学习正则,工作中使用正则让我对“
^
”有了新的认知:
正则中
^
匹配输入字符串的开始位置,除非在
[]
方括号表达式中使用,此时表示不接受该字符集合。
废话不多说,直接看栗子吧,
如下图所示,需要匹配第一个花括号前的地址
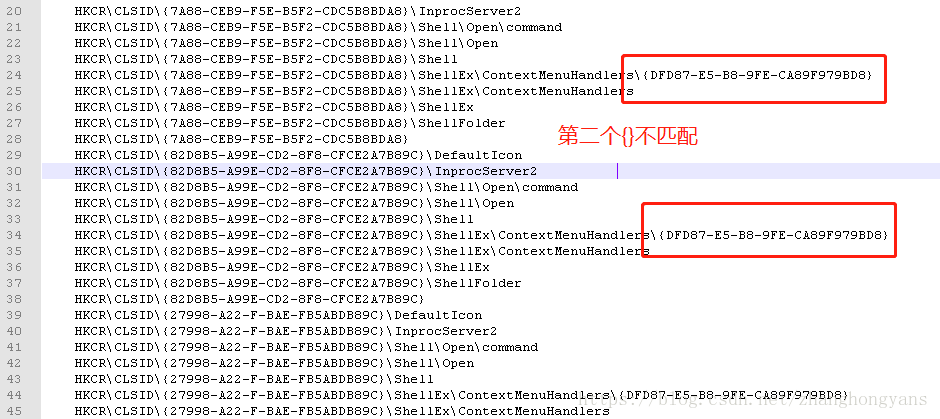
[^}]
除了“
}
”以外的任何字符
[^}]*
0
或多个非“
}
”的字符
^[^}]*
从左向右匹配非“
}
”的多个字符
^[^}]*\}
从左向右匹配第一个包含“
}
”的字符串
正则表达式匹配大括号里面的内容
方法一:
{[^}]+}
var str = "aa ds sdf {asdf asdfag }";
var str1 = str.match(/\{[^\}]+\}/)[0];
方法二:
/{[\S\s]+}/或者/{(.|\r\n)+}/
注:
\S\s
可是微软文档中对
\n
匹配的标准用法哦
var str = "aa ds sdf {asdf asdfag }";
var str1 = str.match(/\{[\S\s]+\}/)[0];
如何利用正则表达式匹配花括号内的内容
匹配花括号内的内容
Input: {abc}, Output: abc
正则表达式:
(?<=\{)[^}]*(?=\})
(?<=\{)
匹配以左花括号开头
[^}]*
取得内容
(?=\})
匹配以右花括号结束
private List<String> GetTokens(String str)
Regex regex = new Regex(@"(?<=\{)[^}]*(?=\})", RegexOptions.IgnoreCase);
MatchCollection matches = regex.Matches(str);
return matches.Cast<Match>().Select(m => m.Value).Distinct().ToList();
java正则表达式匹配小括号内的内容
经常用到正则匹配小括号内容,在此摘录下来
String content = "src: local('Open Sans Light'), local('OpenSans-Light'), url(http://fonts.gstatic.com/s/opensans/v13/DXI1ORHCpsQm3Vp6mXoaTa-j2U0lmluP9RWlSytm3ho.woff2) format('woff2')"
// 从内容上截取路径数组
Pattern pattern = Pattern.compile("(?<=\\()[^\\)]+")
Matcher matcher = pattern.matcher(content)
while(matcher.find()){
System.out.println(matcher.group())
'Open Sans Light'
'OpenSans-Light'
http://fonts.gstatic.com/s/opensans/v13/DXI1ORHCpsQm3Vp6mXoaTa-j2U0lmluP9RWlSytm3ho.woff2
'woff2'
还有一种情况是,我们只匹配url里面的内容,比如要匹配的字符串是
String content = "local('OpenSans-Light'),url(http://fonts.gstatic.com/s/opensans/v13/DXI1ORHCpsQm3Vp6mXoaTa-j2U0lmluP9RWlSytm3ho.woff2) format('woff2');unicode-range:U+0460-052F,U+20B4,U+2DE0-2DFF,U+A640-A69F;}@font-face{font-family:'Open Sans';font-style:normal;font-weight:300;src:local('Open Sans Light'),local('OpenSans-Light'),url(http://fonts.gstatic.com/s/opensans/v13/DXI1ORHCpsQm3Vp6mXoaTZX5f-9o1vgP2EXwfjgl7AY.woff2) format('woff2');unicode-range:U+0400-045F,U+0490-0491,U+04B0-04B1,U+2116;}@font-face{font-family:'Open Sans';font-style:normal;font-weight:300;src:local('Open Sans Light'),local('OpenSans-Light'),url(http://fonts.gstatic.com/s/opensans/v13/DXI1ORHCpsQm3Vp6mXoaTRWV49_lSm1NYrwo-zkhivY.woff2) format('woff2');unicode-range:U+1F00-1FFF;}@font-face{font-family:'Open Sans';font-style:normal;font-weight:300;src:local('Open Sans Light'),local('OpenSans-Light'),url(http://fonts.gstatic.com/s/opensans/v13/DXI1ORHCpsQm3Vp6mXoaTaaRobkAwv3vxw3jMhVENGA.woff2) format('woff2');";
然后将正则规则修改为
Pattern pattern = Pattern.compile("(?<=url\\()[^\\)]+");
这样就能匹配如下内容了
http://fonts.gstatic.com/s/opensans/v13/DXI1ORHCpsQm3Vp6mXoaTa-j2U0lmluP9RWlSytm3ho.woff2
http://fonts.gstatic.com/s/opensans/v13/DXI1ORHCpsQm3Vp6mXoaTZX5f-9o1vgP2EXwfjgl7AY.woff2
http://fonts.gstatic.com/s/opensans/v13/DXI1ORHCpsQm3Vp6mXoaTRWV49_lSm1NYrwo-zkhivY.woff2
http://fonts.gstatic.com/s/opensans/v13/DXI1ORHCpsQm3Vp6mXoaTaaRobkAwv3vxw3jMhVENGA.woff2
正则中使用了零宽度断言
用正则表达式匹配两个字符中间的文本
String skh ="(?<=\\《)[^\\》]+";//用于匹配《》里面的文本
String str="但实际上《kajdwdej》孙大伟多";//测试字符串
Pattern pattern=Pattern.compile(skh);
Matcher matcher=pattern.matcher(str);
boolean is=matcher.find();
if(is)System.out.print(matcher.group());
输出结果为:kajdwdej
同理将skh字符串中《和》换成对应所要匹配的两个字符,就可以匹配两个字符中间的文本
正则获取HTML代码中img的src地址
public static string[] GetHtmlImageUrlList(string sHtmlText)
Regex regImg = new Regex(@"<img\b[^<>]*?\bsrc[\s\t\r\n]*=[\s\t\r\n]*[""']?[\s\t\r\n]*(?<imgUrl>[^\s\t\r\n""'<>]*)[^<>]*?/?[\s\t\r\n]*>", RegexOptions.IgnoreCase);
MatchCollection matches = regImg.Matches(sHtmlText);
int i = 0;
string[] sUrlList = new string[matches.Count];
foreach (Match match in matches)
sUrlList[i++] = match.Groups["imgUrl"].Value;
return sUrlList;
学习正则,工作中使用正则让我对“^”有了新的认知:正则中^匹配输入字符串的开始位置,除非在[]方括号表达式中使用,此时表示不接受该字符集合。废话不多说,直接看栗子吧,如下图所示,需要匹配第一个花括号前的地址[^}] 除了“}”以外的任何字符[^}]* 0或多个非“}”的字符^[^}]* 从左向右匹配非“}”的多个字符...
Python 的 re 模块,使得Python具备了使用全部
正则表达式的功能Python中的
正则表达式正则匹配的时候,
第一个字符是 r,表示 raw string 原生字符,意在声明字符串中间的特殊字符不用转义. r前缀与regex并不特别相关,但通常与Python中的字符串有关.>>> print 'this is n a test'
this is
a test
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。
本系列从易到难分许多篇,对正则表达式比较熟悉的,可以忽略本篇。
正则表达式有两种定义方式:
//1.通过构造函数new出来,需要用\对\进行转义,所以代表数字的\d在参数里要写成 \\d
var reg = new RegExp("\\d")
reg.test(123)
//2.通过字面量书写
使用 ? 字符,正则表达式默认使用贪婪匹配,即尽可能匹配所有符合的,在要匹配的正则后加?可只匹配第一个符合的数字,如 123123 使用 (.) 匹配则group(1)为12323 使用(.?)则会匹配到group(1)-group(6) 内容分别为"1",“2”,“3”,“4”,“5”,“6”

