


ORACLE日常统计分析函数

开发中避免不了通过sql进行统计分析,如果还停留在sum(),count(),嵌套子查询阶段,那就太低端了,现在带你学习一些sao操作,效率杠杠的--
首先,建个示例表:
CREATE TABLE earnings -- 打工赚钱表
earnmonth VARCHAR2 (6),
-- 打工月份
area VARCHAR2 (20),
-- 打工地区
sno VARCHAR2 (10),
-- 打工者编号
sname VARCHAR2 (20),
-- 打工者姓名
TIMES INT,
-- 本月打工次数
singleincome NUMBER (10, 2),
-- 每次赚多少钱
personincome NUMBER (10, 2)
-- 当月总收入
)插入几条实验数据:
insert into earnings values('200912','北平','511601','大魁',11,30,11*30);
insert into earnings values('200912','北平','511602','大凯',8,25,8*25);
insert into earnings values('200912','北平','511603','小东',30,6.25,30*6.25);
insert into earnings values('200912','北平','511604','大亮',16,8.25,16*8.25);
insert into earnings values('200912','北平','511605','贱敬',30,11,30*11);
insert into earnings values('200912','金陵','511301','小玉',15,12.25,15*12.25);
insert into earnings values('200912','金陵','511302','小凡',27,16.67,27*16.67);
insert into earnings values('200912','金陵','511303','小妮',7,33.33,7*33.33);
insert into earnings values('200912','金陵','511304','小俐',0,18,0);
insert into earnings values('200912','金陵','511305','雪儿',11,9.88,11*9.88);
insert into earnings values('201001','北平','511601','大魁',0,30,0);
insert into earnings values('201001','北平','511602','大凯',14,25,14*25);
insert into earnings values('201001','北平','511603','小东',19,6.25,19*6.25);
insert into earnings values('201001','北平','511604','大亮',7,8.25,7*8.25);
insert into earnings values('201001','北平','511605','贱敬',21,11,21*11);
insert into earnings values('201001','金陵','511301','小玉',6,12.25,6*12.25);
insert into earnings values('201001','金陵','511302','小凡',17,16.67,17*16.67);
insert into earnings values('201001','金陵','511303','小妮',27,33.33,27*33.33);
insert into earnings values('201001','金陵','511304','小俐',16,18,16*18);
insert into earnings values('201001','金陵','511305','雪儿',11,9.88,11*9.88); 查一下刚刚入库的数据:
select * from earnings; 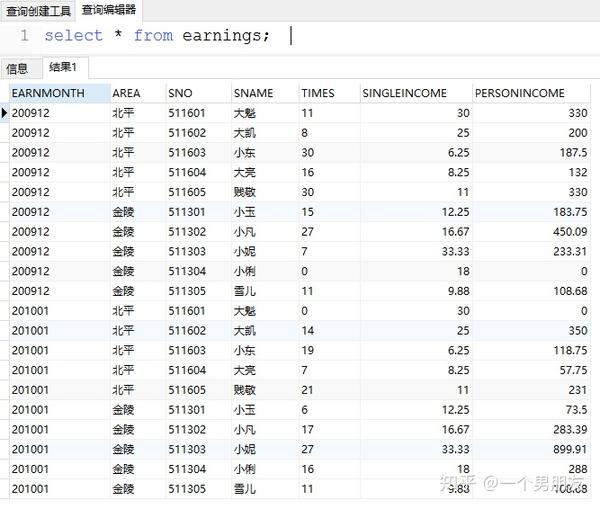
前期准备完成,下面就可以为所欲为了:
(1) sum 函数,统计总合(这个都不陌生,比较常用)
按照月份,统计每個地区的总收入
SELECT
earnmonth,
area,
SUM (personincome)
earnings
GROUP BY
earnmonth,
area;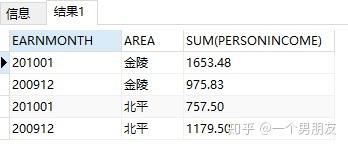
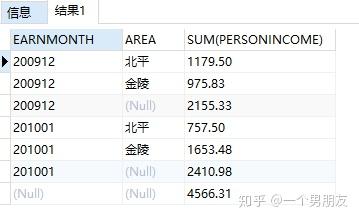
(2) rollup 函数(这个函数可能有一部分同学开始没用过了吧0.0)
按照月份,地区统计收入
SELECT
earnmonth,
area,
SUM (personincome)
earnings
GROUP BY
ROLLUP (earnmonth, area);
(3) cube 函数(先不解释,再来一个)
按照月份,地区进行收入总汇总
SELECT
earnmonth,
area,
SUM (personincome)
earnings
GROUP BY
CUBE (earnmonth, area)
ORDER BY
earnmonth,
area NULLS LAST;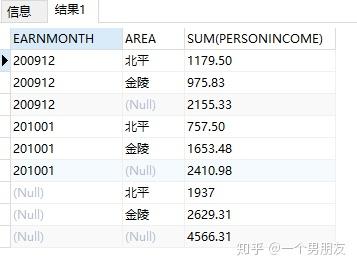
看到这里是不是觉得发现新大陆了,缓一缓,解释一下前三个函数--
sum()是统计求和的函数,很常用,不多解释。
group by 是分组函数,按照earnmonth和area先后次序分组。
以上三例都是先按照earnmonth分组,在earnmonth内部再按area分组,并在area组内统计personincome总合。
group by 后面什么也不接就是直接分组。
group by 后面接 rollup 是在纯粹的 group by 分组上再加上对earnmonth的汇总统计。
group by 后面接 cube 是对earnmonth汇总统计基础上对area再统计。
另外那个 nulls last 是把空值放在最后。
rollup和cube区别:
如果是ROLLUP(A, B, C)的话,GROUP BY顺序
(A、B、C)
(A、B)
(A)
最后对全表进行GROUP BY操作。
如果是GROUP BY CUBE(A, B, C),GROUP BY顺序
(A、B、C)
(A、B)
(A、C)
(A),
(B、C)
(B)
(C),
最后对全表进行GROUP BY操作。
在以上例子中,是用rollup和cube函数都会对结果集产生null,可读性略差,下面对之前sql完善一下--
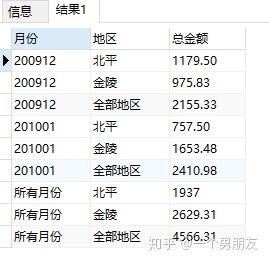
(4) grouping 函数
grouping函数用法,带一个参数,参数为字段名,如果当前行是由rollup或者cube汇总得来的,结果就返回1,反之返回0
SELECT
DECODE (
GROUPING (earnmonth),
'所有月份',
earnmonth
) 月份,
DECODE (
GROUPING (area),
'全部地区',
) 地区,
SUM (personincome) 总金额
earnings
GROUP BY
CUBE (earnmonth, area)
ORDER BY
earnmonth,
area NULLS LAST;
很神奇,是不是有同学对DECODE这个函数有点陌生,简单介绍一下:
decode (条件,值1,返回值1,值2,返回值2,...值n,返回值n,缺省值)
该函数的含义如下:
IF 条件=值1 THEN
RETURN(返回值1)
ELSIF 条件=值2 THEN
RETURN(返回值2)
......
ELSIF 条件=值n THEN
RETURN(返回值n)
ELSE
RETURN(返回值)
END IF
(5) rank() over 开窗函数(难度升级,同学们跟上!)
按照月份、地区,求打工收入排序
重复值所在行的序列值相同,但其后的序列值从重复行数开始递增
SELECT
earnmonth 月份,
area 地区,
sname 打工者,
personincome 收入,
RANK () OVER (
PARTITION BY earnmonth,
ORDER BY
personincome DESC
earnings;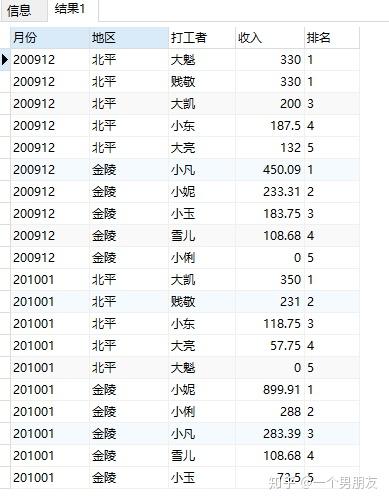
(6) dense_rank() over 开窗函数(再来一个)
按照月份、地区,求打工收入排序
重复值所在行的序列值相同,而其后的序列值依旧递增
SELECT
earnmonth 月份,
area 地区,
sname 打工者,
personincome 收入,
DENSE_RANK () OVER (
PARTITION BY earnmonth,
ORDER BY
personincome DESC
earnings;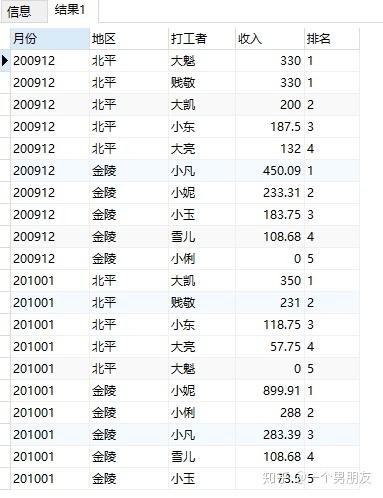
(7) row_number() over (来一个霸道的)
按照月份、地区,求打工收入排序
不管是否有重复行,(分组内)序列值始终递增
SELECT
earnmonth 月份,
area 地区,
sname 打工者,
personincome 收入,
ROW_NUMBER () OVER (
PARTITION BY earnmonth,
ORDER BY
personincome DESC
earnings;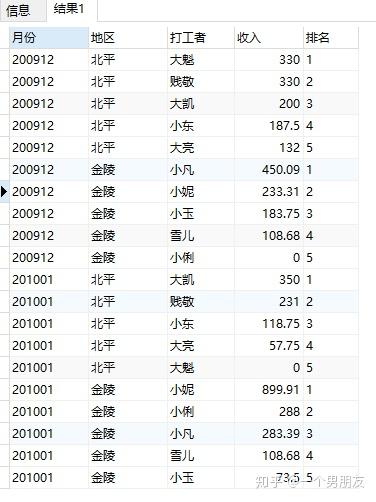
再缓一缓,通过(5)(6)(7)发现rank,dense_rank,row_number的区别--
结果集中如果出现两个相同的数据,那么rank会进行跳跃式的排名,
比如两个第二,那么没有第三接下来就是第四;
但是dense_rank不会跳跃式的排名,两个第二接下来还是第三;
row_number最牛,即使两个数据相同,排名也不一样。
(8)sum累计求和(来个sum升级版)
根据月份求出各个打工者收入总和,按照收入由少到多排序
SELECT
earnmonth 月份,
area 地区,
sname 打工者,
SUM (personincome) OVER (
PARTITION BY earnmonth,
ORDER BY
personincome
) 总收入
earnings;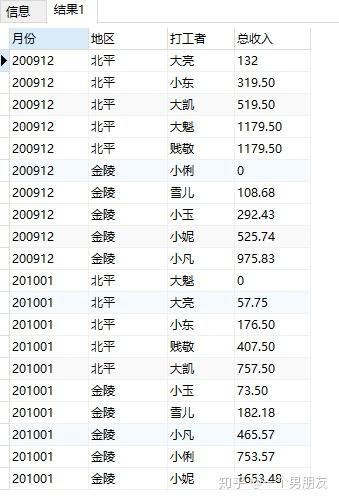
(9)max,min,avg和sum函数综合运用(来个全家桶)
按照月份和地区求打工收入最高值,最低值,平均值和总额
SELECT DISTINCT
earnmonth 月份,
area 地区,
MAX (personincome) OVER (PARTITION BY earnmonth, area) 最高值,
MIN (personincome) OVER (PARTITION BY earnmonth, area) 最低值,
AVG (personincome) OVER (PARTITION BY earnmonth, area) 平均值,
SUM (personincome) OVER (PARTITION BY earnmonth, area) 总额