


类型检查:时常被忽略的编译器组件

原文来自微信公众号“编程语言Lab”: 类型检查:时常被忽略的编译器组件
搜索关注“编程语言Lab”公众号(HW-PLLab)获取更多技术内容!
欢迎加入 编程语言社区 SIG-类型系统 参与交流讨论(加入方式:添加小助手微信 pl_lab_001 ,备注“加入SIG-类型系统”)。
分享嘉宾 | 朱子润
回顾整理 | Hana
视频回顾
编程语言技术沙龙|第 17 期: 类型检查:时常被忽略的编译器组件
大家好,我是朱子润,很高兴为大家带来一个比较简单的类型检查与推导的分享。
这个分享的目标群体是对程序语言理论和类型检查感兴趣的工程师,所以内容以直觉为主,理论为辅。本次分享主要内容分为四个部分:
- 从日常的编码场景来说一下类型检查和类型推导的作用
- 概念上如何实现一个简单的类型检查与推导器(我将用 TC 和 TI 作为类型检查与推导的简写)
- 学界是如何严格定义类型检查与推导的
- 探讨学界和工业界对其的侧重点
相关阅读
# 类型检查 & 类型推导 #
# 什么是类型检查?
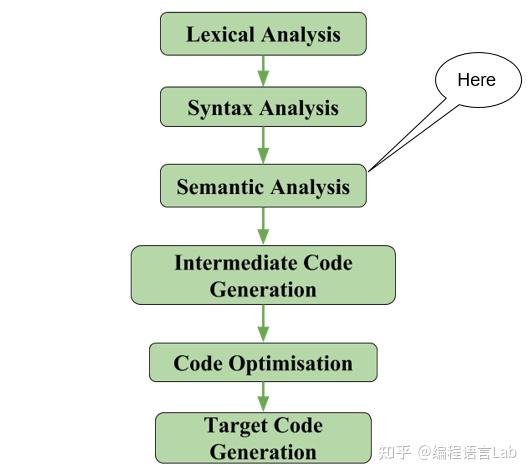
在介绍类型检查 (type check) 前,我们先看一个编译流程图,如下图示,输入的程序会依次进行词法分析、语法分析、语义分析、中间代码生成、代码优化、目标代码生成。 类型检查其实就被涵盖在语义分析中 (即 semantic analysis)。
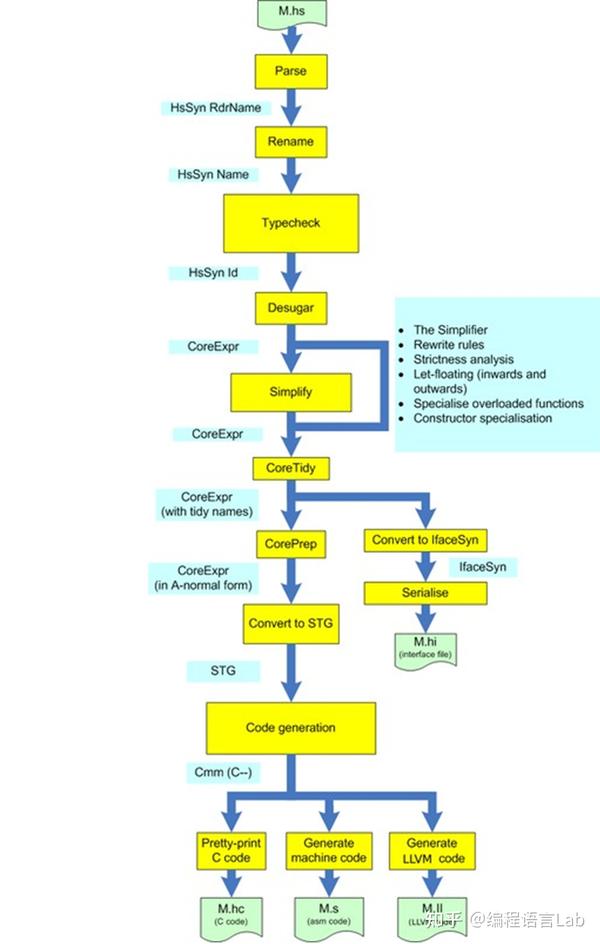
如果我们看一个函数式语言的架构图,比如 Haskell,它可能会明确地标出在解析 parse 与 rename 之后,会有一个类型检查 type check 的阶段,在此之后还有些其他比较复杂的工作比如后端代码生成。
那么,类型检查是怎样的语义分析呢?
顾名思义,类型检查的主要作用就是 找到程序中的类型错误 。我们来看两种简单而又典型的类型错误: 不兼容的赋值 incompatible assignment 与 不兼容的函数调用 incompatible function calls 。
- 不兼容的赋值:比如当我们在声明一个变量后,给其赋一个类型不兼容的值(一个声明为布尔类型的变量被赋一个整数的值)。
- 不兼容的函数调用:比如在函数调用时,形参与实参的类型不匹配。
如下是一个 C++ 中比较典型的例子。变量
x
的类型是
Char
,给
x
赋值了一个字符串
"abc"
,就会出现一个 warning,原因就是赋值时类型不兼容。


下图 Java 的例子中,我们
switch
了一个布尔值
true
,编译器会报错:
switch
接受一个整数值,不能用布尔值,即类型不兼容。


还有一类情况,如下 Swift 的代码示例中,我们声明了两个类
C
和
D
,然后声明一个变量
x
并用一个三元表达式来初始化,三元表达式的两个分支分别创建了
C
和
D
的实例。这里编译器也会报错,说
C
和
D
类型不匹配,mismatching。这是因为编译器无法找到
C
和
D
的公共父类型,即编译器尝试将
C
和
D
的所有父类找出来,发现它们没有交集,所以说没有公共父类型。(不过这样一类问题其实是通过类型推导发现的。)


而如果
D
继承
C
,那它们的公共父类型就变成
C
了,这个错误也就消除了。


前三个例子的对比如下。


# 什么是类型推导?
在第一部分,我们简单介绍了类型检查,最后引出了一点儿类型推导 (type inference):类型推导找类型错误的方法是去看程序片段 能否有一个类型 ,这个类型不是事先标注好的。
除此之外,类型推导更大的好处是 可以让程序编码更加地高效 。比如类型推导可以省掉大量无聊的类型注解 type annotations,让程序员可以聚焦在代码的业务逻辑上;比如类型推导还可以友好地掩盖掉像泛型 generics 或者多态 polymorphisms 这样的类型复杂性。
如下所示的函数调用中,尖括号里很长的部分是一个泛型参数,如果有类型推导的话,那我们可以省略掉这一长串内容,直接写成
f(m)
,程序员无需理解背后的理论,可以轻松地使用多态函数,掩盖一些复杂度。
f<HashMap<User, List<String>>>(m)
f(m)分别以 C++,Java,Swift 为例,对比一下在没有类型推导和有类型推导的情况下,我们写的代码。
C++:


Java:


Swift:


借住类型推导,三个例子的对比如下。


接下来,我们看一下如何简单地实现类型检查与推导 TC & TI,这部分也是本次分享的干货。
# 编写一个类型检查器 #
# 递归下降
类型检查器 type checker 一般是
递归下降
(recursive and descent) 的,(个人认为只有骨骼清奇的人才才能写出自底向上的版本),我们定义一个函数
Check : (AST, Type) -> Bool
。这个函数接受两个参数,第一个参数是抽象语法树 AST,即要检查的语法树节点,第二个参数是目标类型。函数返回一个布尔值,用于告诉我们检查的节点是否有给定的目标类型。
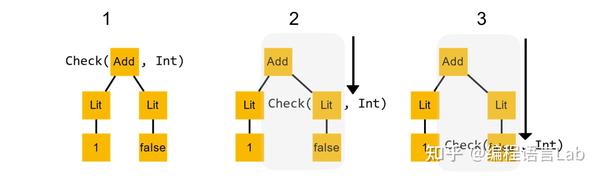
用简单的例子来说明,假设我要检查这样一棵语法树(如下图所示),看它是不是
Int
类型。这棵树很简单,是一个加法,有左右两个分支,左边是
1
,右边是
false
。按照递归下降,我们先递归检查左子树,往下走一步,看 Lit 节点有没有
Int
类型,然后再递归往下走,看
1
有没有
Int
类型。

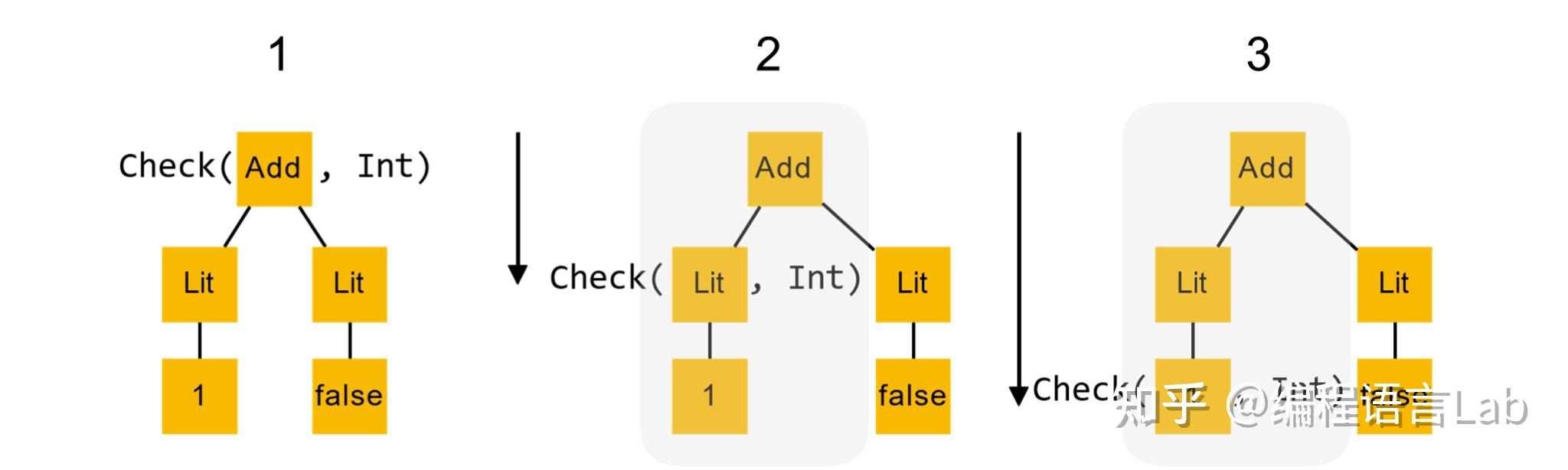
此时,类型检查返回的结果是
true
:即
1
有
Int
类型,那么这个返回结果就可以向上传递直至顶层。那么我们对于左子树的检查就完成了,它返回
true
。

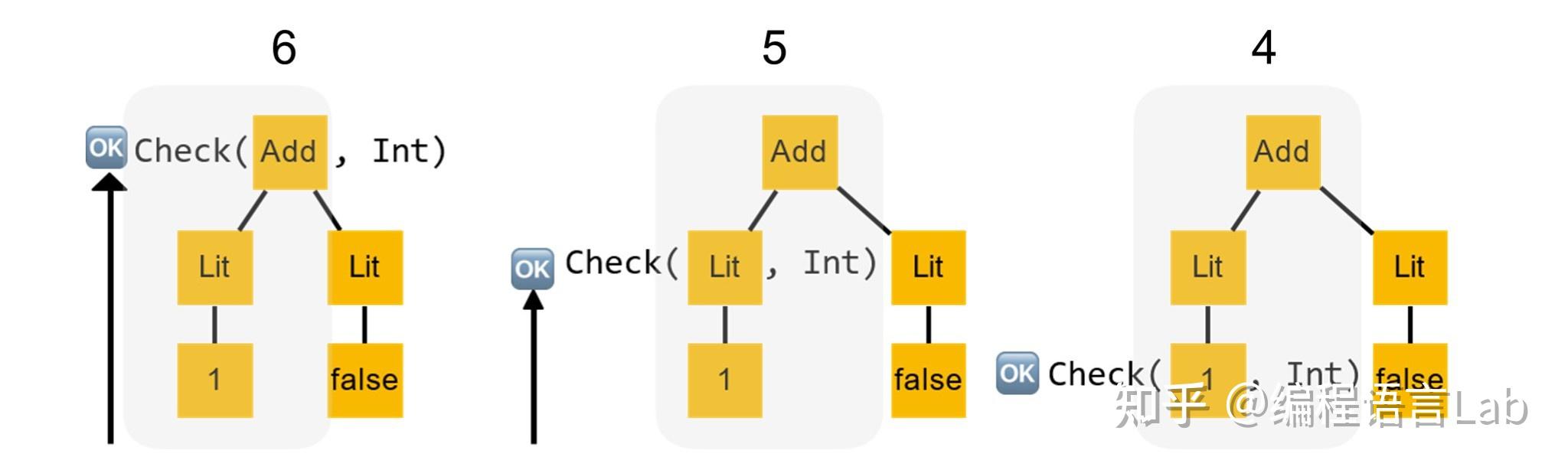
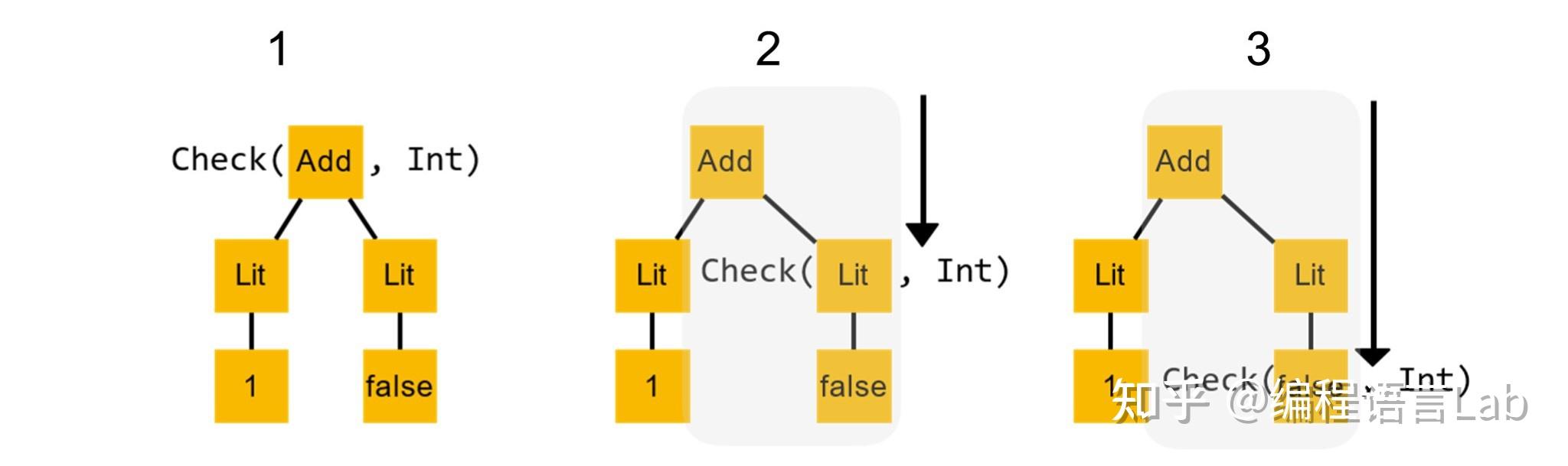
接下来,同样按照递归下降的方式检查右子树,直到最后检查
false
是否是
Int
类型,(鉴于一般语言是不允许的,因此) 结果返回
false
。我们将这个返回结果向上传递至顶层。
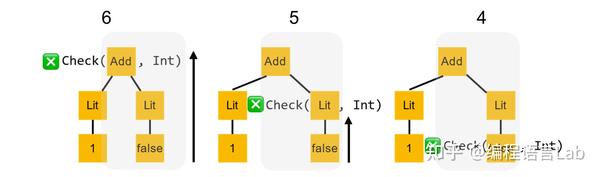
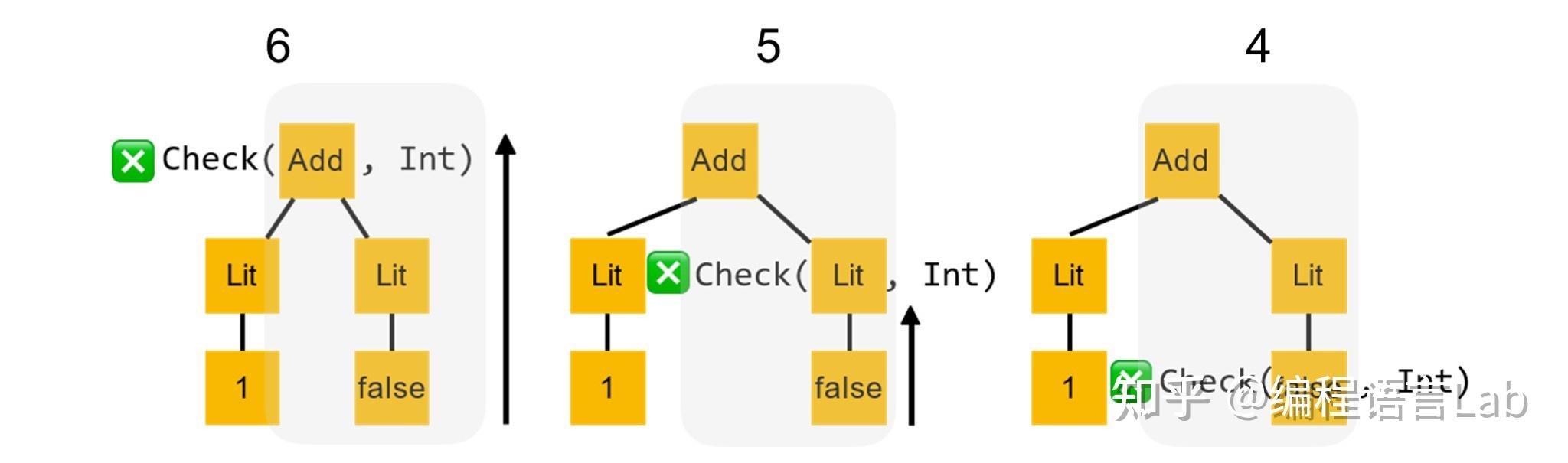
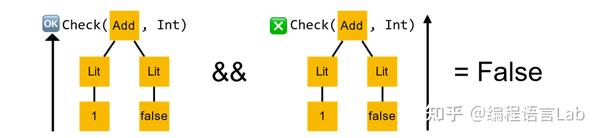
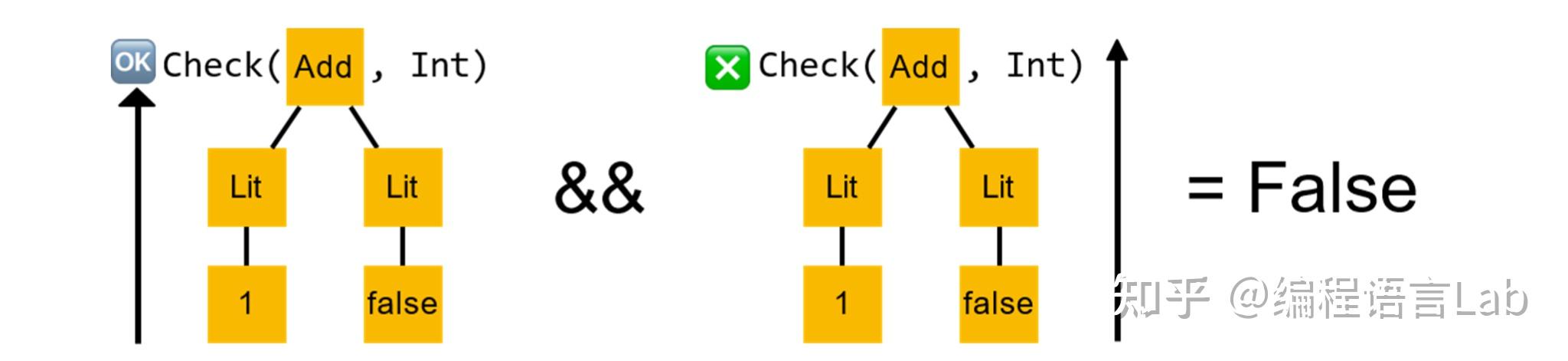
此时左子树的返回结果
true
与右子树的返回结果
false
做一个逻辑与的操作,得到最终的检查结果为
false
,即对这棵语法树的类型检查会失败。
# 伪代码示例
接下来我们用伪代码来解释一下如何实现 (这部分代码会比较像 Haskell)。
说明:
a <: b
表示
a
是
b
的一个子类型 subtype。
首先,编写
Check
的类型。
Check
有两个参数:语法树
ast
和目标类型
ty
。我们给
ast
做模式匹配。
Check : (AST, Type) -> Bool
Check (ast, ty) = case ast of pattern match加法类型检查
我们以上一节的加法场景为例,将加法的左右子树分别绑定到新的变量
l
和
r
,分别递归检查左子树和右子树,检查的目标类型仍然是
ty
。最后将两边子树的检查结果用逻辑与
&&
连接起来,
Check (ast, ty) =
Add(l,r) ---> Check(l, ty) && Check (r, ty)字面值类型检查
在刚才的例子中,我们遇到了字面量,那么我们可以检查字面量的类型是否是目标类型的子类型,
Check (ast, ty) = case ast of pattern match
Lit(n) ---> typeOf(n) <: ty函数定义类型检查
接下来,我们介绍两类比较有意思的情况,即函数定义和函数调用的类型检查。先来看函数定义。如果我们的语法树是一个函数定义的节点,那么我们可以分别将函数名、函数参数、函数体分别绑定到
f
,
param
,
body
上,
Check (ast, ty) =
-- function definitions
FunAbs(f, param, body) --->
接下来我们来做检查。因为我们在做函数定义时,形参名
pName
后会跟形参类型
pTy
,即
fun(pName : pTy)
。因此,我们可以进一步用模式匹配将形参节点解构为声明处的名字和类型。
这里我们使用
let
来做模式匹配,将
param
解构成
Param(pName, pTy)
(即程序片段
fun(pName : pTy
对应的 AST),
Check (ast, ty) =
-- function definitions
FunAbs(f, param, body) --->
-- pattern match fun(pName : pTy)
let Param(pName, pTy) = param第二步,我们将输入的目标类型也通过模式匹配来解构:这个目标类型一定要是一个函数类型才可以,否则报错 (这里的伪代码仅做示意,因此省略掉报错的环节了哈)。那么,函数类型可以解构为参数类型和返回类型。
因此,使用
let
来做模式匹配,将目标类型
ty
中解构出来的参数类型绑定到
parTy
,返回类型绑定到
retTy
,
Check (ast, ty) =
-- function definitions
FunAbs(f, param, body) --->
-- pattern match fun(pName : pTy)
let Param(pName, pTy) = param
let FunTy(parTy, retTy) = ty
基于前述步骤解构出来的数据,我们可以用目标类型解构出的返回类型
retTy
来与函数体的类型
body
做检查,递归地检查函数体是否是
retTy
的子类型。此外,我们还需要检查函数声明处的形参类型
pTy
,与目标类型解构出来的形参类型
parTy
是否形成了有效的子类型关系 (后面会展开解释什么是有效的子类型关系)。
Check (ast, ty) =
-- function definitions
FunAbs(f, param, body) --->
-- pattern match fun(pName : pTy)
let Param(pName, pTy) = param
let FunTy(parTy, retTy) = ty
parTy <: pTy && Check(body, retTy) -- allow subtyping函数调用类型检查
接下来我们来看函数调用的检查。我们需要传入被调用的函数
f
和传给函数的参数
arg
。在此之前该函数已经被定义了,因此可以用
typeOf(f)
获得定义的函数类型,包括形参类型
parTy
和返回类型
retTy
。
Check (ast, ty) = case ast of pattern match
-- function invocations
FunApp(f, arg) --->
let FuncTy(parTy, retTy) = typeOf(f)
我们要检查的是函数调用时的实参
arg
是否满足定义处的形参类型
parTy
。以及函数定义处的返回类型
retTy
是否满足传入的目标返回类型
ty
。
Check (ast, ty) = case ast of pattern match
-- function invocations
FunApp(f, arg) --->
let FuncTy(parTy, retTy) = typeOf(f)
Check(arg, parTy) && retTy <: ty
以上就是几个简单常见的类型检查例子,伪代码示意如下。要进一步说明的是,“是否满足子类型关系”在函数相关的类型检查中是比较特殊的。在检查返回类型时,我们需要判断是否满足协变 co-variance,即
retTy <: ty
;而在检查入参类型时,需要判断是否满足逆变 contra-variance,即
parTy <: pTy
。
Check : (AST, Type) -> Bool
Check (ast, ty) = case ast of pattern match
Add(l,r) ---> Check(l, ty) && Check (r, ty)
Lit(n) ---> typeOf(n) <: ty
-- function definitions
FunAbs(f, param, body) --->
-- pattern match fun(pName : pTy)
let Param(pName, pTy) = param
let FunTy(parTy, retTy) = ty
parTy <: pTy && Check(body, retTy) -- allow subtyping
-- function invocations
FunApp(f, arg) --->
let FuncTy(parTy, retTy)
= typeOf(f)
Check(arg, parTy) && retTy <: ty类型检查的环境
为了简化伪代码,我们有几处做了忽略。事实上,
Check
函数还有一个额外的参数 —— 环境,用于存放变量名/函数名到其类型的映射,即
Check : (Env, AST, Type) -> Bool
。因此,一般情况下,我们会先做全局扫描,抓到所有的函数名和其对应类型并创建
Env
,这样便能应付(互)递归的函数定义了。在检查的过程中,我们也会(根据局部变量的生命周期)动态地往
Env
中加入、删除局部变量。
# 泛型函数类型检查
接下来,我们来看一下如何做泛型 generics(或多态 polymorphic)函数的类型检查。
我们以 Kotlin 的语法为例,如下所示。定义一个函数
f
,该函数有两个泛型类型参数
X
和
Y
;给定一个如下的函数调用 (因为是检查模式,所以这里是用
f<>
的形式调用的),应该如何检查函数调用是否合法呢?
// define
fun <X, Y>f(a : X, b : Y) { }
// use
f<Bool, Int>(true, 0)
如下所示,先建立一个类型上的映射 (或者叫代换 substitution)
m
,具体来说,我们需要根据位置关系,将
X
映射到
Bool
类型,
Y
映射到
Int
类型;第二步,我们需要找到函数
f
的定义,并且将类型中所有的
X
和
Y
用映射
m
代换掉,这样一来,我们就成功地将泛型函数类型检查替换为非泛型函数的类型检查了。
// Step 1: 建立映射
m = [X --> Bool, Y --> Int]
// Step 2: 用 m 代换泛型版本 f 的类型,得到
f : (a : Bool, b : Int) { }
// Step 3: 对代换后的函数进行类型检查
......进一步地,现在很多语言支持在泛型上定义上界 upper bounds。对带泛型上界的函数类型检查其理念其实也很简单。
// define
fun <X, Y>f(a : X, b : Y) where X <: Y { }
// use
f<Bool, Int>(true, 0)
和前面一样,我们先建立类型映射
m
并且做代换。需要注意的是,我们需要优先检查代换后的上界是否还是正确的。(例子中的上界是
where Bool <: Int
。)
// Step 1: 建立映射
m = [X --> Bool, Y --> Int]
// Step 2: 做代换
f : (a : Bool, b : Int) where Bool <: Int { }
// Step 3: 优先验证 `where Bool <: Int` 是否满足子类型关系
// Step 4: 若验证成功,则对代换后的函数进行类型检查;
// 若验证失败,则可以提前终止类型检查
......以上是一些简单的示例,我在参考部分补充了复杂的例子,感兴趣的同学可以进一步阅读。
# 编写一个类型推导器 #
现在我们来看一下如何实现一个类型推导器。
类型推导 type inference 在文献里常被叫做 类型重构造 type reconstruction 。相比类型检查而言,类型推导一般会更困难 (当然,这个困难在本次分享中不会体现得很明显)。
类型推导一个很关键问题就是,什么类型可以被推导出来。一般来说,我们会有 局部 local 推导和 全局 all / global 推导两种情况。
局部一般使用 局部类型推导 local type inference (或者 双向类型检查 bidirectional type checking ) 的推导方法,通常来讲,它只推导局部的变量定义、初始化、表达式、泛型函数调用等的类型,分界明显。
全局,会扫描代码里所有的定义和表达式,根据它们的声明和使用收集 约束 ,最后,使用 合一的方法 purely unification-based approaches 把类型解出来。 (熟悉的朋友应该了解 Hindley-Milner [1] 的类型推导算法 Algorithm W [2] [3] ,该算法在实践中被证明是很有效的,已成功应用于很多的大型项目中。)
# 局部 —— 双向类型检查
我们先从局部的部分开始,即使用双向类型检查。
一般来讲,程序可以被切割成 非泛型的部分 和 泛型的部分 。对于非泛型部分 (后面会有具体的例子解释说明),我们会将定义处的类型信息传递到使用处,或者将使用处的类型信息传递到定义处,从而完成一个简单的类型推导;对于泛型部分,我们会选用合一的方法来做推导(这是比较困难的部分 :-( )。
以变量声明为例,若开发者标注了变量的类型,我们便可以将该类型用作目标类型,来检查初始化表达式
expr
的类型;我们也允许开发者在定义变量的时候不指定类型,那么此时,我们需要先找到初始化表达式
expr
的类型,再将该类型当做变量的类型。这两种情况下类型的传播方向是双向的,即双向类型检查。
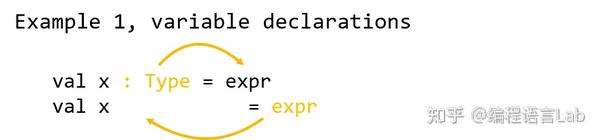

下图是函数返回类型的双向类型检查例子。如果开发者显式标注了函数的返回类型,那么我们可以用该类型去检查函数体中每一个
return
表达式的类型,类型传播如下图左边所示;当然,我们也允许开发者省略掉函数返回类型的标注,此时我们需要找出函数体中所有可能的
return
表达式的类型,将这些类型的公共父类型作为该函数的返回类型。省略返回类型一般在 lambda 表达式里比较有用。


如下是函数调用的例子。若在函数定义时,开发者声明了形参的类型,那在函数调用处,我们可以省略标注实参的类型,直接用形参的类型作为目标类型来检查实参类型即可。


类型推导在高阶函数的场景中是有好处的。如下所示例子中,函数调用的实参是一个 lambda 表达式,我们可以省略标注 lambda 表达式中形参
x
的类型,用函数定义处的形参类型
ParTy
作为
x
的类型即可;也可以使用定义处的返回类型
RetTy
来检查 lambda 体的类型。


以上就是四个简单的例子,用来说明如何使用双向类型检查的框架去做局部的类型推导,其 实质就是将类型信息从已知的部分传递到未知的部分 。
# 伪代码示例
接下来,我们来看如何实现一个类型推导器(双向类型检查器)。
首先,定义一个
Infer
函数,接受环境
Env
和要推导类型的节点
AST
为参数,返回该节点的类型。如下,
-- recall that `Check:(AST, Type) -> Bool`
Infer : (Env, AST) -> Type字面值类型推导
和类型检查类似,我们需要对正在被类型推导的树做模式匹配。字面值的类型推导比较简单,它是一种原子节点,这种情况下,我们可以直接用
typeOf()
获取字面值的类型。
Infer (env, Lit(n)) = typeOf(n) -- pattern match加法类型推导
还是按照刚才的加法例子,我们输入加法的语法树,如下。分别递归地推导左右子树的类型,如果推导出的左右子树类型相等,那么返回该类型作为加法的类型;否则,返回一个错误类型
ErrTy
。
Infer (env, Add(1, r)) =
let tyL = Infer(env, 1)
let tyR = Infer(env, r)
in if (tyL == tyR) then tyL else ErrTy函数调用类型推导
我们再看一个函数调用的例子。给函数
Infer
输入参数
env
和函数调用节点
FunApp(f, x)
(
f
是被调用的函数,
x
是
f
的入参)。
Infer (env, FunApp(f, x))
首先在环境
env
中找到
f
在定义处的类型,将查找到的函数类型使用模式匹配解构到形参类型
parTy
和返回类型
retTy
。
Infer (env, FunApp(f, x)) =
let FunTy(parTy, retTy) = LookUp(env, f)
然后我们就到了类型检查的阶段。我们需要检查,函数的实参
x
是否可以有形参类型
parTy
,或者说实参类型与形参类型是否匹配。如果匹配,则我们可以将查找到的函数返回类型
retTy
当做实际函数调用表达式的返回类型;否则,返回错误类型
ErrTy
。
Infer (env, FunApp(f, x)) =
let FunTy(parTy, retTy) = LookUp(env, f)
in if (Check(env, x, parTy)) then retTy else ErrTy函数定义类型推导
再来看函数定义的例子。我们将函数定义的名字绑定到变量
f
,函数形参绑定到
par
,函数体绑定到
body
,函数定义的返回类型绑定到
retTy
,如下。
Infer (env, FunAbs(f, par, body), retTy)
将形参解构为形参名
x
与形参类型
tyX
。
Infer (env, FunAbs(f, par, body), retTy) =
let (x, tyX) = par
在检查函数体类型之前,我们需要先做一步
扩展环境
的动作,将变量
x
有类型
tyX
这个事实加到环境中 (这是因为,函数体
body
里会有对变量
x
的引用)。
Infer (env, FunAbs(f, par, body), retTy) =
let (x, tyX) = par
-- the new env has mapping x : tyX
let env' = extendEnv(env, x, tyX)
如果我们想支持递归 (即在函数体内引用函数
f
自己),那么我们也需要将函数
f
本身的定义类型
FunTy(tyX, retTy)
加到环境中,如下。
Infer (env, FunAbs(f, par, body), retTy) =
let (x, tyX) = par
-- the new env has mapping x : tyX
let env' = extendEnv(env, x, tyX)
-- support recursion
let env'' = extendEnv(env', f, FunTy(tyX, retTy))
接下来,我们就可以直接检查函数体有没有返回类型
retTy
了。如果有,则返回
FunTy(tyX, retTy)
作为函数定义的类型,否则返回错误类型
ErrTy
。
Infer (env, FunAbs(f, par, body), retTy) =
let (x, tyX) = par
-- the new env has mapping x : tyX
let env' = extendEnv(env, x, tyX)
-- support recursion
let env'' = extendEnv(env', f, FunTy(tyX, retTy))
-- use the new env to check
in if (Check(env'', body, retTy))
then FunTy(tyX, retTy)
else ErrTy
环境扩展的作用是为了让我们可以在函数体
body
内查到
x
和
f
的类型。当然,更好的做法是,如前文所说,先做一次全局扫描,将所有函数的定义全部添加到环境
env
中,这样就可以处理互递归函数的情况了。
# 泛型函数类型推导
接下来我们一起看一下,对于一般初学者来讲比较难的部分,即泛型函数中泛型形参的类型推导 (本次分享我们只提供一个大的框架,有兴趣的小伙伴可以查阅文末的参考文献)。
依旧以 Kotlin 语法为例讲解一下如何做泛型函数的类型求解。定义一个
snd()
函数,有两个泛型形参类型
X
和
Y
,接受两个参数
x
和
y
,并返回第二个参数的类型
Y
。调用函数
snd(1, true)
,并将结果返回给声明为
Bool
类型的变量
res
。那么,我们应该怎样去解泛型函数参数的类型呢?
// define
fun <X, Y> snd(x : X, y : Y) : Y
// use
val res : Bool = snd(1, true)
我们先收集实参 args 的类型,
1 : Int, true : Bool
,以及函数定义处形参 params 的类型,即
x : X, y : Y
。
这里有一个规则 (或者事实),
要求实参类型必须是形参类型的子类型
,即
args <: params
。据此我们可以得到这样两条规则,
-
Int <: X -
Bool <: Y
鉴于我们的环境表示函数的返回类型必须是
Bool
,我们又会有一个规则需要遵循,要求函数声明处的返回类型,必须是我们环境/上下文中要求的类型的子类型,即
return <: context-type
,因此我们可以得到,
-
Y <: Bool
根据前述步骤,我们将已获得的子类型关系按照变量整理收集,可以得到如下两条关系。我们可以看到,变量
X
只有下界
Int
,而变量
Y
有上下界,都是
Bool
。
-
Int <: X -
Bool <: Y <: Bool
据此,我们得到了可能的解,即
X
只要是
Int
的父类型即可,而
Y
只能是
Bool
。
-
Int <: X -
Y = Bool
最后,结合考虑子类型关系、协变、逆变等因素,尽可能地找到一个 最优解 ,如下。
-
X = Int -
Y = Bool
# 如何实现合一
前面介绍的方法就是合一 (即 unifications),接下来我们简单介绍一下如何实现。
第一步,定义合一函数
unify
,输入两个类型,输出一组约束。
unify : (Type, Type) -> Constraints
对输入的类型参数做模式匹配,假设第一个参数输入的是类型变元 (例如前面例子中的
<X, Y>
),那么我们需要生成一条约束,表示该类型变元应该小于等于上界类型
sup
。
-- a singleton set
unify(TyVar(tv), sup) = { tv <: sup }
假设我们给第二个参数输入类型变元,那么对应地,我们可以生成如下这样的约束,表示该类型变元有下界
sub
。
unify(sub, TyVar(tv)) = { sub <: tv }还有一些其他的类型,比较有趣的是如下示例的函数类型。我们需要分别对两个函数的参数类型和返回类型递归地生成约束,再 取并集 ,得到最终的约束。这里需要注意的是,入参的部分是逆变的,返回类型部分是协变的。
unify(FunTy(S1, S2), FunTy(U1, U2)) =
unify(U1, S1) `union` unify(S2, U2)
其它情况下,我们只需要检查左边的类型
sub
是否是右边类型
sup
的子类型。
unify(sub, sup) = checkSubTy(sub, sup)现实中的语言会很复杂,这边就不展开介绍了。
局部 vs 全局
上一小节,我们简单介绍了如何对程序中非泛型部分和泛型部分做类型推导。那么,局部和全局的方法应该如何选用呢?
对比来看,局部的类型推导使用合一的方法来寻找泛型(多态)函数调用的类型变元的代换 (需要单独处理每个函数调用);全局的类型推导算法 (比如 Hindley-Milner-liked / Algorithm W) 使用合一的算法来推导所有表达式、定义的类型 (先将新的类型变元赋给表达式,然后再找到它们的代换)。
除了一些基于技术难度的考量外,局部和全局的选择也是一种设计理念上的哲学,比如,认为类型是文档的一部分 (为了代码的可读性,一些语言可能会倾向于不允许省略类型标注,比如函数定义部分的形参类型和返回类型);认为使用处不应该影响定义处等等。基于这些设计理念的考虑,一些语言,特别是工业语言,也可能会选择一种相对局部的类型推导技术。
# 如何严格地定义类型检查和类型推导 #
接下来,我们来看一下,应该如何严格地定义类型检查和推导,以及它们要满足的一些规则有哪些。
# 严格的类型检查
要严格地定义类型检查,我们需要做这些事情,
语法定义
首先,语法上需要定义程序里哪些是项 terms,哪些是项运行后的结果 values,哪些是类型 types。
- 项 Terms:即我们常说的表达式和语句。
- 值 Values:不可化简(规约)的项,包括字面量,函数和 lambda 等。
- 类型 Types:项的抽象。一个正确的 term 永远会有一个类型,我们用 term : Type 表示二者的二元关系。
我们使用扩展的 BNF 来定义语法。
我们说,一个项 term 可以是一个整数,布尔值,加法,变量,可以是函数定义 ( \lambda x.t ,lambda abstraction,定义一个函数,其形参是 x ,函数体是 t ),可以是函数调用 t(t) ,还可以是序列 t;t 。基于这样的描述,我们就可以规定出如下的简单语法。 (注意:此处的语法定义中,"+" ";" 等这种符号是字面量,而 t 相当于是占位符,可以展开为定义中的任一种。请读者区分。)
t ::= 0 | 1 | 2... ; integers
| true | false ; booleans
| t "+" t ; additions
| x, y... ; variables
| λx "." t ; abstraction
| t "(" t ")" ; application
| t ";" t ; sequence
| ...
值 values 的语法定义如下。值是不可被化简(规约)的部分,比如整数
0
、
1
、
2
、
3
等,但
1+2
不是值,因为它可以被化简(规约)为
3
。
v ::= 0 | 1 | 2... ; integers
| true | false ; booleans
| λx.t ; application
|...我们还需要定义类型 types,语法规则如下。类型可以是类型变元,可以是多态类型,可以是函数类型,可以是布尔类型、整数类型等,如果我们还需要处理子类型关系的话,大概率系统里还需要一个顶类型和底类型 (顶类型 top type,即所有类型的公共父类;底类型 bottom type,即所有类型的公共子类)。
T ::= X ; type variables
| ∀X <: T.T ; polymorphic types
| T → T ; function types
| Bool ; booleans
| Int ; integers
| ⊤ ; the Top type
| ⊥ ; the Bottom type
| Unit ; the Unit type
| ...类型规则
在有了语法之后,我们需要定义一组 类型关系 type relations (t : T) 。
类型关系用 t:T 描述,此处 “:” 是 term 和 type 之间的二元关系 。
如果类型关系没有横线,则表示该描述恒成立,如下图所示。 1:Int 表示 1 永远是 Int 类型, true:Bool 表示 true 永远有 Bool 类型。
\begin{aligned} &1 : Int &\qquad \text{integers}\\ &true : Bool &\qquad \text{booleans}\\ \end{aligned}
若类型关系如下所示,则表示横线上面 x:T\in\Gamma 是横线下 \Gamma \vdash x:T 的前提 (此处 \Gamma 表示环境, \Gamma \vdash A 表示在环境 \Gamma 下 A 成立),即如果我们的环境 \Gamma 中存放了变量 x 到类型 T 的映射关系,那么我们就知道在环境 \Gamma 下 x 一定有类型 T 。
\frac{x:T\in\Gamma}{\Gamma\vdash x:T}\qquad \text{variable}
下面是函数定义的类型规则。它告诉我们如果在环境 \Gamma 加上 x 有类型 T_1 的前提下,函数体 t 有 T_2 类型,则我们可以说,在环境 \Gamma 下,lambda 表达式 \lambda x : T_1 . t 有 T_1 \rightarrow T_2 的类型。
\frac{\Gamma, x:T_1\vdash t : T_2}{\Gamma\vdash\lambda x:T_1.t:T_1\rightarrow T_2}\qquad \text{abstraction}
上述类型规则,还可以用前面介绍过的双向类型检查框架拆分为检查规则 \Leftarrow 和推导规则 \Rightarrow 。
\begin{aligned} &\frac{T_1<:T_x \qquad \Gamma, x:T_x \vdash t \Leftarrow T_2}{\Gamma \vdash \lambda x:T_x.t \Leftarrow T_1 \rightarrow T_2} &\qquad \text{abs check1} \\ \\ &\frac{\Gamma, x:T_1 \vdash t \Leftarrow T_2}{\Gamma \vdash \lambda x.t \Leftarrow T_1 \rightarrow T_2} &\qquad \text{abs check2} \\ \\ &\frac{\Gamma,x:T_x\vdash t \Rightarrow T_2}{\Gamma \vdash \lambda x:T_x.t \Rightarrow T_x \rightarrow T_2} &\qquad \text{abs infer}\\ &\qquad\qquad\qquad\qquad\qquad \end{aligned}
对比来看,检查的规则多出了目标类型这一输入:lambda 表达式的目标类型为 T_1 \rightarrow T_2 ,我们检查其是否成立;而在推导的规则中,“目标类型”是缺失的。不难看出,只有检查的规则 (abs check2) 允许 lambda 表达式省略其形参 x 的类型。通常来说,我们应优先使用检查规则 (如果可用),因为它通常速度更快且可以在更多的场景工作。
子类型关系
在定义了类型关系之后,我们还需要定义子类型关系 (其实 abs check1 已经使用了子类型关系)。子类型关系是两个 类型上的二元关系 ,即 T_1 <: T_2 。
以下是一些恒成立的子类型关系规则,比如一个类型永远是它自身类型的子类型 (自反性),一些语言会有底类型 \bot (Bottom、Nothing 等) ,它是所有类型的子类型,一些语言中还有顶类型 \top (Top、Any 等),它是所有类型的父类型。
T <: T \qquad \bot <: T \qquad T<: ⊤
以下是在一些条件下会成立的子类型关系 ( \Delta 表示类型上的环境,会包含一些类型上下界等相关的信息)。
\frac{X <: T\in\Delta}{\Delta\vdash X <: T}
如下是大多数类型系统都具有的性质:子类型的传递性 transitivity。若存在 T_1 是 T_2 的子类型,且 T_2 是 T_3 的子类型,则我们可以得到, T_1 是 T_3 的子类型。
\frac{\Delta\vdash T_1 <: T_2 \quad \Delta\vdash T_2 <: T_3}{\Delta\vdash T_1 <: T_3}\qquad\text{transitivity}
如下是函数类型的子类型关系,在此(又)要注意协变和逆变。当我们要证明 S_1 \rightarrow T_1 <: S_2 \rightarrow T_2 时,对于函数参数类型我们要用逆变关系,即 S_2 <: S_1 ;对于函数的返回类型我们要用协变关系,即 T_1 <: T_2 。
\frac{\Delta\vdash S_2 <: S_1 \quad \Delta \vdash T_1 <: T_2}{\Delta \vdash S_1\rightarrow T_1 <: S_2 \rightarrow T_2}\qquad\text{arrow}
# 类型系统的证明规则
当我们定义了前述的语法和类型规则后,接下来我们就需要去证明我们的类型系统需要满足什么规则。
一般来讲,需要满足两条规则, 可靠性 soundness 和 完备性 completeness 。
可靠性 Soundness
可靠性指的是, 类型正确的表达式在运行的时候是不会出错的 (well-typed terms do not go wrong) 。即,如果一个表达式通过了类型检查,或者说它可以被赋予一个类型的话,那它运行的时候一定不会出错。
那么,要如何保证这点呢?这里又可以细分为两个子规则,一个叫 progress,一个叫 preservation。 Progress 指,一个 term 或是一个 value,或可以被进一步计算(而最终得到 value),比如 1+2 可以被计算到 3 。 Preservation 指,term 在经过计算后仍然拥有一个合法的类型。下面这个例子就验证了上述两条规则。


完备性 Completeness
对于类型检查器来说,完备性即 每一个正确的表达式都可以通过检查 ;对于类型推导器来说,完备性指 要为每一个正确的表达式分配一个类型 。不过在实际中,我们不一定能完全做到后者。那怎么办呢?很简单,我们只需要将类型标注出来,然后“退回到”类型检查即可。毕竟检查一般来说会比推导兼容更多的场景。
# 举个例子
下面我们用一些反例来说明为什么前述两条规则是重要的。
如果我们的程序不满足可靠性,那么很可能的是,程序可以编译通过,但运行行为是未定义的 undefined。
而如果我们的类型检查器是很不完备的,那么可能一些明显正确的代码,比如
1 + 2 : Int
,也无法编译。如果类型推导器是十分不完备的,那么编译器很有可能会很烦人,要求我们在每个很明显的地方显式指定类型,比如我们不能写
var a = true
,而需要明确写出
bool a = true
。
我们来看一个真实的例子。以 C++ 为例,程序中定义了公共父类
class C
,
C
有两个子类
D
和
E
。我们声明一个类型为
C
的变量
c
,并且用一个简单的二元表达式来初始化它。C++ 的编译器会在这里报错:它说它无法找到
D
和
E
的公共父类——即便这里只能是 C。
class C { };
class D : public C { };
class E : public C { };
C c = true ? D() : E();
// error: incompatible operand
// types ('D' and 'E')