


用 Mapbox 可视化能源数据的 5 个步骤和多个技巧(附源码)



《Mapbox 一分钟》栏目每月更新至少两次,将会以中文视频或通俗易懂的图文,让开发者了解到 Mapbox 的最新使用技巧。
往期回顾:
Mapbox 一分钟 | 为地图标注文字的 5 种超级实用策略
Mapbox 一分钟 | 用 Mapbox GL JS 为地图自定义显示 3D 模型
本期我们将为大家分享关于数据可视化的内容,如果你不知道数据怎么来?拿到数据后怎么处理?怎么导入?怎么优化?那么一定不要错过哦!(文末有彩蛋! )
我们以美国能源数据为例,将它从头到底剖析一番,最终呈现的效果大概是这样的。
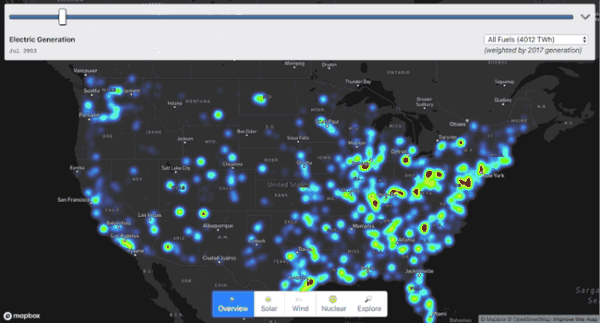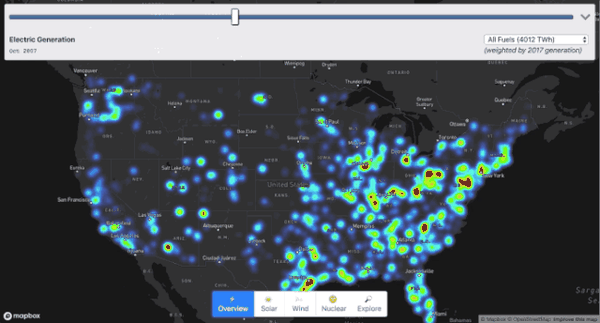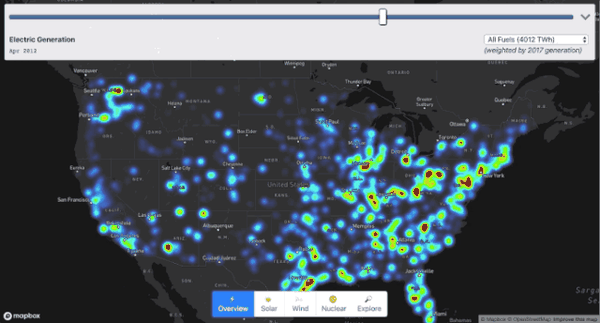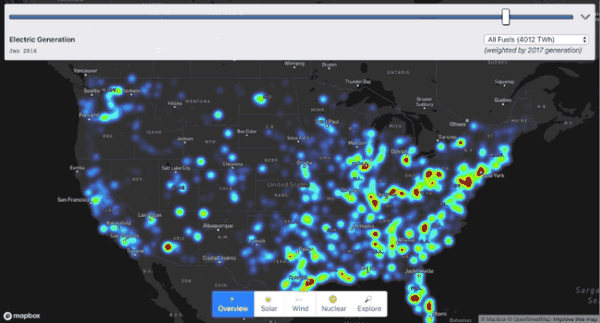
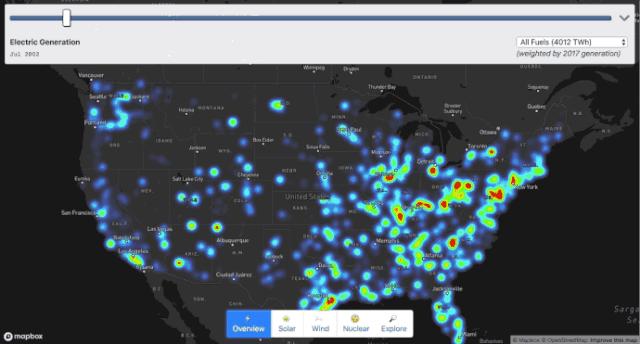
你可以
点击打开项目网站
,在浏览器中亲自体验。
项目源码也为你准备好了,
点击这里查看源码
,并跟着我们下面的内容,开始你的学习之旅吧!
目前的现状是,我们就算拥有了很多数据,却也无法看出其背后的含义,有一种原因是,我们缺乏在时空上的比较,无法看出数据变化的趋势。
为了解决这个问题,我们不妨做个实验?
第一步:从公开网站上获取数据
美国政府有很多公开下载的数据,比如
Data.gov
网站上就能找到许多开放的政府数据。比如在
美国能源信息管理局网站
上,我们能下美国每个发电厂的每月发电数据(如下图)。
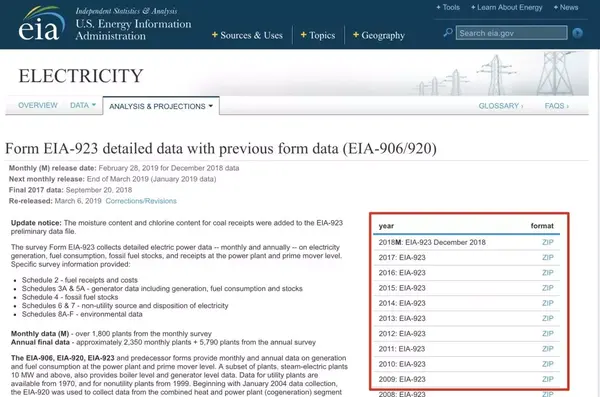
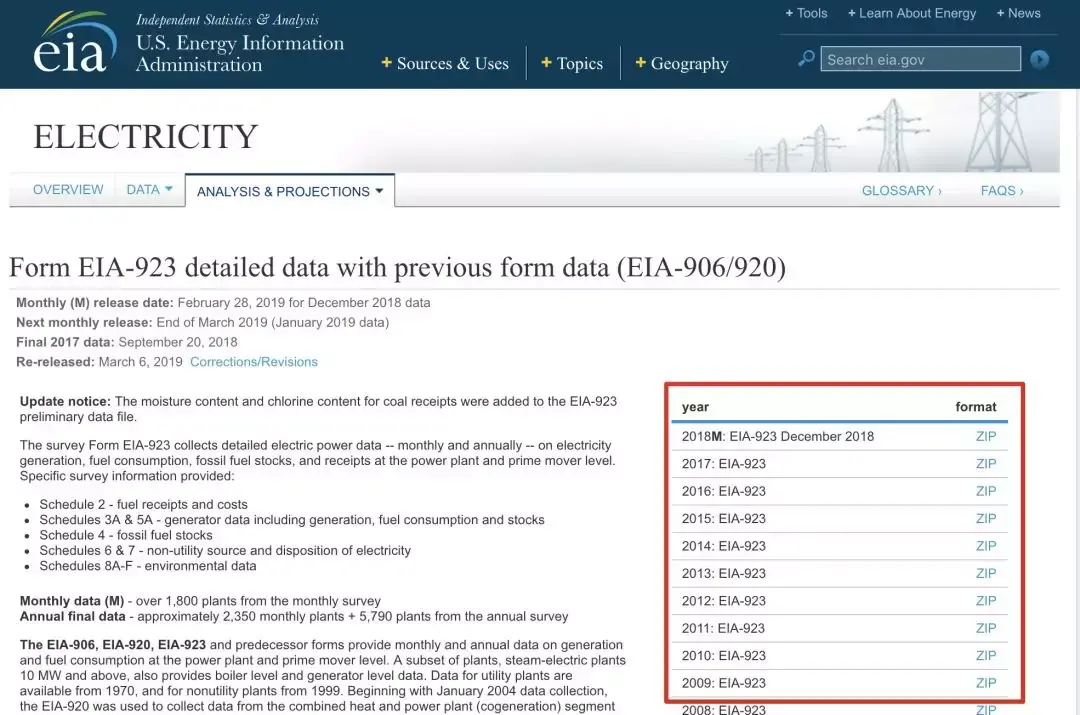
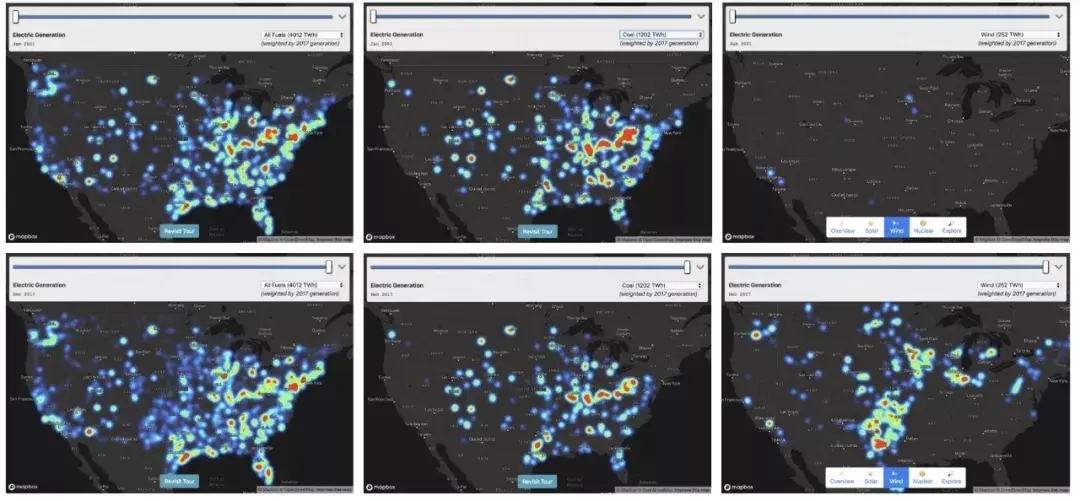
这些数据来自数万家工厂,包括小型热电厂、巨型煤电厂和核电站等,数据量非常大!我们推荐使用 Mapbox GL JS 的热力图,为每个工厂设置能源输出的“权重”。二话不说,先下为敬!
能源数据
- 下载从 2001 年到 2017 年一共 17 年的数据
- 导出为 CSV 格式
- 运行 源码 中的 csv_clean.sh 规范化数据,以便考虑一些小格式更改
发电厂位置数据
- 下载 2017 年发电厂位置数据
- 导出为 CSV 格式
准备好的数据应该是这样的
- [year]/netgen.csv (year 是 2001 - 2017)
- plant_locations.csv
第二步:将数据从 CSV 转化为 GeoJSON
下到了数据我们还需要把坐标和数据结合成为 GeoJSON 格式才能继续使用,运行
源码
中的 node create_geojson.js,则可以创建三个 GeoJSON 文件。
- plant_generation.geojson
- quarterly_generation.geojson
- plant_labels.geojson
我们将位置数据和能源数据通过“Plant ID”相互结合,并收集统计数据。
我们可以使用
Supertiler
将 GeoJSON 转化为 MBTiles,因为 Mapbox GL JS 使用了 Supercluster 进行聚类,如果您使用客户端制作地图并希望切换到服务器托管数据,Supertiler 可以方便直接转换。
第三步:创建地图
我们从 Mapbox 中国地图样式之一的深色地图开始着手吧!用下面的代码把我们准备好的 GeoJSON 文件添加为数据源。
map.addSource('plant-generation', {
"type": "geojson",
"data": "plant_generation.geojson"
});
另外,为了让放大地图的时候可以看到具体的建筑,我们也把卫星图源加入其中。
map.addSource('satellite', {
"type": "raster",
"url": "mapbox://mapbox.satellite",
"tileSize": 256
});
热力图层(中小放大等级)
在一般缩放等级下,我们使用
Heatmap 图层
展示数据热力图。
map.addLayer({
"id": "plant-generation",
"type": "heatmap",
"source": "plant-generation",
...
使用 runtime styling 让 heatmap-weight 跟随数据变化而动态变化,并且相邻插值带来平滑的效果。
map.setPaintProperty('generation-heatmap', 'heatmap-weight',
["/", ["+",
["*", ["to-number",
["get",`netgen_${base.year}_${base.quarter}`]], baseMix],
["*", ["to-number",
["get", `netgen_${next.year}_${next.quarter}`]], nextMix]], 2000000]);
我们还可以根据两个因素来设置 heatmap-intensity 和 heatmap-radius 的大小:一个是
缩放等级,
还有一个是
燃料类型
。在不改变热力图半径和强度的前提下,改变燃料的类型可能让热力图不饱和或过饱和(比如从气体转化为太阳能,会过饱和),我们需要一个权重 —— 强度加权值 —— 来解决这个问题。
为了为每种燃料计算强度加权值,我们使用第二步中的生成的聚类信息。
var intensityRatio = totalGeneration /
fuelTypeWeighting[fuelSelect.value];
map.setPaintProperty('plant-generation', 'heatmap-intensity',
"interpolate",
[ "exponential", 2 ], // Exponential intensity curve matches
[ "zoom" ], // exponential zoom curve
0, // At zoom 0:
intensityRatio, // Start with the base intensity
10, // By zoom 10:
10 * intensityRatio // Reach maximum intensity
]);
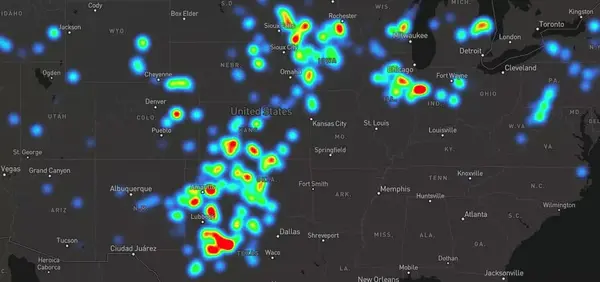
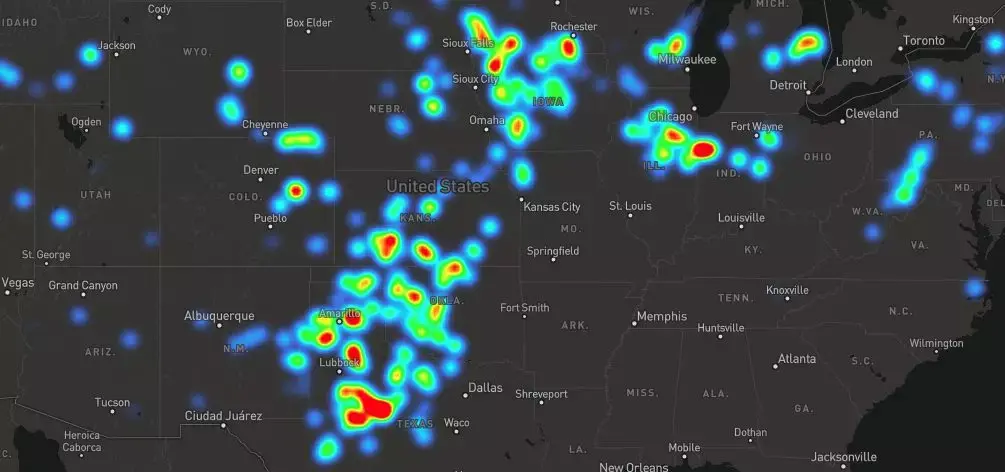
标记圆环(放大等级)
这里的目标是,能够直观地从查看国家/地区的能源模式,转化到地面的具体基础设施信息。我们尝试随着缩放等级渐进转换,具体步骤大概是这样的:
- 渐渐显示卫星图层
- 让热力图层渐渐消失,并用表示发电设施的独立圆环代替它们
- 用颜色代表不同的燃料类型,尺寸代表每月的产量、并且用标签显示17年来数据的名称、类型和总产量
第四步:开始讲故事!
在这一步,我们希望可以找到一个有趣的模式来探索地图,并且加入叙述模块。下面是一些可能的故事思路草稿:
- 碳能源的消耗 —— 关于二氧化碳减排
- 气能源的增加—— 通过挖掘深层的发电厂数据,我们惊讶地发现有很多媒转气工厂的现象发生。
- 太阳能的增加 —— 我们都知道阳光普照的加州富有太阳能,那么你知道北卡罗来纳州也有这样庞大的太阳能工厂吗?
- 风能的增加 —— 希望随着技术和经济的增长,不仅仅是“红色”州推行它,不再有党派因素的干扰。
- 水力发电的季节性 —— 有很大的潜力成为间歇性能源“电池”。
- 核能的停滞 —— 尽管太阳能和风能发展很快,但在无碳能源的角度来看还是规模太小了,核电依然是主导地位,并且只有少数掌握核心技术的国家可以使用。
我不断探索地图,看看哪个故事更能找到契合的场景,并把这些场景做成动态效果,并要保证足够简洁,以适应移动端用户的体验。
如果你不太擅长网页设计,可以考虑使用开源的
Bootstrap
,使用模版,帮助你提升排版和设计。
第五步:提升体验(GeoJSON 转化为 MBTiles)
我们目前还是用一个高达 27 MB 的 GeoJSON 文件,测试虽然没问题但是作为最终产品是远远不够的。所以我尝试绕道而行,把 GeoJSON 转化为 Mapbox 可以托管的 tileset。为了低放大程度的瓦片限制在每瓦片 500KB, 我们需要把临近的发电厂进行聚类。
第一个尝试,我们使用
Tippecanoe
, 使用类似下面的聚类参数。
tippecanoe -zg -o us_electricity_generation.mbtiles -r1 — cluster-distance=4 — accumulate-attribute=netgen_[year]_[month]:sum plant_generation.geojson
一般来说,为每个瓦片上在 4 个像素范围内的发电厂进行聚类,并且汇总每个月的子能源产量。这看起来非常简单快捷,但是实施的时候遇到了两个问题:
- Tippecanoe 通过寻找希伯尔曲线(Hilbert Curve)上的近邻点实现聚类。这在大数据集上十分有效,但是没有给足够的空间让我们去控制聚类的创建。而在这里,我希望聚类可以集中在最大的工厂处,热力图的权重在聚类之前和之后是相似的。
- 如果我将不同能源种类的工厂聚集在一起,想要计算单独的“聚合”发电特征,但是 Tippecanoe 的“sum”聚合算子不能帮我算出来。
于是,我又做了一次尝试,在客户端使用
Supercluster
进行相同的聚类。
map.addSource('plant-generation', {
"type": "geojson",
"data": "plant_generation.geojson",
"cluster": true,