

JavaScript里面的二进制

基础知识点
ECMAScript中的进制
ES中进制规范基于C语言,随着发展然后进行了改进。下面列举JavaScript不同进制写法:
// 二进制 Binary system
// 以0b或0B开头
var FLT_SIGNBIT = 0b10000000000000000000000000000000; // 2147483648
var FLT_EXPONENT = 0b01111111100000000000000000000000; // 2139095040
var FLT_MANTISSA = 0B00000000011111111111111111111111; // 8388607
// 二进制展示(方便展示,理解上却更难了)
// 正数:就是正数的原码
// 负数:负号+正数的原码
// 不是数值的二进制补码
parseInt(-10).toString(2) // -1010
// 八进制 Octal number system
// 以0开头,ECMAScript 6支持0o
var n = 0755; // 493
var m = 0644; // 420
var e = 0o755; // 493 ECMAScript 6规范
// 十进制 Decimal system
// 以0开头,但是后面跟8以下会当作八进制处理
var d = 1234567890;
var l = 0888; // 888 十进制
var o = 0777; // 511 八进制
// 十六进制 Hexadecimal
// 以0x或0X开头
0xFFFFFFFFFFFFFFFFF // 295147905179352830000
0x123456789ABCDEF // 81985529216486900
0XA // 10
原码、反码、补码
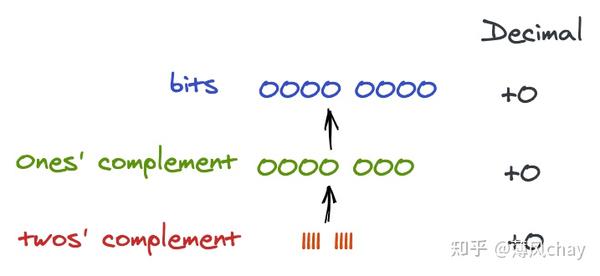
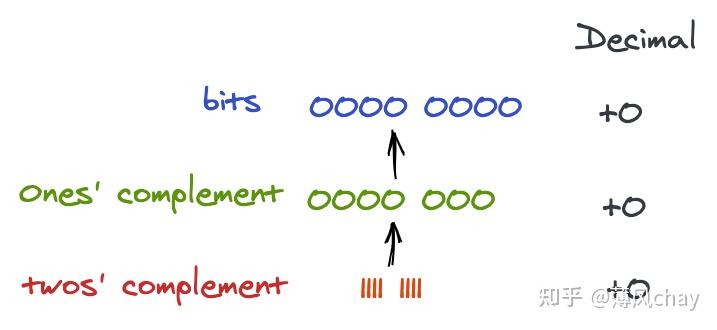
先让我们看下
1
和
-1
原码、反码、补码,然后我们通过这个2个数字来解释原码、反码、补码。
JavaScript 负数显示 是 负号+原码(理论上方便查看),比如parseInt(-10).toString(2)二进制展示输出是-1010


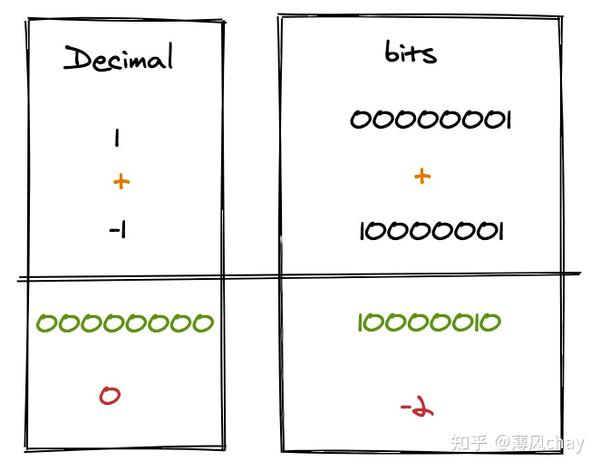
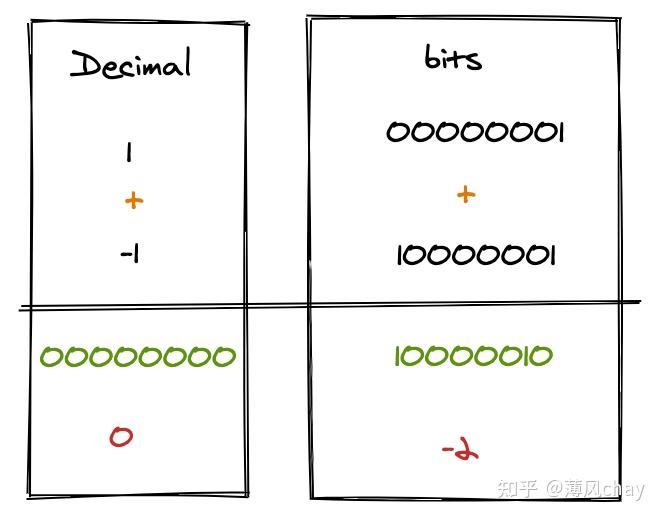
直接原码进行
有符号
的加计算
,结果十进制是
-2
,这个结果明显是错误的。符号直接参与运算有问题。
- 原码:
-
数字的二进制表示,
有符号数,最高位作为符号位,
0表示+,1表示-,无符号数 即无符号位 - 反码:
-
正数和
+0其原码本身就是反码 -
负数和
-0符号位与原码中一样,保持不变,其余位数逐位取反,1换成0,0换成1 - 补码:
-
正数和
+0其原码本身就是补码 -
负数和
-0先计算其反码,然后反码加上1(例如8位的加0000 0001),得到补码
数据在内存中是以补码形式存储(方便换算),原码和补码是在运行过程进行转换的。
通过补码计算得到补码,然后转成反码,再转成原码(这里不是减
1
还是加
1
)。
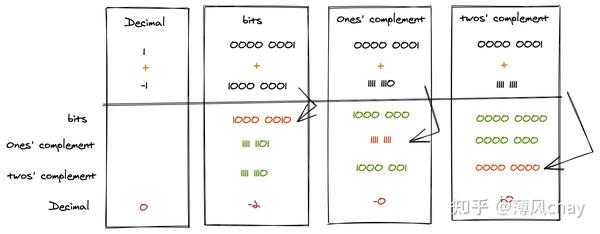
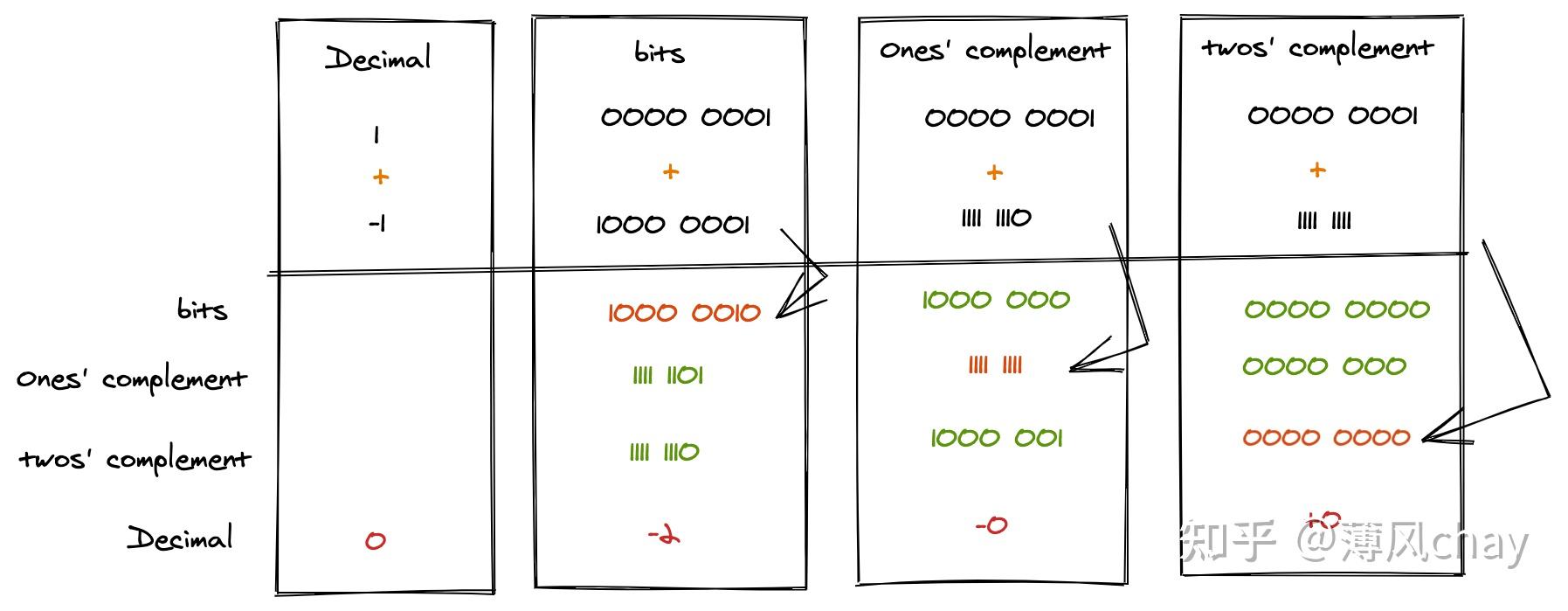
反码是解决“正负相加等于0“的计算问题,补码是解决“怎么表示0(+0、-0)”的问题,反码成了中间过渡转换。
字节序
什么是字节?
大部分系统8个二进制位(Bit)构成一个字节(Byte)单元,一个字节可以存储一个英文字母或半个汉字。
经常听说汉字需要占2个字节(Byte)?
现在基本使用统一的字符集
Unicode
,规定的是字符的十六进制,基本常用字符的在
Plane 0
(0000–FFFF)里面,如
英文
A
字母
U+0041
,
汉字
范围是
U+4E00 ~ U+9FA5
,是
4个十六进制数即可表示一个字符
。
1 byte = 8 bit
那
8 bit
可以存储的数值范围:
-
无符号数值范围
0~255 -
有符号数值范围(符号占1位,1表示负数,0表示正数)
-128~127
十六进制转二进制,1位十六进制对应4 bit二进制,1个 Unicode 字符由4位十六进制组成。所以 Unicode 都需要 2个字节(Byte)。
这怎么英文也要2个字节了?
我们先看下十六进制转二进制,十六进制数与二进制有一一对照表,这里不展开。
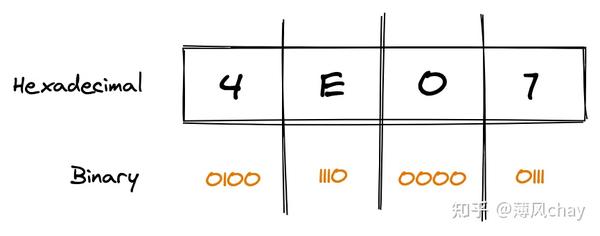
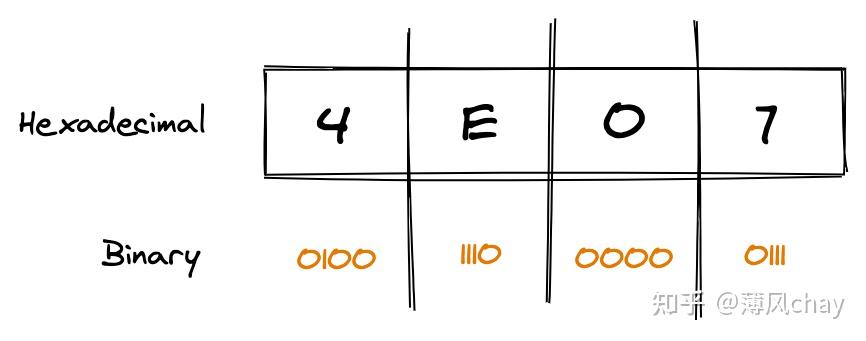
中文
U+4E07
汉字
万
,看下图例子:
英文
U+0041
即
A
,看下图例子:
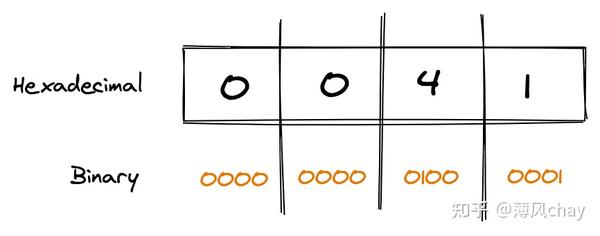
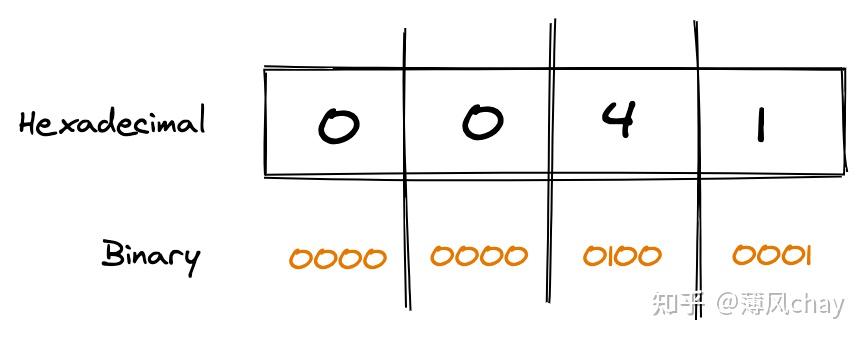
可以看到 Unicode 不管英文、汉字都是需要16 bit来存储,也就是2 byte。大家看到
A
的是
0041
,高位字节
0
其实没有作用,在传输、存储时可以省略。那如何省略,变成1个字节?这时候就出现编码方式,就是
UTF-8
、
GBK
等,通过编码压缩长度。
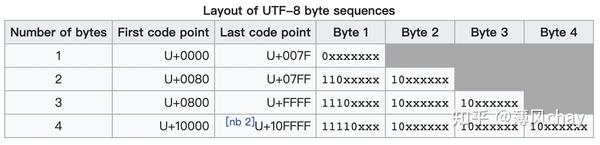

上图
UTF-8
编码方式: 数字、英文是1个字节,汉字是3个字节。 而
GBK
编码方式:数字、英文是1个字节,汉字是2个字节,1个字节范围
00–7F
。
扩展知识:在数据库MySQL4.0 以下 varchar(20) 是指20个字节,可以存储数字英文20个,utf-8汉字6个,在MySQL5.0 及以上 varchar(20) 是指20个字符,可以存储数字英文汉字都是20个。
// Unicode 转换
// charCodeAt、fromCharCode 默认十进制
// 通过 toString 转成十六进制
console.log('a'.charCodeAt(0).toString(16)) // 61
console.log(String.fromCharCode(0x61)) // a
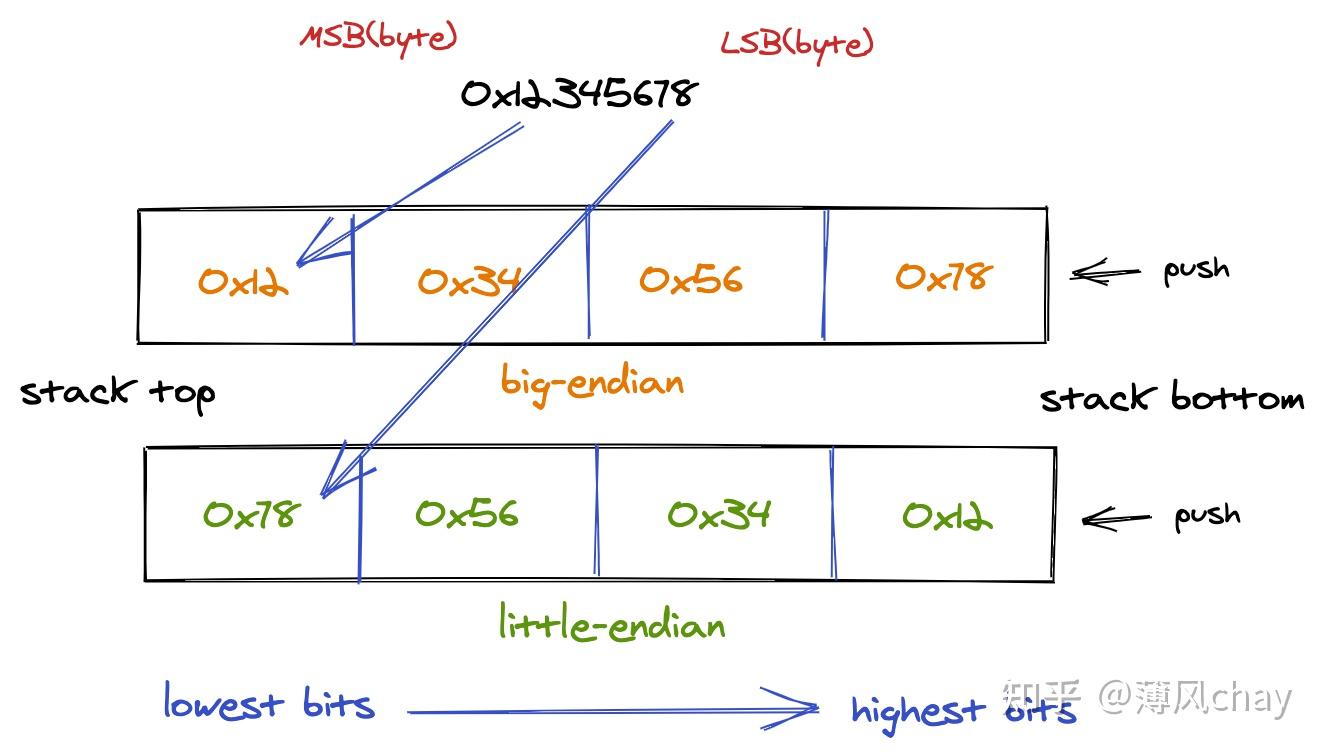
什么是字节序?
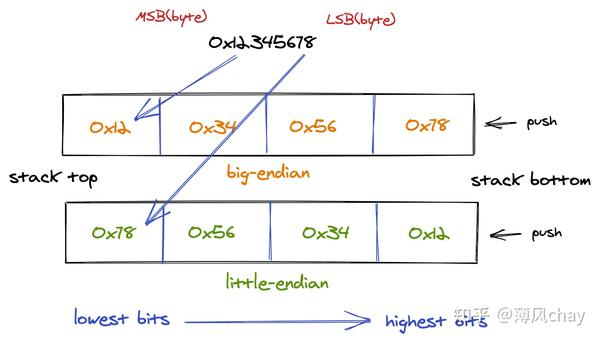
举个例子:十六进制
0x12345678
存储,内存最小的单位一个字节,一个字节8位,将其转成二进制
0001 0010 0011 0100 0101 0110 0111 1000
就是32位,就是4个字节,所以分为
0x12
、
0x34
、
0x56
、
0x78
(只是为了表示是十六进制所以写成
0x12
,实际是
12
存储是8 bits)4个字节存储。但是存储网络传输时是先从
0x12
开始传,还是
0x78
开始传?所以多字节出现才有字节序。
// 十六进制 0x12345678
// 十进制 305419896
// 二进制 0b00010010001101000101011001111000
// 0001 0010 0011 0100 0101 0110 0111 1000
console.log(0b0001, 0b0010) // 1 2
根据字节存储的顺序,分为:
- Big endian(大端):将最高有效字节存储在内存低位
- Little endian(小端):将最低有效字节存储在内存低位
注意区分最高有效字节(高位字节)和最高有效位(高位),大端小端是指最高有效位的顺序不一样
文件可以通过文件头的 字节顺序标记(BOM) 识别哪种字节顺序。
位运算
位运算操作数都当做
32 bits
进行操作。提示:下面案例中二进制都是
原码
。
JavaScript 负数输出展示是 负号+原码(理论上方便查看),比如parseInt(-10).toString(2)二进制展示输出是-1010
&(按位与)
两个运算比较的
bit
位都是
1
时,这个
bit
位才是
1
。
const a = 5; // 00000000000000000000000000000101
const b = 3; // 00000000000000000000000000000011
console.log(a & b); // 00000000000000000000000000000001
// 是否2的n次幂
// (x & x - 1) === 0
console.log((2 & 2 - 1) === 0) // true
// 奇偶
// x & 1 === 0 偶数
// x & 1 === 1 奇数
console.log(2 & 1 === 0) // 0
// 求平均值,防溢出
function avg(x, y){
return (x & y) + ((x ^ y) >> 1);
// 取模
// i % 4 === i & (4 - 1)
console.log(1%4 , 1&3) // 1 1
// 转换
// 0xffffffff 11111111111111111111111111111111
-10 & 0xffffffff
// 0xff 11111111
|(按位或)
两个运算比较的
bit
位只要一个是
1
时,这个
bit
位就是
1
。将任一数值 x 与 0 进行按位或操作,其结果都是 x。将任一数值 x 与 -1 进行按位或操作,其结果都为 -1。
const a = 5; // 00000000000000000000000000000101
const b = 3; // 00000000000000000000000000000011
console.log(a | b); // 00000000000000000000000000000111
~(按位非)
对运算值的每一个
bit
位取反(包括符合位取反)。
const a = 5; // 0000 0000 0000 0000 0000 0000 0000 0101
const b = -3; // 1000 0000 0000 0000 0000 0000 0000 0011
// 5 取反
// 原 0000 0000 0000 0000 0000 0000 0000 0101
// 取反 1111 1111 1111 1111 1111 1111 1111 1010
// -6 补码转原码
// 补 1111 1111 1111 1111 1111 1111 1111 1010
// 反 1000 0000 0000 0000 0000 0000 0000 0101
// 原 1000 0000 0000 0000 0000 0000 0000 0110
console.log(~a); // 10000000000000000000000000000110
// -6
console.log(~b); // 00000000000000000000000000000010
// 取负数
console.log(~4 + 1) // -4
// 舍弃小数
console.log(~~1.5) // 1
^(按位异或)
两个运算比较的
bit
位不相同,这个
bit
位才是
1
。
const a = 5; // 00000000000000000000000000000101
const b = 3; // 00000000000000000000000000000011
console.log(a ^ b); // 00000000000000000000000000000110
// 交换变量值
let a = 1;
let b = 2;
a = a^b;
b = a^b;
a = a^b;
console.log(a, b) // 2 1
// 判断赋值
if(x === a){
x = b
}else{
x =a
// 等价于下面
x = a ^ b ^ x
<<(左移)
9 << 2
数字9转换成32位二进制,然后向左移动2位,左边移出的丢弃,右边用0补位,返回值的十进制计算公式
X * 2 ** Y
,舍弃小数取整。
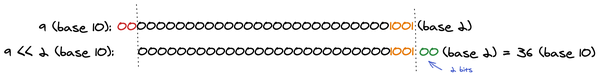

// x * 2 ** y
// x舍弃小数位,向整数位进1
// 9 * (2 ** 2) = 9 * (4) = 36
console.log(9 << 2) // 36
// 9 * (2 ** 3) = 9 * (8) = 72
console.log(9 << 3) // 72
>>(右移)
左移的反向操作,即向右移位,但是左侧补位的不是直接补0,而是复制最左侧位来填充。
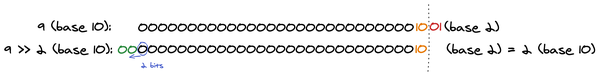
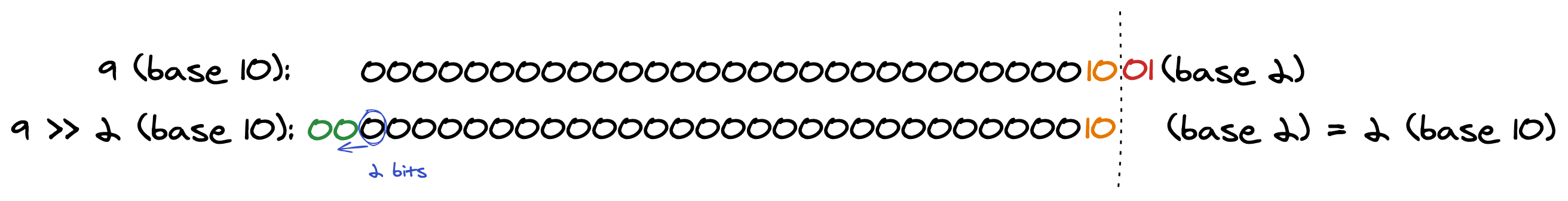
// x / 2 ** y
// 舍弃小数位,负数向整数位进1,正数不进位
// -9 / (2 ** 2) = -9 / (4) = Math.floor(-2.25) = -3
console.log(-9 >> 2) // -3
// 9 / (2 ** 2) = 9 / (4) = Math.trunc(2.25) = 2
console.log(9 >> 2) // 2
// -9 / (2 ** 3) = -9 / (8) = -1.125
console.log(-9 >> 3) // -2
>>>(无符号右移)
操作数向右位移,右位移出的数丢弃,左侧用
0
填充,因为用
0
填充,所以总是"按位非",负数将变成正数。
const a = 5; // 00000000000000000000000000000101
const b = 2; // 00000000000000000000000000000010
const c = -5; // -00000000000000000000000000000101
// -5 补码 10000000000000000000000000000101
console.log(a >>> b); // 00000000000000000000000000000001
// expected output: 1
console.log(c >>> b); // 00111111111111111111111111111110
// expected output: 1073741822
二进制
转二进制
js里面怎么转二进制? 字符通过
charCodeAt
转成
Unicode
码十进制,然后通过 Number 对象
toString
方法转成不同进制。
/**
* 计算字符串所占的内存字节数,默认使用UTF-8的编码方式计算,也可制定为UTF-16
* UTF-8 是一种可变长度的 Unicode 编码格式,使用一至四个字节为每个字符编码
* 000000 - 00007F(128个代码) 0zzzzzzz(00-7F) 一个字节
* 000080 - 0007FF(1920个代码) 110yyyyy(C0-DF) 10zzzzzz(80-BF) 两个字节
* 000800 - 00D7FF 预留 三个字节
* 00E000 - 00FFFF(61440个代码) 1110xxxx(E0-EF) 10yyyyyy 10zzzzzz 三个字节
* 010000 - 10FFFF(1048576个代码) 11110www(F0-F7) 10xxxxxx 10yyyyyy 10zzzzzz 四个字节
* 注: Unicode在范围 D800-DFFF 中不存在任何字符
* @see http://zh.wikipedia.org/wiki/UTF-8
* UTF-16 大部分使用两个字节编码,编码超出 65535 的使用四个字节
* 000000 - 00FFFF 两个字节
* 010000 - 10FFFF 四个字节
* @see http://zh.wikipedia.org/wiki/UTF-16
console.log('0'.charCodeAt()) // "48" 十进制
console.log('0'.charCodeAt().toString(16)) // "30" 十六进制
console.log(0x0030.toString(10)) // "48" 十进制
console.log(String.fromCharCode(48)) // "0"
console.log('万'.charCodeAt().toString(16)) // "4e07" 十六进制
console.log(String.fromCharCode(0x4e07)) // "万"
console.log('万'.charCodeAt().toString(2)) // "100111000000111" 二进制
console.log(String.fromCharCode(0b100111000000111)) // "万"
JavaScript里面
Number
类型是存储为
双精度64位浮点数
, 但是运算转成32位。
关于浮点陷阱问题请看 JavaScript 浮点数陷阱及解法 ,这里不展开。
// 数字 9 的二进制
let binaryStr = parseInt(9, 10).toString(2)
console.log(binaryStr) // 1001
// 上面只返回了4位,4位可以表示0-15的值,超过16位数增加
console.log(parseInt(16, 10).toString(2)) // 10000
// 补位到8位
while(binaryStr.length < 8){
binaryStr = '0' + binaryStr
console.log(Number('0b' + binaryStr)) // 9
但是上面只是单纯的进制转换,不能真正的控制二进制,如何操作二进制?那么就是下面要讲到的
ArrayBuffer
对象、
TypedArray
视图、
DataView
视图。
Note:ES6 规范新增ArrayBuffer对象、TypedArray视图、DataView视图,这三者是操作二进制的接口。最开始设计是为了WebGL通信,提升性能。
ArrayBuffer
ArrayBuffer
对象用来表示通用的、固定长度的原始二进制数据缓冲区。它是一个字节数组集合,通常在其他语言中称为“byte array”。
ArrayBuffer
和
Array
不是同一个概念。所以
ArrayBuffer
只是一个指名长度,并默认填充
0
的二进制数据缓存区。
// 声明一个长度为8的字节数组(8个字节的内存缓存区),并默认用0填充
const buffer = new ArrayBuffer(8);
console.log(buffer.byteLength); // 8
无法直接操作
ArrayBuffer
,可以通过
TypedArray
和
DataView
对象来操作。
// 声明一个长度为8的字节数组,
const buffer = new ArrayBuffer(8);
// new TypedArray(buffer [, byteOffset [, length]]);
const x = new Int8Array(buffer); // 暴露全部字节
console.log(x) // Int8Array [0, 0, 0, 0, 0, 0, 0, 0]
const y = new Int8Array(buffer, 1); // 偏移1位字节
console.log(y) // Int8Array [0, 0, 0, 0, 0, 0, 0]
const z = new Int8Array(buffer, 1, 4); // 偏移1位字节,暴露长度为4
console.log(z) // Int8Array [0, 0, 0, 0]
TypedArray
TypedArray
是不同类型化数组构造函数的原型(
[[Prototype]]
),指定字节位读取的视图,下面列表展示不同类型化数组的数值范围、字节等。
TypedArray
默认使用系统端字节序,一般系统是小端字节序,如果想控制字节序顺序使用
DataView
,所以主要处理本地数据
。
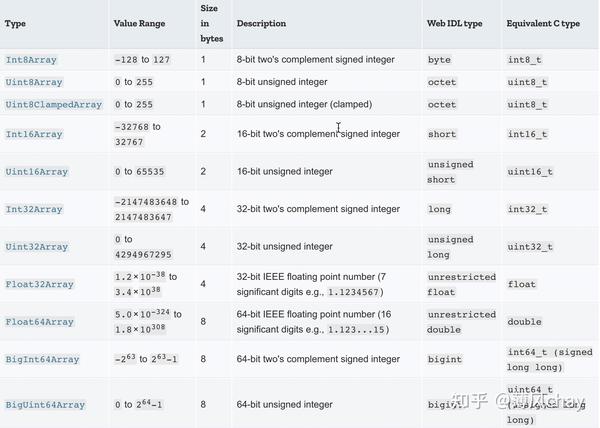
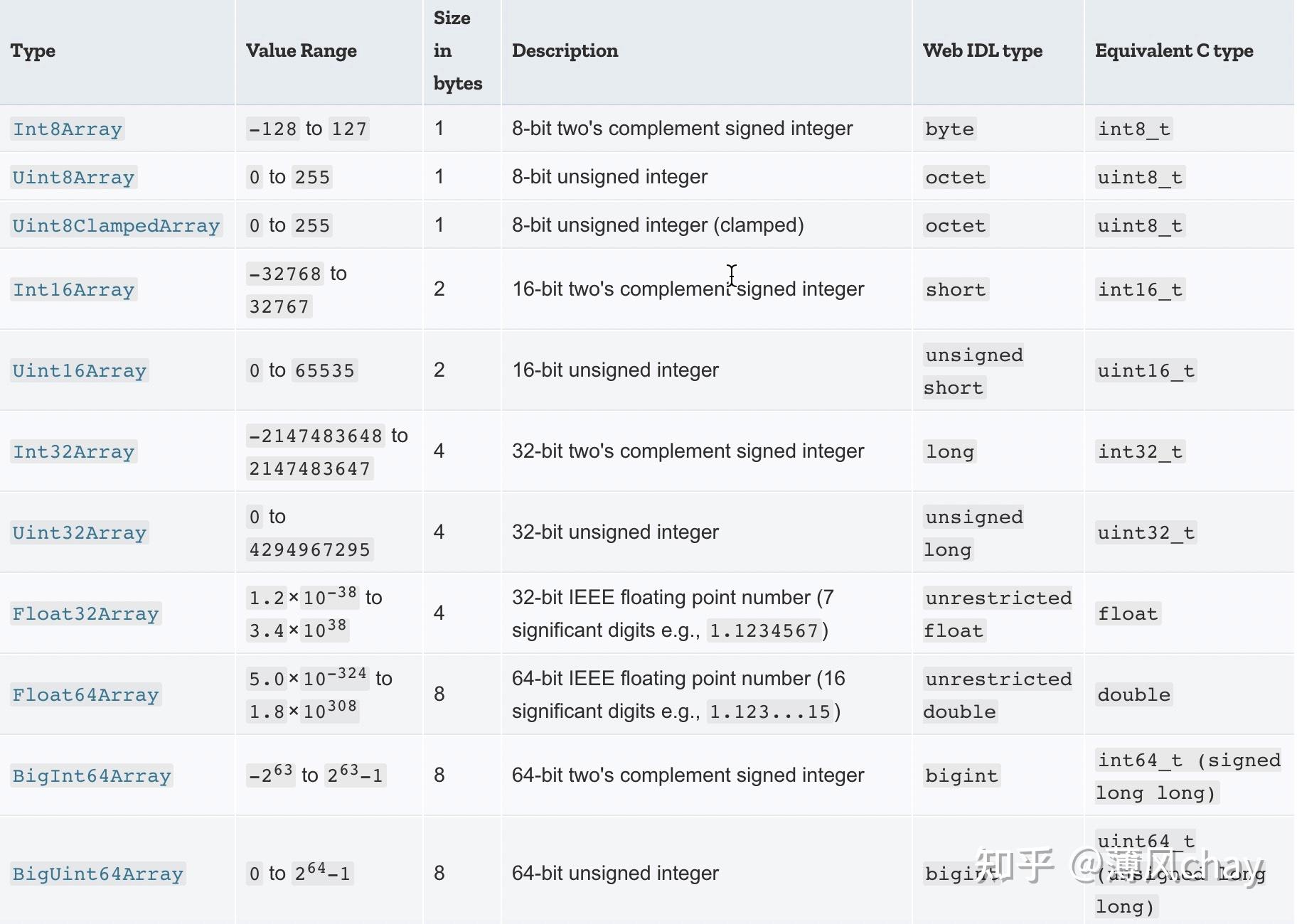
可以直接
new
一个
TypedArray
对象,该对象缓存大小是传入的
length参数 * 数组中每个元素的字节数
,字节数参考上面 TypedArray 列表。
// 类型化数组长度 8
const int8 = new Int8Array(8);
int8[0] = 42;
console.log(int8); // Int8Array [42, 0, 0, 0, 0, 0, 0, 0]
console.log(int8[0]); // 42
console.log(int8.length); // 8
console.log(int8.BYTES_PER_ELEMENT); // 1
console.log(int8.byteLength); // 8 字节长度 8 * 1
或者通过
ArrayBuffer
生成固定大小缓存区,
如果传入的是 ArrayBuffer 那么不会创建新的缓冲区,而是使用传入的 ArrayBuffer 代替
。
// 字节长度 8
const buffer = new ArrayBuffer(8);
// 类型化数组长度 4,每个元素占2个字节 8/2
const int16 = new Int16Array(buffer);
console.log(int16); // Int16Array [0, 0, 0, 0]
console.log(int16.length); // 4
console.log(int16.BYTES_PER_ELEMENT); // 2
console.log(int16.byteLength); // 8
DataView
DataView
视图是可以从
ArrayBuffer
读写多种数值类型的底层接口,还可以控制整数与浮点转化、字节顺序等。
所以在数据传输中更加可控、灵活,比如系统字节序不一样
。
Note:setInt8、setUint8 单字节是无法控制大小端的
// 判断系统是否小端
var littleEndian = (function() {
var buffer = new ArrayBuffer(2);
new DataView(buffer).setInt16(0, 256, true /* 设置值时,使用小端字节序 */);
// Int16Array 使用系统字节序(由此可以判断系统字节序是否为小端字节序)
return new Int16Array(buffer)[0] === 256;
})();
console.log(littleEndian); // 返回 true 或 false
直接通过API读取设置,相比
TypedArray
更加灵活、简单,也可创建
复合视图
(将不同类型视图组合)。
// 16个字节的缓冲区
const buffer = new ArrayBuffer(16);
// 复合视图
const view = new DataView(buffer);
// 32位,4个字节
view.setInt32(1, 2147483647); // (max signed 32-bit integer)
// 8位,1个字节
view.setInt8(5, 34);
console.log(view.getInt32(1)); // 2147483647
console.log(view.getInt8(5)); // 34
NodeJS Buffer
Nodejs 里面的
Buffer
实例也是
JavaScript
的
Uint8Array
和
TypedArray
实例。全部
TypedArray
方法在
buffer
上都是支持的。但是
Buffer
API 和
TypedArray
API 有细微的不兼容。具体查看
Buffers and TypedArrays
。
实际使用
写了这么多,那到底实际中哪些场景可以使用?
- WebGL 游戏数据处理
- WebSockets、AJAX、Fetch、WebRTC 服务通信
- WebUSB、WebAudio 硬件通信
- Crypto 加密算法
后面会写一个游戏的运用场景,敬请期待。
中文转字节
// 字符串转utf8 unicode编码
function stringToByte(str) {
const bytes = new Array();
let c;
let len = str.length;
for (var i = 0; i < len; i++) {
c = str.charCodeAt(i);
if (c >= 0x010000 && c <= 0x10FFFF) {
// 4个字节范围
bytes.push(((c >> 18) & 0x07) | 0xF0);
bytes.push(((c >> 12) & 0x3F) | 0x80);
bytes.push(((c >> 6) & 0x3F) | 0x80);
bytes.push((c & 0x3F) | 0x80);
} else if (c >= 0x000800 && c <= 0x00FFFF) {
// 3个字节范围
bytes.push(((c >> 12) & 0x0F) | 0xE0);
bytes.push(((c >> 6) & 0x3F) | 0x80);
bytes.push((c & 0x3F) | 0x80);
} else if (c >= 0x000080 && c <= 0x0007FF) {
// 2个字节范围
bytes.push(((c >> 6) & 0x1F) | 0xC0);
bytes.push((c & 0x3F) | 0x80);
} else {
// 1个字节范围
bytes.push(c & 0xFF);
return bytes;
charCodeAt 获取到值的范围 0~65536 ,按8 bits切成4个字节。
字节转整数
4个字节数,每个
byte
即
8 bits
(可能是通过汉字的值的每个
8 bits
转过来的),所以可以表示的数值范围是
0~255
,每个值的二进制8位。




& 0xFF
将最高有效8位之外置 0
<<
取是截取对应的位数
|
将后面1个字节位合并(即数值相加)
// 转成有符号整数
0xFFFFFFFF // 无符号 4294967295 有符号 -1
(0xFFFFFFFF).toString(2)
// 11111111111111111111111111111111
// 通过 & 变成32位整数(有符号),并确保不会超过js整数的有效范围
n & 0xffffffff
// convert 4 bytes to unsigned integer
// 如果已经转成8位字节(0~255) ,可不用& 0xff
function byteToInt(bytes, off) {
off = off ? off : 0;
const b = ((bytes[off + 3] & 0xFF) << 24) |
((bytes[off + 2] & 0xFF) << 16) |
((bytes[off + 1] & 0xFF) << 8) |
(bytes[off] & 0xFF);
return b;
也可以使用 ArrayBuffer、DataView 来实现
// 初始化视图 0偏移 大端
function getView(bytes){
var view = new DataView(new ArrayBuffer(bytes.length));
for (var i = 0; i < bytes.length; i++) {
view.setUint8(i, bytes[i]);
return view;