神经网络在实战中遇到的最大的问题就是数据量不够大,数据量不足会导致最后的效果不佳。
有很多机构,构造了自己的网络后,将ImageNet上海量的图片输入到网络中训练,最后得到了识别率很高的网络,入股他们愿意把劳动成果分享出来,我们就可以直接借用。
后面我们将使用一个大型卷积网络,它经过了大量数据的严格训练,这些图片数据来源于ImageNet,该网站包含140万张图片资源,这些图片大多涉及我们日常生活的物品以及常见动物,显然很多不同种类的猫和狗必然包含在内。我们将使用一个训练好的神经网络叫VGG16
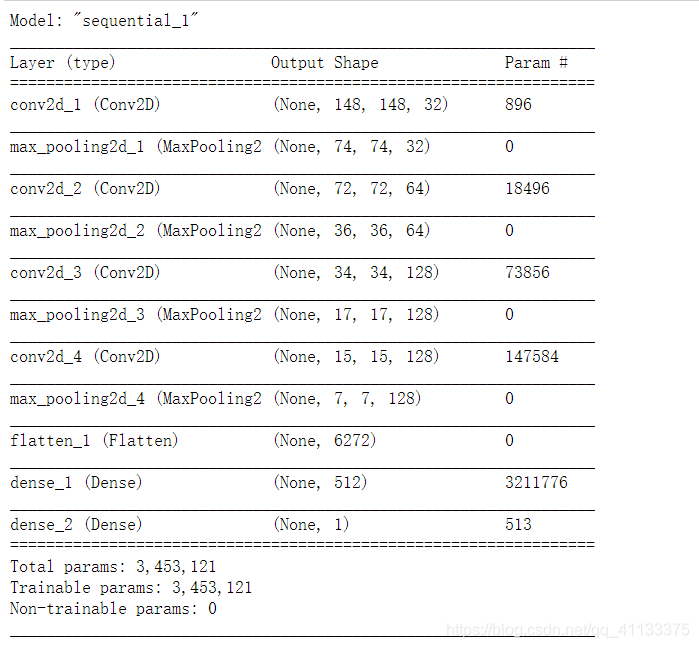
在我们构造卷积网络时,一开始先是好几层卷积层和Max Pooling层,然后会调用Flatten()把他们输出的多维向量压扁后,传入到普通层:
from keras import layers
from keras import models
from keras import optimizers
model = models.Sequential()
model.add(layers.Conv2D(32, (3,3), activation='relu', input_shape=(150 , 150, 3)))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(64, (3,3), activation='relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(128, (3,3), activation='relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(128, (3,3), activation='relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])
model.summary()

我们现在要借用的的VGG16网络,其结构与上面差不多,只不过它的Conv2D和MaxPooling层要比我们上面做的多得多而已。在我们借用别人训练好的网络时,往往要去掉Flatten()后面的网络层,因为那些网络层与别人构造网络时的具体应用场景相关,他们的应用场景与我们肯定不同,我们要借用的是Flatten上面那些由卷积层和Max Pooling层输出的结果,这些结果蕴含着对训练图片本质的认知,这才是我们想要的,去掉Flatten后面的神经层,换上我们自己的神经层,这个行为就叫特征抽取,具体流程如下图:

VGG16网络早已包含在keras框架中,我们可以方便的直接引用:
from keras.applications import VGG16
conv_base = VGG16(weights = 'vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5', include_top = False, input_shape=(150, 150, 3))
conv_base.summary()
weight参数告诉程序将网络的卷积层和max pooling层对应的参数传递过来,并将它们初始化成对应的网络层次。
include_top表示是否也要把Flatten()后面的网络层也下载过来,VGG16对应的这层网络用来将图片划分到1000个不同类别中,由于我们只用来区分猫狗两个类别,因此我们去掉它这一层。
input_shape告诉网络,我们输入图片的大小是150*150像素,每个像素由[R, G, B]三个值表示。

注意:上面这段代码第一次运行会到giuhub上下载一个文件,如果网速不太好可以复制它给的网站到手机上下载,实在不行的话试试科学上网。
从上面输出结果看出,VGG16的网络结构与我们前面做的网络差不多,只不过它的层次要比我们多不少。最后的(None, 4, 4, 512)表示它将输出44的矩阵,而这些矩阵有512层,或者你也可以看成它将输出一个44的矩阵,而矩阵每个元素是包含512个值的向量。
将我们自己的图片读进来,将图片输入上面网络,让它把图片的隐含信息给抽取出来:
import os
import numpy as np
from
keras.preprocessing.image import ImageDataGenerator
base_dir = 'D:/Workspaces/Jupyter-notebook/datasets/mldata/cats_and_dogs_small'
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
test_dir = os.path.join(base_dir, 'test')
datagen = ImageDataGenerator(rescale = 1. / 255)
batch_size = 20
def extract_features(directory, sample_count):
features = np.zeros(shape = (sample_count, 4, 4, 512))
labels = np.zeros(shape = (sample_count))
generator = datagen.flow_from_directory(directory, target_size = (150, 150),
batch_size = batch_size,
class_mode = 'binary')
i = 0
for inputs_batch, labels_batch in generator:
features_batch = conv_base.predict(inputs_batch)
features[i * batch_size : (i + 1)*batch_size] = features_batch
labels[i * batch_size : (i+1)*batch_size] = labels_batch
i += 1
if i * batch_size >= sample_count :
break
return features , labels
train_features, train_labels = extract_features(train_dir, 2000)
validation_features, validation_labels = extract_features(validation_dir, 1000)
test_features, test_labels = extract_features(test_dir, 1000)
上面代码利用VGG16的卷积层把图片的特征抽取出来,接下来我们就可以吧抽取的特征输入到我们自己的神经层中进行分类,代码如下:
train_features = np.reshape(train_features, (2000, 4 * 4 * 512))
validation_features = np.reshape(validation_features, (1000, 4 * 4 * 512))
test_features = np.reshape(test_features, (1000, 4 * 4* 512))
from keras import models
from keras import layers
from keras import optimizers
model = models.Sequential()
model.add(layers.Dense(256, activation='relu', input_dim = 4 * 4 * 512))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(1, activation = 'sigmoid'))
model.compile(optimizer=optimizers.RMSprop(lr = 2e-5), loss = 'binary_crossentropy', metrics = ['acc'])
history = model.fit(train_features, train_labels, epochs = 30, batch_size = 20,
validation_data = (validation_features, validation_labels))
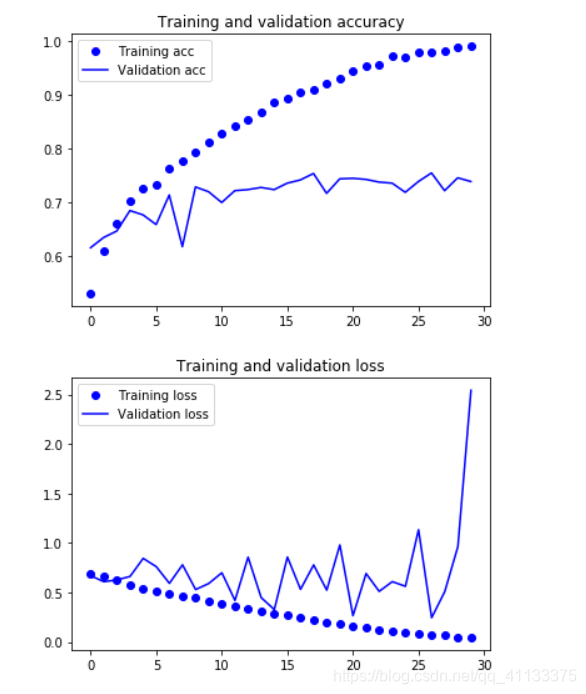
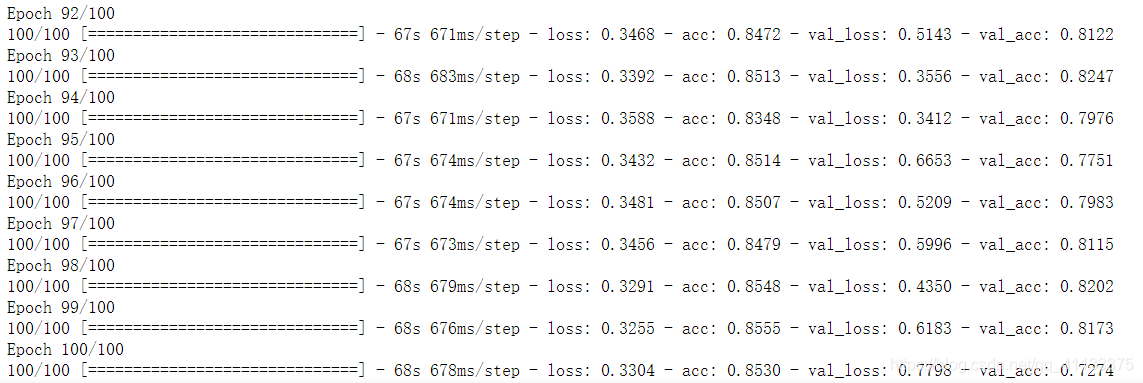
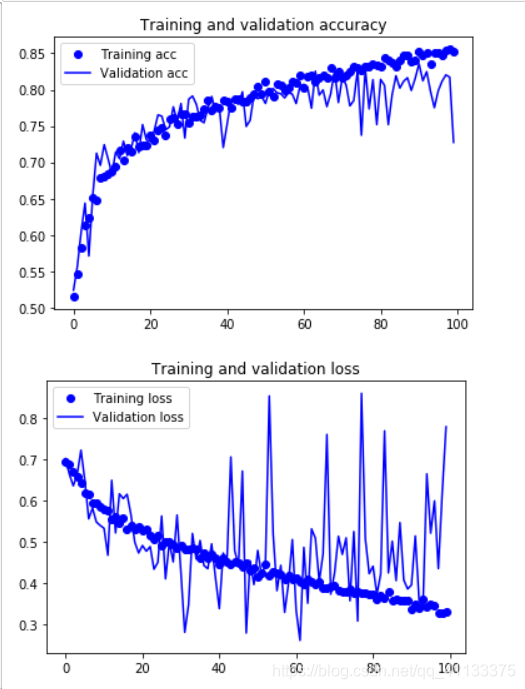
部分结果展示:

由于我们不需要训练卷积层,因此上面代码运行会很快,我们把训练结果和校验结果画出来看看:
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label = 'Train_acc')
plt.plot(epochs, val_acc, 'b', label = 'Validation acc')
plt.title('Trainning and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label = 'Training loss')
plt.plot(epochs, val_loss, 'b', label = 'Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()

从上面图可以看出,经过一百多万张图片训练的网络,其识别效果就要比我们用4000张图片训练的网络要好很多,网络对图片的校验正确率达到了99%以上,同时对训练数据和校验数据的损失估计完全是一模一样的。
上面的方法叫特征提取,还有一种方法叫参数调优。特征提取时,我们把图片输入VGG16的卷积层,让他直接帮我们把图片中的特征提取出来,我们并没有通过自己的图片去训练更改VGG16的卷积层。
参数调优的做法在于,我们会有限度的通过自己的数据去训练VGG16提供的卷积层,于是让其能从我们的图片中学习到相关信息。我们从VGG16模型中获取了它六层卷积层,我们在调优时,让这六层卷积层中的最高2层也去学习我们的图片,于是最高两层的链路权重参数会根据我们的图片性质而更改,基本情况如下:
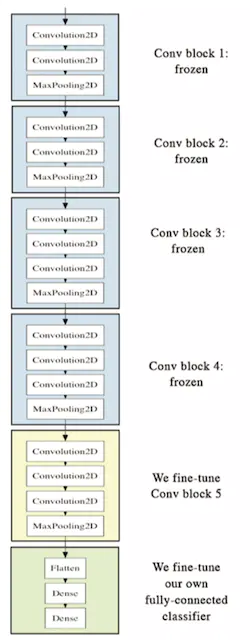
上图就是我们从VGG16拿到的卷积层,我们用自己的图片去训练修改它最高的两层,其他层次不做修改,这种只影响模型一部分的方法就叫参数调优。调优必须只对VGG16的卷积层做小范围修改,因为它的模型是经过大数据,反复训练得到的,如果我们对它进行大范围修改,就会破坏它原来训练的结果,这样人家辛苦做出来的工作成果就会被我们毁于一旦。
参数调优的步骤如下:
- 将我们自己的网络层添加到VGG16的卷积层之上。
- 固定VGG16的卷积层保持不变。
- 用数据训练我们自己添加的网络层。
- 将VGG16的卷积层最高两层放开。
- 用数据同时训练放开的那两层卷积层和我们自己添加的网络层。
代码展示:
model = models.Sequential()
model.add(conv_base)
model.add(layers.Flatten())
model.add(layers.Dense(256, activation = 'relu'))
model.add(layers.Dense(1, activation = 'sigmoid'))
model.summary()

从上面输出结果看,VGG16的卷积层已经有一千多万个参数了!用个人电脑单个CPU是不可能对这个模型进行训练的!但我们可以训练它的其中一部分,我们把它最高三层与我们自己的网络层结合在一起训练,同时冻结最低四层。下面的代码将会把卷积层进行部分冻结:
conv_base.trainable = True
set_trainable = False
for layer in conv_base.layers:
if layer.name == 'block5_conv1':
set_trainable = True
if set_trainable:
layer.trainable = True
else:
layer.trainable = False
然后我们把数据传入网络,训练给定的卷积层和我们自己的网络层:
test_datagen = ImageDataGenerator(rescale = 1. / 255)
train_generator = test_datagen.flow_from_directory(train_dir, target_size = (150, 150), batch_size = 20,
class_mode = 'binary')
validation_generator = test_datagen.flow_from_directory(validation_dir, target_size = (150,150),
batch_size = 20,
class_mode = 'binary')
model.compile(loss = 'binary_crossentropy', optimizer = optimizers.RMSprop(2e-5),
metrics = ['acc'])
history = model.fit_generator(train_generator, steps_per_epoch = 100, epochs = 30,
validation_data = validation_generator,
validation_steps = 50)
部分运行结果:
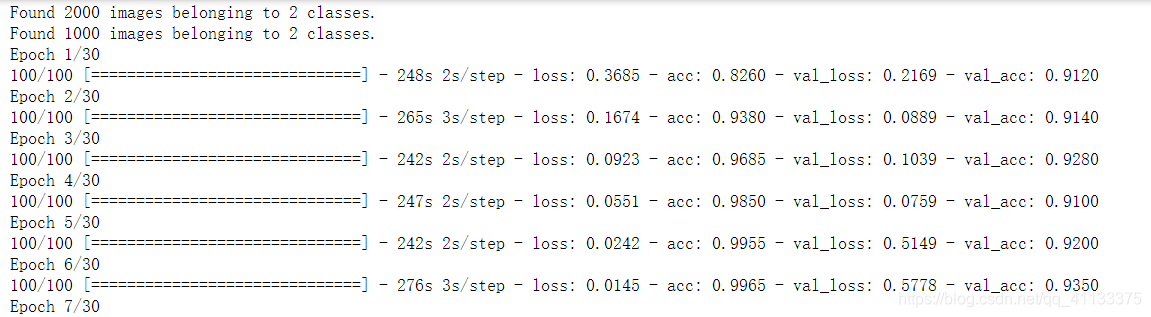
由于是用的cpu跑的,所以跑的非常慢,使用gpu可能会快点。
基于`tensorFlow`框架搭建神经网络,从零开始一步步完成数据读取、网络构建、模型训练和模型测试等过程,最终实现一个可以进行猫狗图像分类的分类器;并借助数据增强技术,例如旋转、翻转、缩放等,来增加数据集的多样性,从而提高模型的泛化能力和鲁棒性。
数据集包含25000张图片,猫和狗各有12500张;创建每个类别1000个样本的训练集、500个样本的验证集和500个样本的测试集(只使用部分数据进行建模)
import os
import shutil
current_dir = %pwd
current_dir #当前目录
base_dir = current_
NLP中一个最基本任务就是分词,当我们分词完成之后怎么来评判分词结果的好坏呢?换句话来说就是我该如何对分词结果打分?这个分数怎么算法,依照的标准是什么?例如:
原句子:武汉市长江大桥
分词一:武汉 市长 江大桥
分词二: 武汉市 长江大桥
对于分词一和分词二的打分应该是多少呢?为了搞清楚这个问题,我们先来学习(回顾)一些机器学习中的常见分类评估标准。
2.机器学习中的分类评估
2.1...
现在将已掌握的知识进行总结,方便以后自己写网络增加思路。
首先数据集下载:链接:https://pan.baidu.com/s/1U4N0PCNfyIP9iHLidVb9xA 提取码:vcvl
keras框架中文文档:https://keras.io/zh/ 英文文档: https://keras.io/
说一下这个数据集的构成:
train文件夹下有25000张猫狗照片,猫和狗各1...
数据集的读取,查阅了那么多文档,大致了解到,数据集的读取方法大概会分为两种
1、先生成图片list,和标签list,把图片名称和标签对应起来,再读取制作迭代器(个人认为此方法一般用在,图片名称...
dogs VS cats1.数据准备2.训练参数及配置2.1 基础训练2.2 对比实验(无数据增强)2.3 对比实验(不用预训练模型)2.4 对比实验(改变学习率)
此项目是kaggle大赛的经典项目.
通过对比实验验证数据增强对降低模型过拟合风险的作用.
对预训练模型进行微调达到加快模型收敛的效果.
对比不同初始学习率,固定部分参数层对模型训练过程的影响
1.数据准备
下载cats vs ...