摘要:
本文是一篇pandas/networkx图分析入门,对所举的欺诈检测用例进行了简单的图论分析,便于可视化及操作。
对于图论而言,大家或多或少有些了解,数学专业或计算机相关专业的读者可能对其更加清楚。图论中的图像是由若干给定的点及连接两点的线所构成的图形,这样的图像通常用来描述某些事物之间的某种特定关系,用点代表事物,用两点之间的连接线表示二者具有的某种关系,在互联网与通信行业中应用广泛。图论分析(Graph analysis)并不是数据科学领域中的新分支,也不是数据科学家目前应用的常用首选方法。然而,图论可以做一些疯狂的事情,一些经典用例包括欺诈检测、推荐或社交网络分析等,下图是 NLP中的非经典用例——处理主题提取。
欺诈检测用例
假设现在你有一个客户数据库,并想知道它们是如何相互连接的。特别是,你知道有些客户涉及复杂的欺诈结构,但是在个人层面上可视化数据并不会带来欺诈证据,欺诈者看起来像其他普通客户一样。
只需查看原始数据,处理用户之间的连接就可以显示更多信息。具体而言,对于通常的基于机器学习的评分模型而言,这些特征不会被视为风险,但这些不会被认为存在风险的特征可能成为基于图表分析评分模型中的风险特征。
示例:三个具有相同电话号码的人,连接到具有相同电子邮件地址的其他人,这是不正常的,且可能存在风险。电话号码本身没有什么价值,并不会提供任何信息(因此,即使最好的深度学习模型也不能从中获取任何价值信息),但个人通过相同的电话号码或电子邮件地址连接这一问题,可能是一种风险。
下面在Python中进行一些处理:
设置数据、清理和创建图表
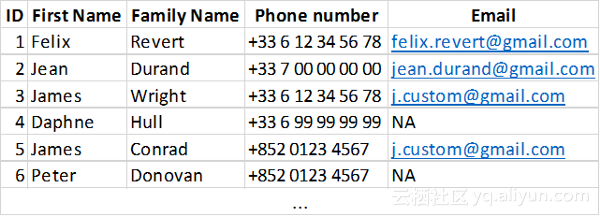
(构造的仿真数据)
首先从一个pandas DataFrame开始(它基本上是Python中的Excel表)
import pandas as pd
df = pd.DataFrame({'ID':[1,2,3,4,5,6],
'First Name':['Felix', 'Jean', 'James', 'Daphne', 'James', 'Peter'],
'Family Name': ['Revert', 'Durand', 'Wright', 'Hull', 'Conrad', 'Donovan'],
'Phone number': ['+33 6 12 34 56 78', '
+33 7 00 00 00 00', '+33 6 12 34 56 78', '+33 6 99 99 99 99', '+852 0123 4567', '+852 0123 4567'],
'Email': ['felix.revert@gmail.com',
'jean.durand@gmail.com', 'j.custom@gmail.com', pd.np.nan, 'j.custom@gmail.com', pd.np.nan]})
从代码中看到,先加载数据,以df表示。下面对其做一些准备,需要连接具有相同电话号码和相同电子邮件的个人(由其ID表示)。首先从电话号码开始:
column_edge = 'Phone number'
column_ID = 'ID'
data_to_merge = df[[column_ID, column_edge]].dropna(subset=[column_edge]).
drop_duplicates() # select columns, remove NaN
# To create connections between people who have the same number,
# join data with itself on the 'ID' column.
data_to_merge = data_to_merge.merge(
data_to_merge[[column_ID, column_edge]].rename(columns={column_ID:column_ID+"_2"}),
on=column_edge
处理的数据看起来像这样:
从图中看到,里面有一些联系,但存在两个问题:
- 个人与自己联系在一起
- 从数据中看到,当X与Y连接时,Y也与X连接,有两行数据用于同一连接。下面让我们清理一下:
# By joining the data with itself, people will have a connection with themselves.
# Remove self connections, to keep only connected people who are different.
d = data_to_merge[~(data_to_merge[column_ID]==data_to_merge[column_ID+"_2"])] \
.dropna()[[column_ID, column_ID+"_2", column_edge]]
# To avoid counting twice the connections (person 1 connected to person 2 and person 2 connected to person 1)
# we force the first ID to be "lower" then ID_2
d.drop(d.loc[d[column_ID+"_2"]<d[column_ID]].index.tolist(), inplace=True)
下面,数据看起来像这样:
从图中看到,1和3连接,5和6也连接。我们对电子邮件地址也进行同样的处理。下面构建一个图表,将在这里只分享代码的一部分,因为添加全部代码比较棘手,项目代码地址在文末给出。
import networkx as nx
G = nx.from_pandas_edgelist(df=d, source=column_ID, target=column_ID+'_2', edge_attr=column_edge)
G.add_nodes_from(nodes_for_adding=df.ID.tolist())
下面进行数据可视化
使用networkx进行图形可视化
简单的nx.draw(G)代码就能获得以下内容:
从图中看到,这是一个相当有趣的形式!但是我们看不出图中的每个点代表的是谁,谁和谁之间有什么连接。下面将其具体化:
从图中可以看到, 4个人通过2个不同的电话号码和1个电子邮件地址连接在一起,后续还应该进行更多的调查!
真正实现工业化的下一步
让我们回顾一下我们前面做过的事情:
- 根据用户数据库创建图表
- 自定义可视化,帮助我们发现潜在奇怪的模式
如果你是业务驱动的,并希望一些专家使用你已经完成的工作,那么你的下一个重点应该是: - 将查找多个人连接在一起的这一过程自动化,或风险模式检测
- 通过图形可视化和原始数据自动创建可视化和创建自定义仪表板的过程
本文不会在这里详细介绍上述内容,但是会告诉你如何继续进行上述两个步骤:
1.风险模式检测
这里有两种方法:
- 从你认为有风险的人(或你被发现为欺诈者的人)那里开始,检查他们与其他人的关系。这与机器学习相关,这是一种“有监督”方法。更进一步,你还可以从机器学习评分(例如,使用XGBoost)开始,寻找他们之间存在的紧密联系。
- 从奇怪的模式(太多的连接、密集的网络...),这是“无监督”的方法。
在我们举的例子中,我们没有已知的欺诈者,所以我们将采用上述的第二种方法。
Networkx已经实现了完全正确的算法:degree( )、centrality( )、pagerank( )、connected_components( )......这些算法可以让你以数学的形式定义风险。
2.为业务创建可视化和自动化分析
对于大多数数据科学家来说,这内容听起来是老派,但快速做到这一点的方法就是使用Excel。
Xlsxwriter软件包可帮助你粘贴风险人物图表中的数据,并将我们创建的图表图像直接粘贴到Excel文件中。通过这种操作之后你将获得每个风险网络的仪表板,如下所示:
对于每个具有潜在风险的网络,你都可以自动地创建仪表板,让专家完成他们的工作。同样你也可以在信息中心中添加一些指标:涉及的人数、不同电话号码的数量及电子邮件地址等。
全文源码在此,希望这篇文章对你有所帮助。
本文为云栖社区原创内容,未经允许不得转载。
0x00 介绍网络图是一种将复杂的网络数据结构化、可分析化和可视化的方法,一个典型的用途便是威胁狩猎、建模分析时对TCP/IP网络通信进行建模和分析。Brim的Python库beta版发布使得将Zeek和网络图融在一起变得前所未有的简单。0x01 预备知识Brim在本地工作站安装Brim来启动Jupyter。注:Windows、Linux和macOS版Brim的详细安装说明https:/...
“他山之石,可以攻玉”,站在巨人的肩膀才能看得更高,走得更远。在科研的道路上,更需借助东风才能更快前行。为此,我们特别搜集整理了一些实用的代码链接,数据集,软件,编程技巧等,开辟“他山之石”专栏,助你乘风破浪,一路奋勇向前,敬请关注。作者:知乎—wxj630地址:https://www.zhihu.com/people/wxj630知识图谱是数据科学中最迷人的概念之一学习如何构建知识图谱...
plt.figure(figsize=(480/my_dpi, 480/my_dpi), dpi=my_dpi)
df = pd.DataFrame({ 'from':['A', 'B', 'C','A'], 'to':['D', 'A', 'E','C']})
G=nx.from_pandas.
近期在某研究中,需要实现类似于百度地图的“智行”与滴滴打车的“公交车”功能,主要目的是将多种出行方式进行组合。这里面就涉及到了两个网络层,层间通过某些节点可以做到互通,而层内则可以全通。仔细想想,还是有些复杂的。于是一开始,我花了两天时间认认真真的写了算法:然后在开始动手撸代码的时候,才发现。。。买买提,原来Python上早有包可以做了。这个包就是做复杂网络的基础包——NETWOTKX。好了,直接...
学习过程中,运行时报错:
AttributeError: module 'networkx' has no attribute 'from_pandas_edgelist'
最终升级networkx包问题解决,代码改为:
G = nx.from_pandas_dataframe(edges, source='sources', target='targets', edge_attr='weights')
问题原因:版本问题,from_pandas_edgelist在新版本没了,没了!!!
NetworkX是一个用于研究图形和网络的Python库。 NetworkX是根据BSD-new许可证发布的免费软件。可用于创造和操作复杂网络,学习复杂网络的结构及其功能。有了NetworkX你就可以用标准或者不标准的数据格式加载或者存储网络,它可以产生许多种类的随机网络或经典网络,也可以分析网络结构,建立网络模型,设计新的网络算法,绘制网络。当然NetworkX单独存在不可能强大,这里春江暮客将...
NETWORK CHART(网络图)代码下载
网络图 (或图表或图形)显示了一组实体之间的互连。每个实体由一个或多个节点表示。节点之间的连接通过链接(或边)表示。网络的理论与实现是一个广阔的研究领域。整个网络都可以致力于此。例如,网络可以是有向的或无向的,加权的或未加权的。有许多不同的输入格式。为了指导您该领域,我建议按照建议的顺序执行以下示例。请注意关于该工具,我主要依靠NetworkX库(2....
1.使用第三方库networkx进行有向图与无向图的可视化在万物皆可嵌入一文中,我们介绍了从物品(item)生成序列,然后做word2vec的原理,并且提到了一些相关的算法——Deep W...
梅西(Lionel Messi)无需介绍,甚至不喜欢足球的人都听说过,最伟大的球员之一为这项运动增光添彩。这是他的维基百科页面:
那里有很多信息!我们有文本,大量的超链接,甚至还有音频剪辑。在一个页面上有很多相关且可能有...

