


描述性统计分析以及在R中的实现

目录:
单组计算描述性统计量:
方法1:summary()函数
方法2:apply()或者sapply()函数
方法3:Hmisc包中的describe()函数
方法4:pastecs包中的stat.desc()函数
方法5:psych包中的describe()函数
分组计算描述性统计量:
方法1:aggregate()函数
方法2:by()函数
方法3:doBy包中的summaryBy()函数
方法4:describeBy()函数
一、单组计算描述性统计量
data(mtcars)
head(mtcars)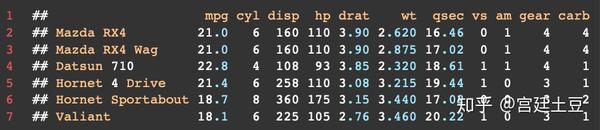
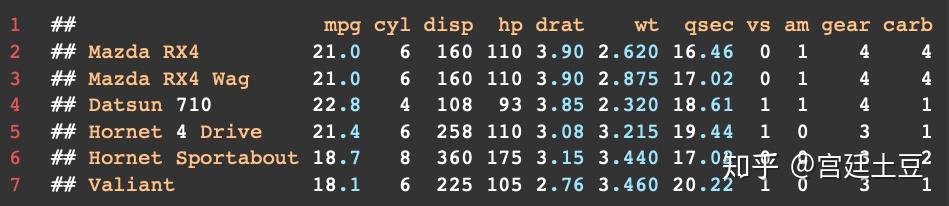
myvars <- c("mpg", "hp","wt")
head(mtcars[myvars])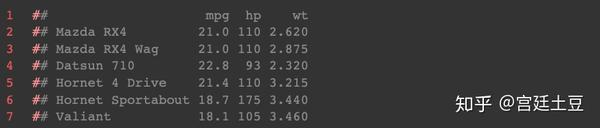
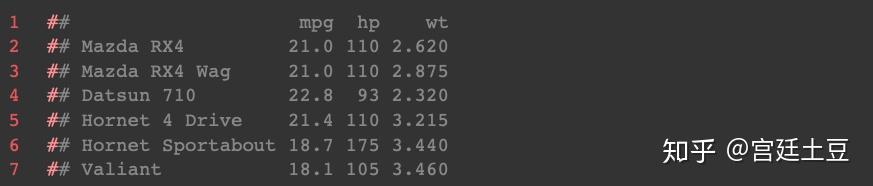
方法1:summary()函数:
summary()为R自带的函数,可以返回最大值、最小值、四分位数、平均数6个值。
summary(mtcars[myvars])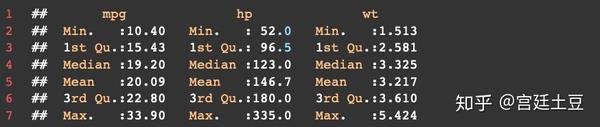
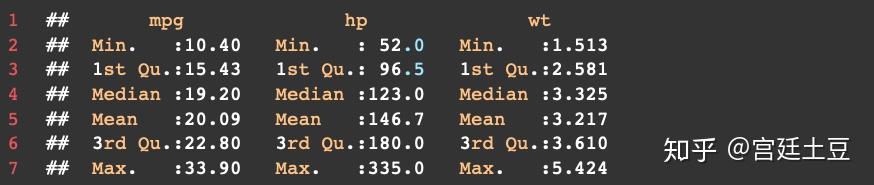
方法2:apply()或者sapply()函数,
可以计算所选择的任意描述统计量,对于sapply()函数,其格式为sapply(x, FUN, options),其中x为数据框,FUN为选择的任意函数,例如mean(), sd(), var(), min(), max(), median(), length(), range(), quantile(), fivenum()。得出的结果偏度为+0.61(右偏态),峰度为-0.37,说明较正态分布稍平。代码:
mystats <- function(x, na.omit=FALSE){
if(na.omit)
x <- x[!is.na(x)] #如果x是非空值,则赋值给x
m <- mean(x)
n <- length(x)
s <- sd(x)
skew <- sum((x-m)^3/s^3)/n
kurt <- sum((x-m)^4/s^4)/n-3
return(c(n=n, mean=m, stdev=s, skew=skew, kurt=kurt))
myvars <- c("mpg", "hp", "wt")
sapply(mtcars[myvars], mystats)结果:


计算数据的峰度和偏度还可以用**e1071**包中的**skewness()**和**kurtosis()**函数来计算。
library(e1071)
mystats <- function(x, na.omit=FALSE){
if(na.omit)
x <- x[!is.na(x)]
skew <- skewness(x)
kurt <- kurtosis(x)
return(c(skew=skew, kurt=kurt))
myvars <- c("mpg", "hp", "wt")
sapply(mtcars[myvars], mystats)结果:


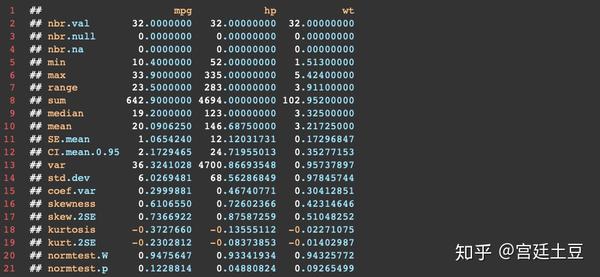
方法3:Hmisc包中的describe()函数
describe()相比于方法1,可以返回变量和观测的数目,缺失值、唯一值数目,以及5个最大的值和5个最小的值。
library(Hmisc)
describe(mtcars[myvars])结果:


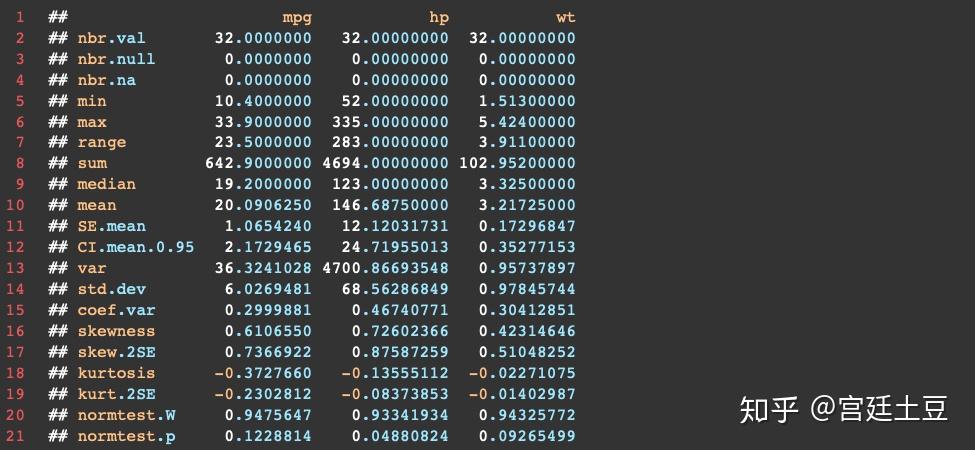
方法4:pastecs包中的stat.desc()函数
基本公式stat.desc(x, basic=TRUE, desc=TRUE, norm=FALSE, p=0.95)。basic=TRUE、desc=TRUE都是默认值,norm=TRUE(FALSE为默认值)返回正态分布统计量,包括偏度、峰度以及它们的限制性水平和Shapiro-Wilk正态检验结果。该函数还计算了平均数95%的置信区间。
library(pastecs)
stat.desc(mtcars[myvars], norm=TRUE)结果:
方法5:psych包中的describe()函数
除了常用的统计量外,可以计算非缺失值的数量、截尾平均数、绝对中位数等。如果截尾平均数和平均数相差太大,说明存在极端值,此时截尾平均数可以更好地反映数据的集中趋势。
注意:hmis包和psych包都含有describe()函数,但最后载入的程序包优先,hmis包describe()函数会被掩蔽,如果想要运行先前载入包的函数,可以使用代码hmisc::describe(),告诉计算机执行哪个函数。
library(psych)
describe(mtcars[myvars])结果:


二、分组计算描述性统计量
如果一个变量有多个水平,想计算每个水平数据的描述统计情况,或者有多个被试组,计算每组被试的数据情况,这时可以使用分组计算的方法计算各组数据的描述统计量。
方法1:aggregate()函数
list(am=mtcars$am),am指定了组的列标签。aggregate()函数一次只能返回一种统计量。
dstats <- function(x)sapply(x, mystats)
myvars <- c("mpg", "hp", "wt")
aggregate(mtcars[myvars], by=list(am=mtcars$am), mean)
aggregate(mtcars[myvars], by=list(am=mtcars$am), sd)

方法2:by()函数
可以指定任意函数返回多个指定的统计量,其基本公式为by(data, INDICES, FUN)。data为一个数据框;INDICES为一个因子或因子组成的列表,定义分组;FUN为任意函数。这里的dstats调用了前面的mystats函数。
myvars <- c("mpg","hp","wt")
mystats <- function(x, na.omit=FALSE){
if(na.omit)
x <- x[!is.na(x)]
m <- mean(x)
sd <- sd(x)
skew <- skewness(x)
kurt <- kurtosis(x)