


基于Python的英国电商数据分析



一、项目背景及目的
1.1 项目背景
该数据集为英国在线零售商在2010年12月1日至2011年12月9日在线零售的所有交易。分析其销售情况,以及客户的行为。
1.2 数据来源
1.3 研究的问题
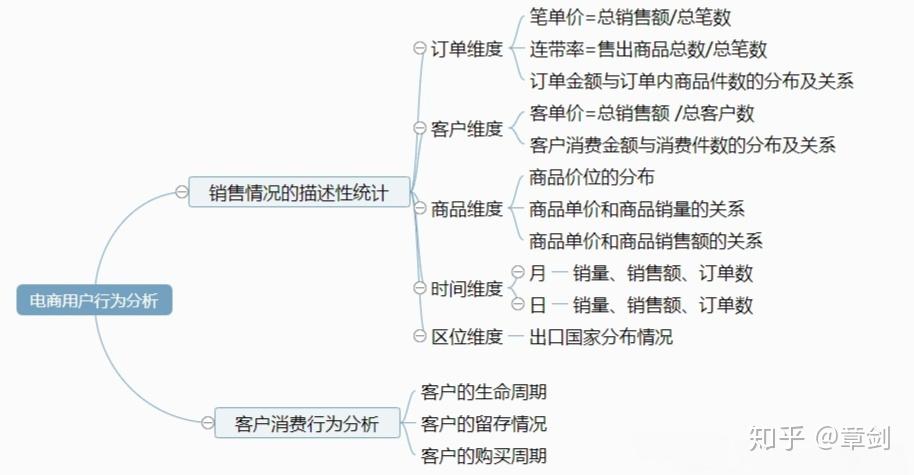
订单维度 :笔单价和连带率是多少?订单金额与订单内商品件数的关系如何?
客户维度 :客单价是多少?客户消费金额与消费件数的关系如何?
商品维度 :商品的价格定位是高是低?哪种价位的商品卖得好?哪种价位的商品带来了实际上最多的销售额?
时间维度 :各月/各日的销售情况是什么走势?可能受到了什么影响?
区域维度 :客户主要来自哪几个国家?哪个国家是境外主要市场?哪个国家的客户平均消费能力最强?
客户行为 :客户的生命周期、留存情况、购买周期如何?
根据上述问题按如下思路进行分析:

二、探索变量的内容
读取数据
df_initial = pd.read_csv('Online Retail.csv' )
print('Dataframe dimensions:', df_initial.shape)Dataframe dimensions: (541909, 8)
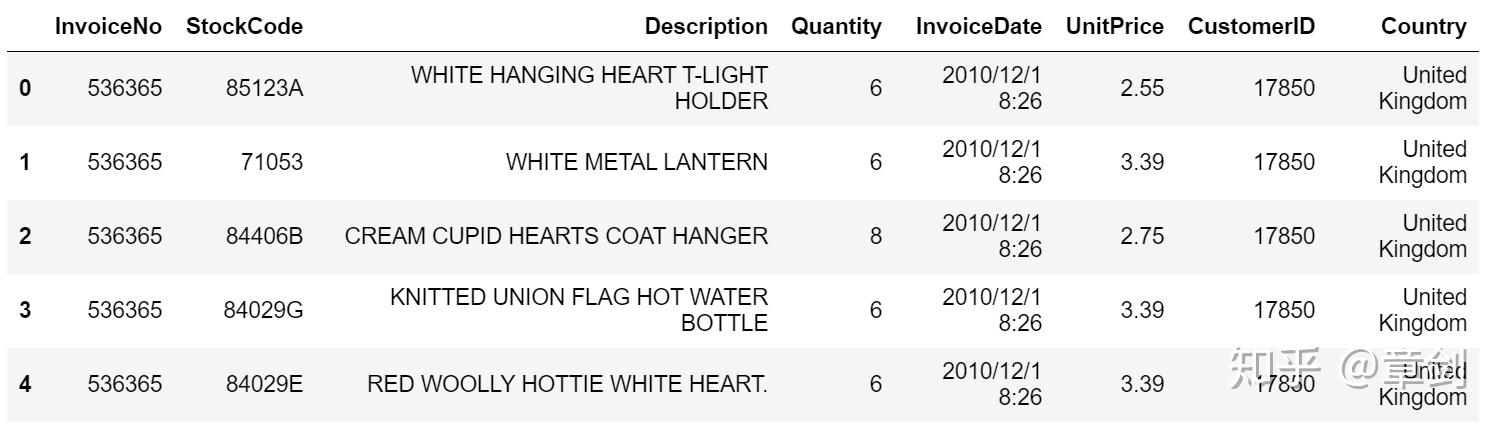
数据有54w行,8种特征分别是:
InvoiceNo:发票编号。为每笔订单唯一分配的6位整数。若以字母'C'开头,则表示该订单被取消。
StockCode:产品代码。为每个产品唯一分配的编码。
Description:产品描述。
Quantity:数量。每笔订单中各产品分别的数量。
InvoiceDate:发票日期和时间。每笔订单发生的日期和时间。
UnitPrice:单价。单位产品价格,单位为英镑。
CustomerID:客户编号。为每个客户唯一分配的5位整数。
Country:国家。客户所在国家/地区的名称2.1 缺失值处理
统计各个特征的数据类型、缺失值数量/占比
tab_info=pd.DataFrame(df_initial.dtypes).T.rename(index={0:'特征类型'})
tab_info=tab_info.append(pd.DataFrame(df_initial.isnull().sum()).T.rename(index={0:'缺失值数量'}))
tab_info=tab_info.append(pd.DataFrame(df_initial.isnull().sum()/df_initial.shape[0]*100).T.
rename(index={0:'缺失值占比'}))
display(tab_info)

# 展示数据
df_initial.head()
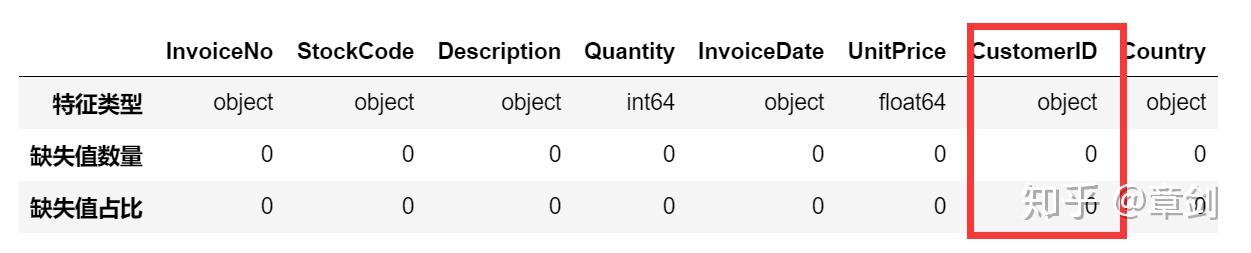
Description是商品的文字描述,不是我们的分析重点,存在1454个空值,不予处理。
CustomerID是客户的唯一编号,很重要,缺失了135080行,将近总行数的1/5。因无法确定缺失原因,所以把缺失值删除
df_initial.dropna(axis = 0, subset = ['CustomerID'], inplace = True)
print('Dataframe dimensions:', df_initial.shape)统计各个特征的数据类型、缺失值数量/占比
tab_info=pd.DataFrame(df_initial.dtypes).T.rename(index={0:'特征类型'})
tab_info=tab_info.append(pd.DataFrame(df_initial.isnull().sum()).T.rename(index={0:'缺失值数量'}))
tab_info=tab_info.append(pd.DataFrame(df_initial.isnull().sum()/df_initial.shape[0]*100).T.
rename(index={0:'缺失值占比'}))
display(tab_info)
Dataframe dimensions: (406829, 8),删除缺失值后剩下40.68W行数据
2.2 重复值处理
print('重复值数量: {}'.format(df_initial.duplicated().sum()))
检查出重复值数量为5225 ,然后删除重复值
df_initial.drop_duplicates(inplace = True)2.3 时间一致化处理
首先将InvoiceTime转为pandas能处理的时间格式datetime:
df_initial['InvoiceDate']=pd.to_datetime(df_initial['InvoiceDate'], errors='coerce')观察到字段InvoiceDate并非只包含了日期信息,同时也涵盖了具体的时分秒维度,故将其重命名为InvoiceTime:
# 列名重命名
df_initial.rename(columns={'InvoiceDate': 'InvoiceTime'}, inplace= True)添加新字段Date存放InvoiceTime中的日期部分:
df_initial['Date'] = pd.to_datetime(df_initial['InvoiceTime'].dt.date, errors='coerce')新增字段Month存放月份信息:
df_initial['Month'] = df_initial['InvoiceTime'].dt.month # 这样得到month依旧是一个整形数据由于我们对时间相关字段的操作有可能产生缺失值,再次查看缺失值情况:
df_initial.isnull().sum()检查结果显示,未出现缺失值
2.4 重新规整数字类型
将UnitPrice(单价)转为浮点型,Quantity(数量)和CustomerID(客户ID)转为整型:
df_initial['Quantity'] = df_initial['Quantity'].astype('int32')
df_initial['UnitPrice'] = df_initial['UnitPrice'].astype('float')
df_initial['CustomerID'] = df_initial['CustomerID'].astype('int32')
df_initial['InvoiceNo'] = df_initial['InvoiceNo'].astype('str') # 后面检查C字段订单的时候,发现这里需要是字符串类型增加字段SumPrice用于存放该行数据的总价:
# 计算总价
df_initial['SumPrice'] = df_initial['Quantity'] *df_initial['UnitPrice']
2.5 异常值处理
首先,查看查看总体的描述性统计情况:
df_initial.describe().T
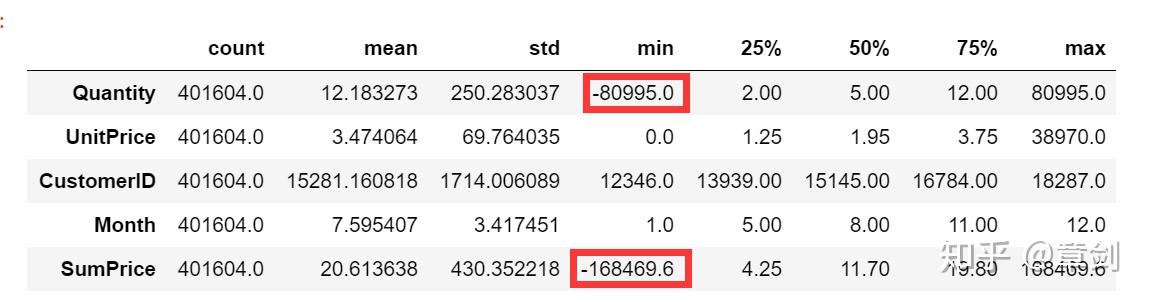
发现Quantity数量、SumPrice总价存在负值的情况,且绝对值较大。
总价是由数量和单价相乘得到,所以负的总价是产品数量为负值导致的。
#查看数量为负值的数据:
df_initial[(df_initial['Quantity'] <= 0)注意到主要是 是C字头订单(取消的订单)导致的负总价
2.5.1 C字头的取消订单
取消订单产生的负值,在销售情况的分析中会产生干扰。
考虑将数据分为只含成功订单和只含取消订单两部分。
需要探究取消订单是直接在原订单上进行的修改,还是用来抵消原订单的新增数据。
以上图第一行为例来说,即是否存在订单ID为536379,与订单ID为 C 536379对应。
将sales_df分为成功订单和取消订单两部分,划分依据是发票编号InvoiceNo是否含有“C”:
query_c = sales_df['InvoiceNo'].str.contains('C')
# 只含取消订单
sales_cancel = sales_df.loc[query_c,:].copy()
# 只含成功订单
sales_success = sales_df.loc[-query_c,:].copy()为sales_cancel增加字段SrcInvoiceNo,用于存放去掉“C”的发票编号:
# 增加原订单号
sales_cancel['SrcInvoiceNo'] = sales_cancel['InvoiceNo'].str.split('C', expand=True)[1]
将sales_cancel和sales_success进行合并:
print('merge之前,sales_cancel的shape为:{}'.format(sales_cancel.shape))
print('merge之前,sales_success的shape为:{}'.format(sales_success.shape))
new_data = pd.merge(sales_cancel, sales_success, left_on='SrcInvoiceNo',right_on='InvoiceNo')
print('merge之后,new_data的shape为:{}'.format(new_data.shape))merge之前,sales_cancel的shape为:(8872, 12)
merge之前,sales_success的shape为:(392732, 11)
merge之后,new_data的shape为:(0, 23)
可以确认发现取消订单和成功订单并无对应关系。
原来的536641行数据中,取消订单占了8872,行。
2.5.2 单价为0的免费订单
推测单价为0的订单是促销活动的赠品,对于订单量、件单价、连带率等指标的计算造成干扰,故也单独分出一张表存放,之后再对免费订单进行分析:
query_free = sales_success['UnitPrice'] == 0
# 只含免费订单
sales_cancel = sales_success.loc[query_free,:].copy()
# 只含普通订单
sales_success = sales_success.loc[-query_free,:]
sales_success.describe().T三、分析与可视化
3.1 销售情况的描述性统计
3.1.1 订单维度
首先将sales_success按订单号分组,对Quantity商品数量和SumPrice总价分组求和:
invoice_grouped = sales_success.groupby('InvoiceNo')[['Quantity','SumPrice']].sum()通过describe获得笔单价(每笔订单的平均交易金额)和连带率(每笔订单平均购买的产品件数):
笔单价 = 总销售额 / 总笔数
连带率 = 售出商品总数 / 总笔数
invoice_grouped.describe()

统计区间(2010年12月1日-2011年12月9日)内共产生有效订单18532笔
笔单价 为479.56英镑, 连带率 约为278件,说明以批发性质的订单为主
订单交易金额和订单内商品件数,其均值都高于中位数
订单交易金额的均值甚至高于Q3分位数
说明订单总体差异大,存在部分购买力极强的客户
接下来绘制订单交易金额的分布图:
invoice_grouped['SumPrice'].hist(bins = 100, figsize = (12, 4), color = 'g')
plt.title('SumPrice Distribution of Orders')
plt.ylabel('Frequency')
plt.xlabel('SumPrice')
plt.rcParams['savefig.dpi'] = 300
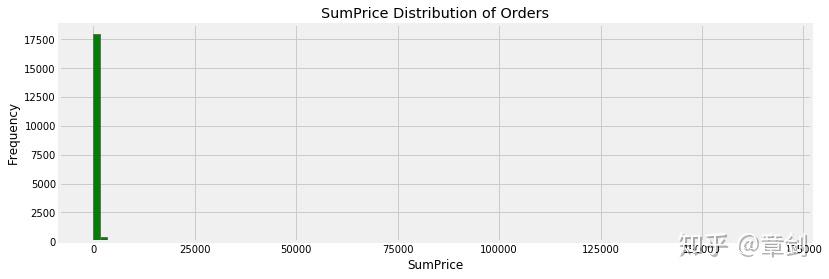
部分订单交易金额过大,影响图表的可读性,筛去1000英镑及以上的订单:
invoice_grouped[invoice_grouped.SumPrice < 1000]['SumPrice'].hist(bins = 100, figsize = (12, 4), color = 'g')
plt.title('SumPrice Distribution of Orders (Below 500)')
plt.ylabel('Frequency')
plt.xlabel('SumPrice')g
plt.rcParams['savefig.dpi'] = 300
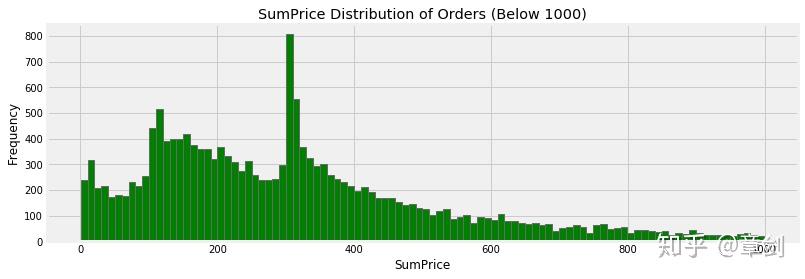
对订单内商品数量的分布同样绘制柱形图,并筛去2000件及以上的订单:
invoice_grouped[invoice_grouped.Quantity < 2000]['Quantity'].hist(bins = 50, figsize = (12, 4), color = 'g',alpha=0.7)
plt.title('Quantity Distribution of Orders (Below 2000)')
plt.ylabel('Frequency')
plt.xlabel('Quantity')
plt.rcParams['savefig.dpi'] = 300
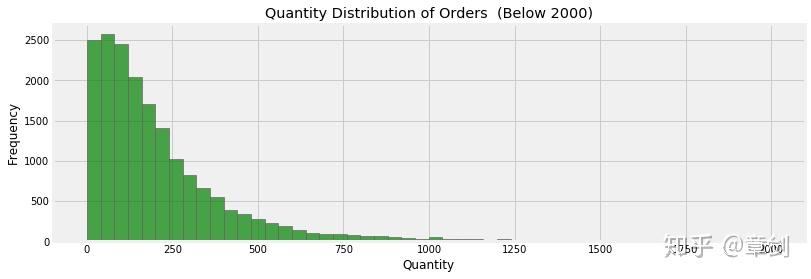
订单内的商品数量呈现出很典型的 长尾分布 ,大部分订单的商品数量在250件内,商品数量越多,订单数相对越少
为了进一步探究订单交易金额与订单内商品件数的关系,我们绘制散点图:
plt.figure(figsize=(14,4))
# plt.subplot用于绘制子图,121表示分成1*2个图片区域,占用第一个。
plt.subplot(121)
plt.scatter(invoice_grouped['Quantity'], invoice_grouped['SumPrice'], color = 'g')
plt.title('SumPrice & Quantity')
plt.ylabel('SumPrice')
plt.xlabel('Quantity')
# 筛去商品件数在20000及以上的订单
plt.subplot(122)
plt.scatter(invoice_grouped[invoice_grouped.Quantity < 20000]['Quantity'], invoice_grouped[invoice_grouped.Quantity < 20000]['SumPrice'], color = 'g')
plt.title('SumPrice & Quantity (Quantity < 20000)')
plt.ylabel('SumPrice')
plt.xlabel('Quantity')
plt.show()
plt.rcParams['savefig.dpi'] = 300
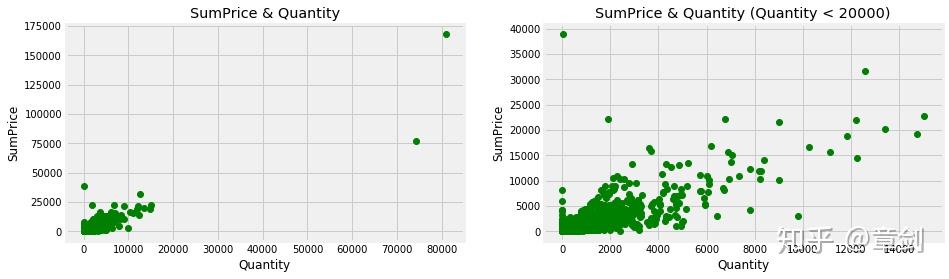
总体来说订单交易金额与订单内商品件数是 正相关 的,订单内的商品数越多,订单金额也相对越高。但在Quantity靠近0的位置也有若干量少高价的订单,后续可以试探究。
3.1.2 客户维度
统计各个客户的订单数量、消费金额和商品购买数。
常用方法:
(1) 先按客户ID和订单编号分组
(2)对同笔订单的商品数量和销售金额求和;
(3)再用reset_index重设索引;最后再按客户ID分组:
#(1) 先按客户ID和订单编号分组
#(2) 对同笔订单的商品数量和销售金额求和;
customer_grouped = sales_customer.groupby(['CustomerID','InvoiceNo'])['Quantity', 'SumPrice'].sum()
#(3)再用reset_index重设索引;最后再按客户ID分组:
customer_grouped.reset_index(['InvoiceNo'],inplace=True)
customer_grouped.head() 
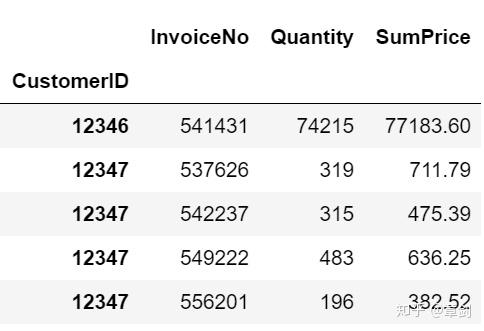
customer_grouped.groupby('CustomerID')[['Quantity', 'SumPrice']].sum().describe()
customer_grouped.groupby('CustomerID')[['InvoiceNo']].count().describe()
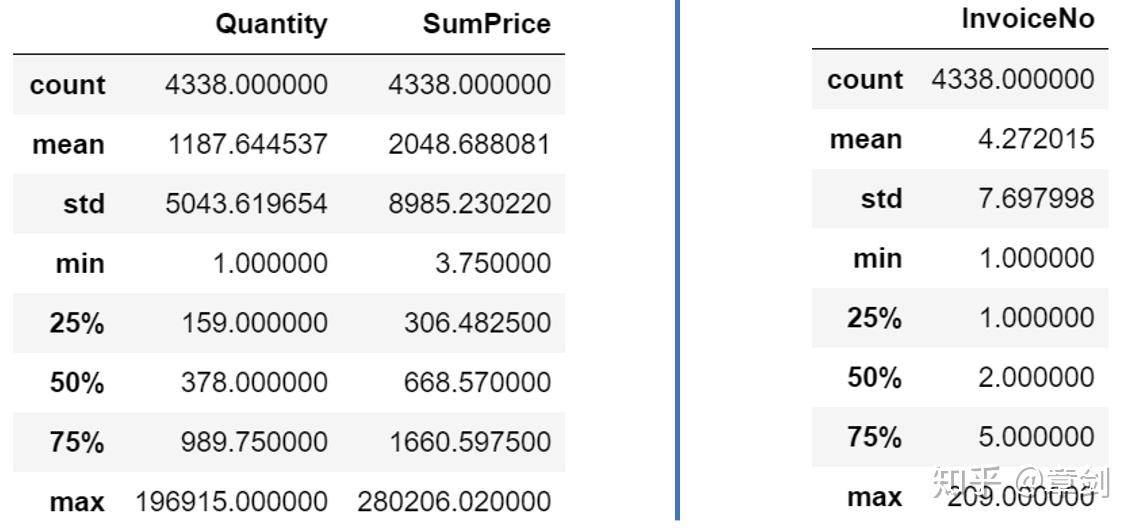
人均购买笔数为4笔,中位数为2笔,25%以上的客户仅下过一次单,并未留存。每位客户平均购买了1187件商品,甚至超过了Q3分位数989.7件。客户购买最大的件数为196915件;客单价为2049英镑,平均值同样超过了Q3分位数。
说明客户的购买力存在较大差距,存在小部分的高消费用户拉高了人均数值。
进一步观察客户消费金额的分布:
customer_grouped.SumPrice.hist(bins = 50, figsize = (12, 4), color = 'g')
plt.title('SumPrice Distribution of Customers')
plt.ylabel('Frequency')
plt.xlabel('SumPrice')
plt.show()
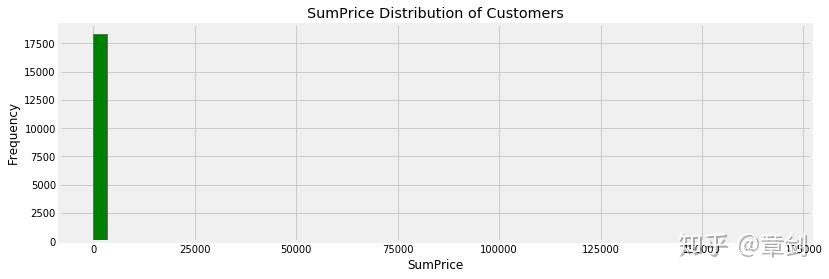
从直方图看,大部分用户的消费能力确实不高,高消费用户在图上几乎看不到。这也确实符合消费行为的行业规律。
截取消费额5000英镑以内的客户
plt.figure()
customer_grouped[customer_grouped.SumPrice < 5000].SumPrice.hist(bins = 60, figsize = (12, 4), color = 'g')
plt.title('SumPrice Distribution of Customers (Below 5000)')
plt.ylabel('Frequency')
plt.xlabel('SumPrice')
plt.show()
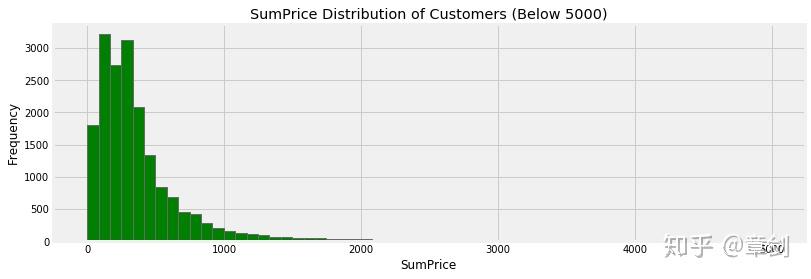
与前面订单金额的多峰分布相比,客户消费金额的分布呈现单峰 长尾形态 ,金额更为集中,峰值在83-333英镑间。
绘制客户消费金额与消费件数的散点图:

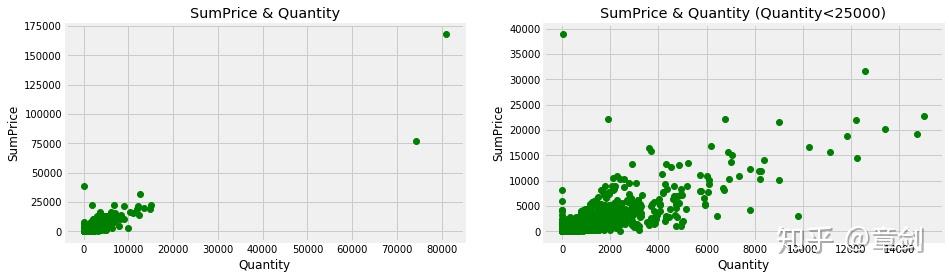
客户群体比较健康,而且规律性比订单更强,同时拥有一定数量消费能力强的用户。总体来说客户的消费金额与购买的商品数量是正相关的,客户购买的东西越多,消费金额相对就越高。
3.1.3 商品维度
根据观察,发现相同的商品在不同的订单中单价存在折扣,可知商品的单价会发生波动
接下来求每件商品的平均价格,思路是:
平均价格=该商品的总销售额 / 该商品的销售数量
具体来说,先按商品编号进行分组,对数量和总价分别求和,即得到对应商品的总销售金额和总销售量,取商即得到平均价格:
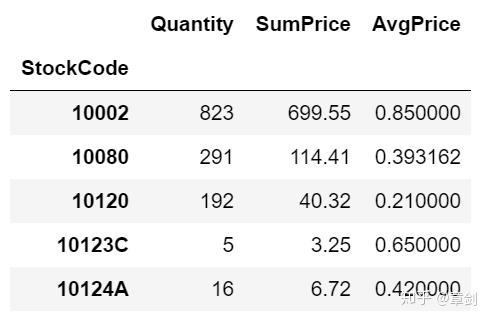
goods_grouped = sales_success.groupby('StockCode')[['Quantity', 'SumPrice']].sum()
goods_grouped['AvgPrice'] = goods_grouped['SumPrice'] / goods_grouped['Quantity']
goods_grouped.head()
查看所有商品AvgPrice的分布,观察这家店的价格定位:
goods_grouped.AvgPrice.hist(bins=100)
plt.title('AvgPrice Distribution')
plt.ylabel('Frequency')
plt.xlabel('SumPrice')
plt.show()
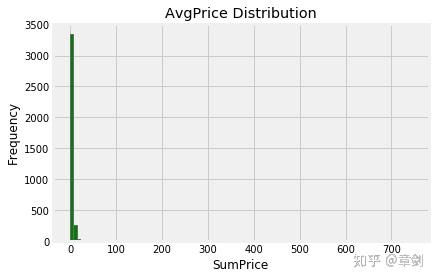
发现商品价位基本上全部集中在100英镑内,出现了极少量的天价商品影响观测,将其筛去,观察100英镑以内的商品的均价分布:
plt.figure()
goods_grouped[goods_grouped.AvgPrice < 100].AvgPrice.hist(bins=100,figsize = (12, 4),color='g')
plt.title('AvgPrice Distribution (Below 100)')
plt.ylabel('Frequency')
plt.xlabel('SumPrice')
plt.show()
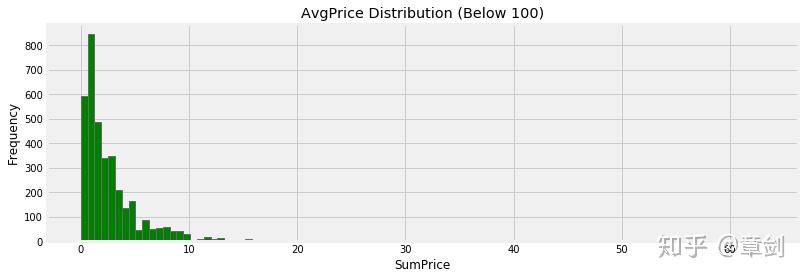
峰值是1-2英镑,单价10英镑以上的商品已经很少见,看来该电商的定位主要是价格低的小商品市场。
接下来查看商品单价和商品销量的散点图,可以看出哪种价位的商品更受欢迎:
# 商品单价和销售数量的散点图
plt.figure(figsize=(14,4))
plt.subplot(121)
plt.scatter(goods_grouped['AvgPrice'], goods_grouped['Quantity'], color = 'b')
plt.title('AvgPrice & Quantity')
plt.ylabel('Quantity')
plt.xlabel('AvgPrice')
plt.subplot(122)
plt.scatter(goods_grouped[goods_grouped.AvgPrice < 50]['AvgPrice'], goods_grouped[goods_grouped.AvgPrice < 50]['Quantity'], color = 'b')
plt.title('AvgPrice & Quantity (AvgPrice < 50)')
plt.ylabel('Quantity')
plt.xlabel('AvgPrice')
plt.show()
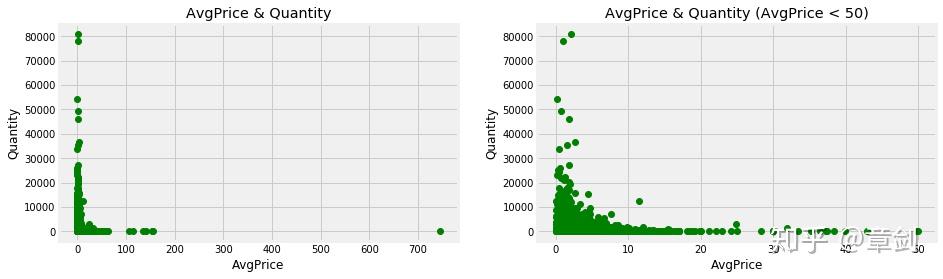
从商品的销量上来看,毫无疑问是低于5英镑的低价区商品大获全胜,受到了客户们的喜爱。
那么是否价格低廉的商品也带来了实际上最多的销售额呢?不妨绘制商品单价和商品总销售额的散点图:

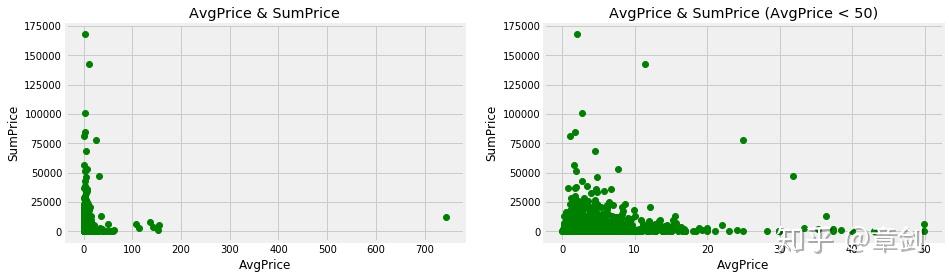
低价区的商品笑到了最后,不仅在销售数量上一骑绝尘,也构成了销售额的主要部分;高价的商品虽然单价高昂,但销量很低,并没有带来太多的销售额。据此,建议平台采购部门可以多遴选售价低于10英镑的产品,来进一步扩充低价区的品类。
3.1.4 时间维度
按订单号分组,提取出我们需要的信息:
time_grouped = sales_success.groupby('InvoiceNo').agg({'Date': np.min, 'Month': np.min, 'Quantity': np.sum, 'SumPrice': np.sum}).reset_index()#这里Date和Month取最小值或最大值都可以,因为都是相同的。(这是同一个订单,时间当然相同)
以月份为单位进行折线图绘制,这里对Quantity和SumPrice分组求和,代表每月的销量和销售额,对InvoiceNo计数,代表每月的订单数。此处采用双坐标图,销量和销售额为左轴,参数secondary_y = 'InvoiceNo’表示订单数为右轴:
month = time_grouped.groupby('Month').agg({'Quantity': np.sum, 'SumPrice': np.sum, 'InvoiceNo': np.size}).plot(secondary_y = 'InvoiceNo', x_compat=True, figsize = (12, 4))
month.set_ylabel('Quantity & SumPrice')
month.right_ax.set_ylabel('Order quantities')
plt.show()
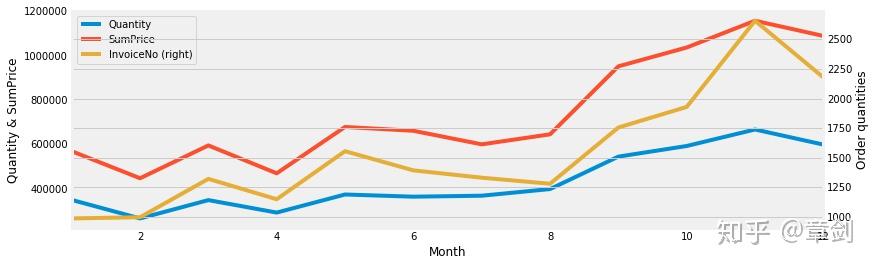
需要注意此处2011年12月仅统计了前9天,如果全月能基本保持前9天的销售情况,销售额会远超2010年同期。
观察到三条折线总体上呈现相近的趋势,除了2011年2月和4月略低外,2010年12月至2011年8月基本维持相近的销售情况;随后在9月-11月连续增长,达到高峰。考虑该电商平台主营礼品,受节日影响可能较大。欧洲重视的万圣节(11月1日)和圣诞节(12月25日)都在年末,与图中的趋势能够相呼应;同时虽然感恩节(11月第4个周四)是美国节日,但“黑五”的营销方式对全球都产生了一定影响。
将日期设为索引,按日绘制折线图:
plt.figure()
time_grouped = time_grouped.set_index('Date')
day = time_grouped.groupby('Date').agg({'Quantity': np.sum, 'SumPrice': np.sum, 'InvoiceNo': np.size}).plot(secondary_y = 'InvoiceNo', figsize = (15, 5))
day.set_ylabel('Quantity & SumPrice')
day.right_ax.set_ylabel('Order quantities')
plt.show()
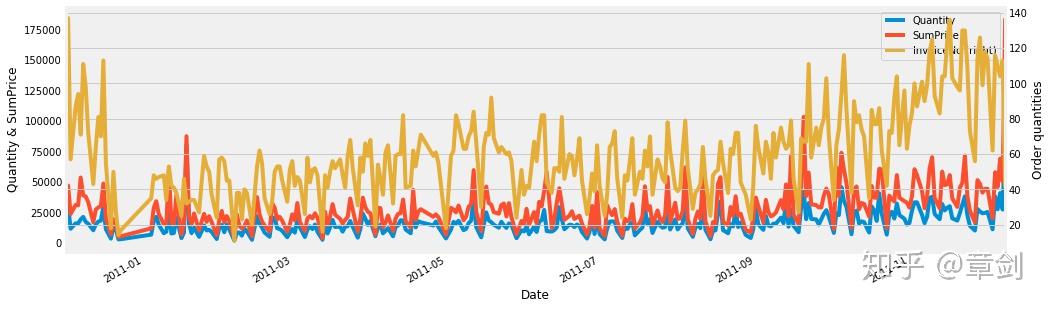
可见销量Quantity和销售额SumPrice的趋势是极趋同的,这也和前一节中分析出该电商以低价商品为主相吻合,商品单价低且价位集中,则销售额主要随销量变化而涨跌。
注意到在最后一天(即2011年12月9日),销量、销售额显著激增,放大看看:
# 节取2011年10月1日至2011年12月9日
plt.figure()
day_part = time_grouped['2011-10-01':'2011-12-09'].groupby('Date').agg({'Quantity': np.sum, 'SumPrice': np.sum, 'InvoiceNo': np.size}).plot(
secondary_y = 'InvoiceNo', figsize = (15, 5))
day_part.set_ylabel('Quantity & SumPrice')
day_part.right_ax.set_ylabel('Order quantities')
plt.show()
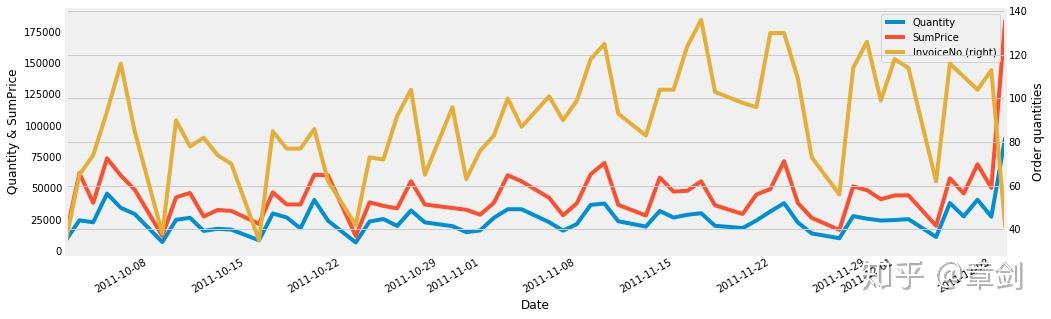
2011年12月的前8天基本延续了11月下旬的销售趋势,但在12月9日订单量大幅下降时,却创造了样本区间内销量和销售额的历史新高。说明存在某笔或某几笔购买量极大的订单,从而使得销售额大幅上升。
将当日的销售详单拉取出来:
sales_success[sales_success.Date == '2011-12-09'].sort_values(by='SumPrice', ascending=False).head()
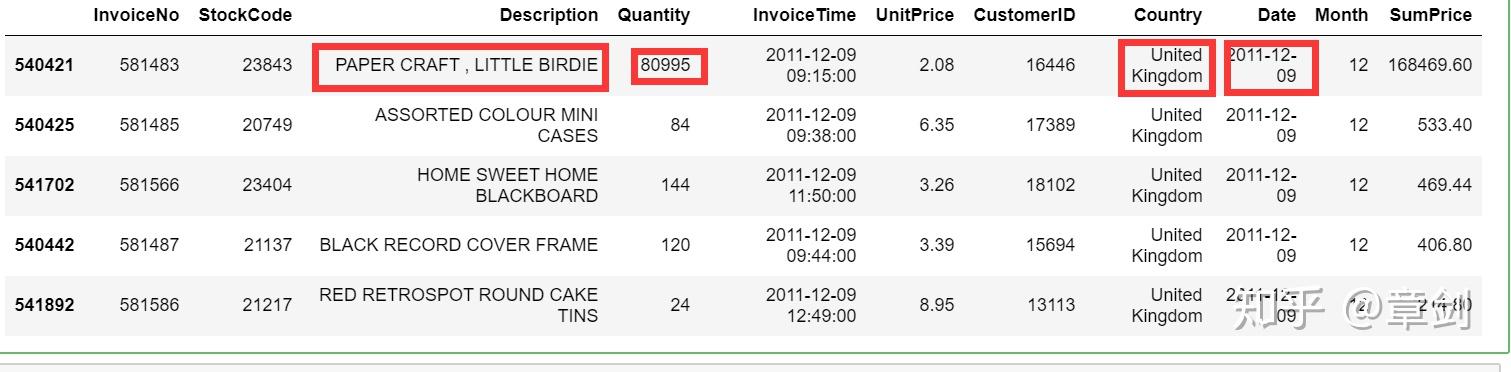
有一个英国的客户,购买了8万余件的纸工艺品,贡献了168469.60英镑的销售额。
建议对大客户配备固定客服,好及时获知对方的需求与意见,并增加客户的认同感。
不过反过来说,12月之后的20余天应该是无法保持这么迅猛的销售势头了。
3.1.5 区位维度
3.1.5.1 各国的订单量分布
查看订单中用户所在的国家有几个
temp = df_initial[['CustomerID', 'InvoiceNo', 'Country']].groupby(['CustomerID', 'InvoiceNo', 'Country']).count()
temp = temp.reset_index(drop = False)
countries = temp['Country'].value_counts()
print('数据中的国家数目: {}'.format(len(countries)))数据中的国家数目: 37
利用tableau查看各国家的客服下单量

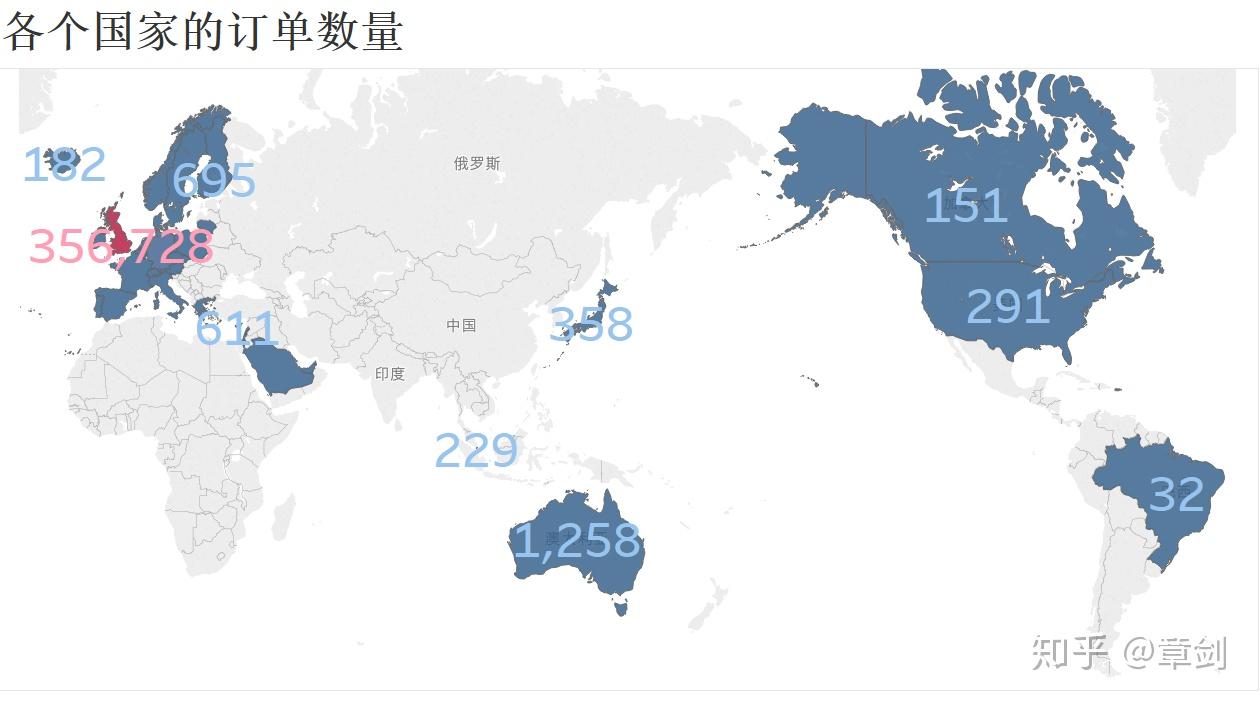


可知绝大部分客户仍来自英国本土,主要境外收入来源也多为 英语系国家 ,基本上符合以英国为圆心向外辐射的情况。这种现象可能和运输成本及语言等有关,也可能是影响力随距离而衰减,可以尝试增加境外的宣传投放,提高知名度;同时建议网站做好多国语言的适配,也可以在网站上对于境外物流费用计算及手续办理等事项给出更易懂的说明。
3.1.5.2 各国的客户和销售额分布
首先提取出一张客户ID及其国家的关系表,按客户分组,计算消费总额。将上述两张表合并,按国家再次分组,计算出各国客户的消费总额和客户总数,新增AvgAmount字段,用于存放该国家客户的人均消费金额,对消费总额降序排列
sales_country = sales_success.drop_duplicates(subset=['CustomerID', 'Country'])[['CustomerID', 'Country']]
country_grouped = sales_success.groupby('CustomerID')[['SumPrice']].sum().reset_index()
country_grouped = pd.merge(country_grouped, sales_country, left_on='CustomerID', right_on='CustomerID')
country_grouped = country_grouped.groupby('Country').agg({'SumPrice': np.sum, 'CustomerID': np.size})
country_grouped['AvgAmount'] = country_grouped['SumPrice'] / country_grouped['CustomerID']
country_grouped.sort_values(by='SumPrice',ascending=False).head(20)

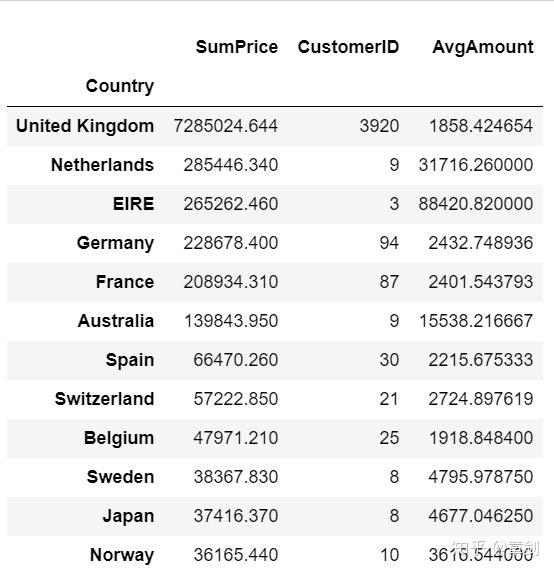
可知绝大部分客户仍来自英国本土,主要境外收入来源也多为英国周边国家,基本上符合以英国为圆心向外辐射的情况。这种现象可能和运输成本及语言等有关,也可能是影响力随距离而衰减,可以尝试增加境外的宣传投放,提高知名度;同时建议网站做好多国语言的适配,也可以在网站上对于境外物流费用计算及手续办理等事项给出更易懂的说明。
3.2 客户消费行为分析
3.2.1 客户的生命周期
其实样本中的客户有许多未进行完整的生命周期 ,我们并不知道在统计时段前他们是否购买过,也不知道在统计时段后他们中的哪些会继续购买。所以这里计算的生命周期是有局限性的,真实的客户平均生命周期必然会更长。
查看用户的初次与末次(最近)消费时间:
# 客户的初次消费时间
mindate = df_initial.groupby('CustomerID')[['Date']].min()
# 客户的末次消费时间
maxdate = df_initial.groupby('CustomerID')[['Date']].max()查看用户的初次/末次消费集中在哪些日期:
maxdate['Date'].value_counts().head(10)
maxdate['Date'].value_counts().head(10)发现初次消费的高频日期为统计时段的初期,末次消费的高频日期为统计时段的末期。说明有大量用户的生命周期被低估,实际上还要向前向后延伸。
末次消费日期减去初次消费日期得到统计时段内的生命周期,展示前5行:
(maxdate - mindate).head()0 days表示该客户只在某一天内消费过,未能留存。
再看一下客户生命周期的总体情况:
life_time = maxdate - mindate
life_time.describe()共有4372个有CustomerID的客户,其平均生命周期为133天,中位数则是98天,说明有部分生命周期很长的忠实客户拉高了均值;而最小值和Q1分位数都为0天,说明存在25%以上的客户仅消费了一次,生命周期的分布呈两极分化的状态。
接下来,绘制柱形图观察客户生命周期的实际分布。
这里的时间差是timedelta类型,无法绘制柱形图, 将其先转化为数值:
life_time['life_time'] = life_time['Date'].dt.days # .dt.days提取出来就是数值了!绘制20个分组的柱形图:
life_time['life_time'].hist(bins=20, color='g')
plt.title('Life Time Distribution')
plt.ylabel('Customer number')
plt.xlabel('Life time (days)')
plt.show()
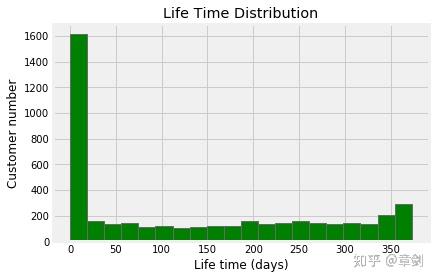
横坐标代表生命周期的天数区间,纵坐标为区间内的客户数。
许多客户仅消费过一次,没有留存下来,需要更加重视客户初次购买的体验感,可以考虑通过网站内服务评价、客服电询等方式获知新客对于购买流程中不满意之处,针对性地加以改进;同时应该对新客采取吸引其二次购买的手段,如发放有时限的优惠券等。有趣的是在350天左右出现一个次高峰,不妨将生命周期为0天的客户排除掉再看看分布:
将分组增多至100,并拉宽图表的尺寸
plt.figure()
life_time[life_time['life_time'] > 0].life_time.hist(bins = 100, figsize = (12, 6), color = 'g')
plt.title('Life Time Distribution without One-time Deal Hunters')
plt.ylabel('Customer number')
plt.xlabel('Life time (days)')
plt.show()
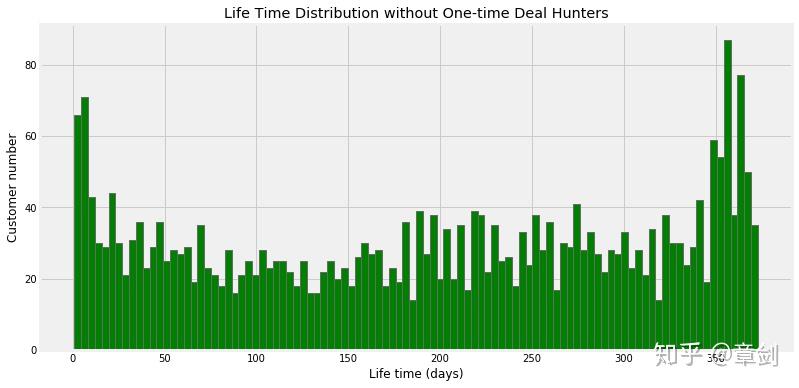
生命周期在0-75天的客户数略高于75-170天,可以考虑加强前70天内对客户的引导。约1/4的客户集中在170天-330天,属于较高质量客户的生命周期;而在330天以后,则是数量可观的死忠客户,拥有极高的用户粘性。考虑到这些客户中有许多未进行完整的生命周期 ,实际的客户平均生命周期会更长。
消费两次及以上的用户平均生命周期
life_time[life_time['life_time']>0].life_time.mean()消费两次及以上的用户平均生命周期是195天,远高于总体均值133天。从策略看,用户首次消费后应该花更多的精力引导其进行多次消费,能有效提高生命周期
3.2.2 客户的留存情况
客户的生命周期实际上是首次和末次消费的时间差,故无法对客户各月的消费情况获得直观的感受。因此接下来我们对客户的留存情况展开探究。这里需要说明的是,同样由于样本统计区间的缘故,我们无法判断2010年12月1日至2011年12月9日内的首次消费是否是该客户的历史首次消费。
先将用户首次消费日期合并进sales_customer中,suffixes参数是对重名的字段自定义后缀:
customer_retention = pd.merge(sales_customer, mindate, left_on='CustomerID', right_index=True, how='inner', suffixes=('','Min'))新增字段DateDiff,用于存放本次消费日期与首次消费日期的时间差,并转为数值:
customer_retention['DateDiff'] = (customer_retention.Date - customer_retention.DateMin).dt.days对时间差分段,我这里将3天、7天、30天、60天、90天、180天作为区间端点,并新增字段DateDiffBin来存放:
date_bins = [0, 3, 7, 30, 60, 90, 180]
customer_retention['DateDiffBin'] = pd.cut(customer_retention.DateDiff, bins = date_bins)
customer_retention['DateDiffBin'].value_counts()DateDiffBin代表客户该笔订单的消费时间距其首次消费属于哪个时间段。因为计算的是留存,如果客户仅消费了一次(当日多次消费也视作一次),我们认为该客户是流失了的,这里DateDiff=0,并不会被划分入(0, 3]天的开闭区间内。
接下来用pivot_table作数据透视表,这里index相当于数据透视表的行,columns相当于列,values表示聚合对象,aggfunc表示聚合方法。对SumPrice求和,获得的结果是客户首次消费后,在后续各时间段内的消费总金额:
retention_pivot = customer_retention.pivot_table(index = ['CustomerID'], columns = ['DateDiffBin'], values = ['SumPrice'], aggfunc= np.sum)
print(retention_pivot)NaN表示该客户在该区间内未进行过消费,聚合值全为NaN的客户会被过滤,即透视表中全为消费2次及以上的留存客户。
将数据转换成是否,1代表在该时间段内有后续消费,0代表没有:
retention_pivot_trans = retention_pivot.fillna(0).applymap(lambda x:1 if x > 0 else 0)