在进行数据分析时,我们经常需要把DataFrame的一列拆成多列或者根据某列把一行拆成多行,这篇文章主要讲解这两个目标的实现。
码字不易,喜欢请点赞!!!
-
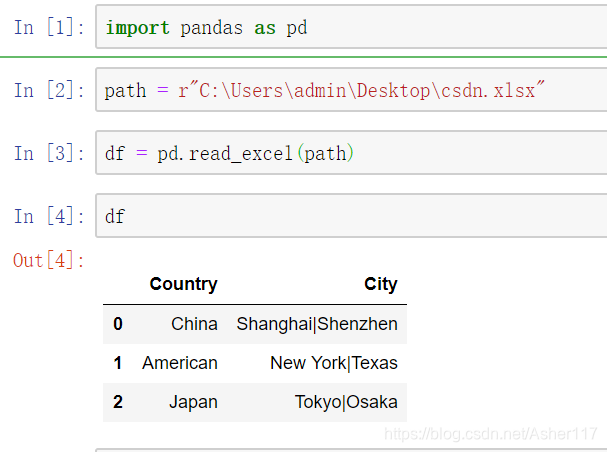
读取数据
-
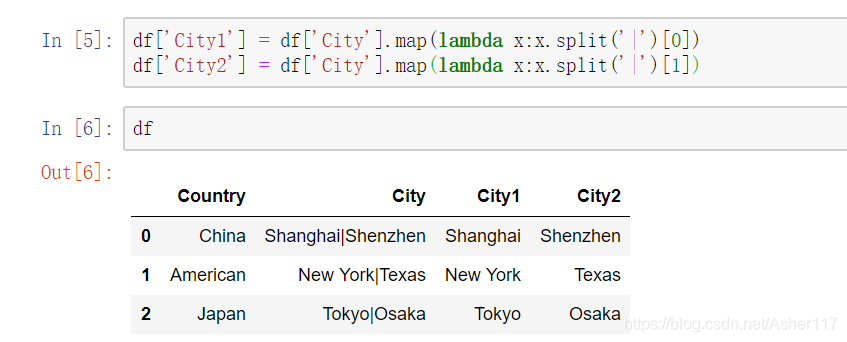
将City列转成多列(以‘|’为分隔符)
这里使用匿名函数lambda来讲City列拆成两列。
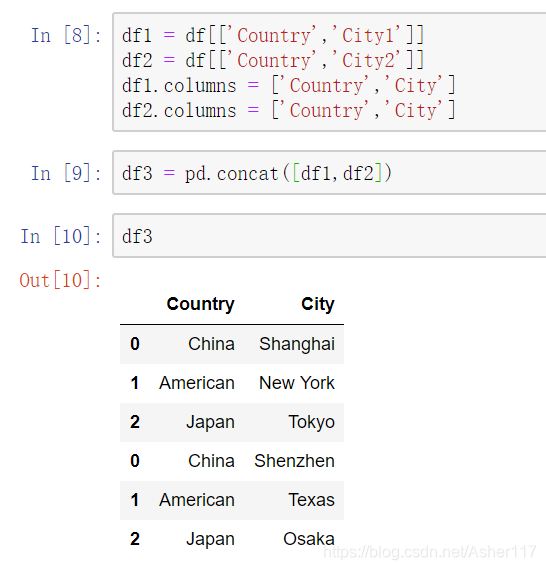
3.将DataFrame一行拆成多行(以‘|’为分隔符)
方法一:在刚刚得到的DataFrame基础上操作,如下图所以,可以明显看到我们按照City列将DataFrame拆成了多行。主要是先将DataFrame拆成多列,然后拆成多个DataFrame再使用concat组合。但是这种方法碰到City列切割不均匀的时候可能会麻烦一点,因此,这个时候你可以使用万能方法二。
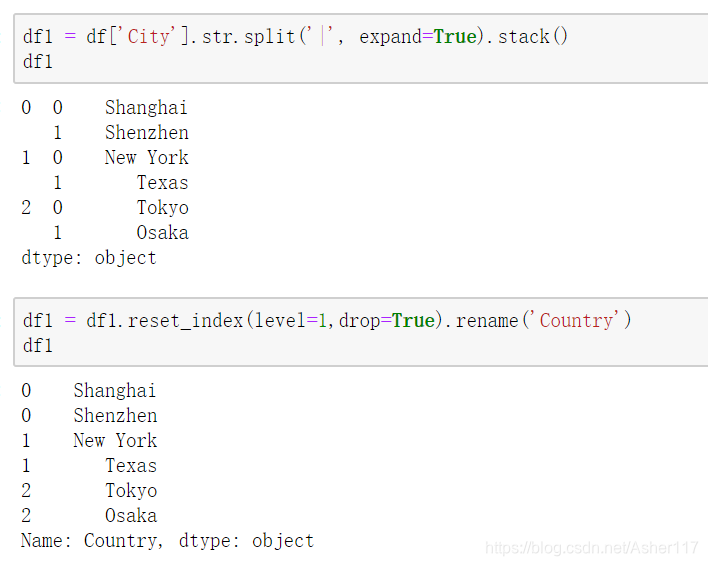
方法二:这个方法的主要思想是,首先将DataFrame中需要拆分的列进行拆分,再使用stack()进行轴变换,然后通过index来join即可,如下所示。
首先,将刚刚的df还原成原始形式:

接下来取出其City列,并切分成多列之后轴转换,之后重新设置索引,并且重命名为Company
最后删除df里面的Country列,并将DataFrame-df1 使用join到df里面得到最后的结果。

想要做成的结果如下图(也就是统计每个id下各个page_no出现的次数)
实现的思路是先对page_no这
一列
进行one-hot编码,将
一列
变为
多列
,然后再用cishu列与之相乘,最后进行groupby之后加和,就得到了最终结果。
代码如下:
df = pd.get_dummies(TestA_beh[‘page_no’])
TestA_beh = pd.concat([TestA_beh,df],axis=1)
col_page = [‘AAO’, ‘BWA’, ‘BWE’, ‘CQA’, ‘CQB’,
以下是在MySQL中通过SQL语句实现Excel中数据透视表/交叉表/二维表的功能。原理不作赘述,具体示例与代码如下:
1. 数据源预览
SELECT * FROM pivot_table;
2. 数据透视表
SELECT
year AS "年份",
SUM(CASE WHEN department = "蔬菜" THEN sale END) AS "蔬菜",
SUM(CASE WHEN department = "水果" THEN sale END) AS "水果",
import
pandas
as pd
df = pd.
DataFrame
([{'var1': 'a,b,c', 'var2': 1},
{'var1': 'd,e', 'var2': 2}])
df1 = pd.concat...
在使用
dataframe
时,我们常常需要依据应用场景,需要将原来一条record拆分为
多行
(字段数增加1个,record增加),或者在一个record中根据已有字段拆分为
多列
(仍是1个record,字段数增加)这里还有另外一个问题,如果我们原始数据并没规律的以@分割的固定格式字段,或者原始数据中并没有事先准备好的array格式的字段,如何生成呢?这里个functions.explode和hive中的explode作用类似,可参考。中的explode使用。udf的使用,可以参见。......

