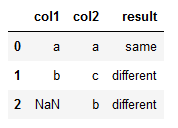
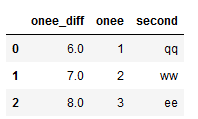
a = pd.DataFrame({'one':[1,2,3,4,5],'two':['q','w','e','r','t'],'three':['aa','ss','dd','ff','gg']})
b = pd.DataFrame({'onee':[1,2,3,4,5,6,7,8],'second':['qq','ww','ee','rr','tt','yy','uu','ii']})
c = a['one'].to_list()
d = b['onee'].to_list()
e = []
for i in d:
if i in c:
continue
else:
e.append(i)
e = pd.DataFrame(e,columns = ['onee_diff'])
f = pd.concat([e,b],axis=1)
g = f[f['onee_diff'].isnull()==False]
以上就是我的方法,如果大家有更好的方法,或者更加多功能对比的方法和想法,欢迎交流。
问题:现在有两个DataFrame,第一个我们命名为df1,第二个我们命名为df2。两个DataFrame中各有一列数据,我需要横向判断这两列的数据是否相同(即:判断df1的第1行和df2的第1行是否相同,df1第2行和df2第2行是否相同,依次类推),网上查看了一些解决办法,有的用循环遍历等都感觉不太正确,因为数据量太大也没办法验证.import pandas as pdimport numpy as np1、当数据长度相同时df1 = pd.DataFrame({'col1':['a','b'
name = ['bob', 'mike','lisa','jay','alen','book','james']
month_sale = [100, 99, 120, 160, 50,70, 90]
day_sale = [120, 99, 100, 260, 50,50, 190]
df = pd.DataFrame(data={'name':name,'month_sale':mon
Spark并没有提供比较两个dataframe是否相等的函数,所以,需要通过现有的函数来完成任务。但不同方式的性能有很大不同。
这里提供4种方式来比较两个Dataframe是否相等,可以根据不同的场景来选择使用。
对于小的dataframe,可以直接collect回来,然后比较。
(1)先检查表结构是否相等;(2)确保df1,df2,df3没有重复行 ,使用intersect,并查看其count数是否和df的count数相等
使用subtract函数
可以通过subtract函数
在官方文档中:pandas.testing.assert_frame_equal — pandas 1.3.5 documentation
介绍了可以使用assert_frame_equal()函数来比价两个DataFrame是否完全一样,包括数值和数据类型。如果不一样,会显示哪列或哪行不一样,比价方便。
assert_frame_equal(my_processed_df, processed_df)
另外,补充一点,将dataframe中的其他数据类型转为int64的方式:
processe
2、在数据中如果有不相等列,那么就只比较相同的列;
3、可以设置绝对差值和相对差值,比如我们比较有浮点数的数据时,设置下绝对差值为0.01,后面的一系列微小的值就忽略了;
4、在数据报告中,每一列的数据类型、不相等数量、最大差值和空值都详细列...
from pandas import Series,DataFrame
data = {'language':['Java','PHP','Python'],'year':[1995,1995,1991]}
frame = DataFrame(data)
frame['IDE'] = Series(['Intellij','Notepad','IPython'])
'IPyt...
在Python中,DataFrame是一种数据结构,用于处理和分析二维数据集。它可以包含多个列,每列可以是不同的数据类型(例如整数,浮点数,字符串等)。
要找到DataFrame中特定列的最大值,可以使用`max()`函数。例如,以下代码将找到名为“列名”的DataFrame列中的最大值:
```python
import pandas as pd
# 创建一个DataFrame
df = pd.DataFrame({'列名': [1, 2, 3, 4, 5]})
# 找到"列名"列的最大值
max_value = df['列名'].max()
print(max_value) # 输出5
要找到多个列中的最大值,可以使用相同的语法并提供列名列表作为参数。例如,以下代码将找到了名为“列_1”和“列_2”的DataFrame列中的最大值:
```python
import pandas as pd
# 创建一个DataFrame
df = pd.DataFrame({'列_1': [1, 2, 3, 4, 5],
'列_2': [10, 20, 30, 40, 50]})
# 找到"列_1"和"列_2"列的最大值
max_values = df[['列_1', '列_2']].max()
print(max_values) # 输出:
# 列_1 5
# 列_2 50
# dtype: int64
在此示例中,使用`df[['列_1', '列_2']]`选择两个列,并在之后调用`max()`函数找到它们的最大值。最终结果是一个包含每个列最大值的Series对象。
python数据分析-concat合并表,报错InvalidIndexError: Reindexing only valid with uniquely valued Index objects