

Oracle分析函数

Oracle分析函数
转载自
Oracle分析函数——函数列表
SUM :该函数计算组中表达式的累积和
MIN :在一个组中的数据窗口中查找表达式的最小值
MAX :在一个组中的数据窗口中查找表达式的最大值
AVG :用于计算一个组和数据窗口内表达式的平均值。
COUNT :对一组内发生的事情进行累积计数
-------------------------------------------------------------------------------------------------
RANK :根据ORDER BY子句中表达式的值,从查询返回的每一行,计算它们与其它行的相对位置
DENSE_RANK :根据ORDER BY子句中表达式的值,从查询返回的每一行,计算它们与其它行的相对位置
FIRST :从DENSE_RANK返回的集合中取出排在最前面的一个值的行
LAST :从DENSE_RANK返回的集合中取出排在最后面的一个值的行
FIRST_VALUE :返回组中数据窗口的第一个值
LAST_VALUE :返回组中数据窗口的最后一个值。
LAG :可以访问结果集中的其它行而不用进行自连接
LEAD :LEAD与LAG相反,LEAD可以访问组中当前行之后的行
ROW_NUMBER:返回有序组中一行的偏移量,从而可用于按特定标准排序的行号
-------------------------------------------------------------------------------------------------
STDDEV :计算当前行关于组的标准偏离
STDDEV_POP:该函数计算总体标准偏离,并返回总体变量的平方根
STDDEV_SAMP:该函数计算累积样本标准偏离,并返回总体变量的平方根
VAR_POP :该函数返回非空集合的总体变量(忽略null)
VAR_SAMP :该函数返回非空集合的样本变量(忽略null)
VARIANCE :如果表达式中行数为1,则返回0,如果表达式中行数大于1,则返回VAR_SAMP
COVAR_POP :返回一对表达式的总体协方差
COVAR_SAMP:返回一对表达式的样本协方差
CORR :返回一对表达式的相关系数
-------------------------------------------------------------------------------------------------
CUME_DIST :计算一行在组中的相对位置
NTILE :将一个组分为"表达式"的散列表示
PERCENT_RANK:和CUME_DIST(累积分配)函数类似
PERCENTILE_DISC:返回一个与输入的分布百分比值相对应的数据值
PERCENTILE_CONT:返回一个与输入的分布百分比值相对应的数据值
RATIO_TO_REPORT:该函数计算expression/(sum(expression))的值,它给出相对于总数的百分比
REGR_ (Linear Regression) Functions:这些线性回归函数适合最小二乘法回归线,有9个不同的回归函数可使用
-------------------------------------------------------------------------------------------------
CUBE :按照OLAP的CUBE方式进行数据统计,即各个维度均需统计
ROLLUP :
SELECT
department_id,
manager_id,
employee_id,
first_name||' '||last_name employee_name,
hire_date,
salary,
job_id
FROM employees
ORDER BY department_id,hire_date
Oracle分析函数实际上操作对象是查询出的数据集,也就是说不需二次查询 数据库 ,实际上就是oracle实现了一些我们自身需要编码实现的统计功能,对于简化开发工作量有很大的帮助,特别在开发第三方 报表 软件 时是非常有帮助的。Oracle从8.1.6开始提供分析函数。
oracle分析函数的语法:
function_name(arg1,arg2,...)
over
( )
说明:
1. partition-clause 数据记录集分组
2. order-by-clause 数据记录集排序
3. windowing clause 功能非常强大、比较复杂,定义分析函数在操作行的集合。有三种开窗方式: range、row、specifying。
--Partition by,按相应的值(manager_id)进行分组统计
SELECT
manager_id,
first_name||' '||last_name employee_name,
hire_date,
salary,
AVG(salary) OVER (PARTITION BY manager_id) avg_salary
FROM employees;
--等同于上面
SELECT
a.manager_id,
a.employee_name,
a.hire_date,
a.salary,
b.avg_salary
FROM
(
SELECT
manager_id,
first_name||' '||last_name employee_name,
hire_date,
salary
FROM employees
) a,
(
SELECT
manager_id,
AVG(salary) avg_salary
FROM employees
GROUP BY manager_id
) b
WHERE a.manager_id=b.manager_id
ORDER BY a.manager_id
--Order by按相应的值(hire_date)进行排序并累计统计
SELECT
manager_id,
first_name||' '||last_name employee_name,
hire_date,
salary,
AVG(salary) OVER (ORDER BY hire_date)
FROM employees;
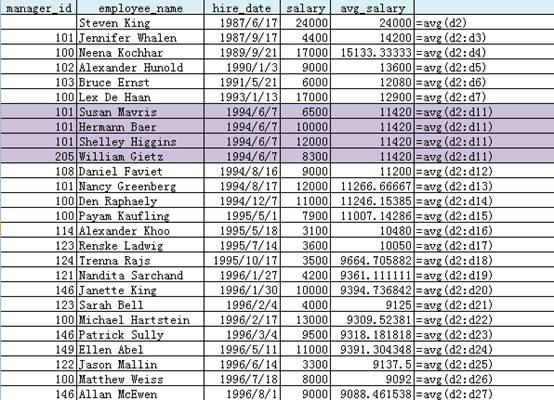
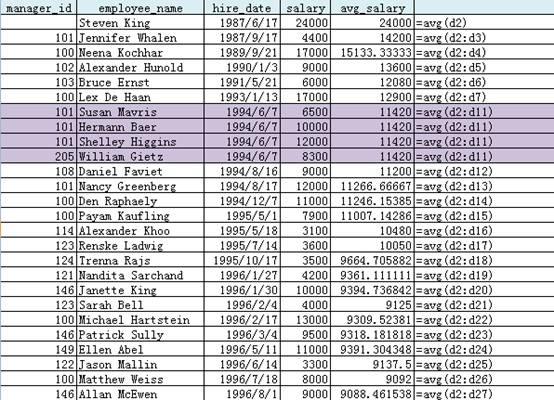
--Partition by Order by首先按相应的值(manager_id,hire_date)排序,并按order by的值(hire_date)进行累计统计
SELECT
manager_id,
first_name||' '||last_name employee_name,
hire_date,
salary,
AVG(salary) OVER (PARTITION BY manager_id ORDER BY hire_date)
FROM employees;
--Partition by Order by首先按相应的值(manager_id,hire_date)排序,并按order by的值(hire_date)进行累计统计
--该平均值由当前员工和与之具有相同经理的前一个和后两个三者的平均数得来
SELECT
manager_id,
first_name||' '||last_name employee_name,
hire_date,
salary,
AVG(salary) OVER (PARTITION BY manager_id ORDER BY hire_date ROWS BETWEEN 1 PRECEDING AND 2 FOLLOWING)
FROM employees;
--Partition by Order by首先按相应的值(manager_id,hire_date)排序,并按order by的值(hire_date)进行累计统计
--该平均值由当前员工和与之具有相同经理,并且雇用时间在该员工时间之前的50天以内和在该员工之后的150天之内员工的薪水的平均值
--range为取值范围,估计只有数字和日期能够进行取值了
SELECT
manager_id,
first_name||' '||last_name employee_name,
hire_date,
salary,
AVG(salary) OVER (PARTITION BY manager_id ORDER BY hire_date RANGE BETWEEN 50 PRECEDING AND 150 FOLLOWING)
FROM employees;
--Partition by Order by首先按相应的值(manager_id,hire_date)排序,并按order by的值(hire_date)进行累计统计
--该平均值由当前员工和与之具有相同经理的平均值
--每行对应的数据窗口是从第一行到最后一行
SELECT
manager_id,
first_name||' '||last_name employee_name,
hire_date,
salary,
AVG(salary) OVER (PARTITION BY manager_id ORDER BY hire_date) avg_salary_part_order,
AVG(salary) OVER (PARTITION BY manager_id ) avg_salary_order,
AVG(salary) OVER (PARTITION BY manager_id ORDER BY hire_date RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) avg_salary_unbound1, --等同于仅partition时候的值
AVG(salary) OVER (PARTITION BY manager_id ORDER BY hire_date ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) avg_salary_unbound2--等同于上面
FROM employees;
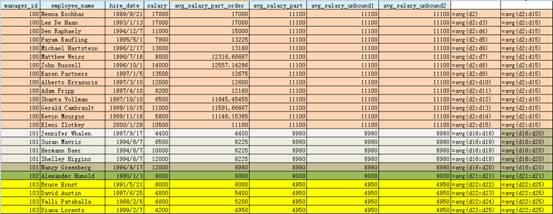
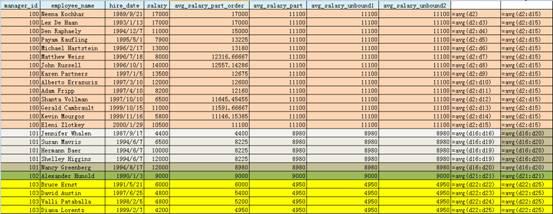
Oracle分析函数——SUM,AVG,MIN,MAX,COUNT
SUM
功能描述:该函数计算组中表达式的累积和。
SAMPLE:下例计算同一经理下员工的薪水累积值
MIN
功能描述:在一个组中的数据窗口中查找表达式的最小值。
SAMPLE:下面例子中dept_min返回当前行所在部门的最小薪水值
MAX
功能描述:在一个组中的数据窗口中查找表达式的最大值。
SAMPLE:下面例子中dept_max返回当前行所在部门的最大薪水值
AVG
功能描述:用于计算一个组和数据窗口内表达式的平均值。
SAMPLE:下面的例子中列c_mavg计算员工表中每个员工的平均薪水报告
SELECT
department_id,
first_name||' '||last_name employee_name,
hire_date,
salary,
MIN(salary) OVER (PARTITION BY department_id order by hire_date) AS dept_min,
MAX(salary) OVER (PARTITION BY department_id order by hire_date) AS dept_max,
AVG(salary) OVER (PARTITION BY department_id order by hire_date) AS dept_avg,
SUM(salary) OVER (PARTITION BY department_id order by hire_date) AS dept_sum/*,
COUNT(*) OVER (ORDER BY salary) AS count_by_salary,
COUNT(*) OVER (ORDER BY salary RANGE BETWEEN 50 PRECEDING AND 150 FOLLOWING) AS count_by_salary_range*/
FROM employees
COUNT
功能描述:对一组内发生的事情进行累积计数,如果指定*或一些非空常数,count将对所有行计数,如果指定一个表达式,count返回表达式非空赋值的计数,当有相同值出现时,这些相等的值都会被纳入被计算的值;可以使用DISTINCT来记录去掉一组中完全相同的数据后出现的行数。
SAMPLE:下面例子中计算每个员工在按薪水排序中当前行附近薪水在[n-50,n+150]之间的行数,n表示当前行的薪水
例如,Philtanker的薪水2200,排在他之前的行中薪水大于等于2200-50的有1行,排在他之后的行中薪水小于等于2200+150的行没有,所以count计数值cnt3为2(包括自己当前行);cnt2值相当于小于等于当前行的SALARY值的所有行数
SELECT
department_id,
first_name||' '||last_name employee_name,
salary,
COUNT(*) OVER (ORDER BY salary) AS count_by_salary,
COUNT(*) OVER (ORDER BY salary RANGE BETWEEN 50 PRECEDING AND 150 FOLLOWING) AS count_by_salary_range
FROM employees
WHERE department_id in (10,20,30);
Oracle分析函数——函数RANK,DENSE_RANK,FIRST,LAST…
RANK
功能描述:根据ORDER BY子句中表达式的值,从查询返回的每一行,计算它们与其它行的相对位置。组内的数据按ORDER BY子句排序,然后给每一行赋一个号,从而形成一个序列,该序列从1开始,往后累加。每次ORDER BY表达式的值发生变化时,该序列也随之增加。有同样值的行得到同样的数字序号(认为null时相等的)。然而,如果两行的确得到同样的排序,则序数将随后跳跃。若两行序数为1,则没有序数2,序列将给组中的下一行分配值3,DENSE_RANK则没有任何跳跃。
SAMPLE:下例中计算每个员工按部门分区再按薪水排序,依次出现的序列号(注意与DENSE_RANK函数的区别)
DENSE_RANK
功能描述:根据ORDER BY子句中表达式的值,从查询返回的每一行,计算它们与其它行的相对位置。组内的数据按ORDER BY子句排序,然后给每一行赋一个号,从而形成一个序列,该序列从1开始,往后累加。每次ORDER BY表达式的值发生变化时,该序列也随之增加。有同样值的行得到同样的数字序号(认为null时相等的)。密集的序列返回的时没有间隔的数
SAMPLE:下例中计算每个员工按部门分区再按薪水排序,依次出现的序列号(注意与RANK函数的区别)
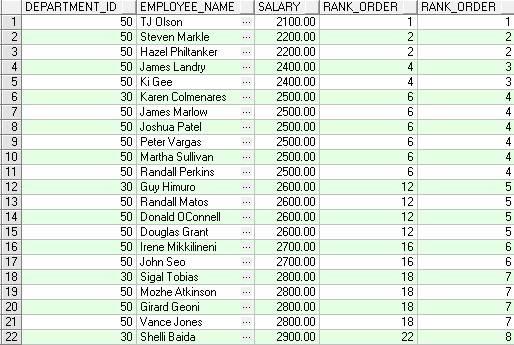
SELECT
department_id,
first_name||' '||last_name employee_name,
salary,
RANK() OVER (ORDER BY salary) AS RANK_ORDER,
DENSE_RANK() OVER (ORDER BY salary) AS DENSE_RANK_ORDER
FROM employees
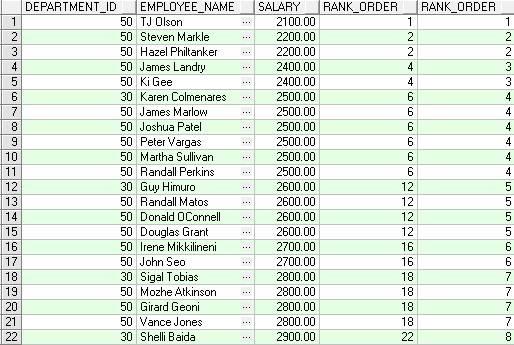
SELECT
department_id,
first_name||' '||last_name employee_name,
salary,
RANK() OVER (PARTITION BY department_id ORDER BY salary) AS RANK_PART_ORDER,
DENSE_RANK() OVER (PARTITION BY department_id ORDER BY salary) AS DENSE_RANK_PART_ORDER
FROM employees
Oracle分析函数——统计分析函数
方差和标准差:
样本中各数据与样本平均数的差的平方和的平均数叫做样本方差;样本方差的算术平方根叫做样本标准差。样本方差和样本标准差都是衡量一个样本波动大小的量,样本方差或样本标准差越大,样本数据的波动就越大。
数学上一般用E{[X-E(X)]^2}来度量随机变量X与其均值E(X)即期望的偏离程度,称为X的方差。
方差是标准差的平方
方差和标准差。方差和标准差是测算离散趋势最重要、最常用的指标。方差是各变量值与其均值离差平方的平均数,它是测算数值型数据离散程度的最重要的方法。标准差为方差的平方根,用S表示。
StdDev返回expr的样本标准偏差。它可用作聚集和分析函数。它与stddev_samp的不同之处在于,当计算的输入数据只有一行时,stddev返回0,而stddev_samp返回null。
Oracle 数据库 中,标准偏差计算结果与variance用作集聚函数计算结果的平方根相等。该函数参数可取任何数字类型或是任何能隐式转换成数字类型的非数字类型。
STDDEV
功能描述:计算当前行关于组的标准偏离。(Standard Deviation)
SAMPLE:
STDDEV_SAMP
功能描述:该函数计算累积样本标准偏离,并返回总体变量的平方根,其返回值与VAR_POP函数的平方根相同。(Standard Deviation-Sample)
SAMPLE:
它与stddev_samp的不同之处在于,当计算的输入数据只有一行时,stddev返回0,而stddev_samp返回null。
SELECT
department_id,
first_name||' '||last_name employee_name,
hire_date,
salary,
STDDEV_SAMP(salary) OVER (PARTITION BY department_id ORDER BY hire_date) AS cum_sdev
FROM employees
WHERE department_id in (20,30,60);
STDDEV和STDDEV_SAMP的区别
SELECT
first_name||' '||last_name employee_name,
hire_date,
salary,
STDDEV(salary) OVER (ORDER BY hire_date) "StdDev",
STDDEV_SAMP(salary) OVER (ORDER BY hire_date) AS cum_sdev
FROM employees
VAR_POP
功能描述:(Variance Population)该函数返回非空集合的总体变量(忽略null),VAR_POP进行如下计算:
(SUM(expr2) - SUM(expr)2 / COUNT(expr)) / COUNT(expr)
VAR_SAMP
功能描述:(Variance Sample)该函数返回非空集合的样本变量(忽略null),VAR_POP进行如下计算:
(SUM(expr*expr)-SUM(expr)*SUM(expr)/COUNT(expr))/(COUNT(expr)-1)
SAMPLE:
VARIANCE
功能描述:该函数返回表达式的变量,Oracle计算该变量如下:
如果表达式中行数为1,则返回0
如果表达式中行数大于1,则返回VAR_SAMP
SAMPLE:
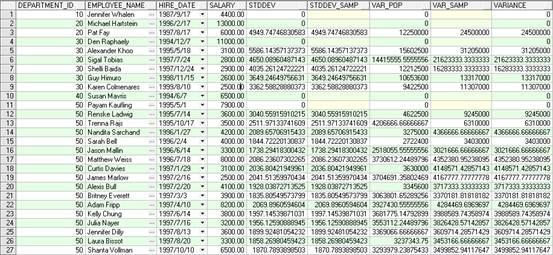
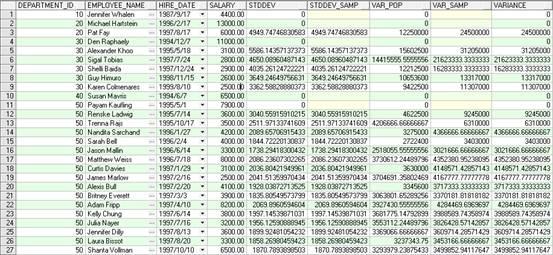
SELECT
department_id,
first_name||' '||last_name employee_name,
hire_date,
salary,
STDDEV(salary) OVER (PARTITION BY department_id ORDER BY hire_date) AS "STDDEV",
STDDEV_SAMP(salary) OVER (PARTITION BY department_id ORDER BY hire_date) AS "STDDEV_SAMP",
VAR_POP(salary) OVER (PARTITION BY department_id ORDER BY hire_date) AS "VAR_POP",
VAR_SAMP(salary) OVER (PARTITION BY department_id ORDER BY hire_date) AS "VAR_SAMP",
VARIANCE(salary) OVER (PARTITION BY department_id ORDER BY hire_date) AS "VARIANCE"
FROM employees
协方差分析是建立在方差分析和回归分析基础之上的一种统计分析方法。
方差分析是从质量因子的角度探讨因素不同水平对实验指标影响的差异。一般说来,质量因子是可以人为控制的。
回归分析是从数量因子的角度出发,通过建立回归方程来研究实验指标与一个(或几个)因子之间的数量关系。但大多数情况下,数量因子是不可以人为加以控制的。
两个不同参数之间的方差就是协方差
若两个随机变量X和Y相互独立,则E[(X-E(X))(Y-E(Y))]=0,因而若上述数学期望不为零,则X和Y必不是相互独立的,亦即它们之间存在着一定的关系。
定义
E[(X-E(X))(Y-E(Y))]称为随机变量X和Y的协方差,记作COV(X,Y),即COV(X,Y)=E[(X-E(X))(Y-E(Y))]。
COVAR_POP
功能描述:返回一对表达式的总体协方差。
SAMPLE:
COVAR_SAMP
功能描述:返回一对表达式的样本协方差
SAMPLE:
SELECT
a.department_id,
a.employee_id,
b.employee_id manager_id,
a.first_name||' '||a.last_name employee_name,
b.first_name||' '||b.last_name manager_name,
a.hire_date,
a.salary employee_salary,
b.salary manager_salary,
COVAR_POP(a.salary,b.salary) OVER (ORDER BY a.department_id,a.hire_date ) AS CUM_COVP,
COVAR_SAMP(a.salary,b.salary) OVER (ORDER BY a.department_id,a.hire_date ) AS CUM_SAMP
FROM employees a,employees b
WHERE a.manager_id=b.employee_id(+)
CORR
功能描述:返回一对表达式的相关系数,它是如下的缩写:
COVAR_POP(expr1,expr2)/STDDEV_POP(expr1)*STDDEV_POP(expr2))
从统计上讲,相关性是变量之间关联的强度,变量之间的关联意味着在某种程度
上一个变量的值可由其它的值进行预测。通过返回一个-1~1之间的一个数,相关
系数给出了关联的强度,0表示不相关。
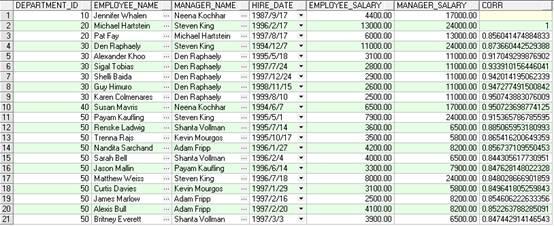
SELECT
a.department_id,
a.first_name||' '||a.last_name employee_name,
b.first_name||' '||b.last_name manager_name,
a.hire_date,
a.salary employee_salary,
b.salary manager_salary,
CORR(a.salary,b.salary) OVER (ORDER BY a.department_id,a.hire_date ) AS CORR
FROM employees a,employees b
WHERE a.manager_id=b.employee_id(+)
Oracle分析函数——统计分析函数
方差和标准差:
样本中各数据与样本平均数的差的平方和的平均数叫做样本方差;样本方差的算术平方根叫做样本标准差。样本方差和样本标准差都是衡量一个样本波动大小的量,样本方差或样本标准差越大,样本数据的波动就越大。
数学上一般用E{[X-E(X)]^2}来度量随机变量X与其均值E(X)即期望的偏离程度,称为X的方差。
方差是标准差的平方
方差和标准差。方差和标准差是测算离散趋势最重要、最常用的指标。方差是各变量值与其均值离差平方的平均数,它是测算数值型数据离散程度的最重要的方法。标准差为方差的平方根,用S表示。
StdDev返回expr的样本标准偏差。它可用作聚集和分析函数。它与stddev_samp的不同之处在于,当计算的输入数据只有一行时,stddev返回0,而stddev_samp返回null。
Oracle 数据库 中,标准偏差计算结果与variance用作集聚函数计算结果的平方根相等。该函数参数可取任何数字类型或是任何能隐式转换成数字类型的非数字类型。
STDDEV
功能描述:计算当前行关于组的标准偏离。(Standard Deviation)
SAMPLE:
STDDEV_SAMP
功能描述:该函数计算累积样本标准偏离,并返回总体变量的平方根,其返回值与VAR_POP函数的平方根相同。(Standard Deviation-Sample)
SAMPLE:
它与stddev_samp的不同之处在于,当计算的输入数据只有一行时,stddev返回0,而stddev_samp返回null。
SELECT
department_id,
first_name||' '||last_name employee_name,
hire_date,
salary,
STDDEV_SAMP(salary) OVER (PARTITION BY department_id ORDER BY hire_date) AS cum_sdev
FROM employees
WHERE department_id in (20,30,60);
STDDEV和STDDEV_SAMP的区别
SELECT
first_name||' '||last_name employee_name,
hire_date,
salary,
STDDEV(salary) OVER (ORDER BY hire_date) "StdDev",
STDDEV_SAMP(salary) OVER (ORDER BY hire_date) AS cum_sdev
FROM employees
VAR_POP
功能描述:(Variance Population)该函数返回非空集合的总体变量(忽略null),VAR_POP进行如下计算:
(SUM(expr2) - SUM(expr)2 / COUNT(expr)) / COUNT(expr)
VAR_SAMP
功能描述:(Variance Sample)该函数返回非空集合的样本变量(忽略null),VAR_POP进行如下计算:
(SUM(expr*expr)-SUM(expr)*SUM(expr)/COUNT(expr))/(COUNT(expr)-1)
SAMPLE:
VARIANCE
功能描述:该函数返回表达式的变量,Oracle计算该变量如下:
如果表达式中行数为1,则返回0
如果表达式中行数大于1,则返回VAR_SAMP
SAMPLE:
SELECT
department_id,
first_name||' '||last_name employee_name,
hire_date,
salary,
STDDEV(salary) OVER (PARTITION BY department_id ORDER BY hire_date) AS "STDDEV",
STDDEV_SAMP(salary) OVER (PARTITION BY department_id ORDER BY hire_date) AS "STDDEV_SAMP",
VAR_POP(salary) OVER (PARTITION BY department_id ORDER BY hire_date) AS "VAR_POP",
VAR_SAMP(salary) OVER (PARTITION BY department_id ORDER BY hire_date) AS "VAR_SAMP",
VARIANCE(salary) OVER (PARTITION BY department_id ORDER BY hire_date) AS "VARIANCE"
FROM employees
协方差分析是建立在方差分析和回归分析基础之上的一种统计分析方法。
方差分析是从质量因子的角度探讨因素不同水平对实验指标影响的差异。一般说来,质量因子是可以人为控制的。
回归分析是从数量因子的角度出发,通过建立回归方程来研究实验指标与一个(或几个)因子之间的数量关系。但大多数情况下,数量因子是不可以人为加以控制的。
两个不同参数之间的方差就是协方差
若两个随机变量X和Y相互独立,则E[(X-E(X))(Y-E(Y))]=0,因而若上述数学期望不为零,则X和Y必不是相互独立的,亦即它们之间存在着一定的关系。
定义
E[(X-E(X))(Y-E(Y))]称为随机变量X和Y的协方差,记作COV(X,Y),即COV(X,Y)=E[(X-E(X))(Y-E(Y))]。
COVAR_POP
功能描述:返回一对表达式的总体协方差。
SAMPLE:
COVAR_SAMP
功能描述:返回一对表达式的样本协方差
SAMPLE:
SELECT
a.department_id,
a.employee_id,
b.employee_id manager_id,
a.first_name||' '||a.last_name employee_name,
b.first_name||' '||b.last_name manager_name,
a.hire_date,
a.salary employee_salary,
b.salary manager_salary,
COVAR_POP(a.salary,b.salary) OVER (ORDER BY a.department_id,a.hire_date ) AS CUM_COVP,
COVAR_SAMP(a.salary,b.salary) OVER (ORDER BY a.department_id,a.hire_date ) AS CUM_SAMP
FROM employees a,employees b
WHERE a.manager_id=b.employee_id(+)
CORR
功能描述:返回一对表达式的相关系数,它是如下的缩写:
COVAR_POP(expr1,expr2)/STDDEV_POP(expr1)*STDDEV_POP(expr2))
从统计上讲,相关性是变量之间关联的强度,变量之间的关联意味着在某种程度
上一个变量的值可由其它的值进行预测。通过返回一个-1~1之间的一个数,相关
系数给出了关联的强度,0表示不相关。
SELECT
a.department_id,
a.first_name||' '||a.last_name employee_name,
b.first_name||' '||b.last_name manager_name,
a.hire_date,
a.salary employee_salary,
b.salary manager_salary,
CORR(a.salary,b.salary) OVER (ORDER BY a.department_id,a.hire_date ) AS CORR
FROM employees a,employees b
WHERE a.manager_id=b.employee_id(+)
Oracle分析函数——统计分析函数
方差和标准差:
样本中各数据与样本平均数的差的平方和的平均数叫做样本方差;样本方差的算术平方根叫做样本标准差。样本方差和样本标准差都是衡量一个样本波动大小的量,样本方差或样本标准差越大,样本数据的波动就越大。
数学上一般用E{[X-E(X)]^2}来度量随机变量X与其均值E(X)即期望的偏离程度,称为X的方差。
方差是标准差的平方
方差和标准差。方差和标准差是测算离散趋势最重要、最常用的指标。方差是各变量值与其均值离差平方的平均数,它是测算数值型数据离散程度的最重要的方法。标准差为方差的平方根,用S表示。
StdDev返回expr的样本标准偏差。它可用作聚集和分析函数。它与stddev_samp的不同之处在于,当计算的输入数据只有一行时,stddev返回0,而stddev_samp返回null。
Oracle 数据库 中,标准偏差计算结果与variance用作集聚函数计算结果的平方根相等。该函数参数可取任何数字类型或是任何能隐式转换成数字类型的非数字类型。
STDDEV
功能描述:计算当前行关于组的标准偏离。(Standard Deviation)
SAMPLE:
STDDEV_SAMP
功能描述:该函数计算累积样本标准偏离,并返回总体变量的平方根,其返回值与VAR_POP函数的平方根相同。(Standard Deviation-Sample)
SAMPLE:
它与stddev_samp的不同之处在于,当计算的输入数据只有一行时,stddev返回0,而stddev_samp返回null。
SELECT
department_id,
first_name||' '||last_name employee_name,
hire_date,
salary,
STDDEV_SAMP(salary) OVER (PARTITION BY department_id ORDER BY hire_date) AS cum_sdev
FROM employees
WHERE department_id in (20,30,60);
STDDEV和STDDEV_SAMP的区别
SELECT
first_name||' '||last_name employee_name,
hire_date,
salary,
STDDEV(salary) OVER (ORDER BY hire_date) "StdDev",
STDDEV_SAMP(salary) OVER (ORDER BY hire_date) AS cum_sdev
FROM employees
VAR_POP
功能描述:(Variance Population)该函数返回非空集合的总体变量(忽略null),VAR_POP进行如下计算:
(SUM(expr2) - SUM(expr)2 / COUNT(expr)) / COUNT(expr)
VAR_SAMP
功能描述:(Variance Sample)该函数返回非空集合的样本变量(忽略null),VAR_POP进行如下计算:
(SUM(expr*expr)-SUM(expr)*SUM(expr)/COUNT(expr))/(COUNT(expr)-1)
SAMPLE:
VARIANCE
功能描述:该函数返回表达式的变量,Oracle计算该变量如下:
如果表达式中行数为1,则返回0
如果表达式中行数大于1,则返回VAR_SAMP
SAMPLE:
SELECT
department_id,
first_name||' '||last_name employee_name,
hire_date,
salary,
STDDEV(salary) OVER (PARTITION BY department_id ORDER BY hire_date) AS "STDDEV",
STDDEV_SAMP(salary) OVER (PARTITION BY department_id ORDER BY hire_date) AS "STDDEV_SAMP",
VAR_POP(salary) OVER (PARTITION BY department_id ORDER BY hire_date) AS "VAR_POP",
VAR_SAMP(salary) OVER (PARTITION BY department_id ORDER BY hire_date) AS "VAR_SAMP",
VARIANCE(salary) OVER (PARTITION BY department_id ORDER BY hire_date) AS "VARIANCE"
FROM employees
协方差分析是建立在方差分析和回归分析基础之上的一种统计分析方法。
方差分析是从质量因子的角度探讨因素不同水平对实验指标影响的差异。一般说来,质量因子是可以人为控制的。
回归分析是从数量因子的角度出发,通过建立回归方程来研究实验指标与一个(或几个)因子之间的数量关系。但大多数情况下,数量因子是不可以人为加以控制的。
两个不同参数之间的方差就是协方差
若两个随机变量X和Y相互独立,则E[(X-E(X))(Y-E(Y))]=0,因而若上述数学期望不为零,则X和Y必不是相互独立的,亦即它们之间存在着一定的关系。
定义
E[(X-E(X))(Y-E(Y))]称为随机变量X和Y的协方差,记作COV(X,Y),即COV(X,Y)=E[(X-E(X))(Y-E(Y))]。
COVAR_POP
功能描述:返回一对表达式的总体协方差。
SAMPLE:
COVAR_SAMP
功能描述:返回一对表达式的样本协方差
SAMPLE:
SELECT
a.department_id,
a.employee_id,
b.employee_id manager_id,
a.first_name||' '||a.last_name employee_name,
b.first_name||' '||b.last_name manager_name,
a.hire_date,
a.salary employee_salary,
b.salary manager_salary,
COVAR_POP(a.salary,b.salary) OVER (ORDER BY a.department_id,a.hire_date ) AS CUM_COVP,
COVAR_SAMP(a.salary,b.salary) OVER (ORDER BY a.department_id,a.hire_date ) AS CUM_SAMP
FROM employees a,employees b
WHERE a.manager_id=b.employee_id(+)
CORR
功能描述:返回一对表达式的相关系数,它是如下的缩写:
COVAR_POP(expr1,expr2)/STDDEV_POP(expr1)*STDDEV_POP(expr2))
从统计上讲,相关性是变量之间关联的强度,变量之间的关联意味着在某种程度
上一个变量的值可由其它的值进行预测。通过返回一个-1~1之间的一个数,相关
系数给出了关联的强度,0表示不相关。
SELECT
a.department_id,
a.first_name||' '||a.last_name employee_name,
b.first_name||' '||b.last_name manager_name,
a.hire_date,
a.salary employee_salary,
b.salary manager_salary,
CORR(a.salary,b.salary) OVER (ORDER BY a.department_id,a.hire_date ) AS CORR
FROM employees a,employees b
WHERE a.manager_id=b.employee_id(+)
Oracle分析函数——统计分析函数
方差和标准差:
样本中各数据与样本平均数的差的平方和的平均数叫做样本方差;样本方差的算术平方根叫做样本标准差。样本方差和样本标准差都是衡量一个样本波动大小的量,样本方差或样本标准差越大,样本数据的波动就越大。
数学上一般用E{[X-E(X)]^2}来度量随机变量X与其均值E(X)即期望的偏离程度,称为X的方差。
方差是标准差的平方
方差和标准差。方差和标准差是测算离散趋势最重要、最常用的指标。方差是各变量值与其均值离差平方的平均数,它是测算数值型数据离散程度的最重要的方法。标准差为方差的平方根,用S表示。
StdDev返回expr的样本标准偏差。它可用作聚集和分析函数。它与stddev_samp的不同之处在于,当计算的输入数据只有一行时,stddev返回0,而stddev_samp返回null。
Oracle 数据库 中,标准偏差计算结果与variance用作集聚函数计算结果的平方根相等。该函数参数可取任何数字类型或是任何能隐式转换成数字类型的非数字类型。
STDDEV
功能描述:计算当前行关于组的标准偏离。(Standard Deviation)
SAMPLE:
STDDEV_SAMP
功能描述:该函数计算累积样本标准偏离,并返回总体变量的平方根,其返回值与VAR_POP函数的平方根相同。(Standard Deviation-Sample)
SAMPLE:
它与stddev_samp的不同之处在于,当计算的输入数据只有一行时,stddev返回0,而stddev_samp返回null。
SELECT
department_id,
first_name||' '||last_name employee_name,
hire_date,
salary,
STDDEV_SAMP(salary) OVER (PARTITION BY department_id ORDER BY hire_date) AS cum_sdev
FROM employees
WHERE department_id in (20,30,60);
STDDEV和STDDEV_SAMP的区别
SELECT
first_name||' '||last_name employee_name,
hire_date,
salary,
STDDEV(salary) OVER (ORDER BY hire_date) "StdDev",
STDDEV_SAMP(salary) OVER (ORDER BY hire_date) AS cum_sdev
FROM employees
VAR_POP
功能描述:(Variance Population)该函数返回非空集合的总体变量(忽略null),VAR_POP进行如下计算:
(SUM(expr2) - SUM(expr)2 / COUNT(expr)) / COUNT(expr)
VAR_SAMP
功能描述:(Variance Sample)该函数返回非空集合的样本变量(忽略null),VAR_POP进行如下计算:
(SUM(expr*expr)-SUM(expr)*SUM(expr)/COUNT(expr))/(COUNT(expr)-1)
SAMPLE:
VARIANCE
功能描述:该函数返回表达式的变量,Oracle计算该变量如下:
如果表达式中行数为1,则返回0
如果表达式中行数大于1,则返回VAR_SAMP
SAMPLE:
SELECT
department_id,
first_name||' '||last_name employee_name,
hire_date,
salary,
STDDEV(salary) OVER (PARTITION BY department_id ORDER BY hire_date) AS "STDDEV",
STDDEV_SAMP(salary) OVER (PARTITION BY department_id ORDER BY hire_date) AS "STDDEV_SAMP",
VAR_POP(salary) OVER (PARTITION BY department_id ORDER BY hire_date) AS "VAR_POP",
VAR_SAMP(salary) OVER (PARTITION BY department_id ORDER BY hire_date) AS "VAR_SAMP",
VARIANCE(salary) OVER (PARTITION BY department_id ORDER BY hire_date) AS "VARIANCE"
FROM employees
协方差分析是建立在方差分析和回归分析基础之上的一种统计分析方法。
方差分析是从质量因子的角度探讨因素不同水平对实验指标影响的差异。一般说来,质量因子是可以人为控制的。
回归分析是从数量因子的角度出发,通过建立回归方程来研究实验指标与一个(或几个)因子之间的数量关系。但大多数情况下,数量因子是不可以人为加以控制的。
两个不同参数之间的方差就是协方差
若两个随机变量X和Y相互独立,则E[(X-E(X))(Y-E(Y))]=0,因而若上述数学期望不为零,则X和Y必不是相互独立的,亦即它们之间存在着一定的关系。
定义
E[(X-E(X))(Y-E(Y))]称为随机变量X和Y的协方差,记作COV(X,Y),即COV(X,Y)=E[(X-E(X))(Y-E(Y))]。
COVAR_POP
功能描述:返回一对表达式的总体协方差。
SAMPLE:
COVAR_SAMP
功能描述:返回一对表达式的样本协方差
SAMPLE:
SELECT
a.department_id,
a.employee_id,
b.employee_id manager_id,
a.first_name||' '||a.last_name employee_name,
b.first_name||' '||b.last_name manager_name,
a.hire_date,
a.salary employee_salary,
b.salary manager_salary,
COVAR_POP(a.salary,b.salary) OVER (ORDER BY a.department_id,a.hire_date ) AS CUM_COVP,
COVAR_SAMP(a.salary,b.salary) OVER (ORDER BY a.department_id,a.hire_date ) AS CUM_SAMP
FROM employees a,employees b
WHERE a.manager_id=b.employee_id(+)
CORR
功能描述:返回一对表达式的相关系数,它是如下的缩写:
COVAR_POP(expr1,expr2)/STDDEV_POP(expr1)*STDDEV_POP(expr2))
从统计上讲,相关性是变量之间关联的强度,变量之间的关联意味着在某种程度
上一个变量的值可由其它的值进行预测。通过返回一个-1~1之间的一个数,相关
系数给出了关联的强度,0表示不相关。
SELECT
a.department_id,
a.first_name||' '||a.last_name employee_name,
b.first_name||' '||b.last_name manager_name,
a.hire_date,
a.salary employee_salary,
b.salary manager_salary,
CORR(a.salary,b.salary) OVER (ORDER BY a.department_id,a.hire_date ) AS CORR
FROM employees a,employees b
WHERE a.manager_id=b.employee_id(+)
Oracle分析函数——数据分布函数及 报表 函数
CUME_DIST
功能描述:计算一行在组中的相对位置,CUME_DIST总是返回大于0、小于或等于1的数,该数表示该行在N行中的位置。例如,在一个3行的组中,返回的累计分布值为1/3、2/3、3/3
SAMPLE:下例中计算每个部门的员工按薪水排序依次累积出现的分布百分比
SELECT
department_id,
first_name||' '||last_name employee_name,
salary,
CUME_DIST() OVER (PARTITION BY department_id ORDER BY salary) AS cume_dist
FROM employees
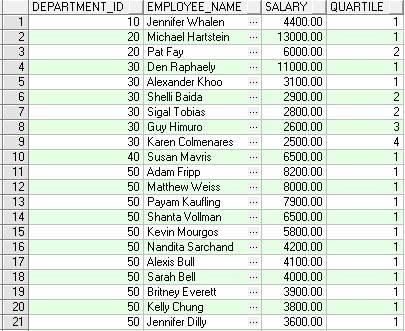
NTILE
功能描述:将一个组分为"表达式"的散列表示,例如,如果表达式=4,则给组中的每一行分配一个数(从1到4),如果组中有20行,则给前5行分配1,给下5行分配2等等。如果组的基数不能由表达式值平均分开,则对这些行进行分配时,组中就没有任何percentile的行数比其它percentile的行数超过一行,最低的percentile是那些拥有额外行的percentile。例如,若表达式=4,行数=21,则percentile=1的有5行,percentile=2的有5行等等。
SAMPLE:下例中把6行数据分为4份
SELECT
department_id,
first_name||' '||last_name employee_name,
salary,
NTILE(4) OVER (PARTITION BY department_id ORDER BY salary DESC) AS quartile
FROM employees
PERCENT_RANK
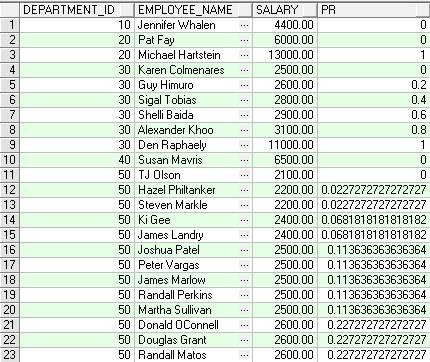
功能描述:和CUME_DIST(累积分配)函数类似,对于一个组中给定的行来说,在计算那行的序号时,先减1,然后除以n-1(n为组中所有的行数)。该函数总是返回0~1(包括1)之间的数。
SAMPLE:下例中如果Khoo的salary为2900,则pr值为0.6,因为RANK函数对于等值的返回序列值是一样的
SELECT
department_id,
first_name||' '||last_name employee_name,
salary,
PERCENT_RANK() OVER (PARTITION BY department_id ORDER BY salary) AS pr
FROM employees
ORDER BY department_id,salary;
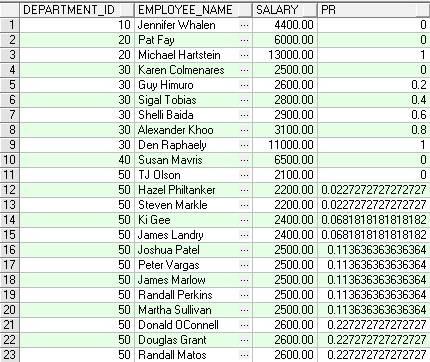
PERCENTILE_DISC
功能描述:返回一个与输入的分布百分比值相对应的数据值,分布百分比的计算方法见函数CUME_DIST,如果没有正好对应的数据值,就取大于该分布值的下一个值。
注意:本函数与PERCENTILE_CONT的区别在找不到对应的分布值时返回的替代值的计算方法不同
SAMPLE:下例中0.7的分布值在部门30中没有对应的Cume_Dist值,所以就取下一个分布值0.83333333所对应的SALARY来替代
SELECT
department_id,
first_name||' '||last_name employee_name,
salary,
PERCENTILE_DISC(0.7) WITHIN GROUP (ORDER BY salary ) OVER (PARTITION BY department_id) "Percentile_Disc",
CUME_DIST() OVER (PARTITION BY department_id ORDER BY salary) "Cume_Dist"
FROM employees
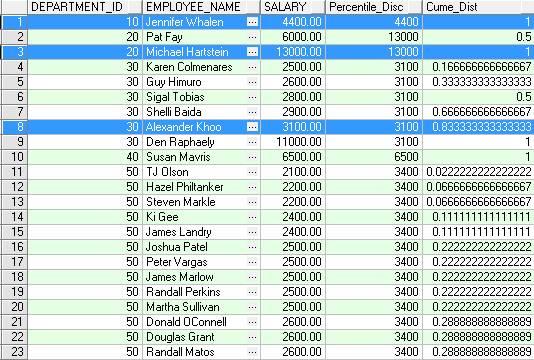
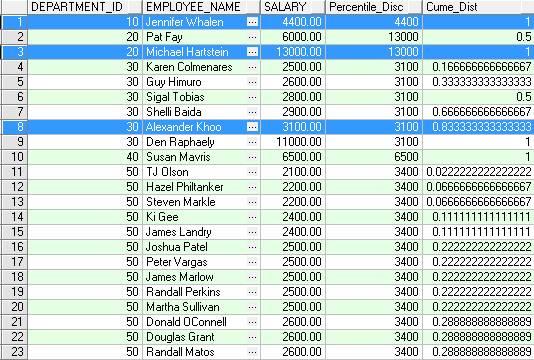
PERCENTILE_CONT
功能描述:返回一个与输入的分布百分比值相对应的数据值,分布百分比的计算方法见函数PERCENT_RANK,如果没有正好对应的数据值,就通过下面算法来得到值:
RN = 1+ (P*(N-1))其中P是输入的分布百分比值,N是组内的行数
CRN = CEIL(RN) FRN = FLOOR(RN)
if (CRN = FRN = RN) then
(value of expression from row at RN)
else
(CRN - RN) * (value of expression for row at FRN) +
(RN - FRN) * (value of expression for row at CRN)
注意:本函数与PERCENTILE_DISC的区别在找不到对应的分布值时返回的替代值的计算方法不同
算法太复杂,看不懂了L
SAMPLE:在下例中,对于部门60的Percentile_Cont值计算如下:
P=0.7 N=5 RN =1+ (P*(N-1)=1+(0.7*(5-1))=3.8 CRN = CEIL(3.8)=4
FRN = FLOOR(3.8)=3
(4 - 3.8)* 4800 + (3.8 - 3) * 6000 = 5760
SELECT
department_id,
first_name||' '||last_name employee_name,
salary,
PERCENTILE_DISC(0.7) WITHIN GROUP (ORDER BY salary) OVER (PARTITION BY department_id) "Percentile_Disc",
PERCENTILE_CONT(0.7) WITHIN GROUP (ORDER BY salary) OVER (PARTITION BY department_id) "Percentile_Cont",
PERCENT_RANK() OVER (PARTITION BY department_id ORDER BY salary) "Percent_Rank"
FROM employees
总案例
SELECT
department_id,
first_name||' '||last_name employee_name,
salary,
CUME_DIST() OVER (PARTITION BY department_id ORDER BY salary) AS cume_dist, --数据分布百分比
NTILE(4) OVER (PARTITION BY department_id ORDER BY salary) AS quartile, --数据分布,以NTILE中的exp来计算
PERCENT_RANK() OVER (PARTITION BY department_id ORDER BY salary) AS pr, --数据分布百分比,从0开始计
PERCENTILE_DISC(0.7) WITHIN GROUP (ORDER BY salary ) OVER (PARTITION BY department_id) "Percentile_Disc", --输入的分布百分比值相对应的数据值
PERCENTILE_CONT(0.7) WITHIN GROUP (ORDER BY salary) OVER (PARTITION BY department_id) "Percentile_Cont" --表达式太复杂了,...
FROM employees
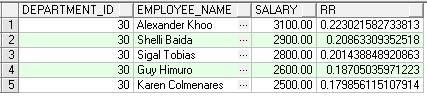
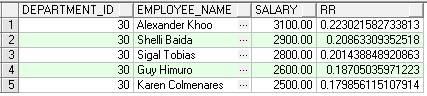
RATIO_TO_REPORT
功能描述:该函数计算expression/(sum(expression))的值,它给出相对于总数的百分比,即当前行对sum(expression)的贡献。
SAMPLE:下例计算每个员工的工资占该类员工总工资的百分比
SELECT
department_id,
first_name||' '||last_name employee_name,
salary,
RATIO_TO_REPORT(salary) OVER () AS rr
FROM employees
WHERE job_id = 'PU_CLERK';
REGR_ (Linear Regression) Functions
功能描述:这些线性回归函数适合最小二乘法回归线,有9个不同的回归函数可使用。
REGR_SLOPE:返回斜率,等于COVAR_POP(expr1, expr2) / VAR_POP(expr2)
REGR_INTERCEPT:返回回归线的y截距,等于
AVG(expr1) - REGR_SLOPE(expr1, expr2) * AVG(expr2)
REGR_COUNT:返回用于填充回归线的非空数字对的数目
REGR_R2:返回回归线的决定系数,计算式为:
If VAR_POP(expr2) = 0 then return NULL
If VAR_POP(expr1) = 0 and VAR_POP(expr2) != 0 then return 1
If VAR_POP(expr1) > 0 and VAR_POP(expr2 != 0 then
return POWER(CORR(expr1,expr),2)
REGR_AVGX:计算回归线的自变量(expr2)的平均值,去掉了空对(expr1, expr2)后,等于AVG(expr2)
REGR_AVGY:计算回归线的应变量(expr1)的平均值,去掉了空对(expr1, expr2)后,等于AVG(expr1)
REGR_SXX:返回值等于REGR_COUNT(expr1, expr2) * VAR_POP(expr2)
REGR_SYY:返回值等于REGR_COUNT(expr1, expr2) * VAR_POP(expr1)
REGR_SXY:返回值等于REGR_COUNT(expr1, expr2) * COVAR_POP(expr1, expr2)
(下面的例子都是在SH用户下完成的)
SAMPLE 1:下例计算1998年最后三个星期中两种产品(260和270)在周末的销售量中已开发票数量和总数量的累积斜率和回归线的截距
SELECT t.fiscal_month_number "Month", t.day_number_in_month "Day",
REGR_SLOPE(s.amount_sold, s.quantity_sold)
OVER (ORDER BY t.fiscal_month_desc, t.day_number_in_month) AS CUM_SLOPE,
REGR_INTERCEPT(s.amount_sold, s.quantity_sold)
OVER (ORDER BY t.fiscal_month_desc, t.day_number_in_month) AS CUM_ICPT
FROM sales s, times t
WHERE s.time_id = t.time_id
AND s.prod_id IN (270, 260)
AND t.fiscal_year=1998
AND t.fiscal_week_number IN (50, 51, 52)
AND t.day_number_in_week IN (6,7)
ORDER BY t.fiscal_month_desc, t.day_number_in_month;
SAMPLE 2:下例计算1998年4月每天的累积交易数量
SELECT UNIQUE t.day_number_in_month,
REGR_COUNT(s.amount_sold, s.quantity_sold)
OVER (PARTITION BY t.fiscal_month_number ORDER BY t.day_number_in_month)
"Regr_Count"
FROM sales s, times t
WHERE s.time_id = t.time_id
AND t.fiscal_year = 1998 AND t.fiscal_month_number = 4;
SAMPLE 3:下例计算1998年每月销售量中已开发票数量和总数量的累积回归线决定系数
SELECT t.fiscal_month_number,
REGR_R2(SUM(s.amount_sold), SUM(s.quantity_sold))
OVER (ORDER BY t.fiscal_month_number) "Regr_R2"
FROM sales s, times t
WHERE s.time_id = t.time_id
AND t.fiscal_year = 1998
GROUP BY t.fiscal_month_number
ORDER BY t.fiscal_month_number;
SAMPLE 4:下例计算1998年12月最后两周产品260的销售量中已开发票数量和总数量的累积平均值
SELECT t.day_number_in_month,
REGR_AVGY(s.amount_sold, s.quantity_sold)
OVER (ORDER BY t.fiscal_month_desc, t.day_number_in_month)
"Regr_AvgY",
REGR_AVGX(s.amount_sold, s.quantity_sold)
OVER (ORDER BY t.fiscal_month_desc, t.day_number_in_month)
"Regr_AvgX"
FROM sales s, times t
WHERE s.time_id = t.time_id
AND s.prod_id = 260
AND t.fiscal_month_desc = '1998-12'
AND t.fiscal_week_number IN (51, 52)
ORDER BY t.day_number_in_month;
SAMPLE 5:下例计算产品260和270在1998年2月周末销售量中已开发票数量和总数量的累积REGR_SXY, REGR_SXX, and REGR_SYY统计值
SELECT t.day_number_in_month,
REGR_SXY(s.amount_sold, s.quantity_sold)
OVER (ORDER BY t.fiscal_year, t.fiscal_month_desc) "Regr_sxy",
REGR_SYY(s.amount_sold, s.quantity_sold)
OVER (ORDER BY t.fiscal_year, t.fiscal_month_desc) "Regr_syy",
REGR_SXX(s.amount_sold, s.quantity_sold)
OVER (ORDER BY t.fiscal_year, t.fiscal_month_desc) "Regr_sxx"
FROM sales s, times t
WHERE s.time_id = t.time_id
AND prod_id IN (270, 260)
AND t.fiscal_month_desc = '1998-02'
AND t.day_number_in_week IN (6,7)
ORDER BY t.day_number_in_month;
Oracle分析函数——分析函数案例
环比
环比就是现在的统计周期和上一个统计周期比较。例如 2008 年7月份与2008年6月份相比较称其为环比。
环比发展速度是报告期水平与前一时期水平之比,表明现象逐期的发展速度。如计算一年内各月与前一个月对比,即2月比1月,3月比2月,4月比3月……12月比11月,说明逐月的发展程度。如分析抗击"非典"期间某些 经济 现象的发展趋势,环比比同比更说明问题。
学过统计或者经济知识的人都知道,统计指标按其具体内容、实际作用和表现形式可以分为总量指标、相对指标和平均指标。由于采用基期的不同,发展速度可分为同比发展速度、环比发展速度和定基发展速度。简单地说,就是同比、环比与定基比,都可以用百分数或倍数表示。
定基比发展速度,也简称总速度,一般是指报告期水平与某一固定时期水平之比,表明这种现象在较长时期内总的发展速度。同比发展速度,一般指是指本期发展水平与上年同期发展水平对比,而达到的相对发展速度。环比发展速度,一般指是指报告期水平与前一时期水平之比,表明现象逐期的发展速度。
同比和环比,这两者所反映的虽然都是变化速度,但由于采用基期的不同,其反映的内涵是完全不同的;同比与环比相比较,而不能拿同比与环比相比较;而对于同一个地方,考虑时间纵向上发展趋势的反映,则往往要把同比与环比放在一起进行对照
同比
英文:year-on-year
同比就是今年第n月与去年第n月比;(环比就是今年第n月与第n-1月或第n+1月比)学过统计或者经济知识的人都知道,统计指标按其具体内容、实际作用和表现形式可以分为总量指标、相对指标和平均指标。由于采用基期的不同,发展速度可分为同比发展速度、环比发展速度和定基发展速度。简单地说,就是同比、环比与定基比,都可以用百分数或倍数表示。
同比发展速度主要是为了消除季节变动的影响,用以说明本期发展水平与去年同期发展水平对比而达到的相对发展速度。如,本期2月比去年2月,本期6月比去年6月等。其计算公式为:同比发展速度=本期发展水平/去年同期发展水平×100%。在实际工作中,经常使用这个指标,如某年、某季、某月与上年同期对比计算的发展速度,就是同比发展速度。
环比发展速度是报告期水平与前一时期水平之比,表明现象逐期的发展速度。如计算一年内各月与前一个月对比,即2月比1月,3月比2月,4月比3月……12月比11月,说明逐月的发展程度。如分析抗击"非典"期间某些经济现象的发展趋势,环比比同比更说明问题。
定基比发展速度也叫总速度。是报告期水平与某一固定时期水平之比,表明这种现象在较长时期内总的发展速度。如,"九五"期间各年水平都以1995年水平为基期进行对比,一年内各月水平均以上年12月水平为基期进行对比,就是定基发展速度。
定基比
定基比发展速度也叫总速度。是报告期水平与某一固定时期水平之比,表明这种现象在较长时期内总的发展速度。如,"九五"期间各年水平都以1995年水平为基期进行对比,一年内各月水平均以上年12月水平为基期进行对比,就是定基发展速度。
另可参见同比、环比:
同比发展速度主要是为了消除季节变动的影响,用以说明本期发展水平与去年同期发展水平对比而达到的相对发展速度。如,本期2月比去年2月,本期6月比去年6月等。其计算公式为:同比发展速度=本期发展水平/去年同期发展水平×100%。在实际工作中,经常使用这个指标,如某年、某季、某月与上年同期对比计算的发展速度,就是同比发展速度。
环比发展速度是报告期水平与前一时期水平之比,表明现象逐期的发展速度。如计算一年内各月与前一个月对比,即2月比1月,3月比2月,4月比3月……12月比11月,说明逐月的发展程度。如分析抗击"非典"期间某些经济现象的发展趋势,环比比同比更说明问题
CREATE TABLE salaryByMonth
(
employeeNo varchar2(20),
yearMonth varchar2(6),
salary number
)
SELECT
employeeno,
yearmonth,
salary,
MIN(salary) KEEP (DENSE_RANK FIRST ORDER BY yearmonth) OVER (PARTITION BY employeeno) first_salary, --基比分析salary/first_salary
LAG(salary,1,0) OVER (PARTITION BY employeeno ORDER BY yearmonth) AS prev_sal, --环比分析,与上个月份进行比较
LAG(salary,12,0) OVER (PARTITION BY employeeno ORDER BY yearmonth) AS prev_12_sal --同比分析,与上个年度相同月份进行比较
FROM salaryByMonth
ORDER BY employeeno,yearmonth
--SQL常用的算法
SELECT *
FROM salaryByMonth a
WHERE (a.employeeno,a.salary) IN
(
SELECT b.employeeno,max(salary)
FROM salaryByMonth b
GROUP BY b.employeeno
)
--用分析函数替代
SELECT distinct
employeeno,
MAX(salary) OVER (PARTITION BY employeeno) AS max_salary,
FIRST_VALUE(yearmonth) OVER (PARTITION BY employeeno ORDER BY salary DESC) AS high_yearmonth
FROM salaryByMonth
Oracle分析函数——CUBE,ROLLUP
CUBE
功能描述:
注意:
ROLLUP
功能描述:
注意:
如果是ROLLUP(A, B, C)的话,GROUP BY顺序
(A、B、C)
(A、B)
(A)
最后对全表进行GROUP BY操作。
如果是GROUP BY CUBE(A, B, C),GROUP BY顺序
(A、B、C)
(A、B)
(A、C)
(A),
(B、C)
(B)
(C),
最后对全表进行GROUP BY操作。
CREATE TABLE studentscore
(
student_name varchar2(20),
subjects varchar2(20),
score number
)
INSERT INTO studentscore VALUES('WBQ','ENGLISH',90);
INSERT INTO studentscore VALUES('WBQ','MATHS',95);
INSERT INTO studentscore VALUES('WBQ','CHINESE',88);
INSERT INTO studentscore VALUES('CZH','ENGLISH',80);
INSERT INTO studentscore VALUES('CZH','MATHS',90);
INSERT INTO studentscore VALUES('CZH','HISTORY',92);
INSERT INTO studentscore VALUES('CB','POLITICS',70);
INSERT INTO studentscore VALUES('CB','HISTORY',75);
INSERT INTO studentscore VALUES('LDH','POLITICS',80);
INSERT INTO studentscore VALUES('LDH','CHINESE',90);
INSERT INTO studentscore VALUES('LDH','HISTORY',95);


SELECT
student_name,
subjects,
sum(score)
FROM studentscore
GROUP BY CUBE(student_name,subjects);
等同于以下标准 SQL
SELECT NULL,subjects,SUM(score)
FROM studentscore
GROUP BY subjects
UNION
SELECT student_name,NULL,SUM(score)
FROM studentscore
GROUP BY student_name
UNION
SELECT NULL,NULL,SUM(score)
FROM studentscore
UNION
SELECT student_name,subjects,SUM(score)
FROM studentscore
GROUP BY student_name,subjects
SELECT
student_name,
subjects,
sum(score)
FROM studentscore
GROUP BY ROLLUP(student_name,subjects);
SELECT student_name,NULL,SUM(score)
FROM studentscore
GROUP BY student_name
UNION
SELECT NULL,NULL,SUM(score)
FROM studentscore
UNION
SELECT student_name,subjects,SUM(score)
FROM studentscore
GROUP BY student_name,subjects
SELECT
grouping(student_name),
grouping(subjects),
student_name,
subjects,
sum(score)
FROM studentscore
GROUP BY CUBE(student_name,subjects)
ORDER BY 1,2;
SELECT
grouping(student_name),
grouping(subjects),
student_name,
subjects,
sum(score)
FROM studentscore
GROUP BY ROLLUP(student_name,subjects)
ORDER BY 1,2;
SELECT
grouping_id(student_name,subjects),
student_name,
subjects,
sum(score)
FROM studentscore
GROUP BY CUBE(student_name,subjects)
ORDER BY 1;
SELECT
grouping_id(student_name,subjects),
student_name,
subjects,
sum(score)
FROM studentscore
GROUP BY ROLLUP(student_name,subjects)
ORDER BY 1;
SELECT
grouping(student_name),
grouping(subjects),
CASE WHEN grouping(student_name)=0 AND grouping(subjects)=1 THEN '学生成绩合计'
WHEN grouping(student_name)=1 AND grouping(subjects)=0 THEN '课目成绩合计'
WHEN grouping(student_name)=1 AND grouping(subjects)=1 THEN '总 计'
ELSE ''
END SUMMARY,
student_name,
subjects,
sum(score)
FROM studentscore
GROUP BY CUBE(student_name,subjects)
ORDER BY 1,2;
本文参考 Oracle 官方网站的相关文档,并加了一些实用例子
使用正规表达式编写更好的 SQL
使用正则表达式编写更好的SQL(续)
什么是正规表达式?
正规表达式由一个或多个字符型文字和/或元字符组成。在最简单的格式下,正规表达式仅由字符文字组成,如正规表达式cat。它被读作字母c,接着是字母a和t,这种模式匹配cat、location和catalog之类的字符串。元字符提供算法来确定Oracle如何处理组成一个正规表达式的字符。当您了解了各种元字符的含义时,您将体会到正规表达式用于查找和替换特定的文本数据是非常强大的。
验证数据、识别重复关键字的出现、检测不必要的空格,或分析字符串只是正规表达式的许多应用中的一部分。您可以用它们来验证电话号码、邮政编码、电子邮件地址、社会安全号码、IP地址、文件名和路径名等的格式。此外,您可以查找如HTML标记、数字、日期之类的模式,或任意文本数据中符合任意模式的任何事物,并用其它的模式来替换它们。
用Oracle Database 10g 使用正规表达式
您可以使用最新引进的Oracle SQL REGEXP_LIKE操作符和REGEXP_INSTR、REGEXP_SUBSTR以及REGEXP_REPLACE函数来发挥正规表达式的作用。您将体会到这个新的功能如何对LIKE操作符和INSTR、SUBSTR和REPLACE函数进行了补充。实际上,它们类似于已有的操作符,但现在增加了强大的模式匹配功能。被搜索的数据可以是简单的字符串或是存储在 数据库 字符列中的大量文本。正规表达式让您能够以一种您以前从未想过的方式来搜索、替换和验证数据,并提供高度的灵活性。
正规表达式的基本例子
在使用这个新功能之前,您需要了解一些元字符的含义。句号(.)匹配一个正规表达式中的任意字符(除了换行符)。例如,正规表达式a.b匹配的字符串中首先包含字母a,接着是其它任意单个字符(除了换行符),再接着是字母b。字符串axb、xaybx和abba都与之匹配,因为在字符串中隐藏了这种模式。如果您想要精确地匹配以a开头和以b结尾的一条三个字母的字符串,则您必须对正规表达式进行定位。脱字符号(^)元字符指示一行的开始,而美元符号($)指示一行的结尾(参见表1)。因此,正规表达式^a.b$匹配字符串aab、abb或axb。将这种方式与LIKE²Ù×÷·û提供的类似的模式匹配a_b相比较,其中(_)是单字符通配符。
默认情况下,一个正规表达式中的一个单独的字符或字符列表只匹配一次。为了指示在一个正规表达式中多次出现的一个字符,您可以使用一个量词,它也被称为重复操作符。.如果您想要得到从字母a开始并以字母b结束的匹配模式,则您的正规表达式看起来像这样:^a.*b$。*元字符重复前面的元字符(.)指示的匹配零次、一次或更多次。LIKE操作符的等价的模式是a%b,其中用百分号(%)来指示任意字符出现零次、一次或多次。
表2给出了重复操作符的完整列表。注意它包含了特殊的重复选项,它们实现了比现有的LIKE通配符更大的灵活性。如果您用圆括号括住一个表达式,这将有效地创建一个可以重复一定次数的子表达式。例如,正规表达式b(an)*a匹配ba、bana、banana、yourbananasplit等。
Oracle的正规表达式实施支持POSIX(可移植操作系统接口)字符类,参见表3中列出的内容。这意味着您要查找的字符类型可以非常特别。假设您要编写一条仅查找非字母字符的LIKE条件—作为结果的WHERE子句可能不经意就会变得非常复杂。
POSIX字符类必须包含在一个由方括号([])指示的字符列表中。例如,正规表达式[[:lower:]]匹配一个小写字母字符,而[[:lower:]]{5}匹配五个连续的小写字母字符。
除POSIX字符类之外,您可以将单独的字符放在一个字符列表中。例如,正规表达式^ab[cd]ef$匹配字符串abcef和abdef。必须选择c或d。
除脱字符(^)和连字符(-)之外,字符列表中的大多数元字符被认为是文字。正规表达式看起来很复杂,这是因为一些元字符具有随上下文环境而定的多重含义。^就是这样一种元字符。如果您用它作为一个字符列表的第一个字符,它代表一个字符列表的非。因此,[^[:digit:]]查找包含了任意非数字字符的模式,而^[[:digit:]]查找以数字开始的匹配模式。连字符(-)指示一个范围,正规表达式[a-m]匹配字母a到字母m之间的任意字母。但如果它是一个字符行中的第一个字符(如在[-afg]中),则它就代表连字符。
之前的一个例子介绍了使用圆括号来创建一个子表达式;它们允许您通过输入更替元字符来输入可更替的选项,这些元字符由竖线(|)分开。
例如,正规表达式t(a|e|i)n允许字母t和n之间的三种可能的字符更替。匹配模式包括如tan、ten、tin和Pakistan之类的字,但不包括teen、mountain或tune。作为另一种选择,正规表达式t(a|e|i)n也可以表示为一个字符列表t[aei]n。表4汇总了这些元字符。虽然存在更多的元字符,但这个简明的概述足够用来理解这篇文章使用的正规表达式。
REGEXP_LIKE操作符
REGEXP_LIKE操作符向您介绍在Oracle数据库中使用时的正规表达式功能。表5列出了REGEXP_LIKE的语法。
下面的SQL查询的WHERE子句显示了REGEXP_LIKE操作符,它在ZIP列中搜索满足正规表达式[^[:digit:]]的模式。它将检索ZIPCODE表中的那些ZIP列值包含了任意非数字字符的行。
SELECT zip
FROM zipcode
WHERE REGEXP_LIKE(zip, '[^[:digit:]]')
ZIP
-----
ab123
123xy
007ab
abcxy
这个正规表达式的例子仅由元字符组成,更具体来讲是被冒号和方括号分隔的POSIX字符类digit。第二组方括号(如[^[:digit:]]中所示)包括了一个字符类列表。如前文所述,需要这样做是因为您只可以将POSIX字符类用于构建一个字符列表。
REGEXP_INSTR函数
这个函数返回一个模式的起始位置,因此它的功能非常类似于INSTR函数。新的REGEXP_INSTR函数的语法在表6中给出。这两个函数之间的主要区别是,REGEXP_INSTR让您指定一种模式,而不是一个特定的搜索字符串;因而它提供了更多的功能。接下来的示例使用REGEXP_INSTR来返回字符串Joe Smith, 10045 Berry Lane, San Joseph, CA 91234中的五位邮政编码模式的起始位置。如果正规表达式被写为[[:digit:]]{5},则您将得到门牌号的起始位置而不是邮政编码的,因为10045是第一次出现五个连续数字。因此,您必须将表达式定位到该行的末尾,正如$元字符所示,该函数将显示邮政编码的起始位置,而不管门牌号的数字个数。
SELECT REGEXP_INSTR('Joe Smith, 10045 Berry Lane, San Joseph, CA 91234',
'[[:digit:]]{5}$')
AS rx_instr
FROM dual
RX_INSTR
----------
45
编写更复杂的模式
让我们在前一个例子的邮政编码模式上展开,以便包含一个可选的四位数字模式。您的模式现在可能看起来像这样:[[:digit:]]{5}(-[[:digit:]]{4})?$。如果您的源字符串以5位邮政编码或5位+ 4位邮政编码的格式结束,则您将能够显示该模式的起始位置。
SELECT REGEXP_INSTR('Joe Smith, 10045 Berry Lane, San Joseph, CA 91234-1234',
' [[:digit:]]{5}(-[[:digit:]]{4})?$')
AS starts_at
FROM dual
STARTS_AT
----------
44
在这个示例中,括弧里的子表达式(-[[:digit:]]{4})将按?重复操作符的指示重复零次或一次。此外,企图用传统的SQL函数来实现相同的结果甚至对SQL专家也是一个挑战。为了更好地说明这个正规表达式示例的不同组成部分,表7包含了一个对单个文字和元字符的描述。
REGEXP_SUBSTR函数
SUBSTR函数的REGEXP_SUBSTR函数用来提取一个字符串的一部分。表8显示了这个新函数的语法。在下面的示例中,匹配模式[^,]*的字符串将被返回。该正规表达式搜索其后紧跟着空格的一个逗号;然后按[^,]*的指示搜索零个或更多个不是逗号的字符,最后查找另一个逗号。这种模式看起来有点像一个用逗号分隔的值字符串。
SELECT REGEXP_SUBSTR('first field, second field , third field',
', [^,]*,')
FROM dual
REGEXP_SUBSTR('FIR
------------------
, second field ,
REGEXP_REPLACE函数
让我们首先看一下传统的REPLACE SQL函数,它把一个字符串用另一个字符串来替换。假设您的数据在正文中有不必要的空格,您希望用单个空格来替换它们。利用REPLACE函数,您需要准确地列出您要替换多少个空格。然而,多余空格的数目在正文的各处可能不是相同的。下面的示例在Joe和Smith之间有三个空格。REPLACE函数的参数指定要用一个空格来替换两个空格。在这种情况下,结果在原来的字符串的Joe和Smith之间留下了一个额外的空格。
SELECT REPLACE('Joe Smith',' ', ' ')
AS replace
FROM dual
REPLACE
---------
Joe Smith
REGEXP_REPLACE函数把替换功能向前推进了一步,其语法在表9中列出。以下查询用单个空格替换了任意两个或更多的空格。( )子表达式包含了单个空格,它可以按{2,}的指示重复两次或更多次。
SELECT REGEXP_REPLACE('Joe Smith',
'( ){2,}', ' ')
AS RX_REPLACE
FROM dual
RX_REPLACE
----------
Joe Smith
'^'匹配输入字符串的开始位置,在方括号表达式中使用,此时它表示不接受该字符集合。
'$'匹配输入字符串的结尾位置。如果设置了RegExp对象的Multiline属性,则$也匹配'n'或'r'。
'.'匹配除换行符n之外的任何单字符。
'?'匹配前面的子表达式零次或一次。
'*'匹配前面的子表达式零次或多次。
'+'匹配前面的子表达式一次或多次。
'( )'标记一个子表达式的开始和结束位置。
'[]'标记一个中括号表达式。
'{m,n}'一个精确地出现次数范围,m=<出现次数<=n,'{m}'表示出现m次,'{m,}'表示至少出现m次。
'|'指明两项之间的一个选择。例子'^([a-z]+|[0-9]+)$'表示所有小写字母或数字组合成的字符串。
num匹配num,其中num是一个正整数。对所获取的匹配的引用。
create table TEST
(
MC VARCHAR2(60)
);
insert into TEST (MC) values ('b0');
insert into TEST (MC) values ('0b');
insert into TEST (MC) values ('1234-233-3223-2323');
insert into TEST (MC) values ('123-45-5678');
insert into TEST (MC) values ('123-56-1234567890');
insert into TEST (MC) values ('123456789');
insert into TEST (MC) values ('idadfa');
insert into TEST (MC) values ('[a');
insert into TEST (MC) values ('[i');
insert into TEST (MC) values ('[a-c]');
insert into TEST (MC) values ('[a-c]a');
insert into TEST (MC) values ('a[a-c]');
insert into TEST (MC) values ('[bdd-a]');
insert into TEST (MC) values ('[adddddd');
insert into TEST (MC) values ('[eeeea]');
insert into TEST (MC) values ('[eeeee]');
insert into TEST (MC) values ('[b]');
insert into TEST (MC) values ('112233445566778899');
insert into TEST (MC) values ('22113344 5566778899');
insert into TEST (MC) values ('991122334455667788');
insert into TEST (MC) values ('aabbccddee');
insert into TEST (MC) values ('bbaaaccddee');
insert into TEST (MC) values ('eeaabbccdd');
insert into TEST (MC) values ('ab123');
insert into TEST (MC) values ('123xy');
insert into TEST (MC) values ('007ab');
insert into TEST (MC) values ('abcxy');
insert into TEST (MC) values ('The final test is is is how to find duplicate words.');
commit;
select 1,'^[:digit:]',mc from test where regexp_like(mc,'^[:digit:]') --以':digit'中的任何一个字符开头的字符串
union
select 2,'[^[:digit:]]',mc from test where regexp_like(mc,'[^[:digit:]]') --任何含有非数字的字符列表
union
select 3,'^[[:digit:]]',mc from test where regexp_like(mc,'^[[:digit:]]') --数字开头
union
select 4,'^[^[:digit:]]',mc from test where regexp_like(mc,'^[^[:digit:]]') --包含任何非数字开头的
union
select 5,'[[:digit:]]',mc from test where regexp_like(mc,'[[:digit:]]') --任何含有数字的字符列表
create table email
( email varchar2(100)
)
insert into email values('windboy@vip.sina.com');
insert into email values('windboy@sina.com');
insert into email values('window2007@vip.sina.com');
insert into email values('21com@sina.com');
insert into email values('windboy@163.com');
insert into email values('test@mail.vip.sina.com');
insert into email values('test.mail.vip.sina.com');
insert into email values('test');
commit;
select * from email where REGEXP_LIKE(email,'^[[:alnum:]] +@([[:alnum:]]).+') ;
关于正则表达式的后向引用,暂时还是没法理解
select 0,REGEXP_REPLACE('Ellen Hildi Smith','(.*) (.*) (.*)', '\11\22\33') from dual
union
select 1,REGEXP_REPLACE('Ellen Hildi Smith','(.*)(.*)(.*)', '\11\22\33') from dual --2,3
union
select 2,REGEXP_REPLACE('Ellen Hildi Smith','(.*)(.*) (.*)', '\11\22\33') from dual --2
union
select 3,REGEXP_REPLACE('Ellen Hildi Smith','(.*) (.*)(.*)', '\11\22\33') from dual --3
union
select 4,REGEXP_REPLACE('EllenHildi Smith','(.*) (.*) (.*)', '\11\22\33') from dual
union
select 5,REGEXP_REPLACE('EllenHildi Smith','(.*)(.*)(.*)', '\11\22\33') from dual --2,3
union
select 6,REGEXP_REPLACE('EllenHildi Smith','(.*)(.*) (.*)', '\11\22\33') from dual --2
union
select 7,REGEXP_REPLACE('EllenHildi Smith','(.*) (.*)(.*)', '\11\22\33') from dual --3
union
select 8,REGEXP_REPLACE('Ellen HildiSmith','(.*) (.*) (.*)', '\11\22\33') from dual
union
select 9,REGEXP_REPLACE('Ellen HildiSmith','(.*)(.*)(.*)', '\11\22\33') from dual --2,3
union
select 10,REGEXP_REPLACE('Ellen HildiSmith','(.*)(.*) (.*)', '\11\22\33') from dual --2
union
select 11,REGEXP_REPLACE('Ellen HildiSmith','(.*) (.*)(.*)', '\11\22\33') from dual --3
-- 'u', 'U' -返回全是大写的字符串
-- 'l', 'L' -返回全是小写的字符串
-- 'a', 'A' -返回大小写结合的字符串
-- 'x', 'X' -返回全是大写和数字的字符串
-- 'p', 'P' -返回键盘上出现字符的随机组合
SELECT
trunc(dbms_random.value(1,101)),
DBMS_RANDOM.string('~',5),
DBMS_RANDOM.string('l',5),
DBMS_RANDOM.string('L',5),
DBMS_RANDOM.string('a',5),
DBMS_RANDOM.string('A',5),
DBMS_RANDOM.string('u',5),
DBMS_RANDOM.string('U',5),
DBMS_RANDOM.string('x',5),
DBMS_RANDOM.string('X',5),
DBMS_RANDOM.string('p',5),
DBMS_RANDOM.string('P',5)
from
(
SELECT level,ROWNUM rn
FROM DUAL
CONNECT BY ROWNUM<=1001
)