两张表
table1
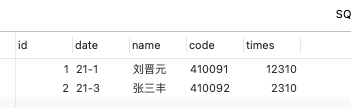
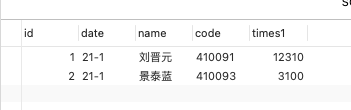
table2
我想要将两者的数据进行合并达到如下的效果:
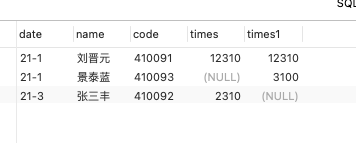
这里限制条件有两个分别是date,code 两个,只有当两者都对应上才能达到我想要的效果。于是我绞尽脑汁也想不出来该如何去解决问题。
于是乎,我又重新回到了起点。(我跑去看菜鸟教程了)
可能是我原来没仔细看吧,终于让我发现了一个解决问题的方式,果然回归原始的基础,还是能解决很多问题的。
菜鸟教程

我先把table1的所有数据和table2 的与table1中有共同限制条件的数据查询出来。
SELECT
t1.date,
t1.NAME,
t1.CODE,
t1.times,
t2.times1
table1 t1
LEFT JOIN table2 t2 ON t1.CODE = t2.CODE
然后再使用is null 去筛选出table2 中既不属于table2 也不属于table1 的数据。
SELECT
t2.date,
t2.NAME,
t2.CODE,
t1.times,
t2.times1
table1 t1
RIGHT JOIN table2 t2 ON t1.CODE = t2.CODE
WHERE
t1.CODE IS NULL
最后再把所有的数据Union成一张中间表,然后再从这张中间表中查询出想要的数据。
SELECT date,name,code,times,times1 FROM ((
SELECT
t1.date,
t1.NAME,
t1.CODE,
t1.times,
t2.times1
table1 t1
LEFT JOIN table2 t2 ON t1.CODE = t2.CODE
UNION
SELECT
t2.date,
t2.NAME,
t2.CODE,
t1.times,
t2.times1
table1 t1
RIGHT JOIN table2 t2 ON t1.CODE = t2.CODE
WHERE
t1.CODE IS NULL
)) AS temp ORDER BY date
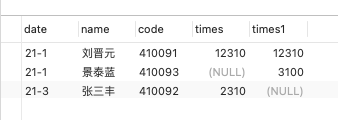
最终得到的结果就是我想要的:
此为SQL案例:将两张具备相同字段,有一部分字段不相同的两张表获取查询结果为整合之后的。两张表table1table2我想要将两者的数据进行合并达到如下的效果:这里限制条件有两个分别是date,code 两个,只有当两者都对应上才能达到我想要的效果。于是我绞尽脑汁也想不出来该如何去解决问题。于是乎,我又重新回到了起点。(我跑去看菜鸟教程了)可能是我原来没仔细看吧,终于让我发现了一个解决问题的方式,果然回归原始的基础,还是能解决很多问题的。菜鸟教程我先把table1的所有数据和tab
也许大家有时候会遇到需要将把数据库中的某张表的数据按照该表的某个字段分类输出,比如一张数据表area如下
我们需要将里面的area按照serialize字段进行分类输出,比如这种形式:
areas serialize
阿蓝色,艾沙云 A
重庆森林,传承家园 C
红军楼小区,海员新村 H
要以这种形式放映出来,于是可以这样做,使用mysql中的group_concat()
、group by实现,
select serialize,group_concat(area) as areas from area group by serialize;
则可以得到上面数据表
这里的grou
select * into 新表名 from (select * from T1 union all select * from T2)
这个语句可以实现将合并的数据追加到一个新表中。
不合并重复数据 select * from T1 union all select * from T2
合并重复数据 select * from T1 union select * from T2
两个表,表1 表2
如果要将 表1的数据并入表2用以下语句即可
insert into 表2(字段1,字段2) select 字
你可以使用 SQL Server 的 "UNION" 运算符来同时查询两张不相关的表,然后将结果合并到一个表中。例如:
SELECT column1, column2
FROM table1
UNION
SELECT column3, column4
FROM table2
这会将 table1 和 table2 中的结果合并为一个表,该表包含 column1, column2, column3...
select
d1.ID,CAST(d1.ID AS CHAR) AS intId, d1.CODE_TYPE, d1.CODE, d1.CODE_IMG, d1.VALUE
from m_dict_code d1
where d1.CODE_TYPE in('USER_TYPE','addSupers')
UNION
今天接到一任务,有一张学生信息表(Excel表),里面有一万多条记录,现在要把这张表导入到数据库中,并设置学生学号为主键,但是现在这张表中的学生学号有重复的记录,我必须先找出这些重复的记录,然后再进行筛选,经过研究问题终于得到解决。 以上问题实际上就是查询数据库表中某一字段值重复的记录,这里省略如何将Excel表导入到数据库步骤,只讨论用SQL查询数据库中某一字段下相同值的记录方法。 现在假设数据库表名为student,里面有字段Sno(学号),ID(身份证),这里提供两种查询的方法: 方法一:通过学号和身份证字段来查询(数据库执行效率高,推荐)
代码如下: SE
1.从数据库中先查询符合条件的记录,存放于一个DataTable中,在使用c#等开始遍历这张表,利用DataRow中的主键,再去读取相应的符合条件的多条记录,合并这些第二次读取到的记录内容,返回给前面的这个DataRow数据行。这样做没有错,但是如果数据量大,我们可能面临无数次的打开断开数据库链接,速度效率将会很低。 2.从数据库中一次读取数据到一张表中返回并显示到UI层。说起来谁都想这么做,但是以前太笨,没有去研究这个,今天因为数据量较大的原因,让我不得不想些其他办法来提高点效率。 Google~hk一下,果真有答案,然后依葫芦画瓢,自己写了一个 目的是获取不定量的符合条件的兼职记录,并将每
left join (左联接) 返回包括左
表中的所有记录和右
表中联结
字段相等的记录
right join (右联接) 返回包括右
表中的所有记录和左
表中联结
字段相等的记录
inner join (等值连接) 只返回两个
表中联结
字段相等的行
例子:连接
表一和
表二
表一主键为组织机构代码,
表二主键为zzjgdm
你可以使用 SQL 的 INSERT INTO SELECT 语句来将 a、b 两张表合并成一张表插入 c 表。具体操作步骤如下:
1. 确认 c 表的结构与 a、b 表一致。
2. 使用以下 SQL 语句合并 a、b 两张表:
SELECT * INTO c FROM a
UNION ALL
SELECT * FROM b
其中,UNION ALL 表示将 a、b 两张表的所有记录合并,包括重复记录。
3. 如果你想要去除重复记录,可以使用以下 SQL 语句:
SELECT DISTINCT * INTO c FROM (
SELECT * FROM a
UNION
SELECT * FROM b
) AS temp
其中,DISTINCT 表示去除重复记录,UNION 表示将 a、b 两张表的所有记录合并并去重。
注意,以上 SQL 语句只是示例,具体操作请根据实际情况进行调整。
Error creating bean with name 'dataSource' defined in class path resource [applicationContext.xml]:
70343
Servlet.service() for servlet [springServlet] in context with path [/TESTVIDEO] threw exception [Req
13491

