

用pyspark读取json数据的方法汇总

JSON(JavaScript对象表示法)是一种轻型格式,用于存储和交换数据。 输入的JSON格式可能不同
- simple,
- multi line with complex format,
- HTTP link,
- a CSV which contains JSON column.
下面用pyspark实现读取几种格式json
1. Simple JSON:
JSON文件 (Simple.json)


代码
from pyspark.sql import SparkSession
spark = SparkSession.builder.config("spark.sql.warehouse.dir", "file:///C:/temp").appName("readJSON").getOrCreate()
readJSONDF = spark.read.json('Simple.json')
readJSONDF.show(truncate=False)输出
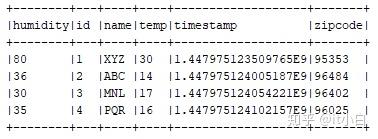
2. 多行混合 JSON:
Input JSON file (ComplexJSON.json)
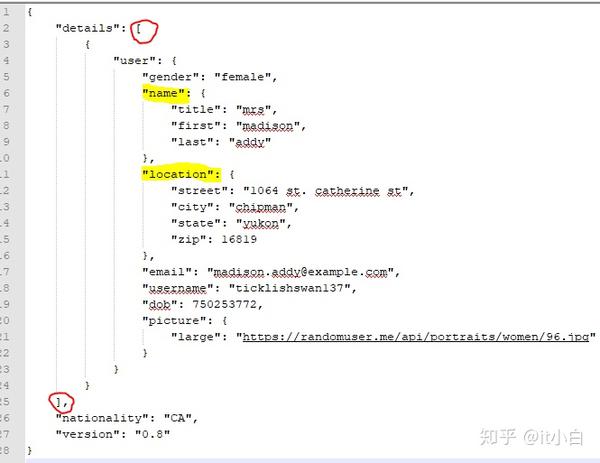


要读取多行JSON文件,我们需要使用option(“ multiLine”,“ true”)。 另外,在上图中,“ details”标记是一个数组,因此要读取数组元素内的内容,我们需要先对其进行分解。 下面的代码将显示我们如何从上述输入文件中读取位置和名称
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
spark = SparkSession.builder.config("spark.sql.warehouse.dir", "file:///C:/temp").appName("readJSON").getOrCreate()
# use multiline = true to read multi line JSON file
readComplexJSONDF = spark.read.option("multiLine","true").json('ComplexJSON.json')
# Explode Array to Structure
explodeArrarDF = readComplexJSONDF.withColumn('Exp_RESULTS',F.explode(F.col('details'))).drop('details')
# Read location and name
dfReadSpecificStructure = explodeArrarDF.select("Exp_RESULTS.user.location.*","Exp_RESULTS.user.name.*")
dfReadSpecificStructure.show(truncate=False)

3. 读取http流json数据:
Input JSON file (online data)
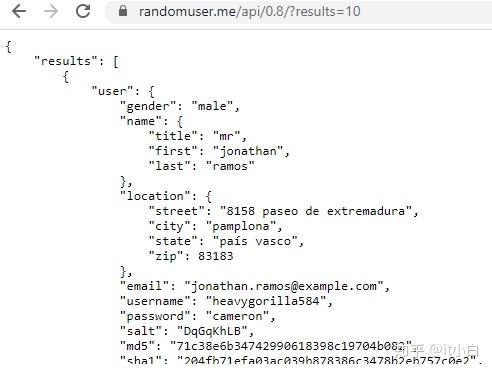
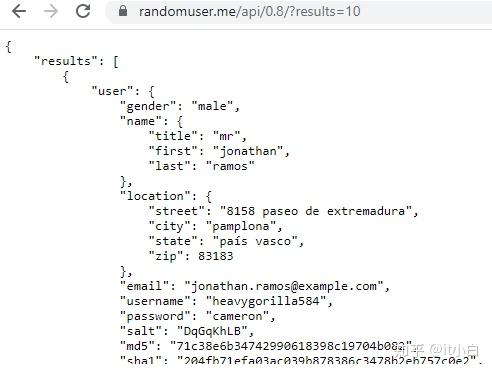
Schema:

要读取在线JSON,我们将使用urllib.request,使用utf-8解码打开URL内容。 之后,将其转换为RDD,最后创建一个数据框。 与上述相同,将数组拆分,然后读取结构“名称”。 请记住,如果没有Array元素,则无需拆分。
from pyspark.sql import SparkSession
from pyspark import SparkContext
from pyspark.sql import functions as F
from urllib.request import Request, urlopen
sc = SparkContext(master="local[*]", appName= "readJSON")
spark = SparkSession.builder.config("spark.sql.warehouse.dir", "file:///C:/temp").appName("readJSON").getOrCreate()
# Online data source
onlineData = 'https://randomuser.me/api/0.8/?results=10'
# read the online data file
httpData = urlopen(onlineData).read().decode('utf-8')
# convert into RDD
rdd = sc.parallelize([httpData])
# create a Dataframe
jsonDF = spark.read.json(rdd)
# read all the users name:
readUser = jsonDF.withColumn('Exp_Results',F.explode('results')).select('Exp_Results.user.name.*')
readUser.show(truncate=False)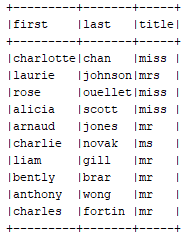
4. CSV文件包含json
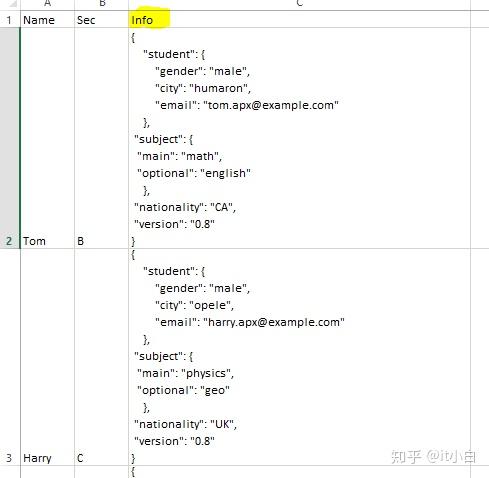
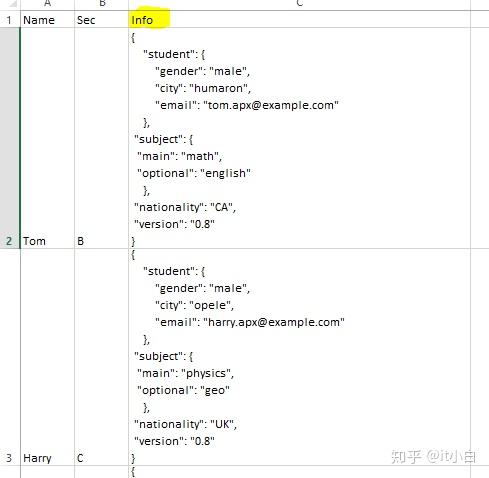
将读取带有选项(“ multiLine”,“ true”)的CSV文件以获取多行JSON格式,而选项(“ escape”,“ \””)忽略JSON内容中的“(上图的信息”列)。 然后,我们将使用JSON_TUPLE从JSON内容读取所需的详细信息。 JSON_TUPLE有两个参数,第一个是列名,第二个是我们感兴趣的必需标记值。
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
spark = SparkSession.builder.config("spark.sql.warehouse.dir", "file:///C:/temp").appName("readJSON").getOrCreate()
# escape all " in the JSON content to read properly
readCSVFileDF = spark.read.option("multiLine","true").option('escape',"\"").option('header',True).csv('mixJSON4.csv')
readCSVFileDF.printSchema()
readCSVFileDF.show(truncate=False)
# use JSON_TUPLE to read required contents : student, nationality and subject from Info column
readJSONContentDF1 = readCSVFileDF.select("*",F.json_tuple("Info","student","nationality","subject")).drop('Info')
readJSONContentDF1.show(truncate=False)
# use JSON_TUPLE to read student details - gender, city, email
readJSONContentDF2 = readJSONContentDF1.select('*',F.col('c1').alias('Nationality'),F.json_tuple('c0','gender','city','email').alias('Gender','City','MailId')).drop('c0','c1')
readJSONContentDF2.show(truncate=False)
# use JSON_TUPLE to read subject details - mainsubject and optional
finalDF = readJSONContentDF2.select('*',F.json_tuple('c2','main','optional').alias('MainSubject','OptionalSubject')).drop('c2')
finalDF.show(truncate=False)
# another way : using withcolumn
readJSONDF = readCSVFileDF.select("*",F.json_tuple("Info","student","nationality","subject")).drop('Info')
readJSONDF.show(truncate=False)
finalDF1 = readJSONDF.withColumn('Gender',F.json_tuple('c0','gender')).\
withColumn('City',F.json_tuple('c0','city')).\