


Cv学习第二阶段ResNet+Animal-10实战(实战向)第六弹

在正常项目中,我们往往需要用到客制化的数据集。因此我们必须要对模型进行修改才能使用,这一章我们主要讲如何在原版模型的基础上作出简单修改。
第一步:读取模型
拿出我们之前训练好的模型,输出一下,让我们看看他的结构是什么样子的吧。
myResNet = torch.load('modelResNet101.pt')
print(myResNet)
简单输出一下,我们能够看到输出了一大堆数据,以图片这一点举例,我们简要分析一下
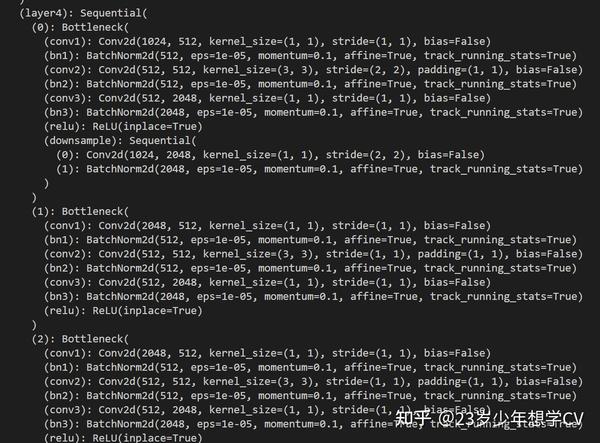

首先是layer4,这是这一层的名称,如果我们要修改模型,首先就要找到这个名字,才能对其修改。
之后是Sequential,他表示接下来括号里的model是连续的。
他加了几个模型呢,从截图里看到有0,1,2三个模型。
这三个模型是相同的——都是Bottleneck。
Bottleneck里包含了哪些简单模型呢,首先是conv1,一个卷积层,然后一个bn1,归一化,按照这个规律重复两次再加一个relu激活,这就形成了一个简单的模型。多个简单模型堆叠在一起就变成了大模型。
大家可以看到规律 卷积+归一化+重复+激活 ,这是深度学习常用堆叠模型的套路,掌握这个套路,写模型也就没有想象中的那么难了。
第二步:修改模型
接下来我们将眼光聚焦到我们要修改的地方,模型的输出部分


输出部分被命名为fc层,他是一个简单的线性层(linear),输入维度为2048,输出维度为1000,显然我们的客制化数据集只有10类,那我们就需要修改这个模型
myResNet.fc = torch.nn.Linear(2048,10)这样我们就把模型的最后一层改为只有10个输出神经元了,这个模型就变成了能够解决10分类问题的模型。


第三步:加载数据集
还是按照以前的样子进行数据集加载与划分,只不过需要注意的是,我们的数据预处理可以去掉烦人的归一化了,毕竟归一化还需要我们自己算均值和方差。
加载数据集的时候也没有使用多线程,因此主函数也可以省略掉了。(省不省看个人喜好,一般来说不省才是对的,但是偶尔偷个懒也没事)
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor()])
dataSet = torchvision.datasets.ImageFolder(
root=r"DataSet\ImageNet\Animals-10\raw-img",
transform=preprocess)
trainSize = int(len(dataSet) * 0.75)
testSize = len(dataSet) - trainSize
trainDataSet, testDataSet = torch.utils.data.random_split(dataSet, [trainSize, testSize])
trainLoader = DataLoader(trainDataSet, batch_size=128, shuffle=True)
testLoader = DataLoader(testDataSet, batch_size=4096, shuffle=True) 第四步:模型的训练
这些训练代码和第一章的代码大同小异,这里就不细讲了。毕竟固定写法嘛,生不出来太多花。
myResNet = myResNet.to(device)
criterion = torch.nn.CrossEntropyLoss()# 使用CrossEntropyLoss多分类损失函数
optimizer = torch.optim.Adam(myResNet.parameters(), lr=learning_rate) # 使用Adam优化器来计算损失与更新,并设置学习率为learning_rate,即0.001
num_epochs = 100 # 跑多少轮
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(trainLoader):
images = images.to(device) # 获取图像
labels = labels.to(device) # 获取图像对应标签
outputs = myResNet(images)# 将图像输入到网络中并得到结果
loss = criterion(outputs, labels)# 通过结果计算损失函数