whenever there is delimiter value present within the data, the data gets enclosed within some characetrs.
Is the data in your file which has comma enclosed within quotes? If yes,you can use the quote char functionality within the dataset
Hi
Lilly W
,
Thanks for the question and using Microsoft Q&A forum.
As per your description, it seems like purely a source data format issue. In case if you source data, column values are enclosed in quote characters (as shown in below example), and you have extra comma (nothing but the column delimiter in your case) then as
Nandan Hegde
called out, you can use Quote character setting in your data set to escape them and avoid issue while reading the data.
If you are source column contain the column delimiter in your column values and the column values are enclosed in quote character, then you will have to configure dataset as below to overcome the issue.
In case if your source data does not contain any quote characters for your column values, then it will be hard to fix it at the pipeline runtime.
Possible workaround
:
Option 1
: The source provide has to correct the data before submitting to ADF pipeline.
Option 2 (recommended if you don't have control over the source file generation)
: Copy activity supports detecting, skipping, and logging incompatible tabular data using
Fault tolerance
feature. The way this featrure works is that the CSV file rows that contain expected number of columns are copied successfully to the sink store. The CSV file rows that contain more than expected columns are detected as incompatible and are skipped and logged as per the configuration. You can then log the skipped incompatible rows into storage account and then fix them manually or some other process and reprocess them through the pipeline.
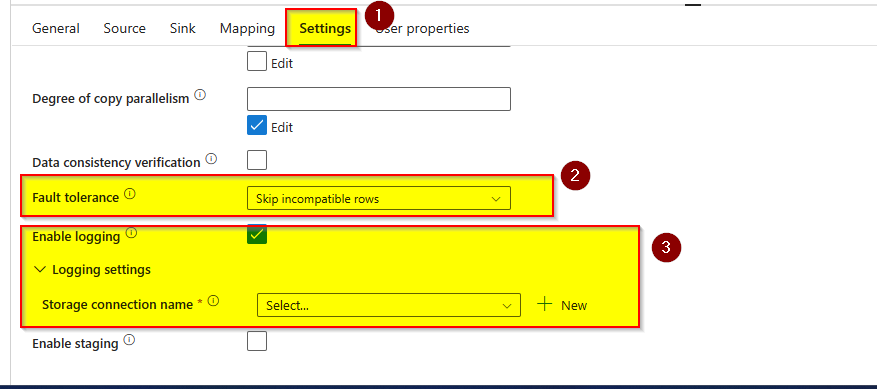 Here is reference doc for Fault tolerance in copy activity:
Copy activity Fault tolerance
Here is reference doc for Fault tolerance in copy activity:
Copy activity Fault tolerance
Hope this info helps.
Please don’t forget to
Accept Answer
and
Up-Vote
wherever the information provided helps you, this can be beneficial to other community members.
This is helpful because I did not know how to log errors before. I want to also add that although learning to log errors is helpful, the solution to this problem for me was to set "Quote Character" and "Escape Character" to Double quote (") in the Copy Data activity source dataset. Hope that helps someone else!
I found solution in this thread -
https://learn.microsoft.com/en-us/answers/questions/645105/comma-and-double-quotes-causing-the-data-flow-to-f

