欢迎使用HttpCanary!
HttpCanary是一款功能强大的HTTP/HTTPS/HTTP2网络包抓取和分析工具,你可以把他看成是移动端的Fiddler或者Charles,但是HttpCanary使用起来更加地简单容易,因为它是专门为移动端设计的!
🔥最重要的是:无需root权限!无需root权限!无需root权限!
HttpCanary支持对HTTP协议包的抓取和注入。使用这款App,您将能够非常非常方便的测试Rest API接口请求。同时,HttpCanary提供了各式各样的数据浏览功能,比如Raw视图、Hex视图、Json视图等等。
* 支持协议
HTTP1.0, HTTP1.1, HTTP2.0, WebSocket 和 TLS/SSL。
* 注入功能
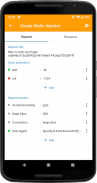
HttpCanary支持修改请求和响应数据,然后提交到客户端或服务端,也就是注入功能。HttpCanary提供了两种不同的注入模式:静态注入和动态注入。使用这两种模式,可以实现对请求参数,请求/响应头,请求/响应体,响应行的注入。您还可以创建不同需求的注入器,因为静态注入可以支持多个注入器同时工作。
* 数据浏览
HttpCanary具有多种不同的视图浏览功能。
Raw视图:可以查看原始数据;
Text视图:以Text的形式查看请求/响应体内容;
Hex视图:以Hex的形式查看请求/响应体内容;
Json视图:格式化Json字符串,支持节点的展开、关闭和复制等操作;
图片视图:可以预览BPM、PNG、GIF、JPG、WEBP等格式的图片内容;
音频视图:可以播放AAC、WAC、 MP3、OGG、MPEG等格式的音频内容;
* 内容总览
HttpCanary支持浏览一个网络请求的总体概况,包括URL、HTTP协议、HTTP方法、响应码、服务器Host、服务器IP和端口、Content-Type、Keep-Alive、时间信息、数据大小信息等。
* 数据筛选和搜索
HttpCanary提供了多维度的数据过滤器和搜索功能,比如通过应用、Host、协议、方法、IP、端口、关键词搜索过滤等。
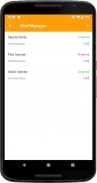
* 屏蔽设定
HttpCanary可以对网络请求的数据发送以及服务器响应进行屏蔽操作,这个功能可以非常方便地帮助开发者进行Rest API的调试。
* 插件
HttpCanary提供了丰富的扩展插件,包括Host屏蔽、Mime-Type屏蔽、图片音频视频下载、请求性能统计、微信定位漂移等。按照设计,开发者还可以开发自己的Plugin集成进HttpCanary中,也可以安装扩展Plugin(功能尚未开放)。Plugin可以对数据包进行修改等自定义操作,也就是一个高级的注入器!我们将会尽快发布Plugin-SDK!
最后,HttpCanary的核心代码将会开源到Github,我们希望HttpCanary能够帮助到更多的人!