

C++17 特性 学习笔记

大部分编译器都完美支持C++17(C++1z)啦用起来xdm。
构造函数模板推导
结构化绑定
if-switch语句初始化
折叠表达式
constexpr lambda表达式
namespace嵌套
__has_include预处理表达式
在lambda表达式用*this捕获对象副本
新增Attribute
字符串转换
std::variant
std::optional
std::any
std::apply
std::make_from_tuple
as_const
std::string_view
file_system
std::shared_mutex
抛弃register
构造函数推导
以
tuple
为例,模板类的构造函数都需要显式指定模板类型才能进行构造,这是比较麻烦的。而这也是为什么
make_tuple
好用的原因(不用指定类型)。
---C++17前
std::tuple<int,int,string> t_iis(1,2,"123");
auto t_iis = make_tuple(1,2,string("123")); // 不是构造函数,可以自动推导模板
---C++17
tuple t_iis(1, 2, "123"); // 构造函数也能自己推导模板类型了
有了构造函数模板推导功能,我们可以写出以下代码:
---c++98
vector<int> vi; // 不爽
vi.push_back(1);
vi.push_back(2);
vi.push_back(3);
---c++11
vector<int> vi{1, 2, 3}; // 小爽
auto vi = vector<int>{1,2,3};
---C++17
vector vi{1,2,3}; // 很爽
auto vi=vector{1,2,3};
此外我们还很想要python中的zip功能与enumerate,其中参考 C++17实现的enumerate ,或者 这个 ,不得不说元编程是屠龙技啊...之后有空学一手。
此外看range这个库也有,甚至还有zip...
#include <range/v3/view/indices.hpp>
#include <range/v3/view/zip.hpp>
using namespace ranges;
std::vector<int> vec{42, 43, 44};
for (const auto& idxAndValue : view::zip(view::indices, vec))
std::cout << ideAndValue.first << " : " << idxAndValue.second << "\n";;
boost也有,果然大家都想要这个功能啊,直接用轮子就好了。
#include <boost/range/adaptor/indexed.hpp>
#include <boost/assign.hpp>
#include <iterator>
#include <iostream>
#include <vector>
int main(int argc, const char* argv[])
using namespace boost::assign;
using namespace boost::adaptors;
std::vector<int> input;
input += 10,20,30,40,50,60,70,80,90;
for (const auto& element : input | indexed(0))
std::cout << "Element = " << element.value()
<< " Index = " << element.index()
<< std::endl;
return 0;
结构化绑定
结构化绑定就是解包... 格式为
auto [v1,...,vn] = bag
。结构化绑定+函数返回tuple然后解包可以很容易实现多个返回值的函数,这在python是很常见的。
---python
a,b,s = (1,2,"123")
t = (a,b,s)
---c++11
std::tie(a, b, s) = [](){return make_tuple(1, 2, "123");}();
auto t = std::tie(a,b,s); // tuple<...> t
---C++17
auto find_person(int id) {
// do something
return tuple{22, 100, string{"oyjy"}};
int main() {
const auto &[age, score, name]=find_person(9);
python中的赋值语句可以 a,b,c = 1,2,3
用了C++17也可以实现类似功能,auto& [a, b, c] = tuple{1, 2.0, "123"};
可以解包的类型有:
- 数组类:C-array、std::array... (vector不行)
- 结构类:tuple、pair、struct...
---Carray、C++Array
int ai[]{1,2,3} or std::array vi{1, 2, 3};
auto[a, b, c]=ai;
for(auto && it:ai){cout<<a<<endl;}
---tuple、pair
auto item = pair{"oyjy", 22};
auto[name, age]=item;
---struct
//class Point{public: float x, y, z; } item{1, 2, 3}; // 必须public
struct Point{ float x, y, z; } item{1, 2, 3};
auto[x, y, z]=item;
在 遍历 字典(pair集合)和tuple集合时非常好用:
---python
dic = {'a': 1, 'b': 2}
for [key, val] in dic.items(): // 括号可加可不加
print(key, val)
---C++17
auto dic = map<string, int>{{"a", 1}, {"b", 2}};
for(auto&& [key,val]:dic){ // 括号必须加
cout<<key<<" "<<val<<endl;
结构体/类解包自定义
由于被解包的结构体/类成员必须全都声明为public才能解包。而一个类是不可能把所有成员都设置为public的,因为许多内部数据需要屏蔽用户如原始数据data。但是结构化绑定真是太香了,怎么办呢?结构化绑定也是调用
get<i>(data)
因此我们只需要实现这个接口就可以了
class Entry {
private:
std::string name_;
int age_;
template<size_t I>
friend auto get(const Entry &e);
template<size_t I>
auto get(const Entry &e) {
if constexpr (I == 0) return e.name_;
else if constexpr (I == 1) return e.age_;
namespace std {
template<> struct tuple_size<Entry> : integral_constant<size_t, 2> { };
template<> struct tuple_element<0, Entry> { using type = std::string; };
template<> struct tuple_element<1, Entry> { using type = int; };
int main() {
Entry e{"oyjy", 22};
auto[name, age] = e;
cout << name << " " << age << endl; // name 10
return 0;
注意:在检查tuple_size与绑定个数匹配后,自定义结构体首先尝试.get<i>(),再尝试
get<i>(data)
,如果不行就按聚合类型解包。而get的返回值需要注意:
- auto:返回值表达式(成员)是引用类型时会退化,返回非引用类型的纯右值。
- auto &:必须返回左值引用,返回得到的是引用类型左值。
- auto &&:万能引用类型,必须返回引用,自动推导出左值引用类型左值或将亡值。
- decltype(auto):自动推导返回值类型,根据表达式得到非引用或引用两种类型。
进阶
参考 ,其实结构化绑定编译器会帮我们转换为以前的样子:以Entry类为例
[cv] auto[[&]&] [a1,a2] = v;
==============================> 编译器转换为原始表达式如下:
[cv] auto[[&]&] temp = v; // 注意[cv] auto[[&]&]只用来修饰隐藏变量temp
// 拆分后的a1,a2是什么类型主要取决get 与 tuple_element_t
// 有 .get 与 tuple_size + tuple_element
tuple_element
<0, remove_reference(temp)>::type 万能引用 temp_a1 = temp.get<0>()//std::get<0>(temp)
... // n=tuple_size-1
tuple_element<n, remove_reference(temp)>::type 万能引用 temp_an = temp.get<n>()//std::get<n>(temp)
// decltype(auto) a1 = decltype(temp.get<0>()) a1 = temp.get<0>()
// 与auto的区别是能推断出cv & &&。
tuple_element_t<0, remove_reference_t<decltype(temp)>> cv xxx a1=temp.get<0>()
=> 等价于
decltype(auto) a1 = temp.get<0>(); // 具体是拷贝还是引用与 a1,a2的声明前无关
decltype(auto) a2 = temp.get<1>(); // 与函数get的返回值有关,详见前文
// 无 .get 且是聚合类型
[cv] temp.成员1的定义类型 + [[&]&] a1 = temp.成员1 // a1 就是成员1
if-switch语句初始化
C++17前if语句需要这样写代码:
---C
int a = GetValue();
if (a < 101) { cout << a; }
---C++98
if (int a = GetValue() < 101) { cout << a; }
---C++17
if (int a = GetValue()); a < 101) {
cout << a;
此外这样用更彰显优势
auto person(int id) {
// do something
return tuple{22, 100, string{"oyjy"}};
if (auto [age,score,name] = person(9); score > 101) {
cout << name << "is 22 ages and get"<< score << "score" << endl;
inline变量
说inline变量就先说说之前的inline函数。inline函数用来在函数使用处进行编译期内联展开而不是函数调用。进行内联展开可以减少函数调用的额外开销,这对高频率调用的函数是有必要优化的点,且相对于宏函数具有函数一样的类型检查等。
而
inline一般不进行实现分离
,而是与声明一起写在同一个文件内。这是因为每个
.cpp
源文件会在预处理期间将各自所包含的头文件展开,这样的话这个
inline函数
对于每个
.cpp
必须都是
可见的
,以便让编译器在调用点内联展开。由于每个
.cpp
生成对应的目标文件
.o
都是二进制文件了,但是其不一定可以执行(无main、或某些定义缺失),
当内联函数实现对当前
.cpp
不可见时
,预处理后只会有声明
inline ret func(arg)
而没定义,编译器仅知道
func
这个函数的声明,于是将其认为是
外部链接类型
(实现在其他.o文件),然后汇编只会生成一条
call 处理过C++格式名字的func
。这个call指令显然是错误的,因为本
.o
中并实现代码,这就是链接器的任务,目标文件与可执行文件一样,都有一个
符号导入表
与
符号导出表
来将所有的符号与他们的地址关联起来,于是连接器负责在其它的
.o
的符号导出表中寻找符号
func
的地址(没找到就提示经典的undefined reference),然后做一些偏移量处理(因为多个文件合并后地址肯定会与单独一个文件时不同)后加入当前
.o
的符号导入表中
func
的那一项,于是当前
.o
文件中对
func
的调用都会跳向同一个地址。因此此时内联函数是进行调转调用的而不是内联展开的。总结如下:
-
每个预处理过的源文件单独编译为
.o此时只检查符号是否定义否则报错error: ‘xxx’ was not declared in this scope。链接时对每个.o自身未定义的符号到其他.o寻找定义,否则报错对‘xxx’未定义的引用 -
当前源文件有
inline修饰函数的实现,则在调用点进行 内联展开 (内即本源文件内) -
无
inline修饰函数的实现,放入当前导入表。从别的.o导出表查询到而进行 跳转调用
内联变量
当我们分离实现的时候,只能在头文件中声明变量
extern int a
这样包含此头文件的源文件中就有此符号的声明就能单独编译过,然后在实现的源文件中有
int a=0
的定义,最终链接器就能正确在实现的目标文件中找到符号的真实地址。
若在头文件中定义
int a
或
int a=0
且该头文件被多个源文件引用,就会在链接时候报错
符号重定义
。虽然说可以通过
static int a=0
来实现多文件引用时不重定义,但如果是类静态成员变量就无法这样定义了,inline变量就可以实现静态成员变量既在头文件中定义是的用户可见其初始化状态,又不导致重定义的功能:
static int CLASS::si=0; // X 静态成员变量定义不能带static
inline int CLASS::si=0; // 既在头文件中定义是的用户可见其初始化状态,又不导致重定义
折叠表达式
将任意长的同形式代码
...
则叠起来缩短代码,更重要的是使可变参数模板编程更方便:其中
pack
表示一个表达式,
op
表示对表达式之间做的操作
+ - * / % ^ & | = < > << >> += -= *= /= %= ^= &= |= <<= >>= == != <= >= && || , .* ->*
而
init
表示一个初始常值。
-
(pack op ...): (E_1 op (... op (E_ {N-1} op E _N))) 单元右折叠 -
(... op pack): (((E_1 op E_2) op ...) op E_N) 单元左折叠 -
(pack op ... op init): (E_1 op (... op (E_{N−1} op (E_N op \quad I)))) 双元右折叠 -
(init op ... op pack): ((((I op E_1) op E_2) op ...) op E_N) 双元左折叠
注:在单元折叠中单输入时双元操作符与
空pack
运算,定义空包在以下运算时候的值为:
&&:true
、
||:false
、
,:void()
。
技巧:如果只是遍历每个元素,即只对元素做E运算(函数/表达式)而元素间无op,使用
op=,
template <typename ... Ts>
auto sum(Ts ... ts) {
return (ts + ...);
int a {sum(1, 2, 3, 4, 5)}; // 15
std
::string a{"hello "};
std::string b{"world"};
cout << sum(a, b) << endl; // hello world
#include <iostream>
#include <vector>
#include <climits>
#include <cstdint>
#include <type_traits>
#include <utility>
template<typename ...Args>
void printer(Args&&... args) {
(std::cout << ... << args) << '\n';
template<typename T, typename... Args>
void push_back_vec(std::vector<T>& v, Args&&... args)
static_assert((std::is_constructible_v<T, Args&&> && ...));
(v.push_back(std::forward<Args>(args)), ...);
// 编译期大小端转换,参考 http://stackoverflow.com/a/36937049
template<class T, std::size_t... N>
constexpr T bswap_impl(T i, std::index_sequence<N...>) {
return (((i >> N*CHAR_BIT & std::uint8_t(-1)) << (sizeof(T)-1-N)*CHAR_BIT) | ...);
template<class T, class U = std::make_unsigned_t<T>>
constexpr U bswap(T i) {
return bswap_impl<U>(i, std::make_index_sequence<sizeof(T)>{});
int main()
printer(1, 2, 3, "abc");
std::vector<int> v;
push_back_vec(v, 6, 2, 45, 12);
push_back_vec(v, 1, 2, 9);
for (int i : v) std::cout << i << ' ';
static_assert(bswap<std::uint16_t>(0x1234u)==0x3412u);
static_assert(bswap<std::uint64_t>(0x0123456789abcdefULL)==0xefcdab8967452301ULL);
库函数中很多模板实现都是折叠表达式+完美转发等操作组合实现的
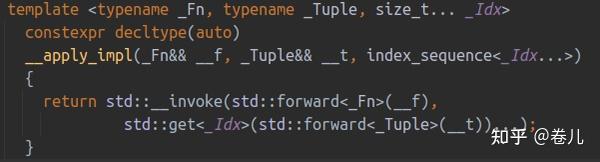
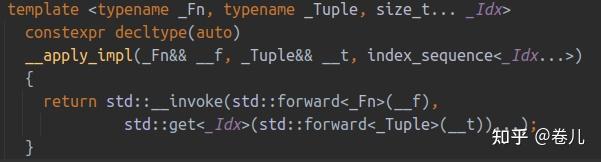
namespace嵌套
更简洁而已
namespace gazebo {
namespace physic {
void func();
---c++17,更方便更舒适
namespace gazebo::physic{
void func();)
lambda捕获对象副本
C++17后类成员函数内可以使用
[*this](...){...}
来设置lambda捕获对象的副本。由实验可见,此时调用了拷贝构造函数,且lambda内外成员变量属于两个不同的对象。
void print() &{
cout << "i'm fine " << endl;
[*this](){cout<<&data<<endl;}() ;
0x7ffe97a93884
0x7ffe97a93854
这在多线程中异步操作中可能用到,如返回一个值的时候其对象已经析构了而造成错误如下:
class Work
private:
int value;
public:
Work() : value(42) {}
std::future<int> spawn()
return std::async([=]() -> int { return value; });
std::future<int> foo()
Work tmp;
return tmp.spawn();
// The closure associated with the returned future
// has an implicit this pointer that is invalid.
int main()
std::future<int> f = foo();
f.wait();
// The following fails due to the
// originating class having been destroyed
assert(42 == f.get());
return 0;
字符串转换
std::variant
union的升级版?
std::optional
顾名思义就是表示这个变量可能是有效的也可以是无效的。在很多场合,我们的函数在正确的情况下返回正确值,而不正确的时候怎么处理呢?一般返回一个
"约定俗成"
的值,比如空指针、0、-1、单位矩阵等。这样会导致有的情况0是无效而有的时候-1是无效,这些不同的无效值在调用处进行判断时需要用到这些0,-1的魔鬼数字,可读性比较差。而且有时候返回一个对象,你也不知道怎么去定义一个无效值,而往往用传引用的方法来从输入参数返回,然后让函数返回值使用bool来表示是否有效,这使得一个函数的输入输出关系复杂了,可读性也不高
为了解决这个问题,神奇的C++引入了optional。它是一个模板类,内部通过保存
对象+bool
来表明对象的有效性。下面给出一个简单的例子:
std::optional<Foo> GetFoo() {
if (/*condition*/)
return Foo(1); // Foo(1):constructor -> move -> destroy
//return {1}; 却只有 constructor,看起来是被编译器返回值优化变成就地构造了?
return std::nullopt;
int main() {
auto f = GetFoo();
if (f)
cout<<f->data<<endl;
返回值为
nullopt
表示optional未初始化(用于表示无效状态),正确情况下直接返回被optional包装的变量就可以了会自己移动构造optional。此外optional类型可以隐式转换为boolean类型来表示当前
是否有效
。并且使用操作符
*
或
->
来进行取值,使用起来像指针。从例子看出,optional作返回值可以方便的处理上述问题,
且函数接口更简洁与明确
。
进阶看一下optional的构造: 其中
就地构造
性能最佳免去拷贝与移动构造的开销。
optional<Foo> op0; // 或者 optional<Foo> op0=nullopt;
optional op1{Foo(1)}; // C++17的模板类构造函数自动推导功能
auto op2 = make_optional(1); // 非常好用,自动推导变量与模板类型,有那味儿了
optional<Foo> op3{std::in_place, 1}; // 就地构造
其中第二构造方法有临时变量的
构造->移动->析构
,而第三四个是在op3内部
就地构造
无需先外部构造一个临时右值变量
然后移动到内部。 既然2行使用了optional的移动构造函数
optional(_Up&& __t)
,那为啥还需要呢
就地构造
呢? 因为有的变量需要使用默认构造函数:
optional op1{Foo()}; // 错,没法这样用默认构造函数
Foo f;
optional op{f}; // 显然需要外部构造左值,然后拷贝到optional内部。
或对象是无法移动和拷贝的(unique_ptr就不可拷贝但可移动,而std::mutex就是不可拷贝不可移动的),这时候就只能直接在内部构建。
optional op1 = make_optional<mutex>();
optional<mutex> op2(std::in_place);
optional<Foo> op3(std::in_place,1); // 调用 Foo(int a)
optional<Foo> op2(std::in_place,1,2); // 调用 Foo(int a, float b)
读取操作
读取方法比较多,此外还支持大小比较
< > ==
此时nullopt总是小于所有有效值:
*op; // 返回内部存储对象的引用
op->xx // 返回内部存储对象的指针
op.value() // op为空时抛出std::bad_optional_access
op.value_or(obj) // op非空时得到内部存储值,op为空时返回默认值作为函数返回值时的细节:强制拷贝
我们知道返回值的值类别根据返回值类型不同而不同,左值引用返回值返回左值,其余返回右值(prvalue+xvalue)。
auto a=func()
根据返回值类别是左值还是右值的不同选择copy或是move。但是C++17有一个强制拷贝规则,即如果返回
{返回值}
则表示使用拷贝。下面以不可拷贝但可移动的类unique_ptr举例。
std::unique_ptr<double> nonCopyableReturn()
std::unique_ptr<double> p = nullptr;
return {p}; //强制产生拷贝,将产生编译错误,因为unique_ptr为non-copyable类型
// return p; //move语义,unique_ptr可以move,编译通过。
std::any
一个可以存储任何类型东西的玩意儿,大佬们说是类型安全的
void*
emm想想也是哈。
---python
a=1, print(a)
a=1.0, print(a)
a="1", print(a)
a=string("1"), print(a)
a={"n":1}, print(a)
---C++17 #include <any>
std::any a;
a = 1; cout << std::any_cast<int>(a) << endl;
a = 1.0; cout << std::any_cast<double>(a) << endl;
a = "1"; cout << std::any_cast<const char *>( a) << endl;
a = make_pair("n", 1); cout << any_cast<pair<const char *, int>>(a).first << endl;
--- 此外还有一些构建方法
std::any a{std::in_place_type<string>,"1"};
std::any a = make_any<Foo>(1,2); // 比上面那个方便,也是就地构造
a.emplace<Foo>(1,2); // 就地分配值,而不是像 a = Foo(1)一样移动或拷贝
这个any阿它同时包含了:
数值
与
typeid来表示值的类型
。
-
std::any_cast<T>(a)读取any的当前值,转换失败会抛出std::bad_any_cast。而使用std::any_cast<T&>(a)可以避免拷贝 -
a.reset()清空当前值 -
a.has_value()检查当前any中是否有值,这里注意值是按类型衰减存储的(数组变指针,忽略CV+引用) -
a.type()返回当前any内部存储的值的类型的typeid,可以用于比较a.type==typeid(int)
any可以放入容器
vector<any> va;
va.emplace_back(1);
cout<<va[0].type().name()<<endl; // i
va.emplace_back(Foo(1));
cout<<va[1].type().name()<<endl; // 3Foo
std::apply
就是把
tuple
元素解包作为函数输入
apply function on tuple
之意?
auto f = [](auto &&a, auto &&b) { return a + b };
std::cout << std::apply(f, std::make_tuple(1.0, 2.0)) << endl;
make_from_tuple
还有这种玩意儿...将构造函数的参数包装成tuple然后调用构造函数来构造对象。我也没想到这样做有啥用目前。可能是将参数收集起来,然后等需要的时候再延迟构造???或者说方便构造参数。
struct Foo {
Foo(int first, float second, int third) {
std::cout << first << ", " << second << ", " << third << "\n";
int main() {
auto tuple = std::make_tuple(42, 3.14f, 0);
std::make_from_tuple<Foo>(std::move(tuple));
as_const
std::string_view
通常我们传递一个string时会触发对象的拷贝操作,大字符串的拷贝赋值操作会触发堆内存分配,很影响运行效率。有了string_view就可以避免拷贝操作,平时传递过程中传递string_view即可。用string_view为string创建视图,在只观察字符串的时候比较高效。
void func(std::string_view stv) { cout << stv << endl; }
int main(void) {
std::string str = "Hello World";
std::cout << str << std::endl;
std::string_view stv(str.c_str(), str.size());
cout << stv << endl;
func(stv);
return 0;