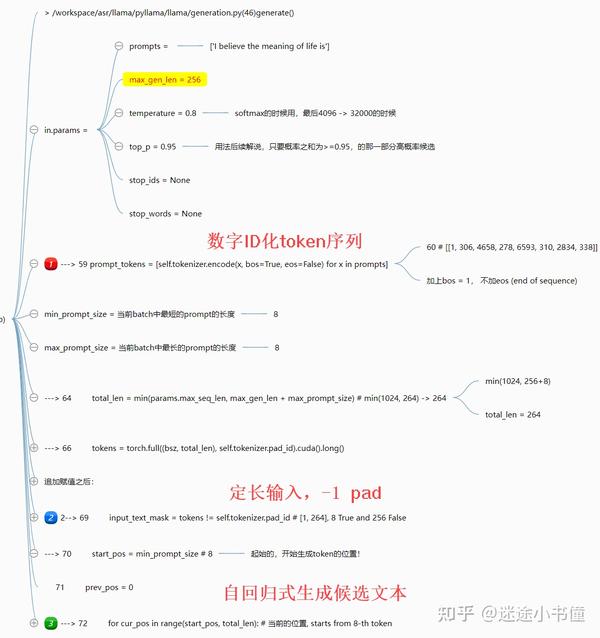
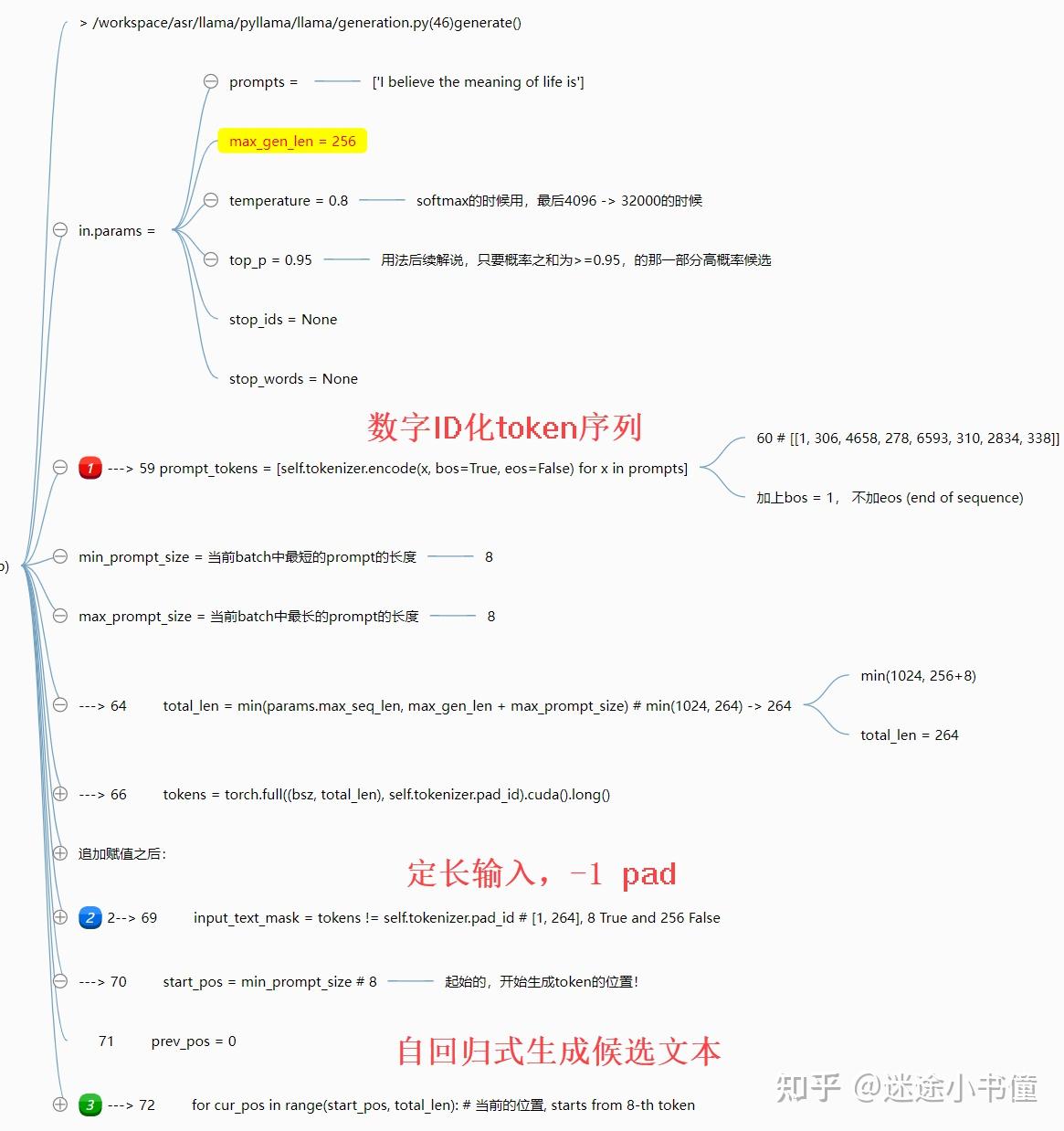
上图给出了“generate()”这个,生成函数的细节。主要是三个部分:
- 把输入文本序列,ID化,调用的是self.tokenizer.encode()方法;前面开头部分追加bos=begin of sequence=1;
- 输入文本的长度的mask,有效部分和padding部分的区分。
- 自回归循环式调用transformer的forward,来一步步生成sequence。
例如,mask的取值为:
ipdb> input_text_mask
tensor([[ True, True, True, True, True, True, True, True, False, False,
False, False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False, False,
False, False, False, False]], device='cuda:0')前面8个位置取值为true,后面的若干位置(264 = 8 true + 256 false)取值为false。整体shape为:[1, 264]。
8个已经给出的prompt tokens,以及后面待生成的256个位置的tokens。
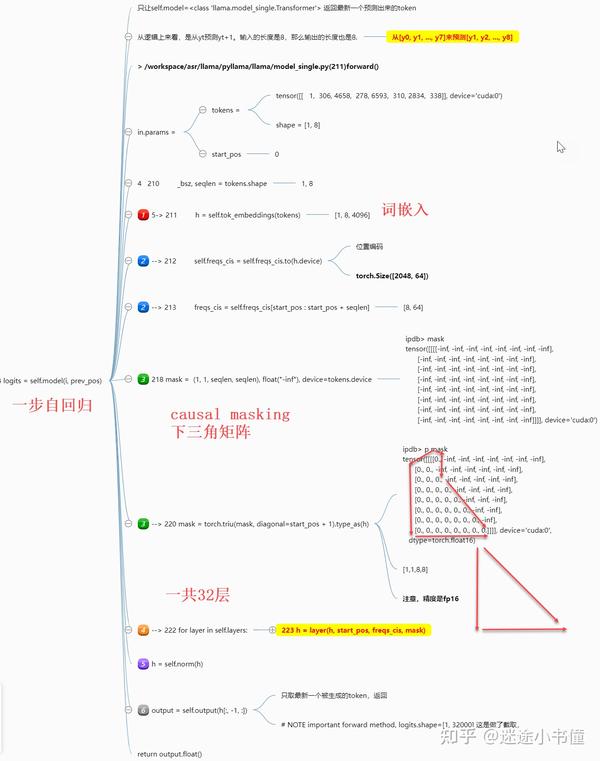
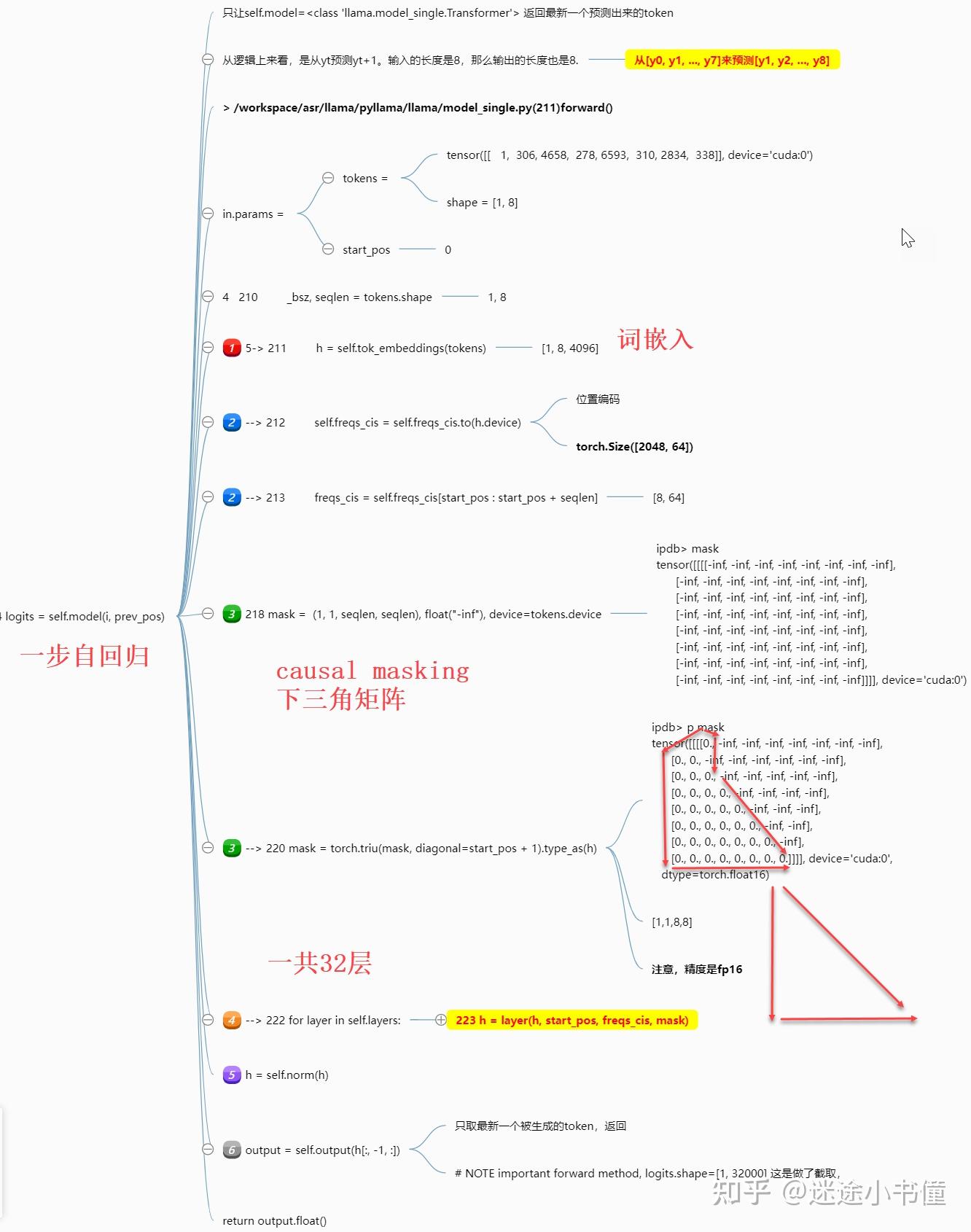
需要注意的是:上面的最后,得到output之后,是只取最后一个(最新生成)的一个token,返回。
block:attention的前向:
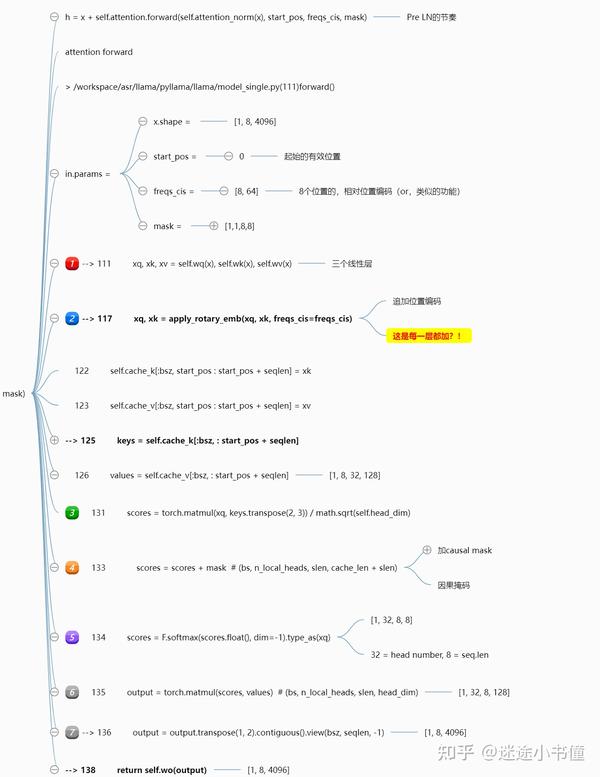

上面是attention layer的前向过程。
切成了七大步:
- 这个就是调用三个线性层,分别得到q, k, v,这个没啥说的;
- 追加位置编码,这个就有意思了,这是把目标序列的位置信息,追加到了attention layer的每一层了啊。“空间信息,追加到了attention的每一层!”。这个类似于stable diffusion model里面把时间t的编码,渗入到每一层attention,那边是“时间信息”。这个有意思了。即,每一层都需要位置信息来指导attention的计算。
- 这个就是Q K^T 然后除以sqrt(head_dim=128),主要是因为softmax的饱和性质,所以,除以sqrt(d_k^h),从而得到mean=0, std=1的一个张量,方便后续softmax的计算,以及梯度的爆炸的防备~~ (和label smoothing有些类似)。
- 追加causal mask,这个是下三角矩阵,下三角以及对角线上都是0,其他的位置都是负无穷大。
- 执行softmax;
- 得到的scores和value相乘积;
- 得到输出,并且还有一步经过第四个线性层wo。
乘积*位置编码
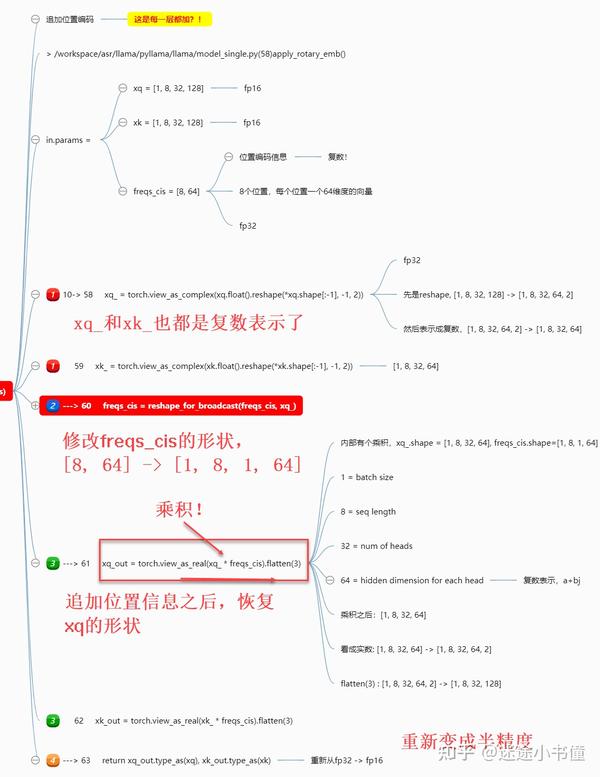

上面这个的追加相对位置编码信息的计算,是在fp32精度下执行的。
通过乘法运算,追加了 位置编码信息到xq和xk 之后,继续恢复fp16.
【2023.05.24追加】
这个是苏剑林大神的,RoFormer的,旋转位置编码:
迷途小书僮:[细读经典]RoFormer: 用旋转位置编码来强化transformer
其核心的思想是类似:
简易计算-旋转位置编码
【需要注意的是,这里的 -x_{d-1} ,其实应该是 -x_d ;
而 x_d ,应该是 x_{d-1} :顺序是:-x2, x1, -x4, x3, ..., 所以,最后两个元素,应该是先-x_d,后是x_{d-1}!】
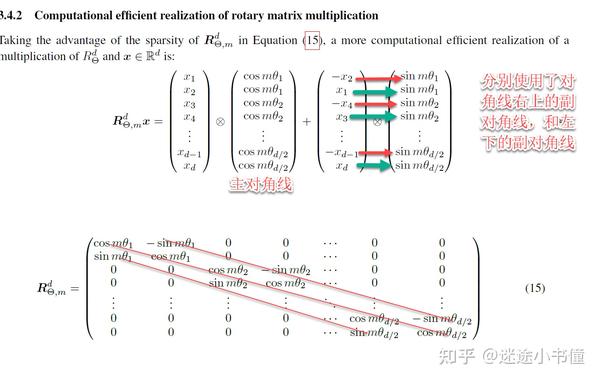
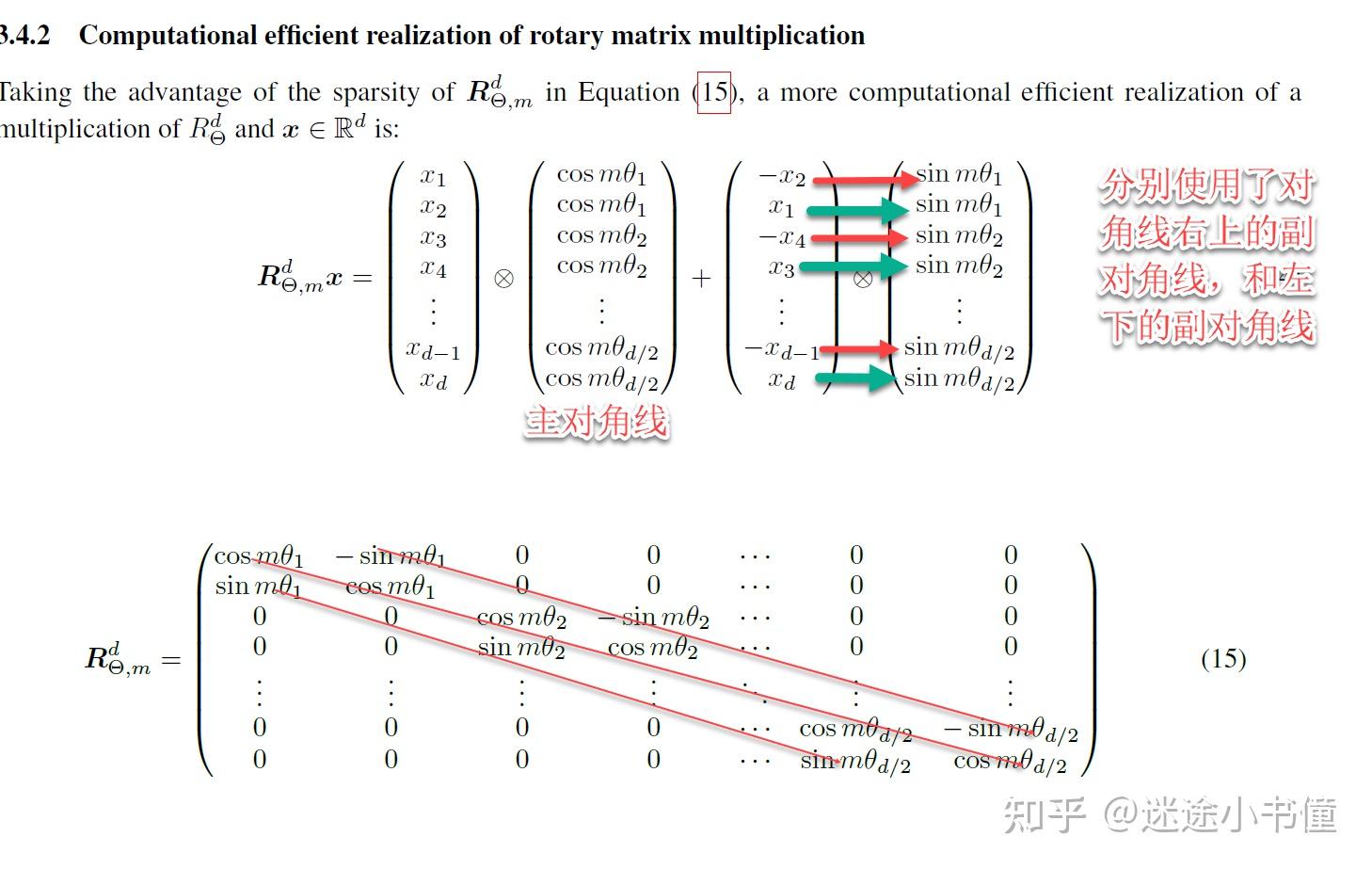
这个旋转位置编码,在复旦的Moss中也有使用:
迷途小书僮:[代码学习]复旦大学MOSS的推理算法代码-part 5-模型前向forward
“旋转位置编码”部分。
上面的第二步,修改freqs_cis的形状的相关操作:


block:ffn的前向:
RMSLN,LN
这个root mean square layer normalization,的逻辑,还是很有意思的;
这里面的可训练参数为:
self.weight = nn.Parameter(torch.ones(dim)) # dim=4096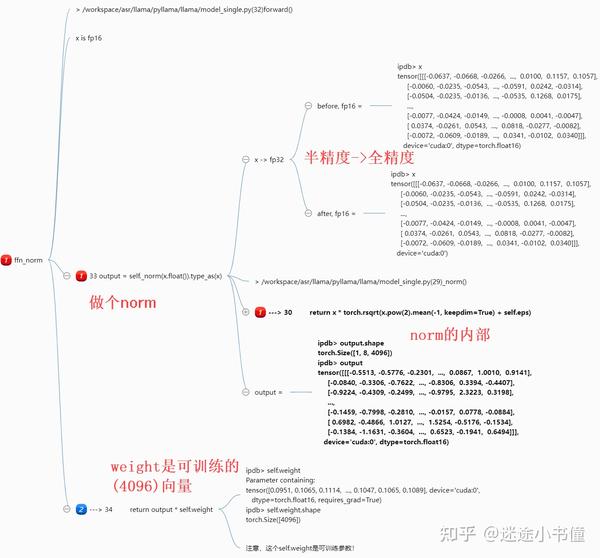

上面的脑图中,涉及到两个大的部分:
- _norm,这部分很好的体现了,power 2 (square,平方),mean 均值,rsqrt 平方根倒数;的逻辑。
- output * self.weight,这是基于可训练的权重张量,self.weight来对output进行重新赋权重。
看一下_norm的细节:
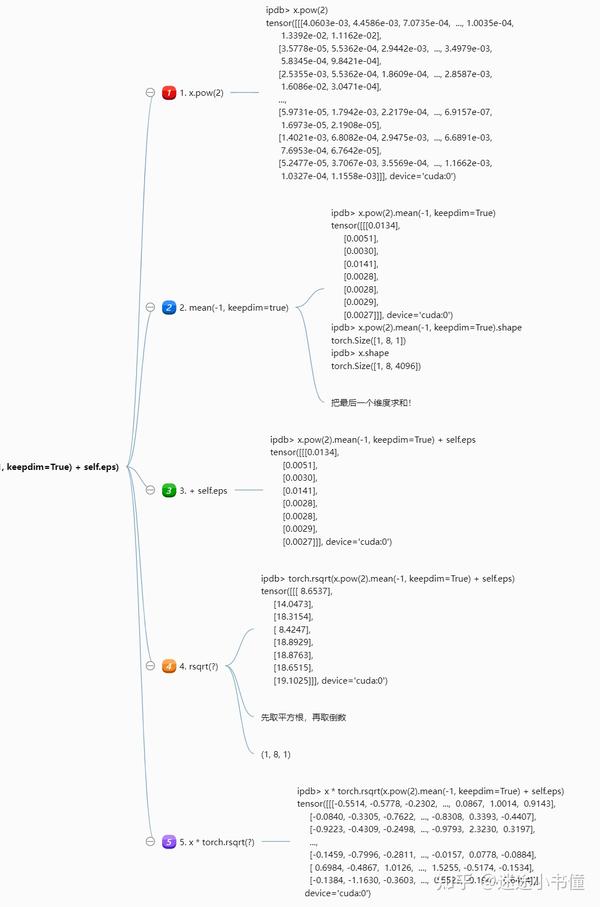
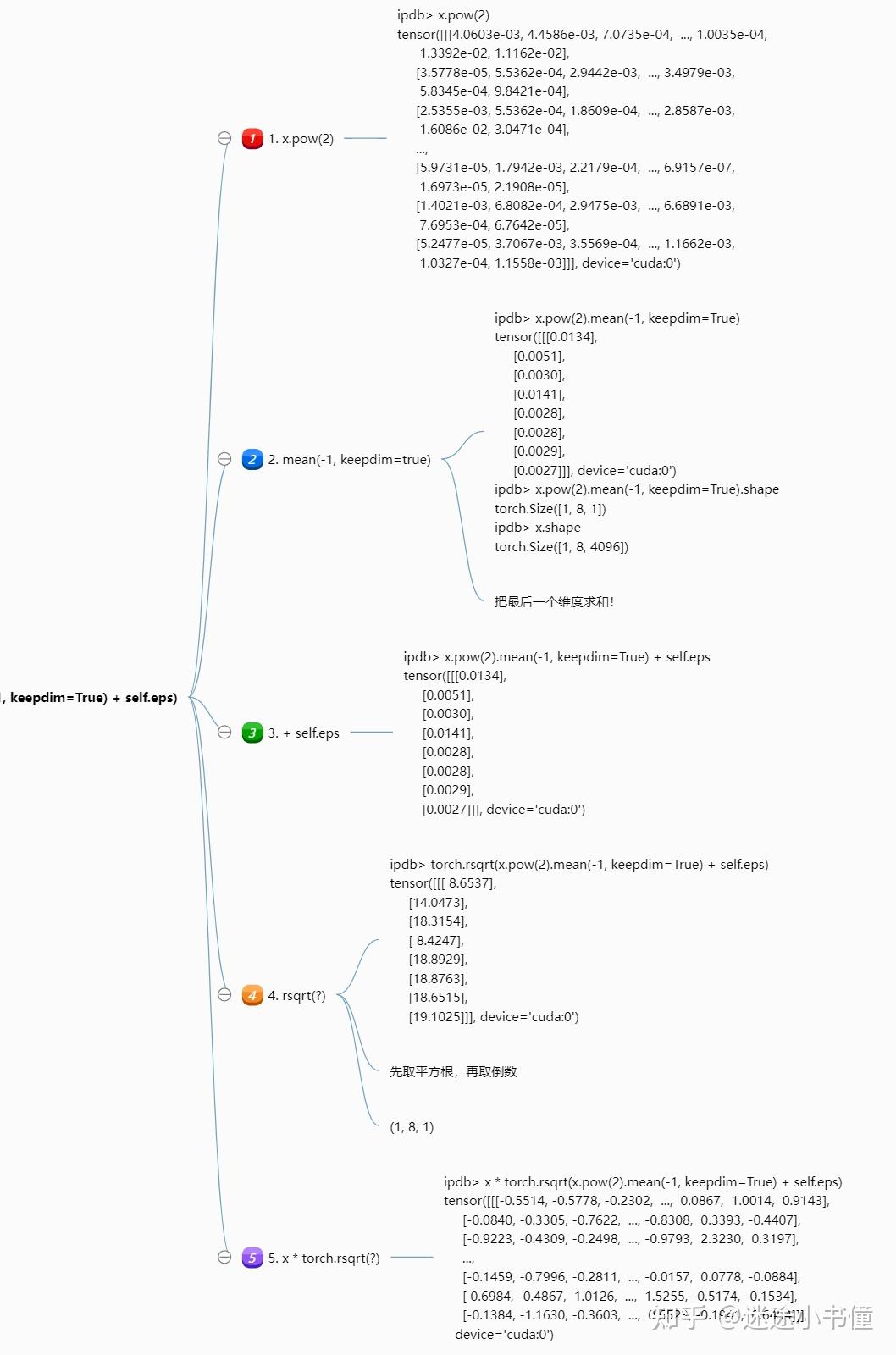
上面的脑图,把中间的取值,都展示出来了。
三个线性层
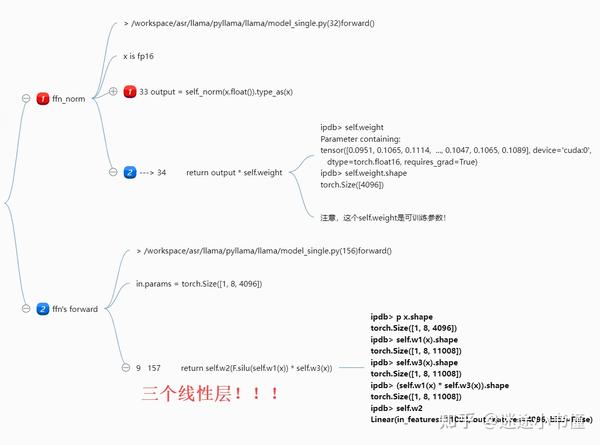

forward之后


上面用到了temperature = 0.8,是softmax里面使用的。
后面,拿到新的token的id = 304,如此,把它追加到tokens中。
更新前一个position, prev_pos=8。
特别的,选择next token的逻辑为:
sample_top_p


上面,next token的挑选,的逻辑,被红色字体的注释,追加出来了。
整体逻辑,还是不难的。直接挑选p>0.95的一些候选了。
eos_id截断


结果整合
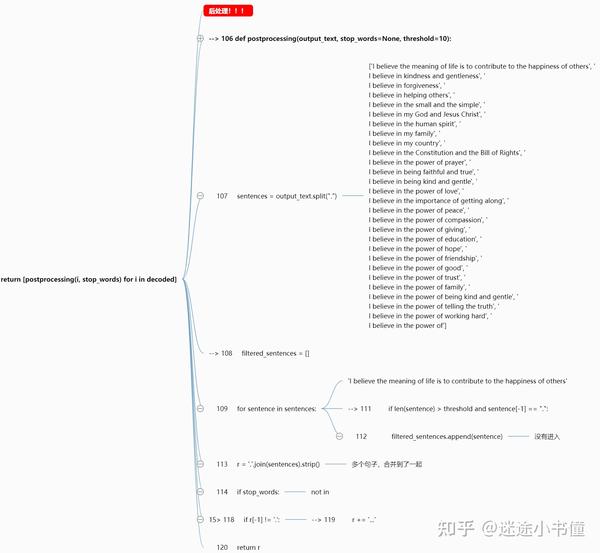
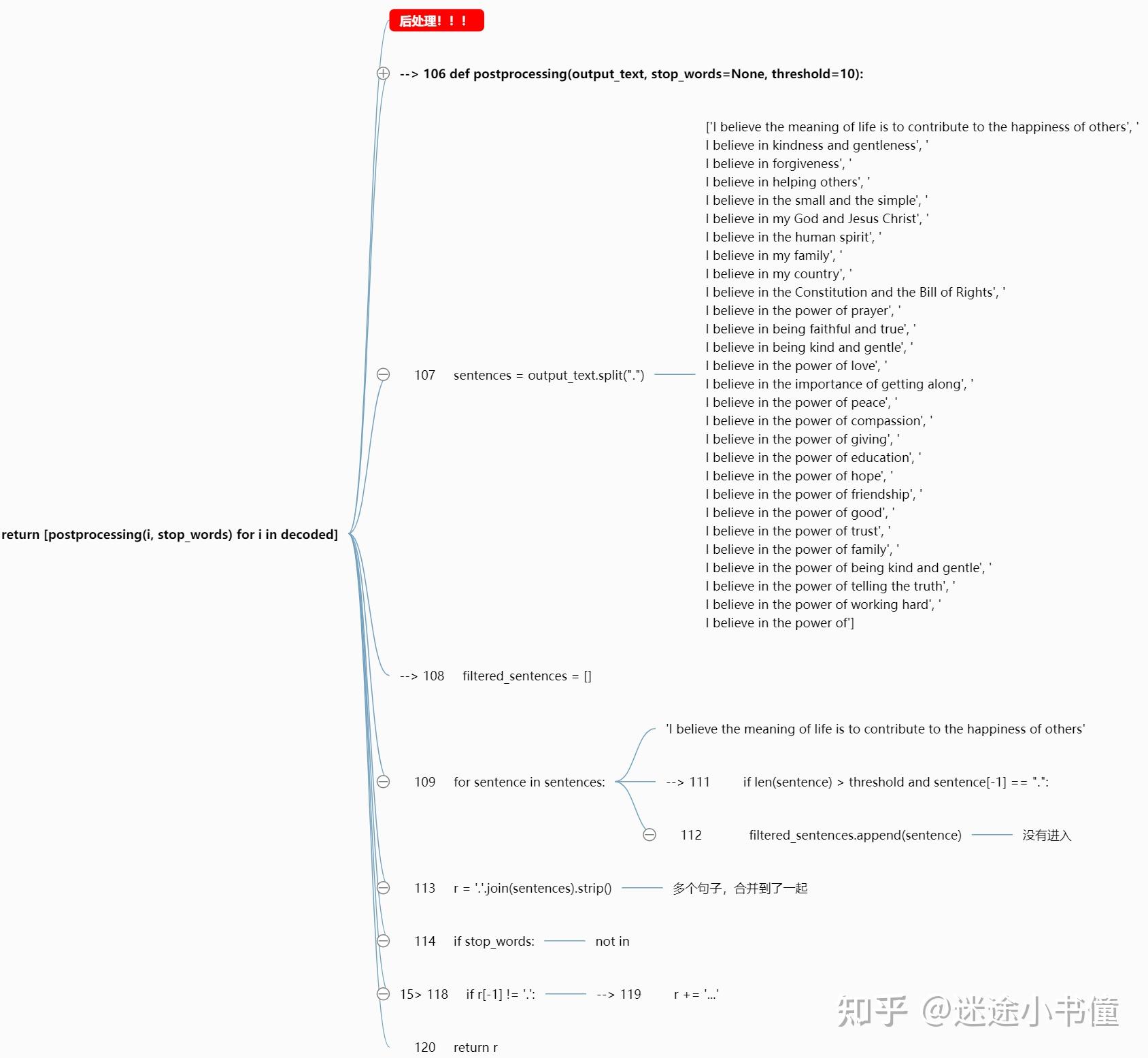
实际的例子:
ipdb> p t
[1, 306, 4658, 278, 6593, 310, 2834, 338, 304, 29126, 304, 278, 22722, 310, 4045,
29889, 13, 29902, 4658, 297, 2924, 2264, 322, 8116, 2435, 404, 29889, 13, 29902,
4658, 297, 18879, 20193, 29889, 13, 29902, 4658, 297, 19912, 4045, 29889, 13,
29902, 4658, 297, 278, 2319, 322, 278, 2560, 29889, 13, 29902, 4658, 297, 590,
4177, 322, 13825, 2819, 29889, 13, 29902, 4658, 297, 278, 5199, 8548, 29889,
13, 29902, 4658, 297, 590, 3942, 29889, 13, 29902, 4658, 297, 590, 4234, 29889,
13, 29902, 4658, 297, 278, 20063, 322, 278, 6682, 310, 26863, 29889, 13, 29902,
4658, 297, 278, 3081, 310, 27402, 29889, 13, 29902, 4658, 297, 1641, 27057, 322,
1565, 29889, 13, 29902, 4658, 297, 1641, 2924, 322, 9914, 29889, 13, 29902, 4658,
297, 278, 3081, 310, 5360, 29889, 13, 29902, 4658, 297, 278, 13500, 310, 2805,
3412, 29889, 13, 29902, 4658, 297, 278, 3081, 310, 10776, 29889, 13, 29902,
4658, 297, 278, 3081, 310, 752, 465, 291, 29889, 13, 29902, 4658, 297, 278,
3081, 310, 6820, 29889, 13, 29902, 4658, 297, 278, 3081, 310, 9793, 29889,
13, 29902, 4658, 297, 278, 3081, 310, 4966, 29889, 13, 29902, 4658, 297,
278, 3081, 310, 27994, 29889, 13, 29902, 4658, 297, 278, 3081, 310, 1781,
29889, 13, 29902, 4658, 297, 278, 3081, 310, 9311, 29889, 13, 29902, 4658,
297, 278, 3081, 310, 3942, 29889, 13, 29902, 4658, 297, 278, 3081, 310, 1641,
2924, 322, 9914, 29889, 13, 29902, 4658, 297, 278, 3081, 310, 14509, 278, 8760,
29889, 13, 29902, 4658, 297, 278, 3081, 310, 1985, 2898, 29889, 13, 29902,
4658, 297, 278, 3081, 310]
ipdb> self.tokenizer.decode(t)
'I believe the meaning of life is to contribute to the happiness of others.\n
I believe in kindness and gentleness.\nI believe in forgiveness.\nI believe in
helping others.\nI believe in the small and the simple.\nI believe in my God and
Jesus Christ.\nI believe in the human spirit.\nI believe in my family.\nI believe
in my country.\nI believe in the Constitution and the Bill of Rights.\nI believe
in the power of prayer.\nI believe in being faithful and true.\nI believe in being
kind and gentle.\nI believe in the power of love.\nI believe in the importance of
getting along.\nI believe in the power of peace.\nI believe in the power of
compassion.\nI believe in the power of giving.\nI believe in the power of