

PyTorch CPU性能优化(三):向量化

前言 本篇是关于PyTorch CPU性能优化相关的简单入门教程的第三篇。
欢迎关注公众号 CV技术指南 ,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。目前公众号正在 征稿 中,可以获取对应的稿费哦。
作者:马鸣飞@知乎(授权转载)
编辑:CV技术指南
原文: https:// zhuanlan.zhihu.com/p/49 9761288
前两篇:
PyTorch CPU性能优化(一):Memory Format 和 Channels Last 的性能优化
向量化基础
向量化(Vectorization)就是指一条指令多个数据的技术,是提高CPU性能的另一种常用手段。Vectorization有很多种方法可以实现,比如使用compiler自动向量化,这篇主要介绍通过写intrinsics的方式手动向量化。
intrinsics数据类型和命名规则
Intel平台上的intrinsics都可在Intel® Intrinsics Guide查到,在AVX2和AVX512中数据类型有:
__m256 // 256-bit vector containing 8 floats
__m256d // 256-bit vector containing 4 doubles
__m256i // 256-bit vector containing integers
__m512 // 512-bit vector containing 16 floats
__m512d // 512-bit vector containing 8 doubles
__m512i // 512-bit vector containing integer一般来讲,intrinsics的命名遵循下面这个范式:
_mm<bit_width>_<operator_name>_<dtype><bit_width>对于128bit指令是空的,对于256bit指令就是256,对于512bit指令是512。
<dtype>可以选下面这个列表中值:
- ps - packed single precision
- pd - packed double precision
- epi8/epi16/epi32/epi64 - extend packed signed integer
- epu8/epu16/epu32/epu64 - extend packed unsigned integer
- si128/si256/si512 - unspecified vector (for casting)
PyTorch的Vectorized Wrapper
PyTorch ATen下面的CPU原生kernel是采用手动向量化方式写的,用了一个工具类at::vec::Vectorized<T>,后续文中简称为Vec。
- Vec 是用来抽象各种SIMD架构指令的结构体,包含了AVX2,AVX512还有mobile的平台;
- 默认条件下,使用Vec写成的CPU kernel文件会被编译多次,对应不同的架构。GCC9上面会编译3种:scalar版本,AVX2版本,AVX512版本。GCC8及以下不会编译AVX512版本,只有scalar版本和AVX2版本;
- 运行时,OP会选择当前可执行的最高指令架构,顺序是AVX512>AVX2>Scalar。
- 目前PyTorch发行版中没有编译AVX512版本,最高执行AVX2。
Fig-1是一些常用的intrinsics:(a) initialization; (b) load/store; (c) gather/scatter; (d) arithmetic.
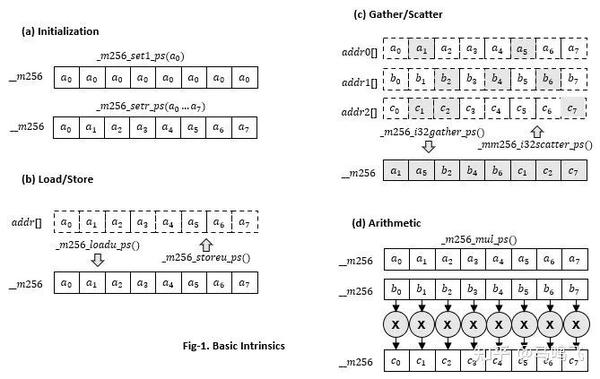

上面这些可以这样映射到Vec中:
Vec(1.0f); // initialization
Vec x = Vec::loadu(addr); // load
x.store(addr); // store
Vec y = x * Vec(2.0f); // multiplvgather、scatter是对应非连续内存访问的intrinsics,会多次访问cache line,所以这两条指令速度比较慢。有的时候,如果按固定stride去访问数据的情况(比如stride=2,即隔一个读一个),经常可以通过load、store和permute、shuffle的方式来实现,这样的话速度会快很多,比如matrix transpose的情况。
Fig-2展示更多的intrinsics,如果用permute和shuffle来重新排列数据:
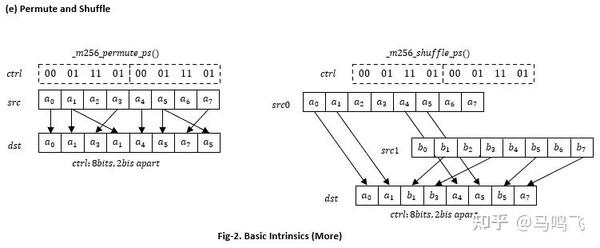

这里的ctrl是个8bit整数,控制数据在一个lane (128bit)上的移动方式。
范例 I: Prefix Sum
第二章里面讲了这个前缀和如何并行化的例子,这里继续介绍一下怎么向量化这个操作。两章内容合在一起就是完整的优化方法。具体流程如Fig-3所示:
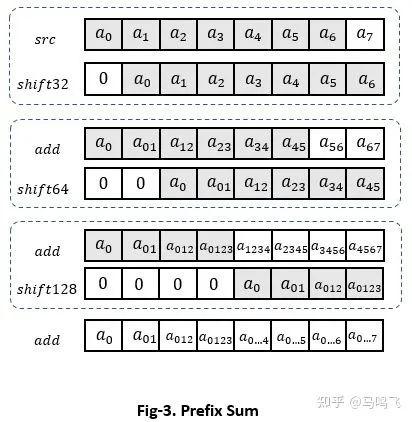
AVX2上面需要3轮'shift' + 'add',如果是AVX512则需要4轮,kernel如下:
template <>
inline void cumsum<float>(float base, const float* src, float* dst, int64_t n) {
__m256 offset = _mm256_set1_ps(base);
int64_t i;
#pragma unroll
for (i = 0; i <= (n - Vectorized<float>::size()); i += Vectorized<float>::size()) {
__m256 x = _mm256_loadu_ps(src + i);
// shift 32 bit
// x = {a0, a1, a2, a3, a4, a5, a6, a7}
// y = { 0, a0, a1, a2, a3, a4, a5, a6}
__m256 t0 = _mm256_permute_ps(x, 0x93);
__m256 t1 = _mm256_permute2f128_ps(t0, t0, 0x29);
__m256 y = _mm256_blend_ps(t0, t1, 0x11);
x = _mm256_add_ps(x, y);
// shift 64 bit
// x = {a0, a01, a12, a23, a34, a45, a56, a67}
// y = { 0, 0, a0, a01, a12, a23, a34, a45}
t0 = _mm256_permute_ps(x, 0x4E);
t1 = _mm256_permute2f128_ps(t0, t0, 0x29);
y = _mm256_blend_ps(t0, t1, 0x33);
x = _mm256_add_ps(x, y);
// shift 128 bit
// x = {a0, a01, a012, a0123, a1234, a2345, a3456, a4567}
// y = { 0, 0, 0, 0, a0, a01, a012, a0123}
y = _mm256_permute2f128_ps(x, x, 0x29);
x = _mm256_add_ps(x, y);
x = x + offset;
_mm256_storeu_ps(dst + i, x);
// broadcast the offset
t0 = _mm256_permute2f128_ps(x, x, 0x11);
offset = _mm256_permute_ps(t0, 0xFF);
float offset_val = _mm256_cvtss_f32(offset);
#pragma unroll
for (; i < n; ++i) {
offset_val += src[i];
dst[i] = offset_val;
}范例 II: Horizontal Reduce
这里的Horizontal Reduce指的是将一个vector归约成一个scalar的操作。如果我们需要将一行数据做归约,一般分两步:第一步先按照vector归约,第二步把最后那个vector归于到一个scalar。
这个PR目的是优化Softmax和LogSoftmax在dim = -1时的性能:#73953。
主要是因为Transformer中MultiheadAttention里面的Softmax最后一维都不会太大,而且原本PyTorch这个Vector reduce的操作比较慢,所以这个地方就成了显著的bottleneck。流程如下图:
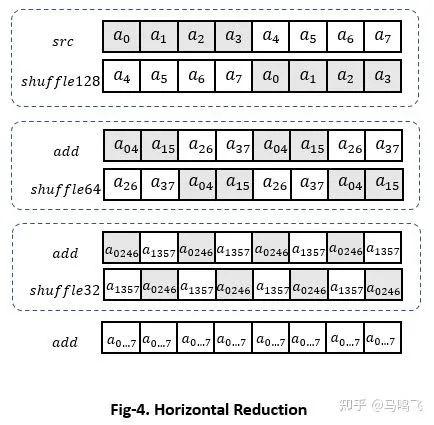

AVX2上面需要3轮'shuffle' + 'add',如果是AVX512则需要4轮,kernel如下:
template <typename scalar_t=float, typename Op>
inline float vec_reduce_all(
const Op& vec_fun,
vec::Vectorized<float> acc_vec) {
using Vec = vec::Vectorized<float>;
Vec v = acc_vec;
// 128-bit shuffle
Vec v1 = _mm256_permute2f128_ps(v, v, 0x1);
v = vec_fun(v, v1);
// 64-bit shuffle
v1 = _mm256_shuffle_ps(v, v, 0x4E);
v = vec_fun(v, v1);
// 32-bit shuffle
v1 = _mm256_shuffle_ps(v, v, 0xB1);
v = vec_fun(v, v1);
return _mm256_cvtss_f32(v);
}上面vec_fun是个lambda,如果是求sum,对应就是个加法。
特例 I: ChannelShuffle
ChannelShuffle 是个用来重新排列channel维度上的数据的op,这里介绍一下这个op在channels first和channels last两种memory format上的写法。并行化策略是按照output的shape来划分的,如Fig-5所示(假设G=2, C=4):
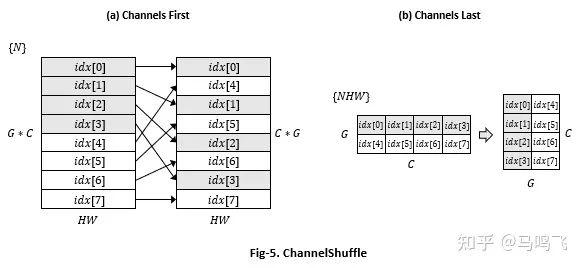

在channels first上面,我们可以在{N * C * G}三个维度上做并行化,算出output对应的input offset之后按行copy {H * W}即可:
using Vec = vec::Vectorized<scalar_t>;
int64_t inner_size = image_size - (image_size % Vec::size());
at::parallel_for (0, nbatch * /* oc*g */channels, 0, [&](int64_t begin, int64_t end) {
int64_t n = 0;
int64_t oc = 0;
int64_t g = 0;
data_index_init(begin, n, nbatch, oc, channels_per_group, g, groups);
for (const auto i : c10::irange(begin, end)) {
scalar_t* output_ptr = output_data + i * image_size;
scalar_t* input_ptr = input_data + n * channels * image_size +
g * channels_per_group * image_size + oc * image_size;
int64_t d = 0;
for (; d < inner_size; d += Vec::size()) {
Vec data_vec = Vec::loadu(input_ptr + d);
data_vec.store(output_ptr + d);
for (; d < image_size; d++) {
output_ptr[d] = input_ptr[d];
// move on to next output index
data_index_step(n, nbatch, oc, channels_per_group, g, groups);
});在channels last上面,可以在{N * H * W}上做并行,然后做个从{G, C}到{C, G}的transpose:
at::parallel_for(0, nbatch * image_size, 0, [&](int64_t begin, int64_t end) {
for (const auto i : c10::irange(begin, end)) {
scalar_t* output_ptr = output_data + i * channels;
scalar_t* input_ptr = input_data + i * channels;
// transpose each channel lane:
// from [groups, channels_per_group] to [channels_per_group, groups]
utils::transpose(groups, channels_per_group, input_ptr, channels_per_group, output_ptr, groups);
});这里我们可以看到,使用PyTorch各种各样的util来搭建kernel非常方便高效。utils::transpose最终会用到fbgemm的transpose_simd。
特例 II: ShuffleNet Fusion
既然讲到了ChannelShuffle,那就说一下怎么在ShuffleNet中做相应的fusion,进一步提高性能。参考TorchVision中的实现,ShuffleNet里面的depthwise_conv模块中的'cat'和'channel_shuffle'可以fuse成一个kernel,过程如Fig-6:
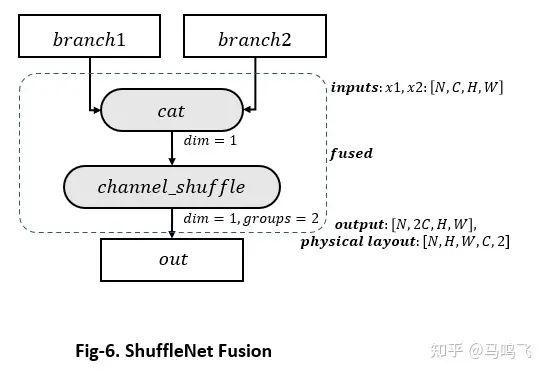

在channels last上面(C是最后一维),我们可以直接在{N,H,W}上并行化,在{C}上面做一个interleaved copy,下面是伪码:
// x1_stride/x2_stride may be C or 2C
// out stride is 2C
at::parallel_for(0, nbatch * height * width, 0, [&](int64_t begin, int64_t end) {
for (int64_t i = begin; i < end; ++i) {
scalar_t* x1_ptr = x1_data + i * x1_stride;
scalar_t* x2_ptr = x2_data + i * x2_stride;
scalar_t* out_ptr = out_data + i * 2 * channels;
int64_t d = 0;
for (; d < channels - (channels % Vec::size()); d += Vec::size()) {
Vec x1 = Vec::loadu(x1_ptr + d);
Vec x2 = Vec::loadu(x2_ptr + d);
Vec out1, out2;
std::tie(out1, out2) = vec::interleave2(x1, x2);
out1.store(out_ptr + d);
out2.store(out_ptr + d + Vec::size();