


模型转换:由Pytorch到TFlite

01 前言
目前,越来越多的开源代码由Pytorch写成,在模型定义、训练和可读性上的优势都远超Tensorflow。 然而在面向移动端部署的时候,某些项目仍旧需要使用TFlite。 这就引发了一个矛盾:新的算法效果很好,但我们却无法直接使用Pytorch来部署,必须要转成Tflite。
那么,我们就有两个选择:
- 方法1: 根据Pytorch的代码,使用Tensorflow重写,得到TFlite;
- 方法2: 在Pytorch上完成训练并保存模型后,利用模型转换工具ONNX,得到TFlite。
不用说,二者的难度不是一个等级的。对于简单一点的模型,方法1还勉强可以接受,而对于目标检测、实例分割等算法,没有个把月的时间,几乎是没办法完成代码转换的。即便完成,能否在Tensorflow上训练出和Pytorch相同的效果,也很难说,毕竟二者反向传播的方式都不同,这无疑对问题排查带来了极大的难度。
因此,这篇文章主要分享的是方法2,即通过ONNX来进行Pytorch到TFlite的模型转换,也就是: Pytorch—>ONNX—>Tensorflow—>TFlite
02 ONNX简介
ONNX(Open Neural Network Exchange)是一种针对机器学习所设计的开放式的文件格式,用于存储训练好的模型。它使得不同的人工智能框架(如Pytorch、MXNet)可以采用相同格式存储模型数据并交互。
目前官方支持加载ONNX模型并进行推理的深度学习框架有: Caffe2, PyTorch, MXNet, ML.NET ,TensorRT 和 Microsoft CNTK, 并且 TensorFlow 也非官方地支持ONNX 。
03 代码实现
Step0:环境配置(非常重要!!!)
torch==1.5.1
torchvision==0.6.1
tf==tf_nightly-2.4.0.dev20200811
onnx==1.7.0
onnxruntime==1.7.0
onnx-tf==1.7.0
tensorflow-addons==0.11.2
Step1:由Pytorch得到ONNX
这里给出一个Pytorch的mobilenet_v2的模型转ONNX的例子,并且验证模型的输出是否相同。
import os.path as osp
import numpy as np
import onnx
import onnxruntime as ort
import torch
import torchvision
# torch --> onnx
test_arr = np.random.randn(10, 3, 224, 224).astype(np.float32)
dummy_input = torch.tensor(test_arr)
model = torchvision.models.mobilenet_v2(pretrained=True).eval()
torch_output = model(torch.from_numpy(test_arr))
input_names = ["input"]
output_names = ["output"]
torch.onnx.export(model,
dummy_input,
"mobilenet_v2.onnx",
verbose=False,
input_names=input_names,
output_names=output_names)
model = onnx.load("mobilenet_v2.onnx")
ort_session = ort.InferenceSession('mobilenet_v2.onnx')
onnx_outputs = ort_session.run(None, {'input': test_arr})
print('Export ONNX!')
Step2:由ONNX转Tensorflow,得到.pb文件
from onnx_tf.backend import prepare
import onnx
TF_PATH = "tf_model" # where the representation of tensorflow model will be stored
ONNX_PATH = "mobilenet_v2.onnx" # path to my existing ONNX model
onnx_model = onnx.load(ONNX_PATH) # load onnx model
tf_rep = prepare(onnx_model) # creating TensorflowRep object
tf_rep.export_graph(TF_PATH)
Step3:由.pb得到TFlite
import tensorflow as tf
TF_PATH = "tf_model"
TFLITE_PATH = "mobilenet_v2.tflite"
converter = tf.lite.TFLiteConverter.from_saved_model(TF_PATH)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tf_lite_model = converter.convert()
with open(TFLITE_PATH, 'wb') as f:
f.write(tf_lite_model)04 转换误差
1,从pytorch到onnx,可以认为无损失
2,从onnx到tflite的精度,不同任务的表现略有差异,下面给出了一些分割、检测和超分模型的转换误差。
| 模型 | 转换误差(像素均方差) |
|---|---|
| unet++ | e-12 |
| linknet.onnx | e-14 |
| manet.onnx | e-08 |
| yolov3.onnx | e-14 |
| yolov4.onnx | e-16 |
| retinanet.onnx | e-12 |
| bsrgan.onnx | e-15 |
05 onnx-tf的问题
由于pytorch的输入是NCHW,转成ONNX也是NCHW,再使用onnx-tf转成tflite时,输入也是NCHW,所以在某些需要以NHWC为输入的算子上(如conv),就会在该算子的前后分别多出一个transpose算子(第一个用于NCHW->NHWC,第二个用于NHWC->NCHW),这也是onnx-tf转换的生硬之处,多出的算子会对推理速度有一些影响。
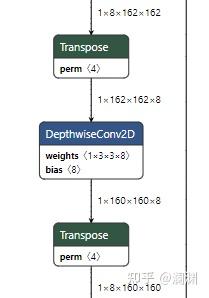
该问题的根本原因就是onnx-tf是逐个算子来解析onnx的,它并不会看到模型的全貌,所以如果有两个conv相邻,就会在它们中间看到重复的transpose操作。
06 onnx模型去冗余
由pytorch转出onnx时,会看到onnx中多出了一些gather,concat等算子,这些算子的输入都是某种意义上的常量,即要么就是常数值,要么是某个算子的输出,而该算子的输入又是常数值……总之,这些多余的算子只是为了计算出某些常数值,作为其他算子的输入参数。
以下图中的reszie节点为例,输入有两个,第一个是input data(由relu节点得到),第二个是shape(由concat节点得到),我们可以看到pytorch源码里resize的实现也是需要这两个参数的,onnx这种处理方式其实是没有问题的。但既然模型结构已经确定下来的,这里concat节点的输出其实就是常量值,那有没有办法可以去掉这个节点,直接把这个固定的shape写到resize节点的输入信息中呢?
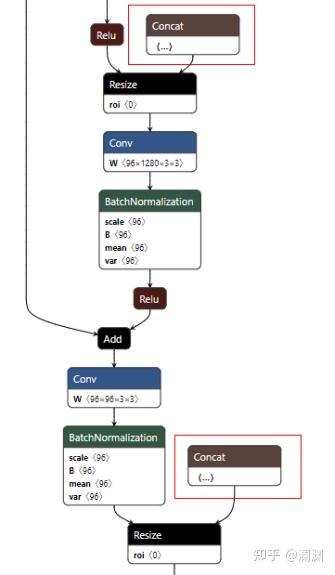
针对这个问题,有大佬开源了一项onnx去冗余的项目,个人在使用中发现这个工具还是特别好用的,建议大家在导出onnx前都先执行一遍去冗,模型会清爽不少。
使用起来也是很简单的,首先通过pip安装该工具:
pip install onnx-simplifierload初始的onnx模型,通过model_simp, check = simplify(model)这一行代码即可得到去除冗余后的模型。
import onnx
from onnxsim import simplify
# load your predefined ONNX model
model = onnx.load(path + model_name + '.onnx')