

Cassandra系列(二):系统流程

一个真正实用的存储系统结构是非常复杂的,除了数据持久性、系统还需要可扩展性、负载均衡、成员检测、故障检测、副本同步、故障恢复、过载处理、状态转移、并发和任务调度、系统监控等等特性。任何一个解决方案都能写出一篇很长的文章,本章主要介绍Cassandra架构的一些基本概念。
先对Cassandra基本流程进行概述:通常,对key的R/W请求将路由到Cassandra集群中的任一节点。然后,节点通过这个特定的key找到对应的replica。其中,对于write,系统将请求路由到replica,等待法定数量的replica以确认写入完成;对于read,基于客户端所需的一致性保证,系统将请求路由到最近的replica或将路由到所有的replica并等待法定数量replica的响应。
下面详述整体系统架构的几个核心部分。
1 划分(Partitioning)
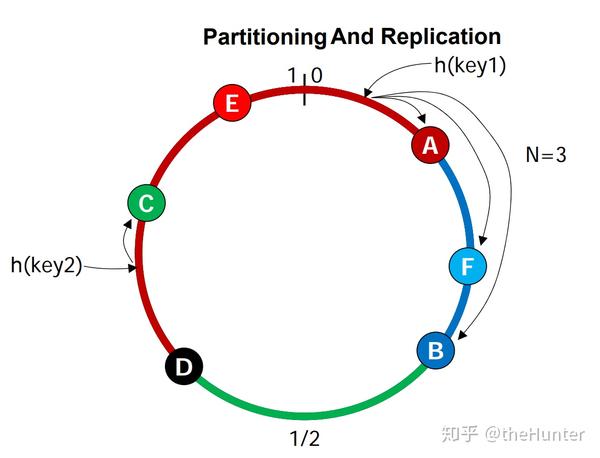
Cassandra的关键特点之一就是能够逐步扩展分布式系统,这就要求集群中的server node动态地划分数据。Cassandra使用一致性哈希在整个集群中划分数据。一致性哈希中哈希函数的输出范围被视为固定的环形(最小的哈希值邻接到最大的哈希值)。 大致的过程在Cassandra系列(一)第一节中叙述地非常详细。 一个data item对应的那个管理的node被视为这个对应的key的coordinator。因此每个node负责它与环上前任node之间的区域。不过基本的算法还有一些问题,首先node随机的位置分布,导致数据和负载的不均匀分布;其次,忽略了各个node性能的差异。那么通常有两种方案解决问题,一种是将node分配到环上的多个位置, 第二种是将轻负荷node分配到环上的某些位置以减轻重负荷node的压力 (参考 Chord: a scalable peer-to-peer lookup protocol 有时间我将会就Chord的论文写一篇学习心得)。Cassandra因为设计简单和易于实现选择了后者。
NOTE: 早期的Cassandra支持在集群中rebalancing using random partitioner。那什么是balanced,当每个node都能负责相等数量的数据时就算balanced。这是通过评估分配给每个node的partitioner token来完成的。所以在OpsCenter中,每次点击” 重新平衡集群 “即可rebalance the cluster。 但是,后来Cassandra支持了Virtual nodes以替代单纯的rebalancing ,virtual nodes是一个非常重要的概念,具体参考 Virtual nodes in Cassandra 1.2 。
2 复制(Replication)
Cassandra使用replication以实现高可用性和数据持久性。每个data item被复制在N个hosts上,N是可配置的replication factor。前一节说过了每个key由一个coordinator负责管理。这个coordinator负责那些对应key落在它范围的data item的replication。除了负责存储这个data item的本身,coordinator还要在ring中的N-1个nodes中备份这个data item。在Cassandra client中,可以选择不同的备份策略,比如 SimpleStrategy (旧称Rack Unaware)和 NetworkTopologyStrategy (能优雅地处理超过2台数据中心,取代了过去叫Rack Aware的一个玩意儿)。前者很简单,是通过chord环在这个coordinator后继中选择N-1个作为备份点。后者在参考链接中有详细描述。
NOTE: 在Facebook内部,一般使用Zookeeper在系统中选取领导者以获取副本的范围,但Apache Cassandra一直避免使用它,所以这里不介绍这种复制策略了。
3 成员资格(Membership)
Cassandra中的集群协议主要基于Scuttlebutt( 参考:Efficient reconciliation and flow control for anti-entropy protocols ),一种基于Gossip的非常有效的anti-entropy。在Cassandra系统中,Gossip不仅用于Membership还能传播其它系统控制状态。(状态在 O(logN) 的rounds中传播,这里N是总的node数量)Gossip大概意思就是一个member每隔T秒增加heartbeat counter并且选择其它的member发送它的list,然后member把自己的list和收到的list合并起来。
Failure detection是一种机制,通过这个机制,一个Node可以在本地就能确定系统中的任何其它Node是启动还是关闭的。在Cassandra中,failure detection还可以避免和一些不可达node通信。Failure detection在Cassandra中主要用于system management,replication,load balancing。应用程序自己设定一个合适的阈值,触发suspicion并执行相应操作。在Cassandra中,检测到故障一般要10~15秒(前几年的版本是这样)。
4 首次启动(Bootstrapping)
当一个node首次启动,它会随机产生一个token然后确定在环上的位置。对于Fault tolerance,mapping会持久化到本地磁盘和Zookeeper上。它的token信息随后gossip到整个cluster里。以上就是我们为什么知道所有的nodes和对应的环上位置。所以任何一个node作为入口,都能把request路由到集群上正确的node。在bootstrap程序中,当一个node需要加入一个cluster中时,它就会读取配置文件,这个文件中包含了少量的contact points,这些最初的contact points我们把它们叫做cluster的种子(seeds)。
关于最开始的部署(刚开始只有一个data center),参考这里: https:// docs.datastax.com/en/ar chived/cassandra/2.0/cassandra/initialize/initializeSingleDS.html
5 本地持久性(Local Persistence)
Cassandra系统的数据持久性依赖于本地文件系统。
在阅读write和read流程前请先知悉现代Cassandra的一些改进:
- Local persistence的改进: JBOD support 和 mixed SSD/HDD deployments .
- 可以自动管理memtable sizes 和 flush policy: https://www. datastax.com/dev/blog/w hats-new-in-cassandra-1-0-improved-memory-and-disk-space-management
- 压缩方面的改进: concurrent compactions , single-pass compaction optimization , compaction throttling , leveled compaction , optimizes more for reads
- 性能的一个重要改进(布隆过滤器): moved off-heap !!!
WRITE
典型的write操作涉及写入commit log以获得持久性和可恢复性以及更新 in-memory 的数据结构。只有在成功写入commit log后才能写入 in-memory 数据结构。在每台机器上都有一个专用的磁盘用于commit log,因为对commit log的所有写入都是顺序的,因此我们可以最大化磁盘吞吐量。当 in-memory 数据结构里的数据达到一个确定的阈值(基于data size和number of objects计算得到的),就会把数据转储到磁盘上。所有的写入都是顺序写到磁盘上并且基于row key生成一个index以便于高效查询。这些索引和数据文件一起存起来。
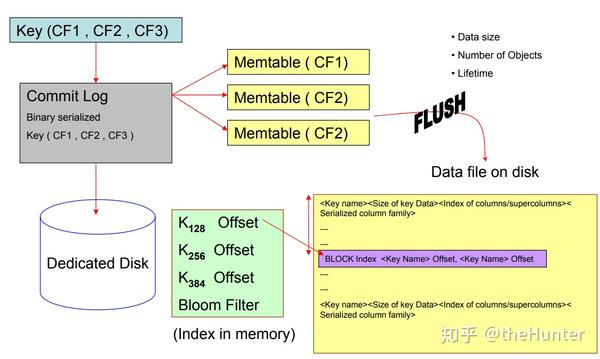

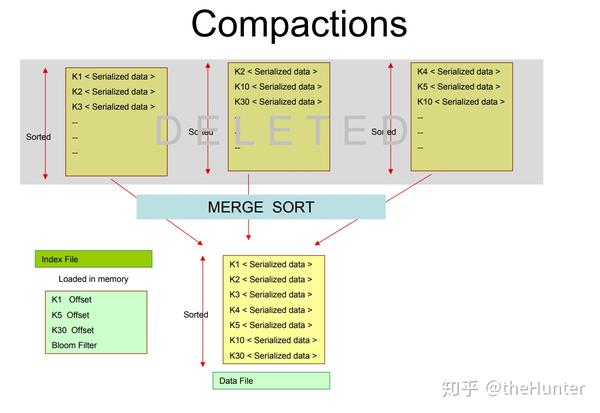
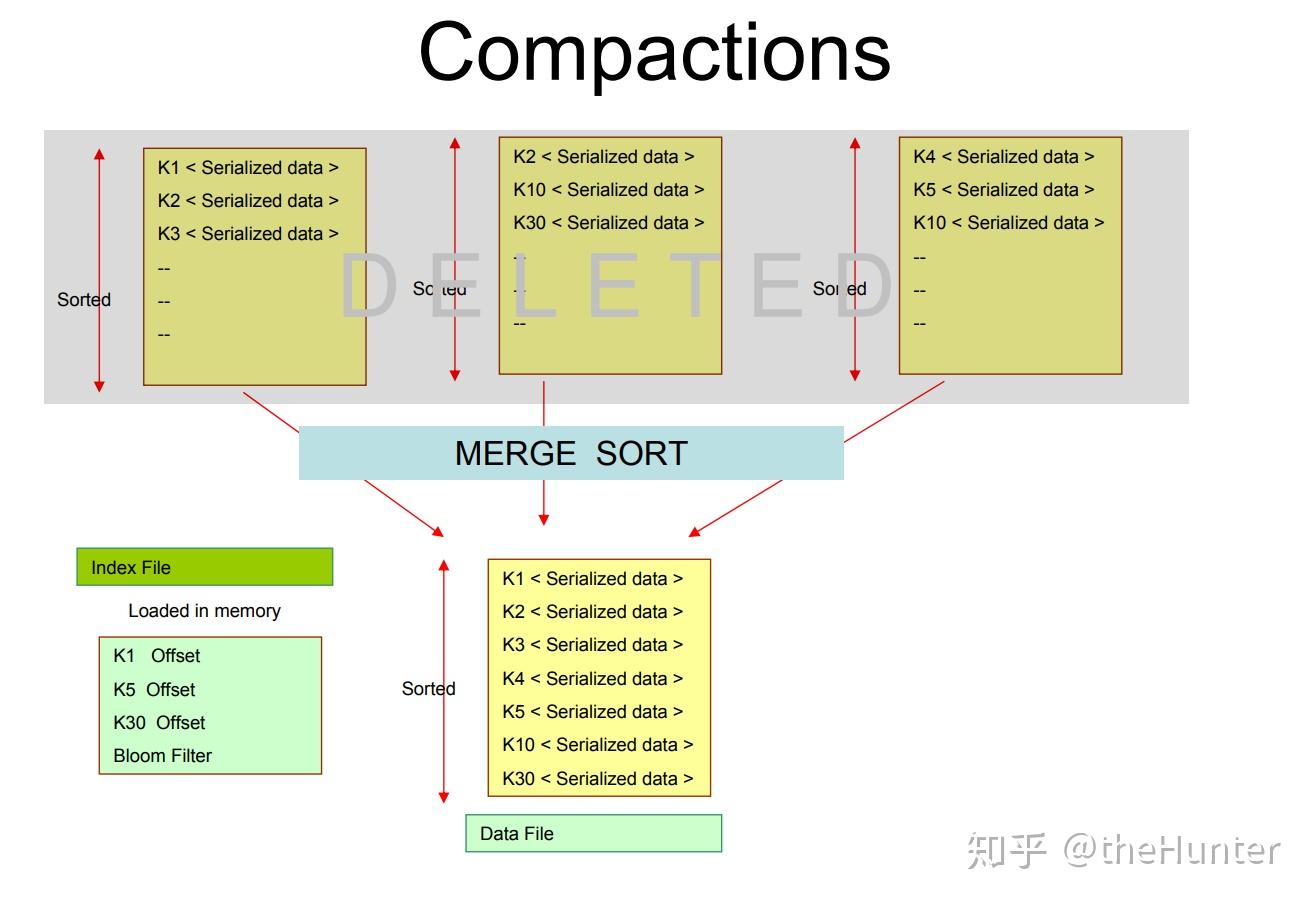
随着时间的推移许多这样的文件被写在磁盘上,后台有一个merge程序负责把不同的文件合并成一个文件。这个过程和Bigtable中的compaction process非常相似。
READ
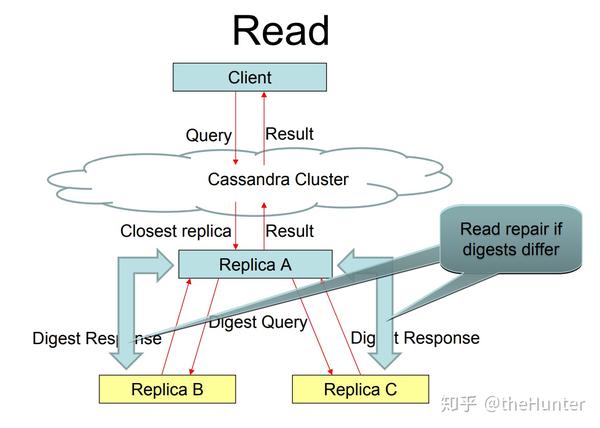
典型的read操作首先查询in-memory数据结构,然后才会在disk上检索文件。按新到旧的顺序查看文件。当一个涉及到磁盘的查找发生时,可能在磁盘上多个文件中查询key。为了避免在没有包含key的files中查询,用到了bloom filter。首先,在bloom filter中检查对应的key是否存在于给定的file中。另外,一个column family中的key可能有很多columns。为了防止扫描磁盘上的每个column,维护一个column索引以减少工作量。


6 实现细节(Implementation Details)
在一台机器上的Cassandra程序主要有下面部分构成:partitioning module, cluster membership, failure detection module, storage engine module。每个module依赖于事件驱动。message processing pipeline 和 task pipeline 被分在SEDA的多个级别上(参考:Seda: an architecture for well-conditioned, scalable internet services. )。而且这些module都是用Java实现的。The cluster membership 和 failure detection模块构建在非阻塞的I/O网络层上面。所有系统控制信息依赖于UDP传递,但是replication和request routing是依赖于TCP传递的。request routing模块使用状态机实现。当Read/Write请求到达集群中的任何node时,状态机在下面的状态中变化:(1) 识别负责这个key相关数据的node (2)把请求路由到nodes然后等待返回的响应 (3)如果replica没能在配置的timeout内返回响应,请求被标记失败并返回给客户端 (4)根据时间戳确定最新的响应 (5)如果replica上没有最新的数据,则在其上repair data。对于那些明确要高吞吐量的系统,可以使用异步replication。在同步模式下,把结果返回给客户端前必须等待法定数量的响应。
Cassandra系统根据主键索引所有的数据。磁盘上的数据文件被分解为一系列的blocks。每个block最多包含128个key,并且由块索引划分。块索引捕获block内key的相对偏移及其数据大小。将 in-memory data structure 转储到磁盘时,会生成块索引,并将其偏移量作为索引写入磁盘。该索引也在内存中以便于快速访问。一个典型的READ操作总是先在in-memory data structure里找寻数据,如果包含了key的最新数据,那么返回到application。但是如果没有找到,就执行disk I/O去查找。
Cassandra额外扩展资料: https:// docs.datastax.com/en/ar chived/cassandra/1.0/docs/
