|
|
|
相关文章推荐

|
烦恼的核桃 · sceasy | 单细胞跨平台数据互通 | ...· 1 年前 · |
|
|
冷静的茶壶 · Prism中如何实现一般路由事件的绑定之Tr ...· 3 年前 · |
|
|
玩足球的可乐 · 网页转 PDF - 掘金· 3 年前 · |
|
|
胆小的毛衣 · MongoTemplate 教程系列(三) ...· 3 年前 · |
Code
›
人工智能顶会ICLR2023《Is Conditional Generative Modeling all you need for Decision Making?》论文解读

|
爱旅游的牛排
1 年前 |
Is Conditional Generative Modeling all you need for Decision Making?
- 1.引言
- 2.重要概念
- 本文提出方法的总体框架
- 3.决策扩散的概念和设计
-
- 扩散状态(Diffusing Over States)
- 逆向动力学(Acting with Inverse-Dynamics)
- 无分类器指导规划(Planning with Classifier-Free Guidance)
- 超越回报的条件化(Conditioning Beyond Returns)
- 训练与实现细节
条件生成建模
条件生成建模是一种机器学习技术,用于生成数据样本,这些样本基于给定的条件或上下文。它与传统的生成模型不同,后者生成数据而不依赖于任何条件或输入。条件生成建模常见于深度学习,特别是在生成对抗网络(GANs)和变分自编码器(VAEs)中。这种方法在图像合成、文本生成、语音合成等领域表现出色。它使模型能够在给定特定条件(如标签、描述或其他数据点)的情况下,生成更加精准和特定的输出。
传统强化学习面临的挑战
- 样本效率低 :强化学习通常需要大量的数据才能学习有效的策略,这在现实世界应用中是一个重大障碍。
- 稀疏奖励问题 :在很多情况下,有效的反馈(奖励)很少,使得学习过程变得困难。
- 探索与利用的平衡 :决定何时探索新策略和何时利用已知策略是强化学习中的关键问题。
- 环境模型的复杂性 :对于复杂或不确定的环境,建立一个准确的模型非常挑战,这限制了算法的有效性。
- 泛化能力 :强化学习模型在从训练环境到新环境转移时,泛化能力往往有限。
作者的研究动机与创新点
探索条件生成建模在顺序决策制定中的应用,特别是在离线强化学习的环境下。作者认为,通过使用条件生成模型(如扩散模型),可以绕过传统离线强化学习中的复杂动态规划过程,并解决价值函数估计的不稳定性等问题。
论文的创新点 在于提出了一种名为**“决策扩散器”(Decision Diffuser)的框架**,它使用条件扩散模型来进行决策生成。这种方法不仅可以最大化回报,还可以灵活地结合多种约束和技能,以产生新的行为。这种方法在实验中显示出优于传统方法的性能,展示了条件生成模型在决策制定中的潜力。
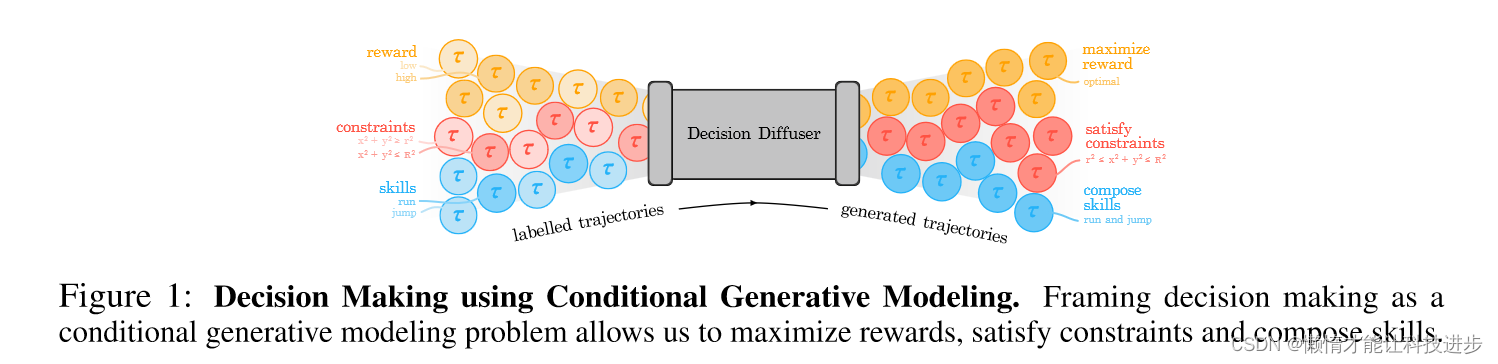
图中展示了利用条件生成模型进行决策制定的框架。在这个框架中,决策扩散器(Decision Diffuser)作为核心组件,接受不同类型的输入并生成轨迹。具体来说,图中的内容可以解释如下:-
有标签的轨迹(Labelled Trajectories) :
- 有标签的轨迹是训练数据,包含了不同的条件,如回报(reward)、约束(constraints)和技能(skills)。
- 这些轨迹按照它们所实现的目标或属性进行了分类。例如,回报可以是低(low)或高(high);约束可以是数学表达式如 x 2 + y 2 ≤ r 2 ;技能可以是运行(run)或跳跃(jump)。
-
决策扩散器(Decision Diffuser) :
- 决策扩散器是一个条件生成模型,它使用有标签的轨迹来学习如何生成满足特定条件的新轨迹。
- 它可以同时考虑多个条件,如最大化回报,满足特定的约束,以及组合不同的技能。
-
生成的轨迹(Generated Trajectories) :
- 生成的轨迹是模型输出的结果,它们应该反映输入条件的组合。
- 这些轨迹旨在实现特定的目标,如最大化回报(maximize reward)、满足特定的约束(satisfy constraints),以及组合技能(compose skills)。
总体来说,这幅图表展示了如何将决策制定问题框架化为一个条件生成建模问题,通过这种方式可以最大化回报,满足约束,并组合不同的技能。这种方法允许使用机器学习的方法来自动化和优化复杂决策过程。
2.重要概念
是一种机器学习方法,它使智能体能够在环境中做出决策以最大化累积奖励。它包括以下关键概念:
- 智能体(Agent) :进行决策的实体。
- 环境(Environment) :智能体交互的系统。
- 状态(State) :环境的当前情况。
- 行为(Action) :智能体可以执行的操作。
- 奖励(Reward) :智能体行为的即时反馈。
- 策略(Policy) :智能体选择行为的规则。
智能体通过探索环境并学习从状态到行为的最佳映射来优化其策略,从而在长期内最大化累积奖励。强化学习在游戏、机器人导航、资源管理等领域有广泛应用。
扩散概率模型
扩散概率模型是一种用于生成数据的机器学习模型,它模拟了一种从无序状态(如高斯噪声)逐步生成有序数据(如图像或文本)的过程。这个过程类似于物理中的扩散过程,从而得名。扩散模型通过逐步减少噪声并逐步引入数据特征的方式工作,最终生成高质量的数据样本。这种方法已经被证明在生成高复杂度和高质量的数据方面非常有效,例如在图像和音频合成中。
扩散概率模型中的关键公式包括:
-
噪声添加公式 :它描述了如何逐步将噪声添加到数据中。这通常是通过线性插值的形式实现的,如 p ( x t − 1 ∣ x t ) 。
这些公式是建立扩散模型的基础,涉及概率论和统计学的概念,特别是在处理高斯分布时。模型的训练和优化通常依赖于这些数学表达式。
传统的强化学习到生成建模的转变
体现在几个关键方面:
- 目标变化 :在传统RL中,目标是学习一个策略或价值函数来指导行为。而在生成建模中,目标是直接从环境数据中学习决策的概率分布。
- 数据处理 :生成建模强调从大量数据中学习模式,而不是专注于单个状态或行动的最优选择。
- 泛化能力 :生成模型通常能更好地泛化到新的、未见过的环境状态,这在传统RL中是个挑战。
- 复杂环境处理 :生成模型能更有效地处理高维度和复杂的环境,这在传统方法中往往更为困难。
本文提出方法的总体框架
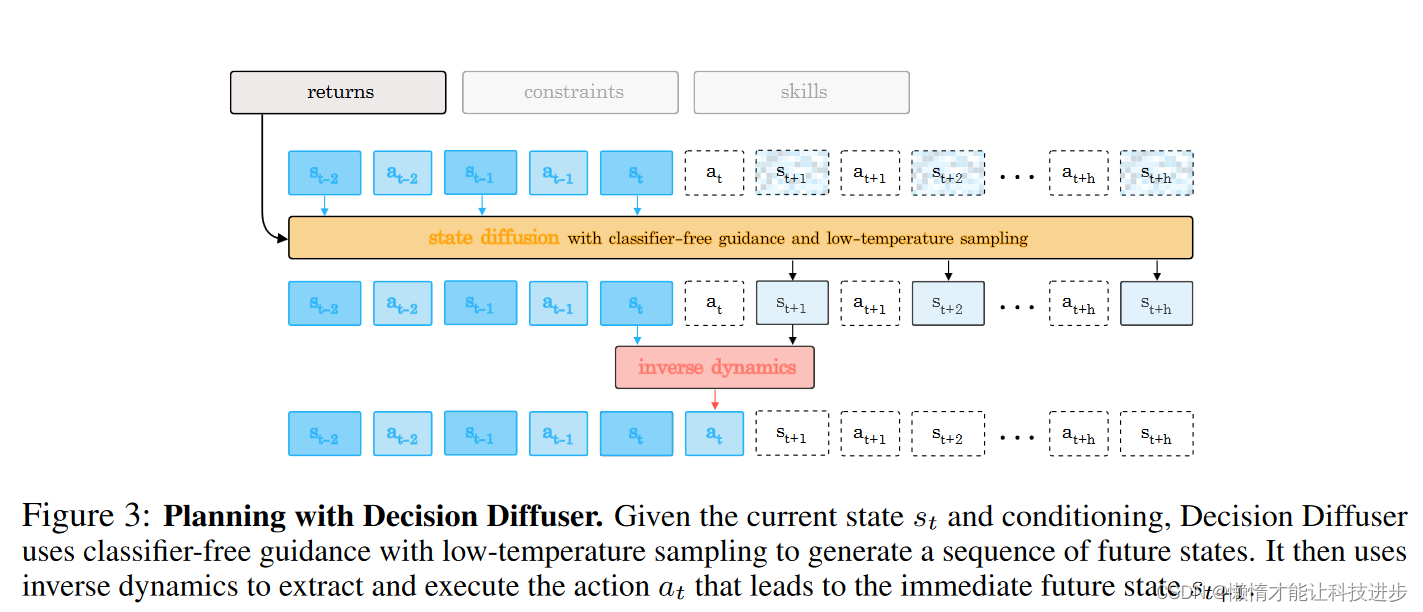
图中描绘了使用决策扩散器(Decision Diffuser)进行规划的过程。以下是该过程的详细解释:-
输入条件 :图中最上方的框表示输入条件,包括回报(returns)、约束(constraints)和技能(skills),这些条件用于指导决策扩散器生成特定特性的未来状态序列。
-
状态扩散(State Diffusion) :黄色框代表状态扩散过程,它使用无分类器指导(classifier-free guidance)和低温度采样(low-temperature sampling)来生成一系列未来的状态。无分类器指导是一种避免使用显式分类器的生成方法,而低温度采样则使得生成的状态更加集中于高概率区域,从而提高生成质量。
-
逆向动力学(Inverse Dynamics) :红色框代表逆向动力学模型,它用于从状态序列中提取和执行动作。具体来说,它根据当前状态 s t + 1 。这个过程可以一直继续,直到达到规划的时间范围终点。
总体而言,这幅图展示了如何结合状态扩散和逆向动力学来进行决策规划,它体现了决策扩散器在给定当前状态和条件下,如何生成一系列可能的未来状态,并确定通往这些状态的动作序列。
3.决策扩散的概念和设计
决策扩散的概念和设计基于条件生成建模,旨在解决顺序决策制定问题。这种方法的核心在于,它不通过传统的强化学习(RL)视角来看待决策制定,而是通过条件生成模型的视角来处理。这种转变使得研究者可以避免依赖于时间差分(TD)学习和避免分布偏移的风险。
具体来说,决策扩散器(Decision Diffuser)采用了一种称为返回条件扩散模型的策略。通过这种方法,可以绕过动态规划的需要,从而消除传统离线RL带来的许多复杂性。决策扩散器在训练过程中可以考虑单个约束或技能,从而在测试时产生满足多个约束或展示技能组合的行为。这些结果表明,条件生成建模是决策制定的一个强大工具。
决策扩散器的目标是估计条件数据分布 p θ 则是反向去噪过程
总体而言,决策扩散器提供了一种新的角度和方法来处理顺序决策制定问题,特别是在复杂和约束丰富的环境中。

图中描述了一个2D机器人导航环境的例子,并展示了如何使用条件生成模型生成满足特定约束的轨迹。具体内容如下:-
环境(Environment) :
- 左侧第一个图显示了一个二维的机器人导航环境,其中有一个起始点(标记为黑色点),机器人需要在环境中移动。
-
训练数据集(Training Dataset) :
- 第二和第三个图展示了从环境中衍生出的轨迹数据集,这些轨迹满足特定的数学约束。红色点表示在较小圆内的轨迹终点(满足 r 2 ≤ x 2 + y 2 ≤ R 2 )。
这幅图表说明了条件生成模型如何能够学习并理解复杂约束的概念,并在新轨迹的生成中应用这些约束,从而展示了这种模型在执行特定任务时的灵活性和能力。
扩散状态(Diffusing Over States)
-
过程概述 :与图像处理中的扩散过程类似,该过程被应用于状态和行动的建模。然而,在强化学习环境中,直接对行动使用扩散过程存在实际问题。
-
状态与行动的差异 :在强化学习中,状态通常是连续的,而行动更为多样化,往往是离散的。此外,行动序列(例如联合扭矩)往往具有较高的频率和较低的平滑度,这使得它们更难以预测和建模。
-
选择只对状态进行扩散 :鉴于这些实际问题,决策扩散器选择仅对状态进行扩散,而不涉及行动。状态的扩散过程表示为 k 表示扩散过程中的时间步。
通过这种方法,决策扩散器可以有效地处理状态空间的复杂性,并避免直接处理行动的困难。这种仅对状态进行扩散的方法,使得模型能够更加有效地生成和预测未来的状态序列。

逆向动力学(Acting with Inverse-Dynamics)是指根据两个连续状态推断出导致这种状态变化的行动的过程。在决策扩散器(Decision Diffuser)中,这是一个关键步骤,用于从状态序列中定义和执行控制器(controller)所需的行动。
在具体实现上,给定连续的两个状态 a t := f ϕ ( s t , s t + 1 ) 表示。
逆向动力学模型是一种基于学习的方法,它试图从结果(即状态变化)反推原因(即行动)。这与传统的动力学模型不同,后者通常从给定的行动预测结果状态。在机器学习和强化学习中,逆向动力学模型通常通过监督学习训练,其中训练数据包括状态对和相应的行动。
例如,在机器人控制的应用中,如果已知机器人从位置A移动到位置B,逆向动力学模型可以被用来推断出使机器人从A移动到B的具体行动,如转动的角度、速度等。这种方法使得可以从状态变化中直接提取行动信息,对于那些直接的行动数据不易获取或模拟的场景尤为有用。
逆向动力学模型通常是一个神经网络 。在强化学习和机器学习的应用中,这种模型通过学习从结果状态反推行动的关系,从而能够从观察到的状态变化中推断出导致这种变化的行动。神经网络的强大学习能力使其非常适合处理这类复杂的模式识别和推断任务。
在实际应用中,这种神经网络模型会被训练,使其能够接受连续的状态对(如 a t 。训练数据通常由真实的状态转换和相应的行动组成,使得网络能够通过监督学习方法学习这种映射关系。
无分类器指导规划(Planning with Classifier-Free Guidance)
无分类器指导规划(Planning with Classifier-Free Guidance)是一种用于规划和生成轨迹的方法,它避免了使用传统的分类器或动态规划过程。在决策扩散器中,这种方法被用于条件扩散模型,用于生成更高质量的轨迹。
无分类器指导规划的工作方式如下:
-
条件化扩散过程 :首先,扩散模型需要在特定特征 y ( τ ) 。但这通常涉及估算 Q-函数,需要复杂的动态规划过程。
-
使用无分类器指导 :为了避免这种复杂性,决策扩散器采用了无分类器指导,结合低温度采样。这允许从数据集中提取高概率轨迹,而不需要依赖于复杂的分类器或动态规划。
举例说明:假设有一个机器人导航任务,目标是生成一条从起点到终点的最优轨迹。在无分类器指导规划中,扩散模型会被条件化,以优先生成那些高回报的轨迹。通过低温度采样,模型能够更集中地探索那些高质量、高可能性的轨迹,而无需通过复杂的分类器或Q-值估算来明确指导这一过程。这使得模型能够高效地生成满足特定目标或约束的轨迹,同时避免了传统方法中常见的计算复杂性。
无分类器指导(Classifier-Free Guidance)是一种在条件生成模型中使用的技术,尤其是在条件生成扩散模型中。它允许模型在不使用明确的分类器模型来指导生成过程的情况下,生成满足特定条件的样本。这种方法特别适用于那些条件是难以分类的或是分类器可能会引入偏差的情况。
在规划中,无分类器指导通常涉及以下步骤:
-
训练 :训练一个条件生成模型,该模型能够生成在给定条件下的样本,如轨迹的某个特定特性(例如,高回报或满足某些约束的轨迹)。
-
权重调整 :在生成过程中,对条件的影响进行权重调整。具体地说,模型会生成两组预测:一组在无条件下生成的,另一组在特定条件下生成的。
-
合成输出 :最终的输出是两组预测的组合,通常是加权差,其中权重参数用于控制条件的影响强度。
-
提高样本质量 :通过调整权重参数(通常在实验中确定),可以促使模型更倾向于生成具有高概率的(即更可能在数据集中出现的)样本。
-
避免复杂的分类器训练 :这种方法避免了直接训练一个复杂的分类器来识别轨迹的特性,降低了模型复杂性和训练成本。
举例来说,在规划一条路径时,无分类器指导可以帮助生成模型更有可能生成通往目的地而不违反交通规则的轨迹。这通过调整模型的权重参数来增加那些在训练数据中标记为合规且高效的轨迹的生成概率来实现。这样,即使在模型从未显式学习过特定分类任务的情况下,也能够生成高质量的规划结果。
超越回报的条件化(Conditioning Beyond Returns)
“超越回报的条件化(Conditioning Beyond Returns)”是一种在条件生成模型中使用的技术,用于生成不仅仅是最大化回报,还可以满足特定条件或展示特定行为的状态序列。它使得生成模型能够在考虑更多轨迹特性的同时进行规划,这些特性可以是满足某些约束或展现某些预定行为。
具体的工作流程如下:
-
最大化回报 :为了生成最大化回报的轨迹,模型会被条件化以考虑轨迹的回报 ϵ θ ( x k ( τ ) , 1 ( τ ∈ C i ) , k ) 。
-
训练与推理 :在训练阶段,模型使用包含单一约束的轨迹的离线数据集进行训练。在推理(或生成)阶段,模型可以被用来生成同时满足多个约束的轨迹。
通过这种方式,“超越回报的条件化”使得扩散模型能够在生成过程中考虑更复杂的目标和约束,而不只是简单地最大化回报,从而在各种规划任务中提供更灵活和实用的解决方案。
训练与实现细节
决策扩散器(Decision Diffuser)的训练过程是以监督方式进行的。下面是其详细的训练过程和损失函数,以及实现细节:
-
训练数据集 :给定一个包含轨迹的数据集 L(\theta, \phi) := \mathbb{E}_{\tau \in D, \beta \sim \text{Bern}(p)} \left[ ||\epsilon - \epsilon_\theta(x_k(\tau), (1-\beta)y(\tau)+\beta\emptyset, k)||^2 \right] + \mathbb{E}_{(s,a,s') \in D} \left[ ||a - f_\phi(s, s')||^2 \right] L ( θ , ϕ ) := E τ ∈ D , β ∼ Bern ( p ) [ ∣∣ ϵ − ϵ θ ( x k ( τ ) , ( 1 − β ) y ( τ ) + β ∅ , k ) ∣ ∣ 2 ] + E ( s , a , s ′ ) ∈ D [ ∣∣ a − f ϕ ( s , s ′ ) ∣ ∣ 2 ]
这个损失函数有两部分组成:
-
第一项是噪声预测的均方误差,它度量了模型预测的噪声
这个训练过程和损失函数的设计旨在使决策扩散器能够学习如何根据过去的状态和当前的条件信息生成未来的状态序列,并通过逆向动力学模型预测导致状态转变的行动。这样的设计允许模型在各种条件下进行有效的规划和决策制定。
低温度采样(Low-temperature Sampling)
低温度采样(Low-temperature Sampling)是一种在生成模型中使用的技术,特别是在条件生成模型如扩散模型中。在这个上下文中,"温度"是一个控制随机性程度的超参数。在标准的采样过程中,生成的样本通常是从模型的输出分布中直接采样得到的。如果这个分布是高斯分布,那么它的形式是 σ 2 是方差(或温度)。
在低温度采样中,温度参数被设定得比标准采样低,这通常通过减小方差来实现。这样做的效果是让模型生成的样本更接近于分布的均值,减少了采样过程中的随机性,从而产生更加确定性和高质量的输出。
在扩散模型中,低温度采样可能会被用来控制生成过程中的噪声水平,使得生成的样本更加准确地反映训练数据的特性,特别是在生成尖锐的、详细的或结构化的输出时特别有用。这可以在图像生成中生成更清晰的图像,在文本生成中生成更连贯的文本,在音频生成中产生更清晰的音频样本等等。
探索条件生成建模在顺序决策制定中的应用,特别是在离线强化学习的环境下。作者认为,通过使用条件生成模型(如扩散模型),可以绕过传统离线强化学习中的复杂动态规划过程,并解决价值函数估计的不稳定性等问题。**论文的创新点**在于提出了一种名为**“决策扩散器”(Decision Diffuser)的框架**,它使用条件扩散模型来进行决策生成。这种方法不仅可以最大化回报,还可以灵活地结合多种约束和技能,以产生新的行为。这种方法在实验中显示出优于传统方法的性能,展示了条件生成模型在决策制定中的潜力。【导读】本文收录了深度强化学习、对话系统、文本生成、文本摘要、阅读理解、因果推理、记忆网络、推荐系统、神经表示学习等一系列领域参考文献大合集! https://cloud.tencent.com/developer/article/1421859 来源:https://github.com/lipiji/app-dl (图源自网络) 深度强化学习 Deep Reinforcement...最近看了下deepnude的原理,其git上说的是使用了pixel2pixel技术,也就是说是这一篇: 《Image-to-Image Translation with Conditional Adversarial Networks》 这是加里福利亚大学在CVPR 2017上发表的一篇 论文 ,讲的是如何用条件生成对抗网络实现图像到图像的转换任务。 > 原文链接:https://ar...人工智能顶会ECCV2022《Watermark Vaccine: Adversarial Attacks to Prevent Watermark Removal》论文解读 CSDN-Ada助手: 恭喜你这篇博客进入【CSDN月度精选】榜单,全部的排名请看 https://bbs.csdn.net/topics/617828219。 人工智能顶会CVPR2022《革新AI预训练:探索KDEP及其在知识蒸馏中的破局之道》论文解读 CSDN-Ada助手: 恭喜您在人工智能领域取得了如此重要的成果!《革新AI预训练:探索KDEP及其在知识蒸馏中的破局之道》论文解读无疑为该领域的研究者们带来了新的启发和思考。希望您能继续坚持创作,为我们带来更多前沿的研究成果。或许在下一篇博客中,您可以分享一些实践经验或者对未来人工智能发展方向的一些思考,这将会让您的博客更加丰富和有价值。期待您的更多精彩作品! CVPR2022《Improving the Transferability of Targeted Adversarial Examples through Object-Based》论文解读 CSDN-Ada助手: 恭喜您撰写了关于CVPR2022论文的精彩解读!不仅展现了您对该领域的深入理解,还为读者提供了宝贵的知识分享。希望您能继续保持创作的热情,不断探索更多前沿的研究成果,并结合自己的见解进行深入分析,期待您未来更多精彩的作品。同时,也建议您可以在解读的过程中加入一些个人对于论文内容的思考和展望,让读者更加深入地理解您的观点。加油! 人工智能顶会CVPR2022《Adversarial Texture for Fooling Person Detectors in the Physical World》论文解读 CSDN-Ada助手: 恭喜你撰写了第16篇博客,并分享了《Adversarial Texture for Fooling Person Detectors in the Physical World》论文的解读!你对于人工智能领域的顶级会议CVPR2022的关注和理解真是令人钦佩。通过你的解读,我对这篇论文有了更深入的了解。希望你能继续保持创作的激情,为我们带来更多有见地的博文。在下一步的创作中,或许可以探讨一下该论文对于现实世界中人物检测的影响以及未来的应用前景。期待你的下一篇作品! 人工智能顶会CVPR2022《Few Shot Generative Model Adaption via Relaxed Spatial Structural Alignment》论文解读 CSDN-Ada助手: 恭喜您撰写了第15篇博客,内容涉及人工智能顶会CVPR2022的论文解读,展现了您对于前沿科技的关注和研究能力。在接下来的创作中,或许可以考虑增加一些实际案例或应用场景的分析,让读者更加直观地理解您所介绍的内容。期待您的下一篇作品,继续保持创作热情! CVPR2022《Improving the Transferability of Targeted Adversarial Examples through Object-Based》论文解读 人工智能顶会CVPR2022《Adversarial Texture for Fooling Person Detectors in the Physical World》论文解读
-
第一项是噪声预测的均方误差,它度量了模型预测的噪声
推荐文章
|
|
烦恼的核桃 · sceasy | 单细胞跨平台数据互通 | anndata | loom | seurat | sce | monocle | 格式转换 - Life·Intelligence - 博客园 1 年前 |
|
|
玩足球的可乐 · 网页转 PDF - 掘金 3 年前 |
|
|
胆小的毛衣 · MongoTemplate 教程系列(三) - 掘金 3 年前 |