自编码器(autoencoder, AE)是一类在半监督学习和非监督学习中使用的人工神经网络(Artificial Neural Networks, ANNs),属于深度学习领域的范畴,其功能是通过将输入信息作为学习目标,对输入信息进行表征学习。通常用于压缩降维,风格迁移和离群值检测等等。对于图像而言,图像的数据分布信息可以高效表示为编码,但是其维度和数据信息一般远小于输入数据,可作为强大的特征提取器,适用于深度神经网络的预训练,此外它还可以随机生成与训练数据类似的数据,以此来高效率的表达原数据的重要信息,因此通常被看作是生成模型。
自编码器在深度学习的发展过程中出现了很多变体,比如演化出去噪自编码器再到变分自编码器(Denoising Autoencoder,DAE),再到变分自编码器(Variational auto-encoder,VAE),最后到去耦变分自编码,随着时代的发展,往后会出现更多优秀的模型,但它的原理从数学角度都是从输入空间和特征空间开始,自编码器求解两者的映射的相似性误差,通过以下公式使其最小化.
求解完成之后,自编码器输出计算后的特征h,即编码特征,但在自编码运算过程中,容易混入一些随机性,在公式中标识为高斯噪声,然后将编码器的输出作为下一道解码器的输入特征,最终得到一个生成后的数据分布信息。
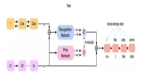
简单的架构如下所示,以变分自编码器(Variational auto-encoder,VAE)为例。
接下来,按照条理逻辑分别介绍。
1.自编码器(AE):
自编码器分成两个部分,第一个部分是encoder,一般是多层网络,将输入的数据压缩成为一个向量,变成低维度,而该向量就称之为瓶颈。第二个部分是decoder,灌之以瓶颈,输出数据,我们称之为重建输入数据。我们的目的是要让重建数据和原数据一样,以达到压缩还原的作用。损失函数就是让重建数据和原数据距离最小即可。损失函数参考图3。
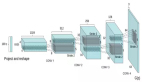
下图是一次训练一个浅层自编码器
首先,第一个自编码器学习去重建输入。然后,第二个自编码器学习去重建第一个自编码器隐层的输出。最后,这两个自编码器被整合到一起。缺点:低维度的瓶颈显然丢失了很多有用的信息,重建的数据效果并不好。
2.去噪自编码器(DAE)
这里要讲的是,我们拿到一张干净的图片,想象一下比如是干净的原始minst数据集,此时我们给原来干净的图片集加上很多噪声,灌给编码器,我们希望可以还原成干净的是图片集,以和AE相同的方式去训练,得到的网络模型便是DAE.
如上图,去噪编码器一般对最初输入增加噪声,通过训练之后得到无噪声的输出。这防止了自编码器简单的将输入复制到输出,从而提取出数据中有用的模式。增加噪声方式可以通过图6左侧增加高斯噪声,或者通过图6右侧的droupout,直接丢弃掉一层特征。
3.变分自编码器VAE
VAE和AE,DAE不同的是,原先编码器是映射成一个向量,现在是映射成两个向量,一个向量表示分布的平均值,另外一个表示分布的标准差,两个向量都是相同的正太分布。现在从两个向量分别采样,采样的数据灌给解码器。于是我们得到了损失函数:
损失函数的前部分和其他自编码器函数一样是重建loss损失,后部分是KL散度。KL散度是衡量两个不同分布的差异,有个重要的性质是总是非负的。仅当两个分布式完全相同的时候才是0。所以后部分的作用就是控制瓶颈处的两个向量处于正态分布。(均值为0,标准差为1)。这里有一个问题,从两个分布采样数据,BP时候怎么做?所以有一个技巧叫做参数重现(Reparameterization Trick),前向传播的时候,我们是通过以上公式得到z,BP的时候是让神经网络去拟合μ和σ,一般我们很难求的参数都丢给神经网络就好,就像Batch Normonization的γ和β一样。缺点效果还是比较模糊。
4.去耦变分自编码
我们希望瓶颈处的向量,即低维度的向量把编码过程中有用的维度保留下来,把没有用的维度用正态分布的噪声替代,可以理解为学习不同维度的特征,只是这些特征有好坏之分而已。我们仅需在loss function中加上一个β即可达到目的。
最后实验表明,VAE在重建图片时候对图片的<长度,宽度,大小,角度>四个值时候是混乱的,而去耦变分自编码器是能比较清晰的展示,最后生成的图片效果也更锐利清楚。至此,非常简单明了的介绍完了自编码到去噪自编码器到变分自编码器到去耦变分自编码。