代码实现一遍这个大佬的过程:https://amberwest.github.io/2019/03/05/%E5%88%A0%E9%99%A4DataFrame%E4%B8%AD%E6%9F%90%E5%88%97%E5%80%BC%E4%B8%BANaN%E7%9A%84%E8%AE%B0%E5%BD%95-%E8%A1%8C/
import pandas as pd
import numpy as np
input_rows = [[1,2,3], [2,3,4], [np.nan, 2, np.nan, 5], [np.nan, 5, 7]]
df = pd.DataFrame(input_rows, columns=['a', 'b', 'c', 'd'])
1.过滤某一列没有nan的数据。~取反
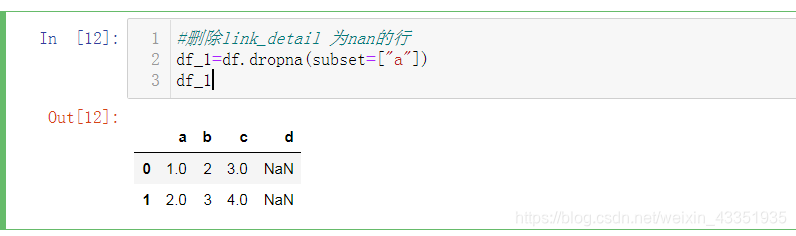
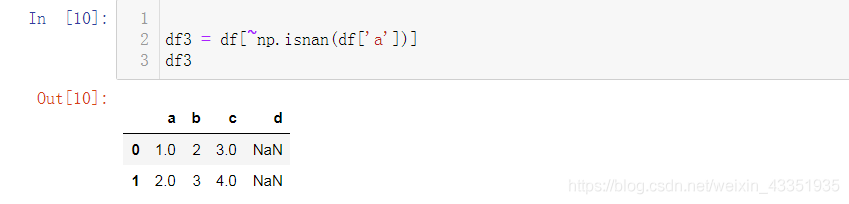
2.使用numpy.isnan
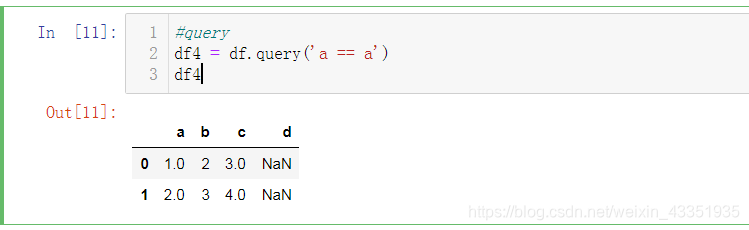
3.使用query
代码实现一遍这个大佬的过程:https://amberwest.github.io/2019/03/05/%E5%88%A0%E9%99%A4DataFrame%E4%B8%AD%E6%9F%90%E5%88%97%E5%80%BC%E4%B8%BANaN%E7%9A%84%E8%AE%B0%E5%BD%95-%E8%A1%8C/import pandas as pdimport numpy ...
关于dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)参数的说明:
axis:默认是0,即删除行。1或者columns则是删除列
how:删除方式。any删除至少有一个NaN的行/列;all删除全部都是NaN的行/列
thresh:阈值。int,删除的行/列至少有n个NaN值
subset:列表。columns或者index,只删除指定列/行
一、any:删除至少有一个NaN的行/列
#删除至少有一个NaN的行
=== 数据过滤获取 ===
个人觉得并没有什么用,完全可以用切片或索引器代替
stu_info = pd.read_excel('student_info1.xlsx',sheetname='countif',index_col='学号').head(3)
stu_info[stu_info.columns...
去除null、
NaN
去除 dataframe 中的 null 、
NaN 有方法 drop ,用
dataframe.na 找出带有 null、
NaN 的
行,用 drop
删除行:
df.na.drop()
您可以使用 pd.DataFrame.isnull() 或 pd.isnull() 函数来筛选出 pd.DataFrame 中的 nan。例如:
import pandas as pd
df = pd.DataFrame([[1, 2, 3], [float('nan'), 5, 6], [7, 8, 9]])
# 使用 pd.DataFrame.isnull() 函数筛选出 nan
nan_...
可以使用 Pandas 的 dropna() 方法来删除包含 NaN 值的行。可以指定要删除的列,然后将参数 'subset' 设置为该列名。以下是一个示例代码:
```python
import pandas as pd
# 创建一个包含 NaN 值的 DataFrame
df = pd.DataFrame({'A': [1, 2, 3, 4, 5],
'B': [2, 4, 6, 8, 10],
'C': [3, 6, None, 12, None]})
# 删除 C 列值为 NaN 的行
df = df.dropna(subset=['C'])
print(df)
A B C
0 1 2 3.0
1 2 4 6.0
3 4 8 12.0
在上面的示例中,我们删除了 C 列值为 NaN 的行,结果只保留了包含有效值的行。

