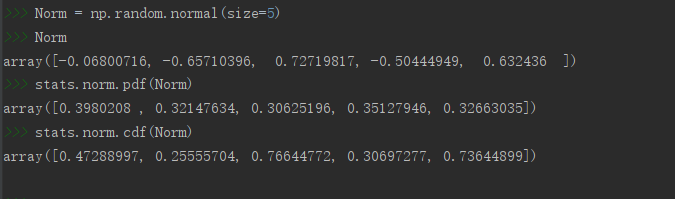
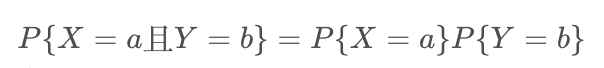随机变量X和Y的协方差(Covariance)可以衡量二者之间的关系,描述的是两随机变量与各自期望的偏差共同的变动状况,表达式为:
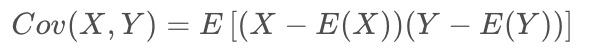
协方差为正说明,平均而言变量X、Y与各自期望的偏差呈同方向变动;如果为负,则为反方向变动。
协方差有如下性质:
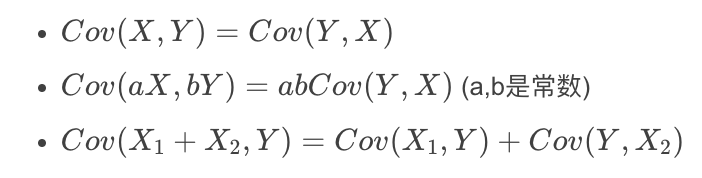
第二个性质说明,协方差受比例影响,并不能准确地衡量两变量相关性的大小。,不能直接衡量两变量相关性强弱。对协方差进一步处理,清除比例的影响,于是就有了相关系数(Correlation Coefficient):
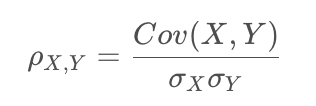
相关系数取值范围为[-1,+1]
ρ=0时,说明两个变量是不相关的。
0<ρ<1时, 说明两变量呈正向的线性关系
-1<ρ<0时,说明两变量呈负向的线性关系。
aX和bX的相关性:
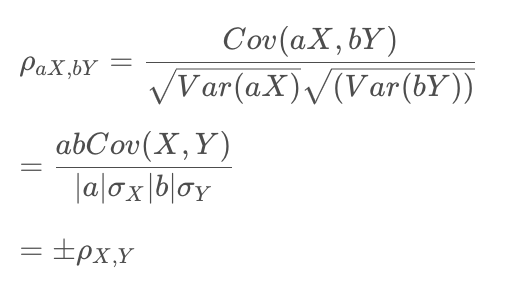
如果变量Y是X的线性变换,满足Y=a+bX,则二者之间的相关系数为:‘
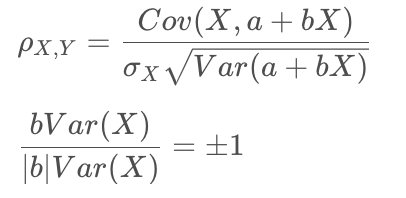
上证指数和深证成指是股票市场常用的反映股票市场情况的指数,我们认为两个指数的日收益率可以存在相关的关系。代码如下:
import numpy as np
import tushare as ts
import pandas as pd
token = 'Your Token'
pro = ts.pro_api(token)
SZindex = pro.index_daily(ts_code='399001.SZ')
SZindex['trade_date'] = pd.to_datetime(SZindex['trade_date'])
SZindex.set_index(['trade_date'], inplace=True)
SZindex = SZindex.sort_index()
SHindex = pro.index_daily(ts_code='000001.SH')
SHindex['trade_date'] = pd.to_datetime(SHindex['trade_date'])
SHindex.set_index(['trade_date'], inplace=True)
SHindex = SHindex.sort_index()
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.scatter(SHindex.pct_chg['2020'],SZindex.pct_chg['2020'])
plt.title('上证指数与深证成指2020年收益率散点图')
plt.xlabel('上证指数收益率')
plt.ylabel('深证成指收益率')
plt.show()
生成图像展示如下:

SHindex.pct_chg['2020'].corr(SZindex.pct_chg['2020'])

相关系数为0.9308847411746248,可以认为二者存在较强的相关性,二者呈现正向的线性关系。
python机器学习数据建模与分析——决策树详解及可视化案例
你是否玩过二十个问题的游戏,游戏的规则很简单:参与游戏的一方在脑海里想某个事物,其他参与者向他提问题,只允许提20个问题,问题的答案也只能用对或错回答。问问题的人通过推断分解,逐步缩小待猜测事物的范围。决策树的工作原理与20个问题类似,用户输人一系列数据,然后给出游戏的答案。我们经常使用决策树处理分类问题,近来的调查表明决策树也是最经常使用的数据挖掘算法。它之所以如此流行,一个很重要的原因就是使用者基本上不用了解机器学习算法,也不用深究它是如何工作的。