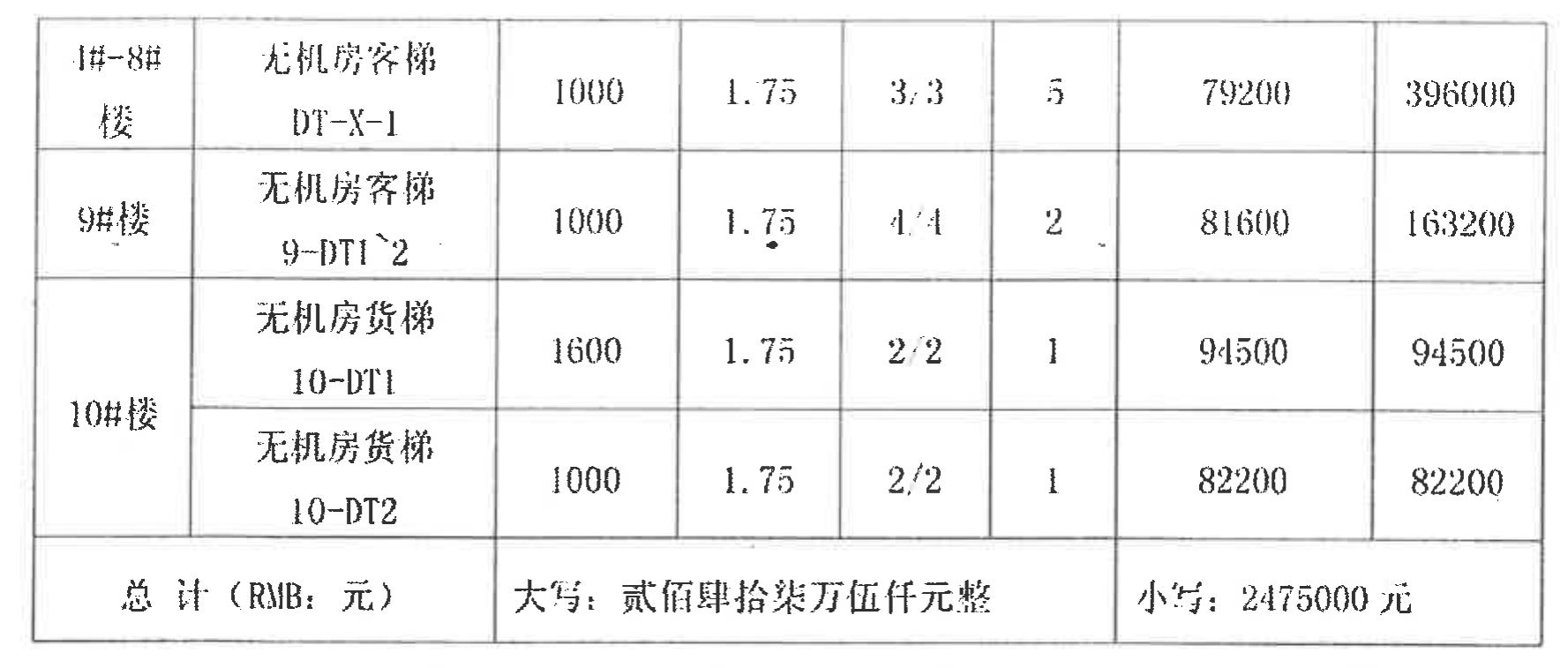
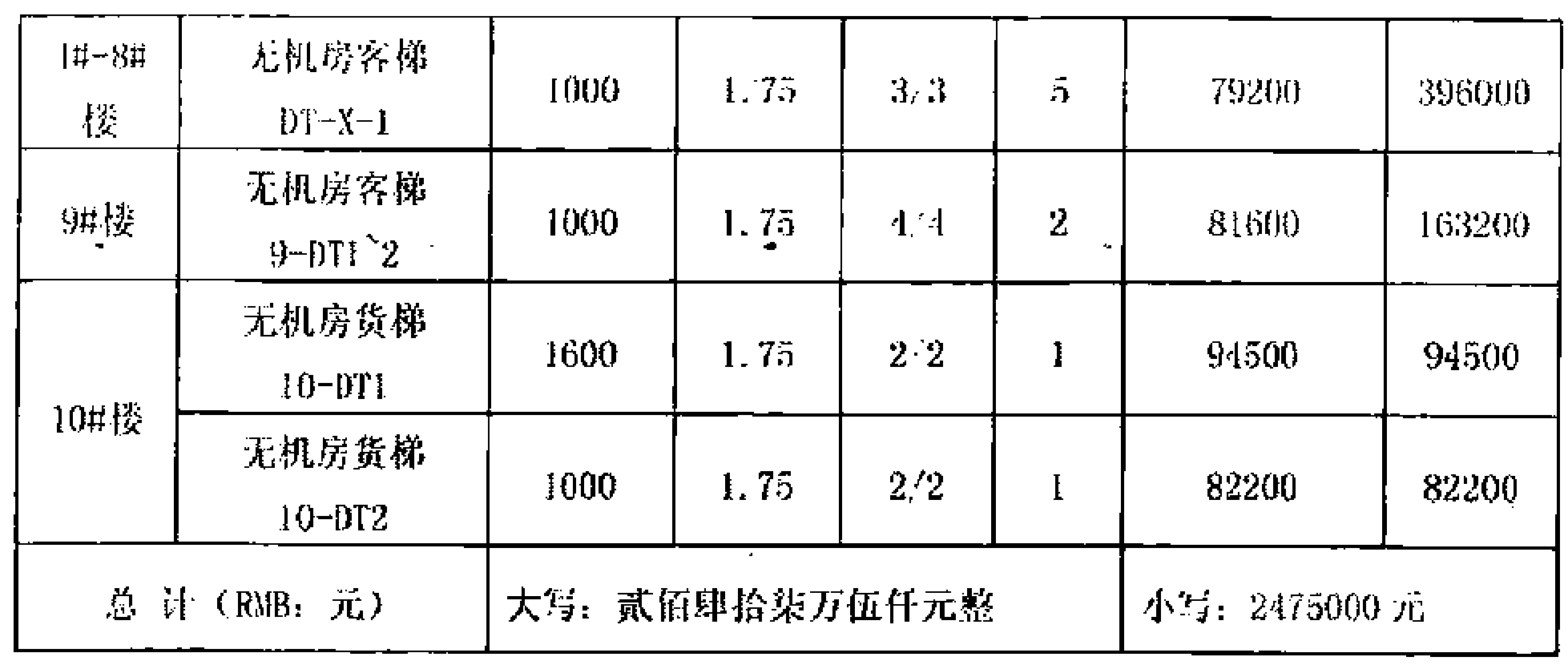
|
|
|
相关文章推荐

|
温柔的仙人掌 · “我有一抹春,愿染万层林”_个人品德_河南省 ...· 1 年前 · |
|
|
文雅的炒饭 · 2021年国产喜剧爱情片《东北恋哥》HD国语 ...· 2 年前 · |
|
|
一身肌肉的蛋挞 · 滚球体育网址长城汽车副总裁佘尚锋:围绕数据_ ...· 2 年前 · |
|
|
幸福的冲锋衣 · Call MEX Functions - ...· 2 年前 · |