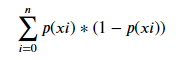clf = DecisionTreeClassifier(criterion='gini', max_depth=3)
clf.fit(X_train,y_train)
plt.figure(figsize=(12,10))
_ = tree.plot_tree(clf,filled=True,feature_names = feature_names)
plt.show()
输出
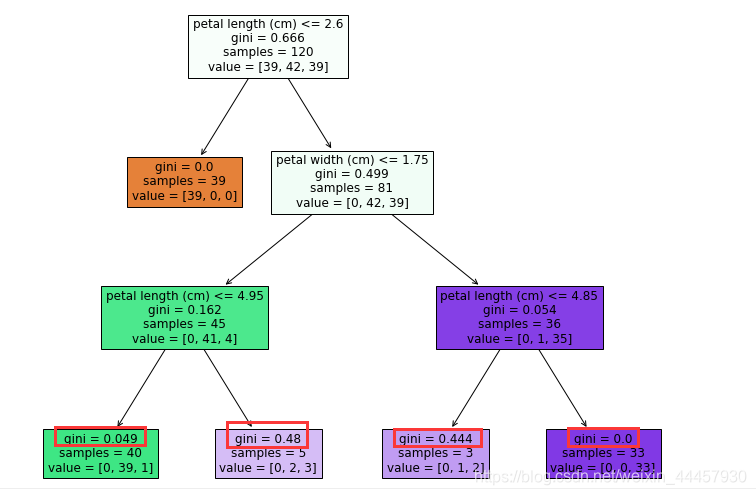
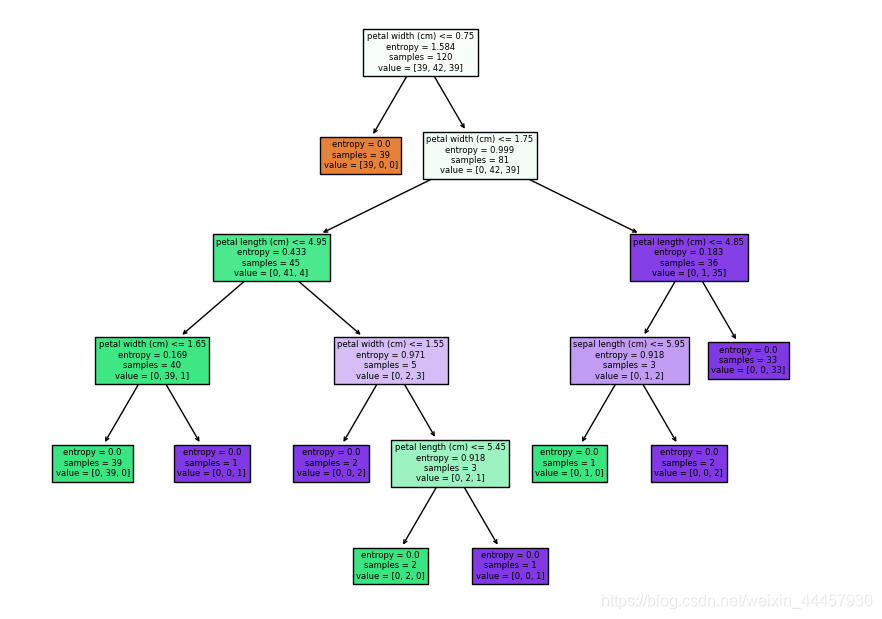
可以看到,由于限定了树的深度,使得叶子结点的基尼系数并非都为0,只有第二层的叶子结点基尼系数为0
决策树决策树的显示结果可以看到,满足petal width <= 0.75的样本,其三种标签值的样本数分别为[39, 0, 0],也就是说,只要满足这个条件,它的结果是确定的,因此交叉熵为0
本文于cnblogs,介绍了决策树的生成,Bagging策略,python实现代码等。首先,在了解树模型之前,自然想到树模型和线性模型有什么区别呢?其中最重要的是,树形模型是一个一个特征进行处理,之前线性模型是所有特征给予权重相加得到一个新的值。决策树与逻辑回归的分类区别也在于此,逻辑回归是将所有特征变换为概率后,通过大于某一概率阈值的划分为一类,小于某一概率阈值的为另一类;而决策树是对每一个特征做一个划分。另外逻辑回归只能找到线性分割(输入特征x与logit之间是线性的,除非对x进行多维映射),而决策树可以找到非线性分割。而树形模型更加接近人的思维方式,可以产生可视化的分类规则,产生的模型具
波士顿房价机器学习作业python编码,策树算法是一种逼近离散函数值的方法。它是一种典型的分类方法,首先对数据进行处理,利用归纳算法生成可读的规则和决策树,然后使用决策对新数据进行分析。本质上决策树是通过一系列规则对数据进行分类的过程。
决策树方法最早产生于上世纪60年代,到70年代末。由J Ross Quinlan提出了ID3算法,此算法的目的在于减少树的深度。但是忽略了叶子数目的研究。C4.5算法在ID3算法的基础上进行了改进,对于预测变量的缺值处理、剪枝技术、派生规则等方面作了较大改进,既适合于分类问题,又适合于回归问题。
决策树算法构造决策树来发现数据中蕴涵的分类规则.如何构造精度高、规模小的决策树是决策树算法的核心内容。决策树构造可以分两步进行。第一步,决策树的生成:由训练样本集生成决策树的过程。一般情况下,训练样本数据集是根据实际需要有历史的、有一定综合程度的,用于数据分析处理的数据集。第二步,决策树的剪枝:决策树的剪枝是对上一阶段生成的决策树进行检验、校正和修下的过程,主要是用新的样本数据集(称为测试数据集)中的数据校验决策树生成过程中产生的初步规则,将那些影响预衡准确性的分枝剪除。
今天的内容介绍如何将决策树模型画出来。进入实战部分!首先安装所需的R包,并且载入:install.packages("rpart")
install.packages("rpart.plot")
library(rpart)
library(rpart.plot)R包get!下一步,使用mtcars数据集建立一个决策树模型,其中的mpg作为因变量,代码如下:tree <- rpart(...
源代码:https://gitee.com/zhyantao/DeepLearning/tree/master/DecisionTree
使用工具Graphviz可视化决策树后,可以得到如下所示的一个PDF文件:
与之对应的CSV表格如...
决策树是机器学习的十大算法之一,可用于解决分类和回归问题。决策树的结构很像二叉树,通过一层一层的节点,来对我们的样本进行分类。决策树算法的可解释性非常的好,通过绘制决策树,我们可以很清楚理地解算法的工作原理,同时也方便向别人进行展示。这一节,我们的重点是画决策树,对于决策树算法的原理以及细节,我们不做深入的探讨。
我们使用iris数据集,它有150个样本,5个特征。接下来我们就以iris数据集为例,来进行决策树的绘制。
iris数据集链接:
链接:https://pan.baidu.com/s/1YCyvn
前言:在使用python绘制决策树的时候,需要使用到matplotlib库,要想使用matplotlib库可以直接安装anaconda就可以了,anaconda中包含了许多的python科学计算库。在使用决策树算法进行分类的时候,我们可以绘制出决策树便于我们进行分析。
对于在绘制决策树的时候使用中文显示出现乱码的时候,加下下面两句代码就可以正常显示
#用来正常显示中文
plt.rcParams
在这篇文章中,我们讲解了如何训练决策树,然后我们得到了一个字典嵌套格式的决策树结果,这个结果不太直观,不能一眼看着这颗“树”的形状、分支、属性值等,怎么办呢?
本文就上文得到的决策树,给出决策树绘制函数,让我们对我们训练出的决策树一目了然。
在绘制决策树之后,我们会给出决策树的使用方法:如何利用训练好的决策树,预测训练数据的类别?
提示:不论是绘制还是使用决策树,中心思想都是递归。
理论知识大部分参考七月在线学习笔记(很好,推荐)https://www.zybuluo.com/frank-shaw/note/103575
部分理论和编程主要参考《机器学习实战》
首先,要搞清楚决策树能做什么?
事实上,决策树学习是用于处理分类问题的机器学习方法,而这些类别事先是知道的,你只需要选择其中的某一个类作为你最终的决策即可,也就是说,决策树的学习是一个监督学...
决策树和随机森林是机器学习中经常使用的分类方法,可以通过matlab编程实现对图像的分类。
首先,对于决策树的图像分类代码,可以使用matlab中的ClassificationTree.fit函数构造决策树分类器,再使用predict函数对待分类的图像进行分类预测。具体步骤如下:
1. 读取图像数据,并将其转化为特征矩阵。
2. 将数据分为训练集和测试集。
3. 使用ClassificationTree.fit函数训练决策树分类器。
4. 使用predict函数对测试集进行分类预测。
5. 计算分类准确率。
对于随机森林的图像分类代码,也可以使用matlab中的随机森林工具箱实现。具体步骤如下:
1. 读取图像数据,将其转化为特征矩阵。
2. 将数据分为训练集和测试集。
3. 使用TreeBagger函数构造随机森林分类器,并使用train函数进行训练。
4. 使用predict函数对测试集进行分类预测。
5. 计算分类准确率。
总的来说,通过matlab中的机器学习工具箱和随机森林工具箱,可以轻松实现对图像的决策树和随机森林分类。需要注意的是,在选择属性特征和结构设计方面需要深入掌握机器学习相关知识,并进行充分的实验验证。