

使用Apache Hudi + Amazon S3 + AWS DMS构建数据湖

欢迎关注微信公众号:ApacheHudi
1. 引入
数据湖使组织能够在更短的时间内利用多个源的数据,而不同角色用户可以以不同的方式协作和分析数据,从而实现更好、更快的决策。Amazon Simple Storage Service(amazon S3)是针对结构化和非结构化数据的高性能对象存储服务,可以用来作为数据湖底层的存储服务。
然而许多用例,如从上游关系数据库执行变更数据捕获(CDC)到基于Amazon S3的数据湖,都需要在记录级别处理数据,执行诸如从数据集中插入、更新和删除单条记录的操作需要处理引擎读取所有对象(文件),进行更改,并将整个数据集重写为新文件。此外为使数据湖中的数据以近乎实时的方式被访问,通常会导致数据被分割成许多小文件,从而导致查询性能较差。Apache Hudi是一个开源的数据管理框架,它使您能够在Amazon S3 数据湖中以记录级别管理数据,从而简化了CDC管道的构建,并使流数据摄取变得高效,Hudi管理的数据集使用开放存储格式存储在Amazon S3中,通过与Presto、Apache Hive、Apache Spark和AWS Glue数据目录的集成,您可以使用熟悉的工具近乎实时地访问更新的数据。Amazon EMR已经内置Hudi,在部署EMR集群时选择Spark、Hive或Presto时自动安装Hudi。
本篇文章将展示如何构建一个CDC管道,该管道使用AWS数据库迁移服务(AWS DMS)从Amazon关系数据库服务(Amazon RDS)for MySQL数据库中捕获数据,并将这些更改应用到Amazon S3中的一个数据集上。Apache Hudi包含了HoodieDeltaStreamer实用程序,它提供了一种从许多源(如分布式文件系统DFS或Kafka)摄取数据的简单方法,它可以自己管理检查点、回滚和恢复,因此不需要跟踪从源读取和处理了哪些数据,这使得使用更改数据变得很容易,同时还可以在接收数据时对数据进行基于SQL的轻量级转换,有关详细信息,请参见 写Hudi表 。ApacheHudi版本0.5.2提供了对带有HoodieDeltaStreamer的AWS DMS支持,并在Amazon EMR 5.30.x和6.1.0上可用。
2. 架构
下图展示了构建CDC管道而部署的体系结构。
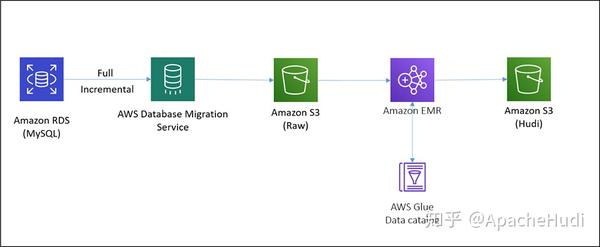
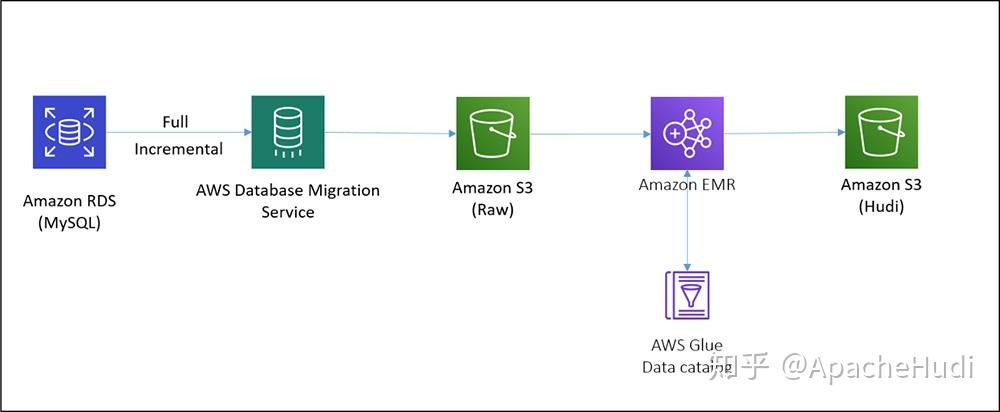
在该架构中,我们在Amazon RDS上有一个MySQL实例,AWS-DMS将完整的增量数据(使用AWS-DMS的CDC特性)以Parquet格式存入S3中,EMR集群上的HoodieDeltaStreamer用于处理全量和增量数据,以创建Hudi数据集,当更新MySQL数据库中的数据后,AWS-DMS任务将获取这些更改并将它们变更到原始的S3存储桶中。HoodieDeltastreamer作业可以在EMR集群上以特定的频率或连续模式运行,以将这些更改应用于Amazon S3数据湖中的Hudi数据集,然后可以使用SparkSQL、Presto、运行在EMR集群上的Apache Hive和Amazon Athena等工具查询这些数据。
3. 部署解决方案资源
使用AWS CloudFormation在AWS帐户中部署这些组件,选择一个AWS区域部署以下服务:
- Amazon EMR
- AWS DMS
- Amazon S3
- Amazon RDS
- AWS Glue
- AWS Systems Manager
在部署CloudFormation模板之前需要先满足如下条件:
- 拥有一个至少有两个公共子网的专有网络(VPC)。
- 有一个S3存储桶来从EMR集群收集日志,需要在同一个AWS区域。
-
具有AWS身份和访问管理(IAM)角色DMS VPC角色
dms-vpc-role。 - 如果要使用AWS Lake Formation权限模型在帐户中部署,请验证以下设置:
- 用于部署技术栈的IAM用户需要被添加为Lake Formation下的data lake administrator,或者用于部署堆栈的IAM用户具有在AWS Glue data Catalog中创建数据库的IAM权限。
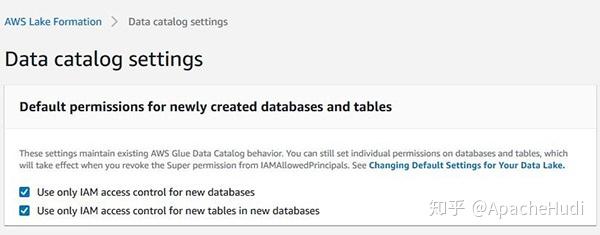
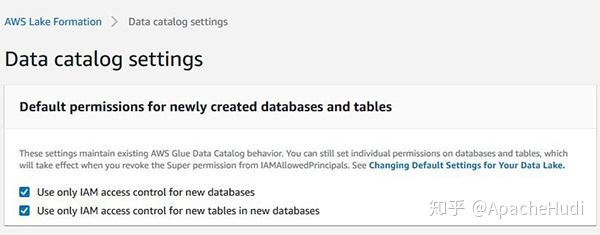
- Lake Formation下的数据目录(Data Catalog)设置配置为仅对新数据库和新数据库中的新表使用IAM访问控制,这将确保仅使用IAM权限控制对数据目录(Data Catalog)中新创建的数据库和表的所有访问权限。
-
IAMAllowedPrincipals在Lake Formation database creators页面上被授予数据库创建者权限。


如果此权限不存在,请通过选择
授予
并选择授予
创建数据库
权限。
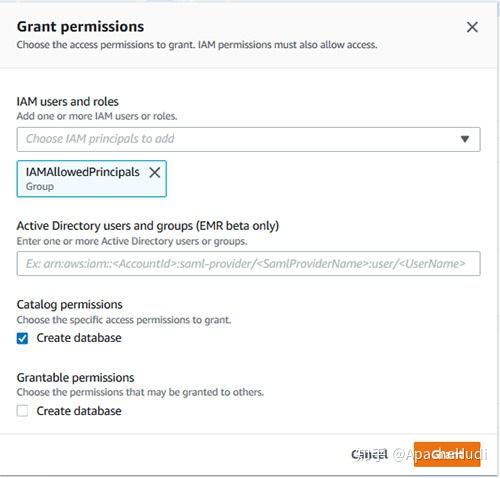
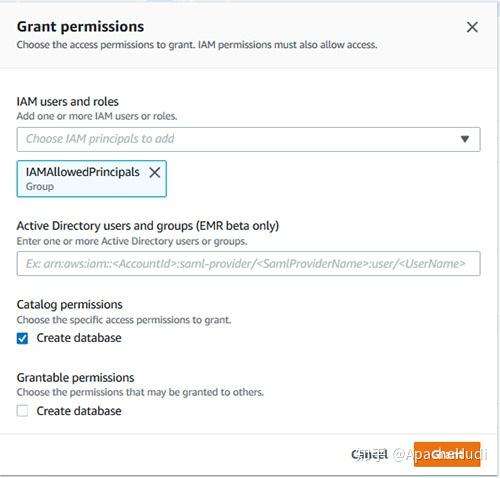
这些设置是必需的,以便仅使用IAM控制对数据目录对象的所有权限。
4. 启动CloudFormation
要启动CloudFormation栈,请完成以下步骤
-
选择启动CloudFormation栈
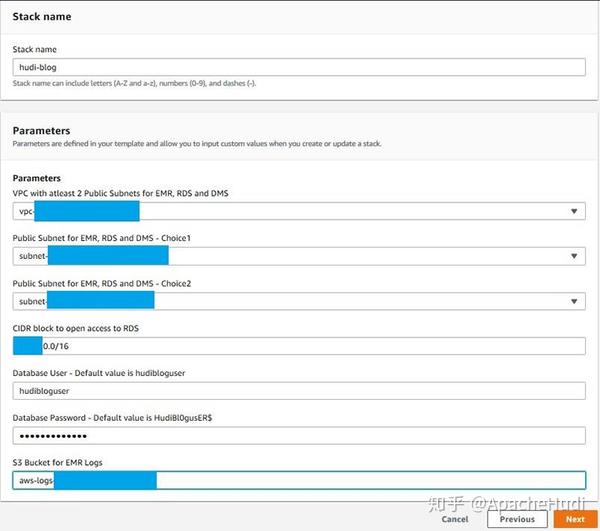
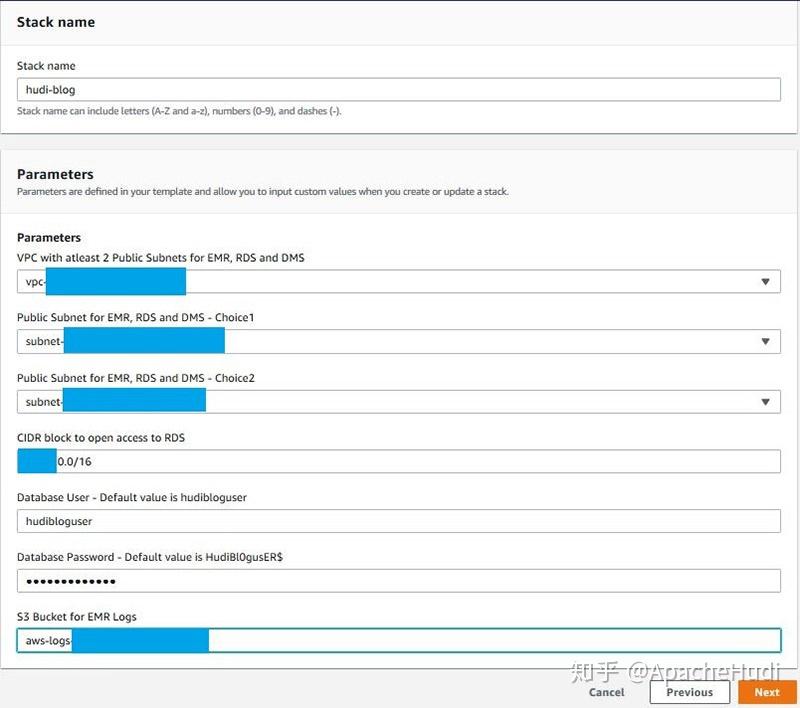
-
在Parameters部分提供必需的参数,包括一个用于存储Amazon EMR日志的S3 Bucket和一个您想要访问Amazon RDS for MySQL的CIDR IP范围。
-
遵循CloudFormation创建向导,保持其余默认值不变。
-
在最后一个页面上,选择允许AWS CloudFormation可能会使用自定义名称创建IAM资源。
-
选择
创建。
-
当创建完成后,在CloudFormation堆栈的Outputs选项卡上记录S3 Bucket、EMR集群和Amazon RDS for MySQL的详细信息。
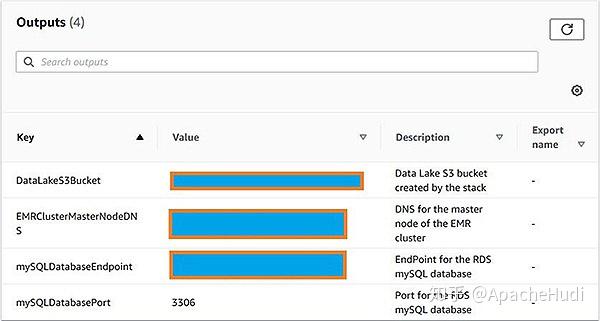
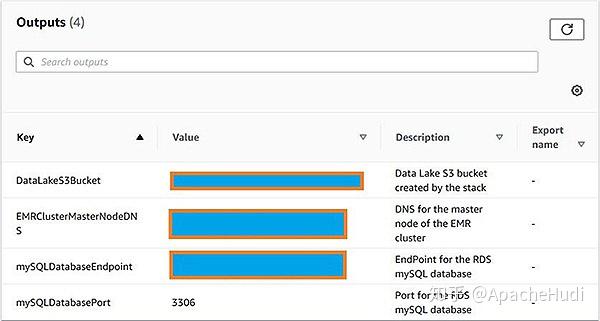
CloudFormation模板为EMR集群使用m5.xlarge和m5.2xlarge实例,如果这些实例类型在你选择用于部署的区域或可用性区域中不可用,那么CloudFormation将会创建失败。如果发生这种情况,请选择实例类型可用的区域或子网。
CloudFormation还使用必要的连接属性(如
dataFormat
、
timestampColumnName
和
parquetTimestampInMillisecond
)创建和配置AWS DMS端点和任务。
作为CloudFormation栈的一部分部署的数据库实例已经被创建,其中包含AWS-DMS在数据库的CDC模式下工作所需的设置。
-
binlog_format=ROW -
binlog_checksum=NONE
另外在RDS DB实例上启用自动备份,这是AWS-DMS进行CDC所必需的属性。
5. 运行端到端数据流
CloudFormation部署好后就可以运行数据流,将MySQL中的完整和增量数据放入数据湖中的Hudi数据集。
- 作为最佳实践,请将binlog保留至少24小时。使用SQL客户端登录Amazon RDS for MySQL数据库并运行以下命令:
call mysql.rds_set_configuration('binlog retention hours', 24)- 在dev数据库中创建表:
create table dev.retail_transactions(
tran_id INT,
tran_date DATE,
store_id INT,
store_city varchar(50),
store_state char(2),
item_code varchar(50),
quantity INT,
total FLOAT);- 创建表时,将一些测试数据插入数据库:
insert into dev.retail_transactions values(1,'2019-03-17',1,'CHICAGO','IL','XXXXXX',5,106.25);
insert into dev.retail_transactions values(2,'2019-03-16',2,'NEW YORK','NY','XXXXXX',6,116.25);
insert into dev.retail_transactions values(3,'2019-03-15',3,'SPRINGFIELD','IL','XXXXXX',7,126.25);
insert into dev.retail_transactions values(4,'2019-03-17',4,'SAN FRANCISCO','CA','XXXXXX',8,136.25);
insert into dev.retail_transactions values(5,'2019-03-11',1,'CHICAGO','IL','XXXXXX',9,146.25);
insert into dev.retail_transactions values(6,'2019-03-18',1,'CHICAGO','IL','XXXXXX',10,156.25);
insert into dev.retail_transactions values(7,'2019-03-14',2,'NEW YORK','NY','XXXXXX',11,166.25);
insert into dev.retail_transactions values(8,'2019-03-11',1,'CHICAGO','IL','XXXXXX',12,176.25);
insert into dev.retail_transactions values(9,'2019-03-10',4,'SAN FRANCISCO','CA','XXXXXX',13,186.25);
insert into dev.retail_transactions values(10,'2019-03-13',1,'CHICAGO','IL','XXXXXX',14,196.25);
insert into dev.retail_transactions values(11,'2019-03-14',5,'CHICAGO','IL','XXXXXX',15,106.25);
insert into dev.retail_transactions values(12,'2019-03-15',6,'CHICAGO','IL','XXXXXX',16,116.25);
insert into dev.retail_transactions values(13,'2019-03-16',7,'CHICAGO','IL','XXXXXX',17,126.25);
insert into dev.retail_transactions values(14,'2019-03-16',7,'CHICAGO','IL','XXXXXX',17,126.25);现在使用AWS DMS将这些数据推送到Amazon S3。
- 在AWS DMS控制台上,运行hudiblogload任务。
此任务将表的全量数据加载到Amazon S3,然后开始写增量数据。


如果第一次启动AWS-DMS任务时系统提示测试AWS-DMS端点,那么可以先进行测试,在第一次启动AWS-DMS任务之前测试源和目标端点通常是一个好的实践。
几分钟后,任务的状态将变更为"加载完成"、"复制正在进行",这意味着已完成全量加载,并且正在进行的复制已开始,可以转到由CloudFormation创建的S3 Bucket,应该会在S3 Bucket的dmsdata/dev/retail_transactions文件夹下看到一个.parquet文件。
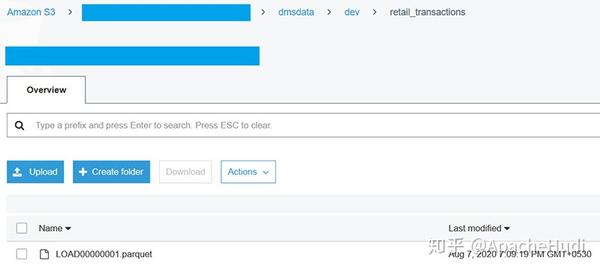
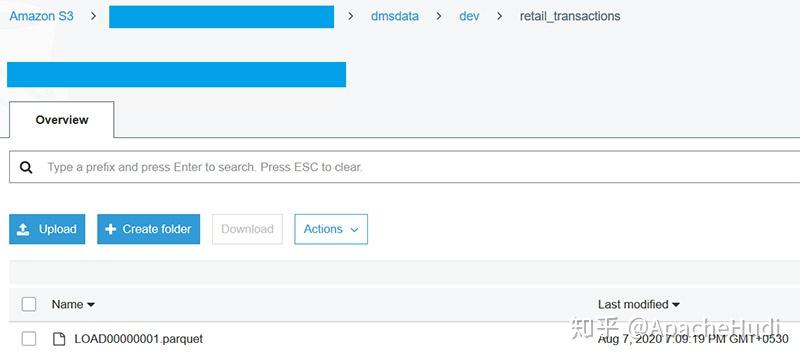
-
在EMR集群的Hardware选项卡上,选择主实例组并记录主实例的EC2实例ID。
-
在Systems Manager控制台上,选择会话管理器。
-
选择"启动会话"以启动与群集主节点的会话。
-
通过运行以下命令将用户切换到Hadoop
sql sudo su hadoop
在实际用例中,AWS DMS任务在全量加载完成后开始向相同的Amazon S3位置写入增量文件,区分全量加载和增量加载文件的方法是,完全加载文件的名称以load开头,而CDC文件名具有日期时间戳,如在后面步骤所示。从处理的角度来看,我们希望将全部负载处理到Hudi数据集中,然后开始增量数据处理。为此,我们将满载文件移动到同一S3存储桶下的另一个S3文件夹中,并在开始处理增量文件之前处理这些文件。
- 在EMR集群的主节点上运行以下命令(将<s3-bucket-name>替换为实际的bucket name):
sql aws s3 mv s3://<s3-bucket-name>/dmsdata/dev/retail_transactions/ s3://<s3-bucket-name>/dmsdata/data-full/dev/retail_transactions/ --exclude "*" --include "LOAD*.parquet" --recursive
有了datafull文件夹中的全量表转储,接着使用EMR集群上的HoodieDeltaStreamer实用程序来向Amazon S3上写入Hudi数据集。
- 运行以下命令将Hudi数据集填充到同一个S3 bucket中的Hudi文件夹中(将<S3 bucket name>替换为CloudFormation创建的S3 bucket的名称):
spark-submit --class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer \
--packages org.apache.hudi:hudi-utilities-bundle_2.11:0.5.2-incubating,org.apache.spark:spark-avro_2.11:2.4.5 \
--master yarn --deploy-mode cluster \
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer \
--conf spark.sql.hive.convertMetastoreParquet=false \
/usr/lib/hudi/hudi-utilities-bundle_2.11-0.5.2-incubating.jar \
--table-type COPY_ON_WRITE \
--source-ordering-field dms_received_ts \
--props s3://<s3-bucket-name>/properties/dfs-source-retail-transactions-full.properties \
--source-class org.apache.hudi.utilities.sources.ParquetDFSSource \
--target-base-path s3://<s3-bucket-name>/hudi/retail_transactions --target-table hudiblogdb.retail_transactions \