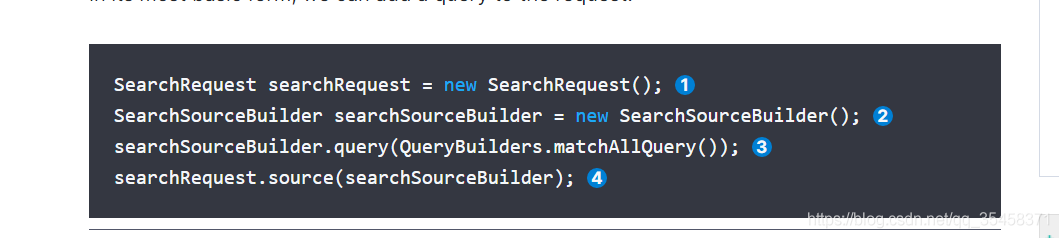
官方的简单查询如下图:
可以在
new SearchRequest
()里的()中加入索引,就会根据下图的代码查询索引下所有数据。
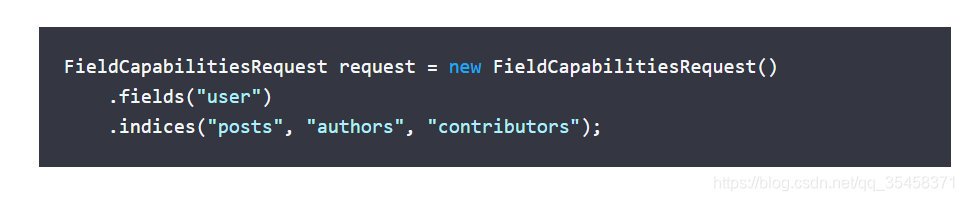
或者可以指定多个索引进行查询:
因为FieldCapabilitiesRequest继承的是SearchRequest,所以只需要直接像FieldCapabilitiesRequest一样把fields()和indices()添加到SearchRequest后面就行了。
可以指定多个field和index
。
查询某个索引下的所有数据:
在第一张图上的
searchSourceBuilder.query
()中添加参数如下两个:
// 我用的7.7es会自动中文分词
QueryBuilders.multiMatchQuery("我是老八");
//我用的7.7es会自动中文分词
// new MultiMatchQueryBuilder("我是宋三")也行
new MultiMatchQueryBuilder("我是宋三","user","message");
我自己的测试代码如下:(下面的可以不看,我自己存下来的方便自己查看)
package com.rg1b;
import org.apache.http.HttpHost;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.TransportAddress;
import org.elasticsearch.common.unit.TimeValue;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.MatchQueryBuilder;
import org.elasticsearch.index.query.MultiMatchQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightField;
import java.net.InetAddress;
import java.sql.*;
import java.util.Date;
import java.util.HashMap;
import java.util.Map;
import static org.elasticsearch.common.xcontent.XContentFactory.jsonBuilder;
public class Ceshi {
public static void createAndupdate(String[] args) throws Exception{
String sql = "select * from BLOG_USER LIMIT 100 ";
String driver = "com.mysql.cj.jdbc.Driver";
String url = "jdbc:mysql://ip:3306/数据库?serverTimezone=UTC&autoReconnect=true";
String user = "账号";
String pwd = "密码";
Class.forName(driver);
Connection conn = DriverManager.getConnection(url, user, pwd);
Statement statement = conn.createStatement();
ResultSet rs = statement.executeQuery(sql);
String username = "";
String password = "";
String Uname = "";
String ID = "";
String phone = "";
String mailbox = "";
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("localhost", 9200, "http")
Map<String, String> jsonMap = new HashMap<>();
//批量处理类
BulkRequest bulkrequest = new BulkRequest();
//批量从mysql中引到ES
while(rs.next()){
username = rs.getString("username");
password = rs.getString("password");
Uname = rs.getString("Uname");
ID = rs.getString("ID");
phone = rs.getString("phone");
mailbox = rs.getString("mailbox");
jsonMap.put("username", username);
jsonMap.put("password", password);
jsonMap.put("Uname", Uname);
jsonMap.put("ID", ID);
jsonMap.put("phone",phone);
jsonMap.put("mailbox", mailbox);
IndexRequest request = new IndexRequest("blog_user")
.id(ID).source(jsonMap);
bulkrequest.add(request);
BulkResponse bulkResponse = client.bulk(bulkrequest, RequestOptions.DEFAULT);
System.out.println(bulkResponse.toString());
public static void select(String[] args) throws Exception{
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("localhost", 9200, "http")
SearchRequest searchRequest = new SearchRequest();
searchRequest.indices("posts");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// String[] includeFields = new String[] {"user"};
// String[] excludeFields = new String[] {""};
// searchSourceBuilder.fetchSource(includeFields, excludeFields);
// searchSourceBuilder.query(QueryBuilders.multiMatchQuery("我是老八"));
searchSourceBuilder.query(new MultiMatchQueryBuilder("我是张三","user","message"));
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHits hits = searchResponse.getHits();
SearchHit[] searchHits = hits.getHits();
for (SearchHit hit : searchHits) {
// do something with the SearchHit
System.out.println(hit.getSourceAsString());
//最简单的添加索引数据
public static void zz(String[] args) throws Exception{
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("localhost", 9200, "http")
Map<String, Object> jsonMap = new HashMap<>();
jsonMap.put("user", "bababa");
jsonMap.put("postDate", new Date());
jsonMap.put("message", "张三");
IndexRequest request = new IndexRequest("posts")
.id("1").source(jsonMap);
IndexResponse indexResponse = client.index(request, RequestOptions.DEFAULT);
System.out.println(indexResponse.toString());
public static void main(String[] args) throws Exception{
select(null);
ES的模糊查询(ES查询),在多个索引或者单个索引,全局查询官方的简单查询如下图:可以在new SearchRequest()里的()中加入索引,就会根据下图的代码查询索引下所有数据。或者可以指定多个索引进行查询:因为FieldCapabilitiesRequest继承的是SearchRequest,所以只需要直接像FieldCapabilitiesRequest一样把fields()和indices()添加到SearchRequest后面就行了。可以指定多个field和index。查询某个索
作为一个分布式可扩展的实时搜索和分析引擎,一个建立在全文搜
索引擎 Apache Lucene基础上的搜
索引擎。
Elasticsearch 可以用于:分布式实时文件存储,并将每一个字段都编入
索引,使其可以被搜索;实时分析的分布式搜
索引擎;可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。
Elasticsearch的文件存储
Elasticsearch是面向文档型
数据库,一条数据在这里就是一个文档,用JSON作为文档序列化的格式,比如下面这条用户数据:
name : XiaoMing,
sex : Male,
一、基础操作
1、创建索引
elasticsearch不像关系型数据库需要先建表,指定具体的字段才能存入数据。我们可以直接向elasticsearch中插入数据,只要需要指定index(索引)和type(类型)就行了
格式如下:
PUT /index/type/id
“field1”:“value1”,
“field2”:“value2”
这是在没有预先创建索引的情况下,使用PUT...
Elasticsearch部署
1. 选择合理的硬件配置:尽可能使用 SSD
Elasticsearch 最大的瓶颈往往是磁盘读写性能,尤其是随机读取性能。使用SSD(PCI-E接口SSD
卡/SATA接口SSD盘)通常比机械硬盘(SATA盘/SAS盘)查询速度快5~10倍,写入性能提升不明显。
对于文档检索类查询性能要求较高的场景,建议考虑 SSD 作为存储,同时按照 1:10 的比例配置内存和
硬盘。对于日志分析类查询并发要求较低的场景,可以考虑采用机械硬盘作为存储,同时按照 1:50 的比
例配置内存和硬盘。单节点存储数据建议在2TB以内,不要超过5TB,避免查询速度慢、系统不稳定。
在单机存储 1TB 数据场景下,SATA 盘和 SSD 盘的全文检索性能对比(测试环境:Elasticsearch5.5.3,
10亿条人口户籍登记信息,单机16核CPU、64GB内存,12块6TB SATA盘,2块1.5 TB SSD盘)。
2. 给JVM配置机器一半的内存,但是不建议超过32G
修改 conf/jvm.options 配置,-Xms 和 -Xmx 设置为相同的值,推荐设置为机器内
Elasticsearch是一个分布式、Restful的搜索及分析服务器,Apache Solr一样,它也是基于Lucence的索引服务器,但我认为Elasticsearch对比Solr的优点在于:
轻量级:安装启动方便,下载文件之后一条命令就可以启动;
Schema free:可以向服务器提交任意结构的JSON对象,Solr中使用schema.xml指定了索引结构;
多索引文件支持:使用不同的index参数就能创建另一个索引文件,Solr中需要另行配置;
分布式:Solr Cloud的配置比较复杂。
启动Elasticsearch,访
可以使用Elasticsearch的聚合(Aggregation)功能来查询多个索引并对索引名进行分组。具体实现步骤如下:
1. 首先创建一个SearchRequest对象,设置要查询的索引列表和查询条件。
2. 创建一个TermsAggregationBuilder对象,设置聚合的字段为索引名,并设置其它聚合参数,如聚合大小、排序等。
3. 将TermsAggregationBuilder对象添加到SearchRequest对象中的AggregationBuilder列表中。
4. 使用RestHighLevelClient执行查询,将SearchRequest对象作为参数传入search()方法。
示例代码如下:
SearchRequest searchRequest = new SearchRequest("index1", "index2");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchAllQuery());
TermsAggregationBuilder aggregationBuilder = AggregationBuilders.terms("index_names").field("_index");
searchSourceBuilder.aggregation(aggregationBuilder);
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
Terms indexNames = searchResponse.getAggregations().get("index_names");
for (Terms.Bucket bucket : indexNames.getBuckets()) {
String indexName = bucket.getKeyAsString();
long docCount = bucket.getDocCount();
// Do something with indexName and docCount
以上示例代码中,我们查询了两个索引index1和index2,并对它们进行了分组。最后,我们使用聚合结果中的Bucket对象获取索引名和文档数量等信息。

