

聚类及可视化

背景
Consensus Clustering(一致性聚类)是一种无监督聚类方法,是一种常见的癌症亚型分类研究方法,可根据不同组学数据集将样本区分成几个亚型,从而发现新的疾病亚型或者对不同亚型进行比较分析。这类文章一般会对基因表达量(芯片数据或者RNA-seq数据)或甲基化等数据进行聚类分析,选出最优聚类数;对聚出的类组进行差异化表达分析得到DEGs,差异表达基因做GO、pathway,PPI等一系列分析,在分析一下与生存的关系、免疫细胞丰度的区别,等等。找出了分之间免疫细胞有区别、生存有区别,一篇揭示XX癌免疫应答异质性的文章就来了。Consensus Clustering 的基本原理假设:从原数据集不同的子类中提取出的样本构成一个新的数据集,并且从同一个子类中有不同的样本被提取出来,那么在新数据集上聚类分析之后的结果,无论是聚类的数目还是类内样本都应该和原数据集相差不大。因此所得到的聚类相对于抽样变异越稳定,我们越可以相信这一样的聚类代表了一个真实的子类结构。重采样的方法可以打乱原始数据集,这样对每一次重采样的样本进行聚类分析然后再综合评估多次聚类分析的结果给出一致性(Consensus)的评估。总结,一致聚类通过基于重采样的方法来验证聚类合理性,其主要目的是评估聚类的稳定性,可用于确定最佳的聚类数目K。
相比其他聚类方法一致性聚类的优势:
不能提供“客观的”分类数目的标准和分类边界,例如Hierarchical Clustering。
需要预先给定一个分类的数目,且没有统一的标准去比较不同分类数目下分类的结果,例如K-means Clustering。
聚类结果的合理性和可靠性无法验证。
一致性聚类需要z-score标准化,通常scale函数,均值为0,标准差为1;
NMF聚类为了不让矩阵出现负值,我们在这里用归一化。归一化(Normalization)这样数据的范围在[0,1]之间
1.1 MSigDB
hypoxia=read.csv("hypoxia.csv",header=TRUE,sep=",")
hypoxiagene1=tpmdata[rownames(tpmdata)%in%hypoxia$gene,]
hypoxiagene2=log2(hypoxiagene1+1)
1.2 先看看heatmap
library(pheatmap)
pheatmap(hypoxiagene1, #表达数据
cluster_rows = T,#行聚类
cluster_cols = T,#列聚类
annotation_col =annotation_c, #样本分类数据
annotation_row = annotation_r,
annotation_legend=TRUE, # 显示样本分类
show_rownames = T,# 显示行名
scale = "row", #对行标准化
color =colorRampPalette(c("#8854d0", "#ffffff","#fa8231"))(100), # 热图基准颜色
)一致性聚类
ConsensusClusterPlus则将Consensus Clustering在 R 中实现了
if (!requireNamespace("BiocManager", quietly = TRUE))
install.packages("BiocManager")
BiocManager::install("ConsensusClusterPlus")
library(ConsensusClusterPlus)
ConsensusClusterPlus(d=d, maxK = 3, reps=1000, pItem=0.8,
pFeature=1, clusterAlg="hc", ##文章多选用km,
title="untitled_consensus_cluster",
innerLinkage="average",
finalLinkage="average",
distance="pearson", ml=NULL, ##文章多选用欧氏距离euclidean
tmyPal=NULL,seed=NULL,
plot="png",writeTable=FALSE,weightsItem=NULL,
weightsFeature=NULL,verbose=F,corUse="everything")
常用参数:
d 提供的需要聚类的数据矩阵,其中列是样本,行是features,可以是基因表达矩阵。
maxK 聚类结果中分类的最大数目,必须是整数。
reps重抽样的次数
pItem 样品的抽样比例,如 pItem=0.8 表示采用重抽样方案对样本的80%抽样,经过多次采样,找到稳定可靠的亚组分类。
pFeature Feature的抽样比例
clusterAlg 使用的聚类算法,“hc”用于层次聚类,“pam”用于PAM(Partioning Around Medoids)算法,“km”用于K-Means算法,也可以自定义函数。
title 设置生成的文件的路径
distance 计算距离的方法,有pearson、spearman、euclidean、binary、maximum、canberra、minkowski。
tmyPal可以指定一致性矩阵使用的颜色,默认使用白-蓝色
seed 设置随机种子。
plot 不设置时图片结果仅输出到屏幕,也可以设置输出为'pdf', 'png', 'pngBMP' 。
writeTable 若为TRUE,则将一致性矩阵、ICL、log输出到CSV文件
weightsItem 样品抽样时的权重
weightsFeature Feature抽样时的权重
verbose 若为TRUE,可输出进度信息在屏幕上
corUse 设置如何处理缺失值:all.obs:假设不存在缺失数据——遇到缺失数据时将报错;everything:遇到缺失数据时,
相关系数的计算结果将被设为missing
complete.obs:行删除; pairwise.complete.obs:成对删除,pairwisedeletion
calcICL函数:
calcICL(res,title="consensus_cluster",plot=NULL,writeTable=FALSE)
res consensusClusterPlus的结果
title 设置生成的文件的路径
plot 不设置时图片结果仅输出到屏幕,也可以设置输出为'pdf', 'png', 'pngBMP' 。
writeTable 若为
TRUE,则将一致性矩阵、ICL、log输出到CSV文件

1. 数据准备
1.1 sweep函数中位数中心化
#对上面这个芯片表达数据我们一般会简单的进行normalization (本次采用中位数中心化)
mads=apply(d,1,mad) # mad(x) 绝对中位数差 按行(1)取d数据的中位数,#计算每个基因的标准差
d=d[rev(order(mads))[1:5000],] #去除前5000个数据
d = sweep(d,1, apply(d,1,median,na.rm=T)) #sweep函数对基因表达数据执行中位数中心化,以用于后续聚类
#按行减去中位数,r语言中使用sweep(x, MARGIN, STATS, FUN="-", ...) 对矩阵进行运算。MARGIN为1,表示行的方向上进行运算,
#为2表示列的方向上运算。STATS是运算的参数。FUN为运算函数,默认是减法。
#也可以对这个d矩阵用DESeq的normalization 进行归一化,取决于具体情况1.2 在R中提供了一个用于标准化的函数,即scale()函数。先了解一下scale()函数及其参数。
还可以使用z-score的方法来对表达谱数据进行标准化:z-score=(表达量-均值)/标准差
scale(x, center = TRUE, scale = TRUE)
d1<- as.data.frame(t(scale(t(d1))))
d1=as.matrix(d1)上面是scale()函数的格式,x——就是需要标准化的数值矩阵,center——决定了怎样计算一列数据的均值。它可以是一个逻辑值或与x的列数相等的数值向量,若为数值向量,则x中的每一列的值减去此数值向量中对应该列的值,也就是说可以人为的设定均值;若center为逻辑值,默认为TRUE,表示x中的每一列会减去对应列的算术平均值,若为FASLE,则不做减法处理。scale——决定了怎样计算一列数据的缩放比例,及标准差。它也可以是一个逻辑值或者与x中列数相等数值向量。若为数值向量,则x中每一列的缩放比例按此向量中的数值进行计算,即可以人为设置均方根(标准差)。如果scale为逻辑值,默认为TRUE,表示经过上一步center计算后的数据会除以该列求出的均方根(标准差),若为FALSE,则不除。
2. ConsensusClusterPlus
library(ConsensusClusterPlus)
results <- ConsensusClusterPlus(d = d, # 分析矩阵
maxK = 7, # 最大聚类数目
reps = 1000, # 重抽样的次数
pItem = 0.8, # 样品的重抽样比例
clusterAlg = "km", # 使用的聚类算法,可以选择"hc"(hclust), "pam", "km"(k-means) hc对应pearson
innerLinkage = "ward.D2", finalLinkage = "ward.D2",
distance = "euclidean", # 计算距离的方法,可以选择pearson、spearman、euclidean、binary/maximum、canberra、minkowski
seed = 123456, # 设置随机种子,方便重复
plot = "png", # 结果图片的导出类型,可以选择"png"或者"pdf"
title = "Consensus Cluster")
之后进行提取基因集等后续操作,ConsensusClusterPlus的输出是一个列表,其中列表对应于来自KTH集群的结果,
例如,results[[2]]是结果k=2。consensusMatrix输出一致矩阵。
分类树及结果:
results[[4]][["consensusMatrix"]][1:5,1:5]
results[[2]][["consensusTree"]]
results[[2]][["consensusClass"]][1:5]
进行验证 你可以用flexclust包中的兰德指数(Rand index)来量化类型变量和类之间的协议
r1=results1[[2]][["consensusClass"]]
r2=results2[[2]][["consensusClass"]]
check <- table(r1, r2)
library(flexclust)
randIndex(check)3. 聚类结果展示
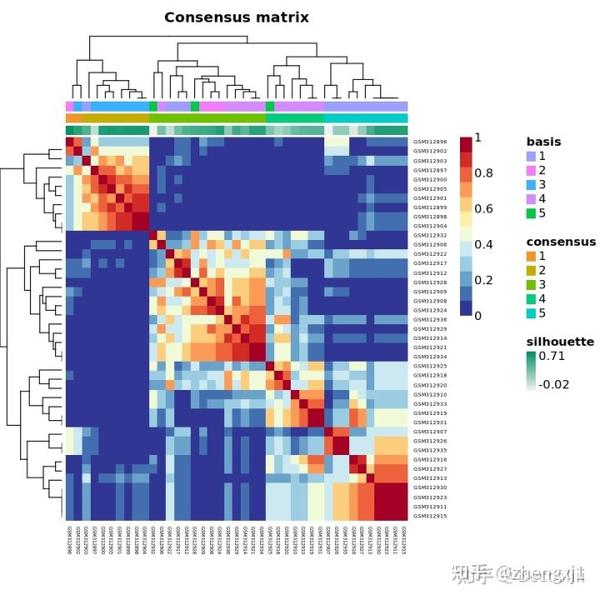
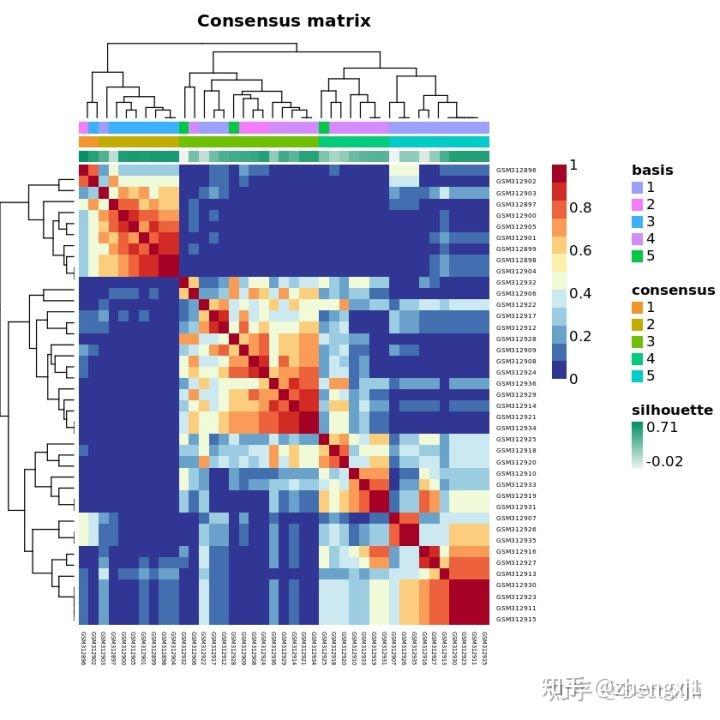
(1)k = 2, 3, 4, 5, 6 时的矩阵热图:矩阵的行和列表示的都是样本,一致性矩阵的值按从0(不可能聚类在一起)到1(总是聚类在一起)用白色到深蓝色表示,一致性矩阵按照一致性分类(热图上方的树状图)来排列。树状图和热图之间的长条即分出来的类别。注意第一张为图例;


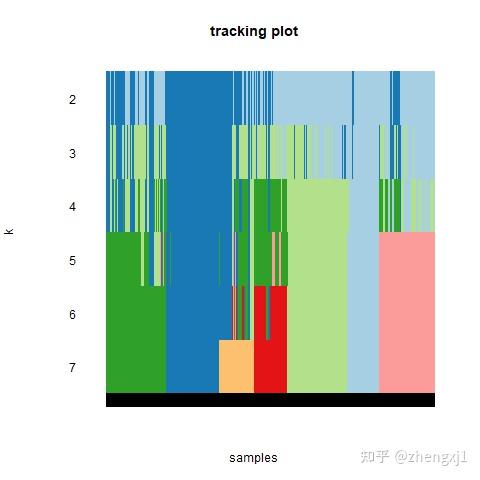
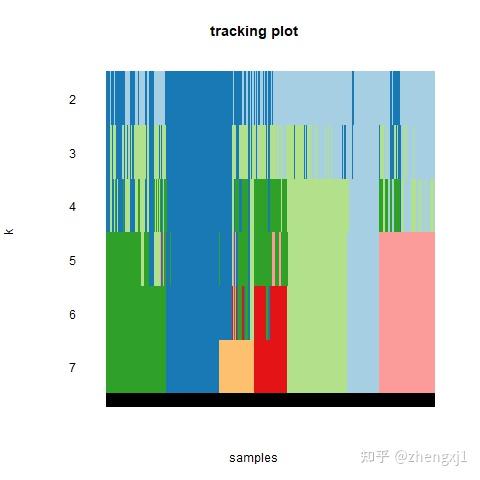
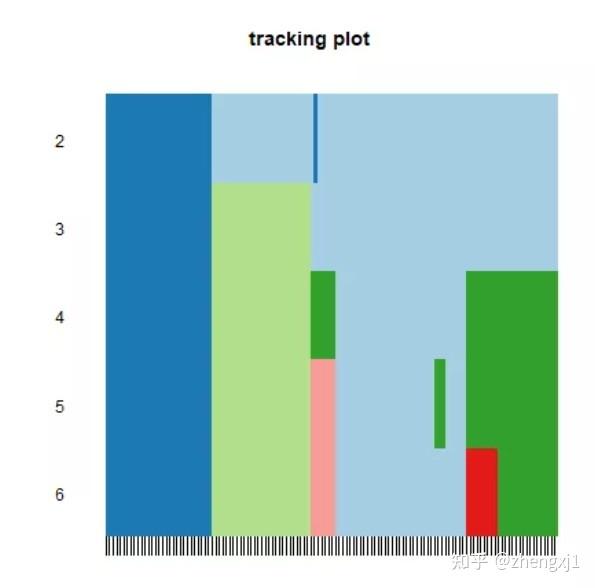
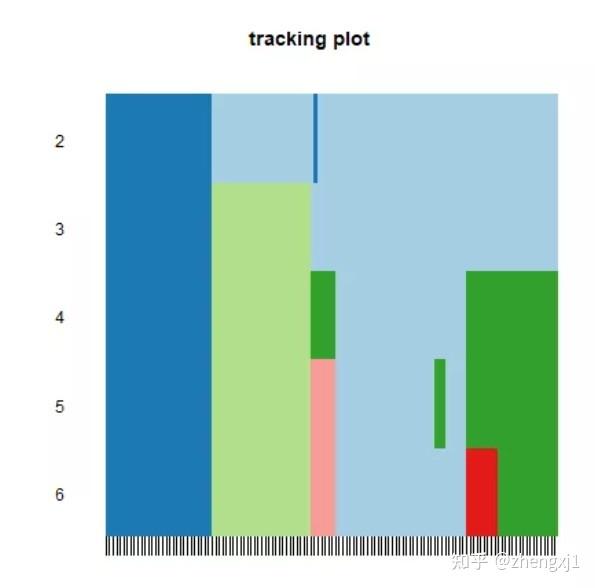
tracking plot :图片下方的黑色条纹表示样品(这里因为样本太多,看起来像是一个黑色图形),展示的是样品在k取不同的值时,归属的分类亚型情况,不同颜色的色块代表不同的亚型。取不同k值前后经常改变颜色分类的样品表示这个样品分类不稳定。若分类不稳定的样本太多,则说明该k值下的分类不稳定。
(2)一致性累积分布函数图:简称为CDF图,这张图展示了k取不同数值时的累积分布函数,用于判断k值的最佳取值,当CDF达到一个近似最大值时,此时的聚类分析结果最可靠,对应的k值就是最佳k值,得到的分类就是最佳分类。即考虑CDF下降坡度小的k值。
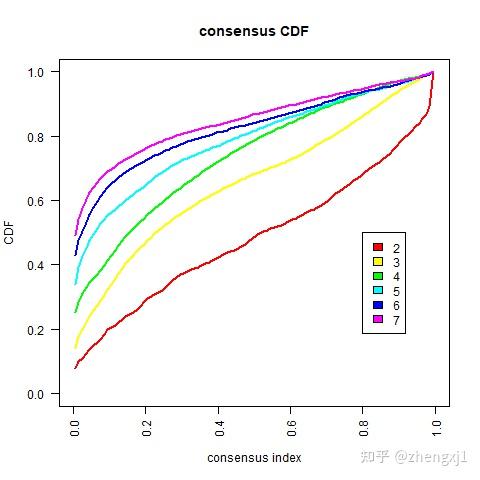
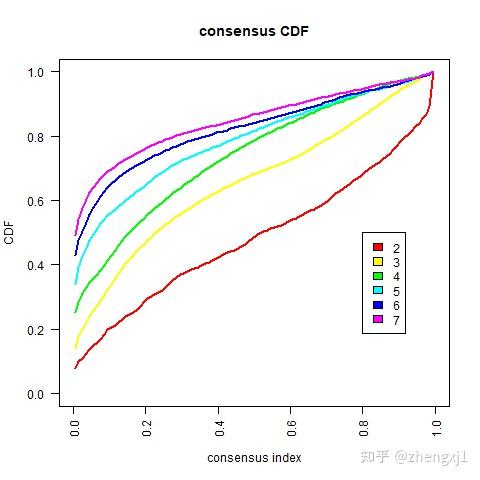
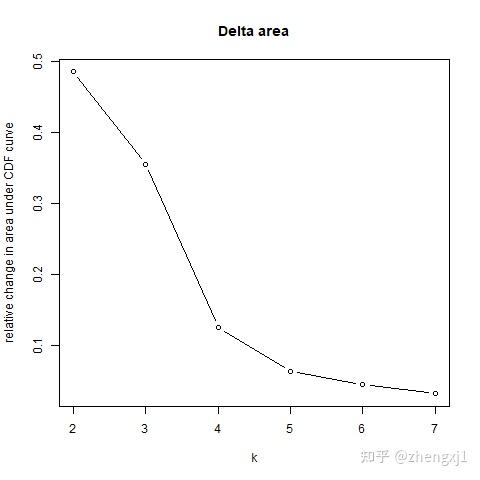
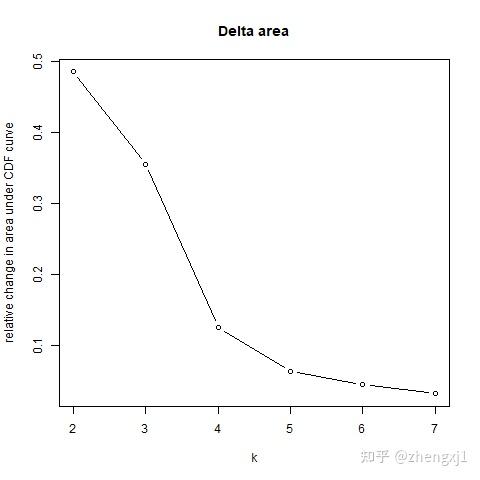
(3)Delta Area Plot:这张图展示了 k 和 k-1 相比CDF曲线下面积的相对变化。当k = 2时,因为没有k=1,所以第一个点表示的是k=2时CDF曲线下总面积,而当k = 5 时,曲线下面积趋近于平稳,所以7为最合适的k值。
4. 计算聚类一致性 (cluster-consensus) 和样品一致性 (item-consensus)
icl <- calcICL(results, title = title,plot = "png")
dim(icl[["clusterConsensus"]])
icl[["clusterConsensus"]]
dim(icl[["itemConsensus"]])
icl[["itemConsensus"]][1:5,](1)Tracking Plot:此图下方的黑色条纹表示样品,展示的是样品在k取不同的值时,归属的分类情况,不同颜色的色块代表不同的分类。取不同k值前后经常改变颜色分类的样品代表其分类不稳定。若分类不稳定的样本太多,则说明该k值下的分类不稳定。
(2)Cluster-Consensus Plot:聚类一致性图 此图展示的是不同k值下,每个分类的cluster-consensus value(该簇中成员pairwise consensus values的均值)。该值越高(低)代表稳定性越高(低)。可用于判断同一k值下以及不同k值之间cluster-consensus value的高低。
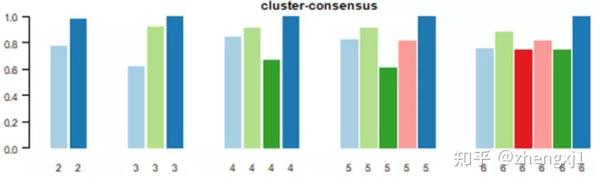
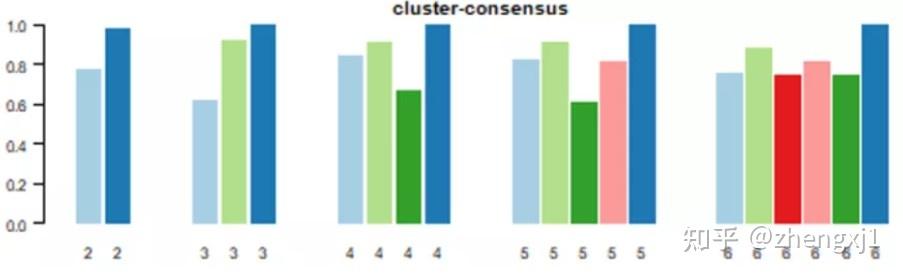
(3)item-Consensus Plot:样本一致性图 纵坐标代表Item-consensus values。k值不同时,每个样本都会有一个对应不同簇的item-consensus values。竖条代表每一个样本,竖条的高度代表该样本的总item-consensus values。每个样本的上方都有一个小叉叉,小叉叉的颜色代表该样本被分到了哪一簇。从这张图,可以看到每个样本的分类是否足够“纯净”,从而帮助决定k值,例如当k=6时,样本的分类变得没有那么纯净,说明k=5才是合适的。条形的矩形按从下到上递增的值排列。顶部的星号表示每个样本的consensus cluster。
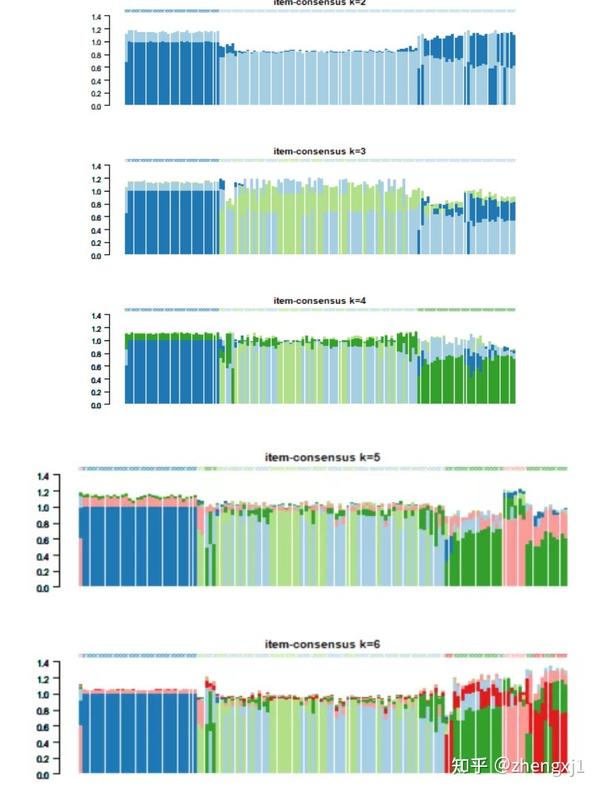
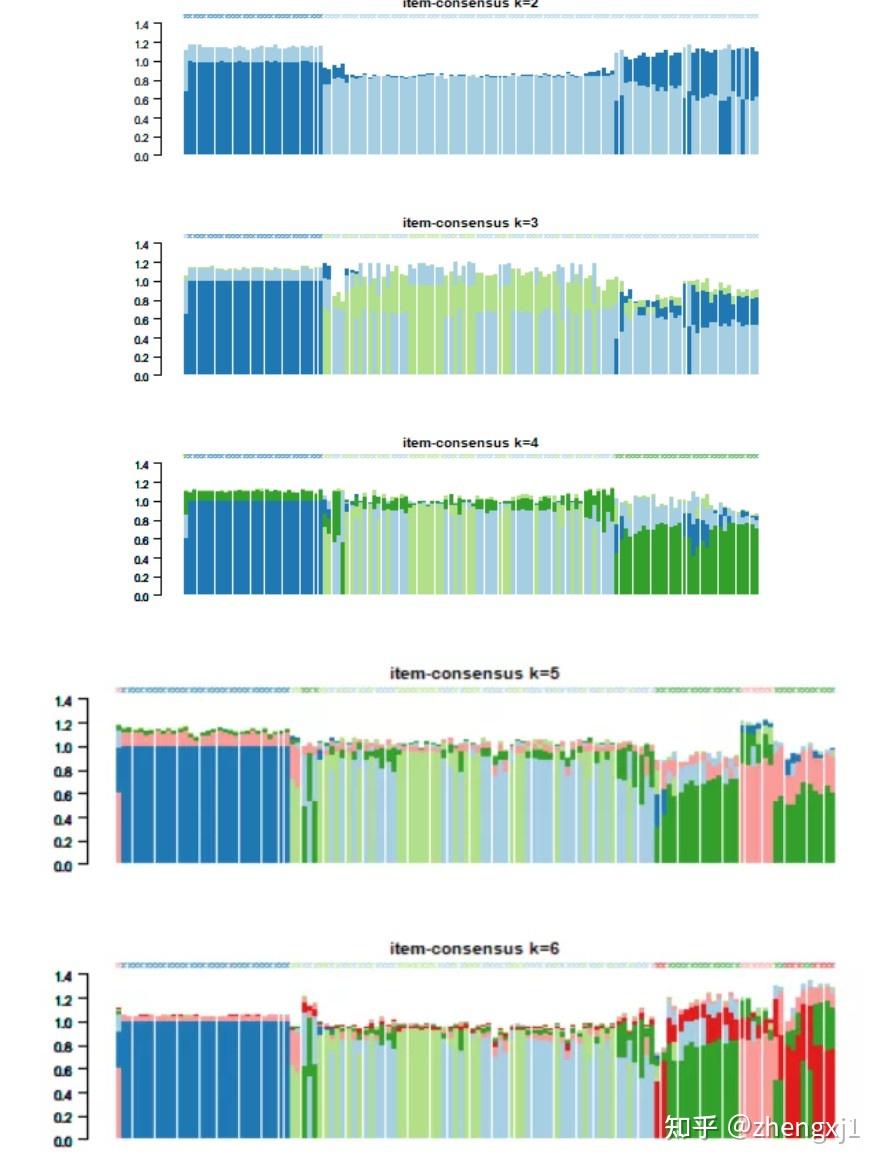
通过上面的结果解读我们可以选取出初步分类的亚组的个数,但是这种方法有时候带有主观性,我们也可以用PAC法确定最佳聚类数目。此外,如果对于Consensus Cluster Plus包得到的图片的颜色不太喜欢,我们还可以重新进行绘图:
Kvec <- 2:7
x1 = 0.1
x2 = 0.9
PAC <- rep(NA,length(Kvec))
names(PAC) <- paste("K =", Kvec, sep="")
for(i in Kvec){
M = Cluster[[i]]$consensusMatrixFn = ecdf(M[lower.tri(M)])# 计算出共识矩阵
PAC[i-1] = Fn(x2) - Fn(x1)
}
optK <- Kvec[which.min(PAC)]# 理想的K值
NMF聚类
针对基因表达矩阵或者芯片数据,可以基于表达水平对数据进行无监督聚类分析。 完成这个功能的算法有很多种,如非负矩阵分解(nonnegative matrix factorization),一致性聚类(consensus clustering), 自组织映射(SOM clustering)等,文章 Metagenes and molecular pattern discovery using matrix factorization 介绍和比较了几种算法,文章总结NMF算法更优,但其他几种算法针对不同特征的数据也各有偏好,可以多了解一下算法再自行选择。
用法:
nmf(x, rank, method, seed = nmf.getOption("default.seed"), rng = NULL, nrun = if (length(rank) > 1) 30 else 1, model = NULL, .options = list(), .pbackend = nmf.getOption("pbackend"), .callback = NULL, ...)接下来我们看下nmf函数的主要参数:
x:就是我们的表达矩阵;
rank:因式分解秩的说明。它通常是一个单一的数值,但也可能是其他类型的值(例如矩阵),为其实现特定的方法。你可以理解成分几群。
method:就是NMF算法的选择,总共有11种,可通过nmfAlgorithm()函数查看,默认brunet。


nrun:范围内每个值的迭代次数;
model:如果有已经构建好的模型,那就是直接把模型写在这里,优化等级计算。构建模型的函数是nmfModel(rank,c(features,samples))或者是nmfModel(rank,data,W,H)。
.options:可以设置是否保留每次的运算结果:keep.all=T。例:.options=list(keep.all=TRUE);
下面是该文章的TCGA数据处理方式。


输入数据格式,可能使用tpm较好
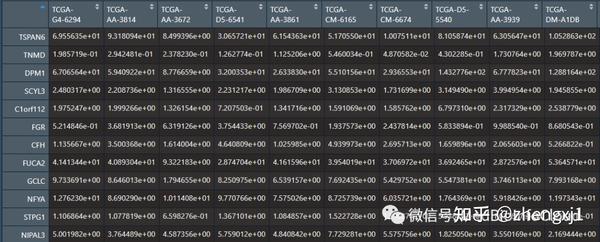
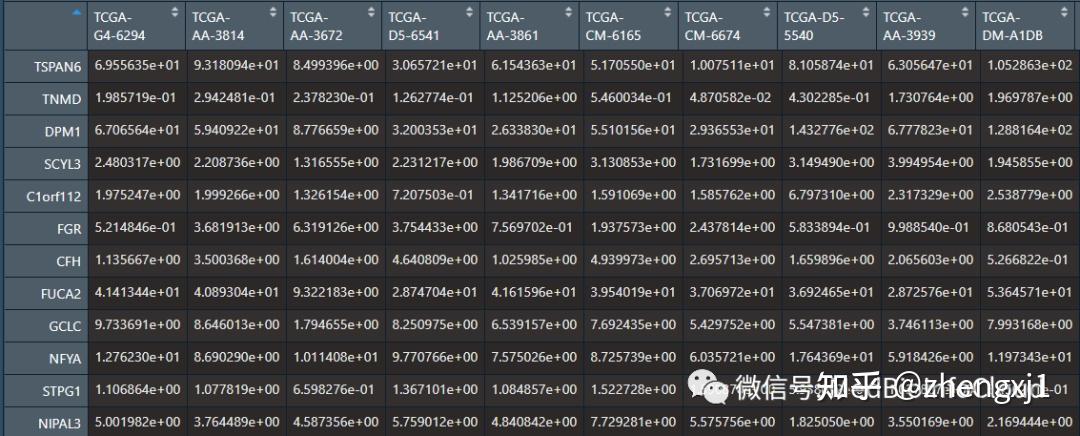
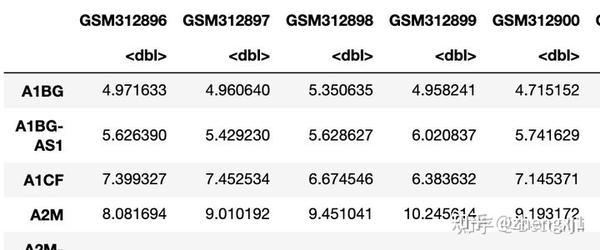
算法的使用


1.1 数据准备
#做聚类前先对数据标准化,这很重要!
#原因请查看《R语言实战》的第352页
#为了不让矩阵出现负值,我们在这里用归一化。归一化(Normalization)这样数据的范围在[0,1]之间
#标准化(Standardization),这样数据的均值为0,标准差为1,也成为z-score 标准化数据可以使用R语言的scale函数 scale(data, center=T,scale=T)
#归一化,标准化,中心化,scale的知识请参考下面的博客:
https://blog.csdn.net/tanzuozhev/article/details/50602051
hypoxiagene2 <- log2(hypoxiagene1 + 1)
normalize <- function(x){return((x-min(x))/(max(x)-min(x)))}
NMFmatrix <- normalize(nmf)
library(NMF)
library(doMPI) #rank设定4以上需要用这个包
#选定rank
# compute NMF for each method, rank设定为2:7 (2,3,4,5,6,7都试一遍一起比较)
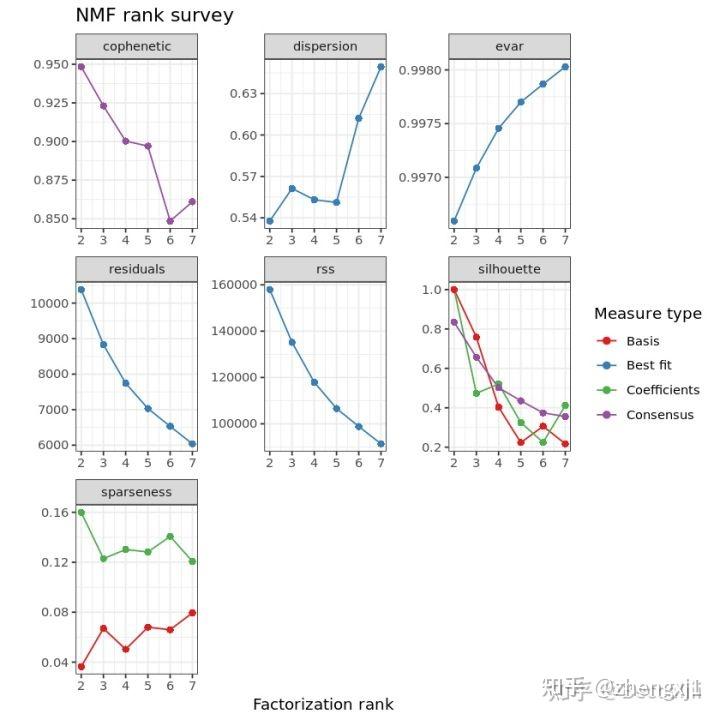
res <- nmf(NMFmatrix,2:10,nrun=50,seed=123,method = 'brunet')
plot(res)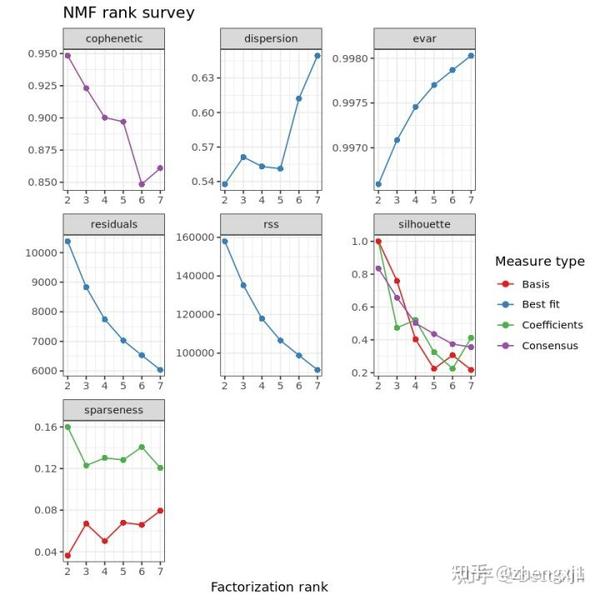
#选用较优rank再运行一次NMF
res <- nmf(NMFmatrix,5,nrun=10)
coefmap(res)
consensusmap(res)这里的选择用默认设置的热图来展示结果,详细的还有很多参数可以优化结果输出形式,这一步还没有太理解,仅放图做参考哈。
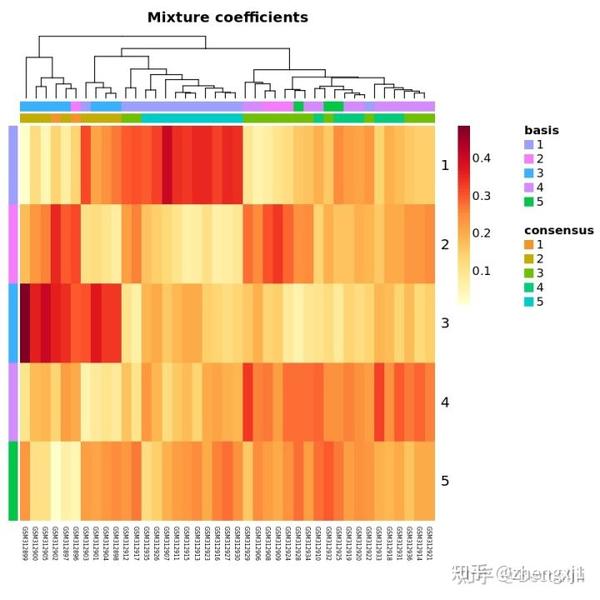
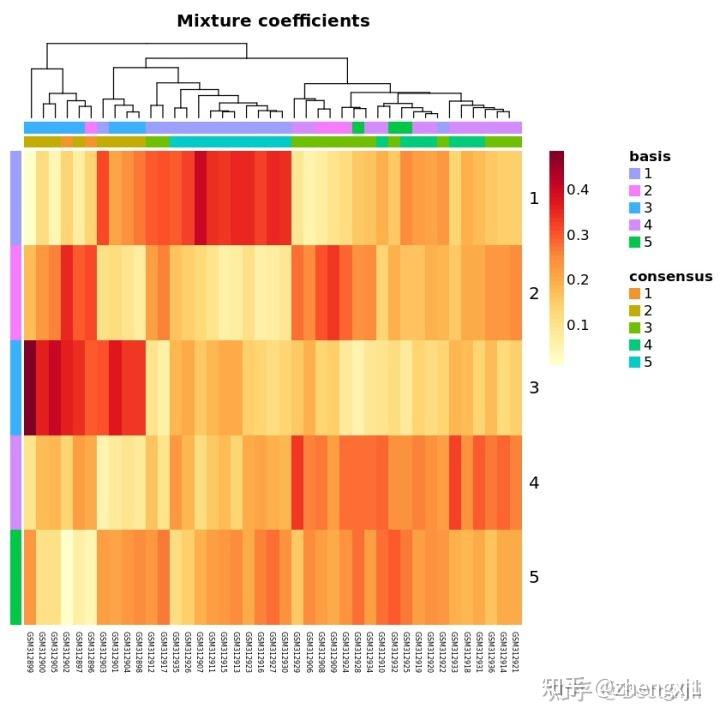
NMF包中包含不同的算法method(第三个参数),默认使用brunet,可以比较算法择优录用
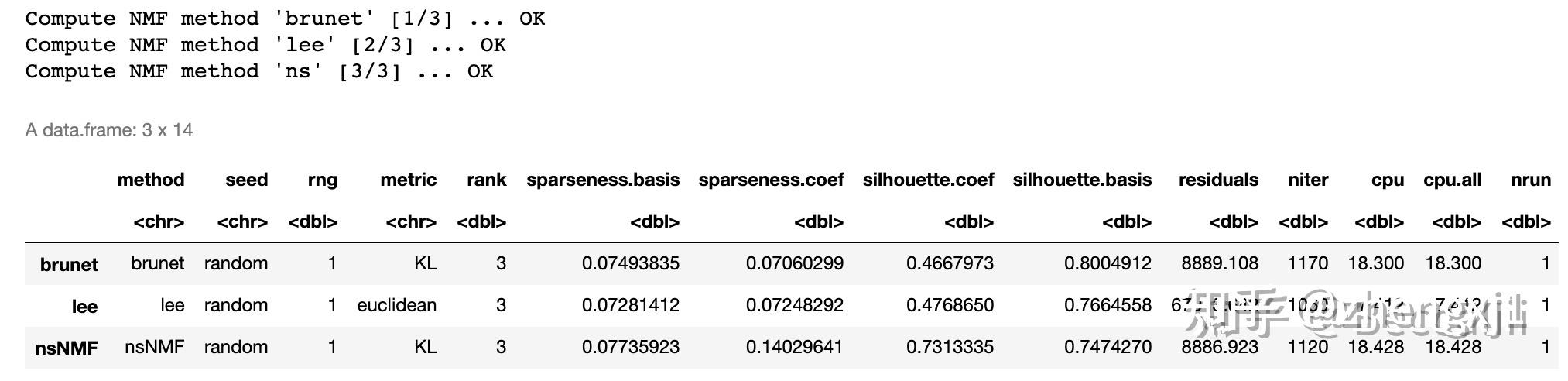
res.multi.method <- nmf(dat, 3, list('brunet', 'lee', 'ns'), seed=222)
compare(res.multi.method)
#为方便展示,这里选择聚类成2簇;
rank <- 2
seed <- 123
res2 <- nmf(NMFmatrix,
rank = rank,
seed = seed,
method = "brunet")
#查看分组情况
group <- predict(res2)
group <- as.data.frame(group)
group$group <- paste0('Cluster',group$group)
group$sample <- rownames(group)
group <- group[order(group$group),]
table(group$group) tSNE降维可视化
library(Rtsne)
library(RColorBrewer)
data= ###导入数据
data=t(data) ##转置,行为样本,列为基因名
data = unique(data) # 去除重复数据
1.1 Rtsne
set.seed(321) # 设置随机数种子
tsne= Rtsne(
data,
dims = 2,
pca = T,
max_iter = 1000,
theta = 0.4,
perplexity = 20,
verbose = F
) # 进行t-SNE降维分析
1.2
kmeans算法以k为参数,把n个对象分为k个聚类,以使聚类内具有较高的相似度,而聚类间的相似度较低。相似度的计算是根据一个聚类中对象的均值来进行的。kmeans算法的处理流程如下:随机地选择k个对象,每个对象初始地代表了一个簇的平均值或中心;对剩余的每个对象,根据其与各个聚类中心的距离将其赋给最近的簇;重新计算每个簇的平均值作为聚类中心进行聚类。这个过程不断重复,直到准则函数收敛,得到最终需要的k个类,算法结束;准则函数通常采用最小平方误差准则
kmeans(data,centers,iter.max)可以直接用来做K-means聚类,其中data代表输入的待聚类样本,形式为样本x变量,
centers代表设定的聚类簇数量,iter.max代表算法进行迭代的最大次数,一般比较正常的数据集不会消耗太多次迭代。
#自定义代价函数计算函数
Mycost <- function(data,centers_){
l <- length(data[,1])
d <- matrix(0,nrow=l,ncol=length(centers_[,1]))
for(i in 1:l){
for(j in 1:length(centers_[,1])){
dd <- 0
for(k in 1:length(data[1,])){
dd <- dd + (data[i,k]-centers_[j,k])^2
d[i,j] <- sqrt(dd)
mindist <- apply(d,1,min)
return(sum(mindist))
opar <- par(no.readonly = TRUE)
### par()函数可以用来设置或者获取图形参数。 函数par()可以全局设置图形参数,而在具体作图函数plot()
### opar <- par(no.readonly = TRUE)用来更改当前变量环境
### 或 lines()是临时设置图形参数。
#初始化代价函数记录向量
zb <- c()
par(mfrow=c(2,2)) ###设置绘图函数,mfrow参数)实现一页多图的功能,2*2=4个图
cols<-brewer.pal(n=5,name="Set1") ###设置颜色
for(i in 2:5){
kmeans <- kmeans(data,centers = i,iter.max = 10)
plot(tsne$Y,xlab="tSNE dim 1", ylab="tSNE dim 2", col=cols[kmeans$cluster],pch=19,cex=0.9)
title(paste(as.character(i),'Clusters'))
zb[i-1] <- Mycost(data,kmeans$centers)
par(opar)
####如果不用tsne降维,则此处选择data数据
#col表示给原数据添加一列,颜色列,为每个样本指定一个颜色
#pch=19,表示指定实心圆点,不加该参数默认是空心圆点
绘制代价函数变化图:
#绘制代价函数随k的增加变化情况
plot(2:5,zb,type='o',xaxt='n',xlab='K值',ylab='Cost')
axis(1,at=seq(2,5,1))
title('Cost Change')
决定采用分类数之后:
newdata=data.frame(data,paste("cluster",kmeans$cluster) ###生成新的数据框
TSNEkmeans=factor(kmeans$cluster)
tsne <- data.frame(tSNE1=tsne_out$Y[,1],
tSNE2=tsne_out$Y[,2],
TSNEkmeans,levels = c("low","high"))
for (i in 1:50) {undefined
set.seed(i)
tsne_i <- Rtsne(data, dims = 2, perplexity=i, verbose=F, pca = T, max_iter = 500,check_duplicates = F)
set.seed(i)
#用K-means进行二次聚类,设定K-means簇的个数为10
cl_i <- kmeans(tsne_i$Y, centers = 10, nstart = 3,algorithm="Lloyd") # k = 10
#将聚类结果存为PNG图片格式,大小为800*600
png(file = paste("path",1,"tsne_kmeans.png"),width = 800, height = 600)
plot(tsne_i$Y, t = "n")
#以数据标签来显示聚类结果,以不同颜色区分簇
text(tsne_i$Y,labels=row.names(data),font =1, cex = 0.8,col = cl_i$cluster)
dev.off()
}


tsneOut <- Rtsne(data,dims=2,
PCA=F,
perplexity=10,
verbose=F,
max_iter=500,
check_duplicates=F)
tsne <- data.frame(tSNE1=tsneOut$Y[,1],
tSNE2=tsneOut$Y[,2],
risk=factor(data$group,levels = c("low","Cluster2")))下面结合ggplot2进行绘图:
library(ggsci)
ggplot(tsne,aes(tSNE1,tSNE2))+
geom_point(aes(color=risk))+
scale_color_lancet()+