

C/C++基于Windows平台使用Visual Studio 2019学习笔记

第一章标准输入/输出库(I/O)的同异
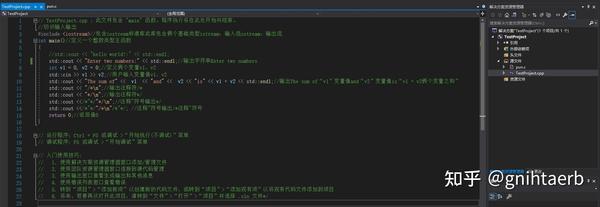

scanf_s:ANSI C中没有scanf_s(),只有scanf(),scanf()在读取时不检查边界,所以可能会造成内存访问越界,例如分配了5字节的空间但是读入了10字节
- char buf[5]={'\0'};
- scanf("%s", buf);如果输入1234567890,后面的部分会被写到别的空间上去。以上代码如果用scanf_s,第二行应改为scanf_s("%s",buf,5),表示最多读取5-1个字符,因为buf[4]要放'\0'
scanf_s最后一个参数是缓冲区的大小,表示最多读取n-1个字符.
vc++2005/2008中提供了scanf_s(),在最新的VS2019中也提供了scanf_s()。在调用时,必须提供一个数字以表明最多读取多少位字符。
3.读取单个字符也需要限定长度:scanf_s("%c,%c",&c1,1,&c2,1);而不能写成scanf_s("%c,%c",&c1, &c2,1, 1);否则编译器会报错
ANSI:ANSI是一种字符代码,为使计算机支持更多语言,通常使用 0x00~0x7f 范围的1 个 字节 来表示 1 个英文字符。超出此范围的使用0x80~0xFFFF来编码,即扩展的ASCII编码。
其他字符代码:在实际应用中接触比较多的文本编码有3种: ASCII 、ANSI和UNICODE,其中ASCII码是后两种也是大多数常用编码的基础。
ASCII码
文本编码方式的基础是ASCII码,它是一个7位的编码标准,包括26个小写字母、26个大写字母、10个数字、32个符号、33个控制代码和一个空格,共128个 代码 。由于计算机通常采用“字节”为单位存储和交换数据信息,因此很多计算机厂家对ASCII码进行了扩充,在原来的基础上又增加了128个附加字符,如ANSI、UNICODE等字符集。
UNICODE
对于 英文 来讲,ASCII码就足以编码所有字符,但对于中文,则必须使用两个字节来代表一个汉字,这种表示汉字的方式习惯上称为双字节。虽然双字节可以解决中英文字符混合使用的情况,但对于不同字符系统而言,就要经过字符码转换,非常麻烦,如中英、中日、日韩混合的情况。为解决这一问题,很多公司联合起来制定了一套可以适用于全世界所有国家的字符码,不管是东方文字还是西方文字,一律用两个字节来表示,这就是UNICODE。

字符:包括字母、数字、运算符号、标点符号和其他符号,以及一些功能性符号。字符在 计算机内存 放,应规定相应的代表字符的 二进制代码 。代码的选用要与有关外围设备的规格取得一致。这些外围设备包括键盘控制台的输入输出、打印机的输出等等。字符作输入时,要自动转换为二进制代码存于机内;输出时,计算机内二进制代码自动转化为字符,两者的转换全是靠外围设备实现的。字符是数据结构中最小的数据存取单位。通常由8个二进制位(一个字节)来表示一个字符,但也有少数计算机系统采用6个二进制的字符表示形式。一个系统中字符集的大小,完全由该系统自己规定。 [1] 计算机可用字符一般为128~256个(不包括汉字时),每个字符进入计算机后,都将转换为8位二进制数。不同的计算机系统和不同的语言,所能使用的字符范围是不同的。
在 ASCII 编码中,一个英文字母字符存储需要1个字节。在 GB 2312 编码或 GBK 编码中,一个 汉字 字符存储需要2个 字节 。在UTF-8编码中,一个英文字母字符存储需要1个字节,一个汉字字符储存需要3到4个字节。在UTF-16编码中,一个英文字母字符或一个汉字字符存储都需要2个字节(Unicode扩展区的一些汉字存储需要4个字节)。在UTF-32编码中,世界上任何字符的 存储 都需要4个字节。
字符串:字符串或串(String)是由数字、字母、下划线组成的一串字符。一般记为 s=“a1a2···an”(n>=0)。它是 编程语言 中表示文本的 数据类型 。在程序设计中,字符串(string)为符号或数值的一个连续序列,如符号串(一串字符)或二进制数字串(一串二进制数字)。
补充:字符串在存储上类似 字符数组 ,它每一位单个元素都是能提取的,字符串的 零位 是它的长度,如s[0]=10,这提供给我们很多方便,例如高精度 运算 时每一位都能转化为数字存入 数组 。
标识符:标识符由字母(A-Z,a-z)、数字(0-9)、下划线“_”组成,并且首字符不能是数字,但可以是字母或者下划线。例如,正确的标识符:abc,a1,prog_to。
- 不能把 C语言关键字 作为用户标识符,例如if,for,while等。
- 标识符长度是由机器上的 编译系统 决定的,一般的限制为8字符(注:8字符长度限制是C89标准,C99标准已经扩充长度,其实大部分工业标准都更长)。
- 标识符对大小写敏感,即严格区分大小写。一般对变量名用小写,符号常量命名用大写。
- 标识符命名 应做到 “ 见名知意 ” ,例如,长度(length),求和、总计(sum),圆周率(pi)……
C语言中把标识符分为三类: 关键字 , 预定义标识符 ,用户自定义标识符 。
C语言 中无参宏定义的一般形式为:#define 宏名 字符串。
其中的“#”表示这是一条 预处理命令 。凡是以“#”开头的均为预处理命令。“define”为 宏定义 命令。“标识符”为所定义的宏名。“字符串”可以是常数、 表达式 、格式串等。
C
结构化编程:一种编程典范。它采用 子程序 、程序码区块(英语:block structures)、 for循环 以及while循环等结构,来取代传统的 goto。希望借此来改善计算机程序的明晰性、品质以及开发时间,并且避免写出面条式代码。
面向过程编程:一种以过程为中心的编程思想。这些都是以什么正在发生为主要目标进行编程,不同于 面向对象 的是谁在受影响。与面向对象明显的不同就是 封装 、 继承 、 类 。简写为POP。
C++包含C
面向对象编程:一种新方法,其本质是以建立模型体现出来的抽象思维过程和 面向对象 的方法。模型是用来反映现实世界中事物特征的。任何一个模型都不可能反映客观事物的一切具体特征,只能对事物特征和变化规律的一种抽象,且在它所涉及的范围内更普遍、更集中、更深刻地描述客体的特征。通过建立模型而达到的抽象是人们对客体认识的深化。简写为OOP。
泛型编程:能够帮助实现一个通用的标准容器库。所谓通用的标准容器库,就是要能够做到,比如用一个 List 类存放所有可能类型的对象这样的事;泛型编程让你编写完全一般化并可重复使用的算法,其效率与针对某特定数据类型而设计的算法相同。泛型即是指具有在多种 数据类型 上皆可操作的含义,与模板有些相似。STL巨大,而且可以扩充,它包含很多计算机基本算法和 数据结构 ,而且将算法与数据结构完全分离,其中算法是泛型的,不与任何特定数据结构或对象类型系在一起。