


语义召回:在工业界实现语义索引

Semantic Retrieval
标题:《Pre-trained Language Model for Web-scale Retrieval in Baidu Search》
arxiv链接: https:// arxiv.org/pdf/2106.0337 3.pdf
Abstract
在网页搜索中,如何从数十亿级别的集合中选出少量的与query相关的候选集,是非常重要的事情。当前缺少如何将语义匹配有效地运用在信息检索中的例子。
本片论文做了三点贡献:
- 语义检索模型
- 检索模型训练范式:4阶段
- ERNIE预训练→MLM+NSP
- 用大量点展日志数据 post-pretrain→MLM+NSP
- 初步 fine-tune→semantic matching
- 用少量人工标注数据 fine-tune→semantic matching
3.语义召回检索系统
结论:基于我们训练好的semantic model下的系统,能够召回更高质量的query-doc,尤其在长冷无明确需求的query上体现更好。
Keywords
PLM、IR、search
1.Introduction
1.1 Challenges
越来越大规模和多种类需求的query检索给搜索系统带来巨大挑战,总结如下:
- C1:传统的文本/term匹配的方式在很多case中落败,需要语义匹配解决;同时多需求的query也给语义匹配带来多项挑战
- C2:长尾分布的query和doc形式,给语义召回带来挑战,主要体现:长冷query语义召回
- C3:在工业界实现,需要建立可行方案
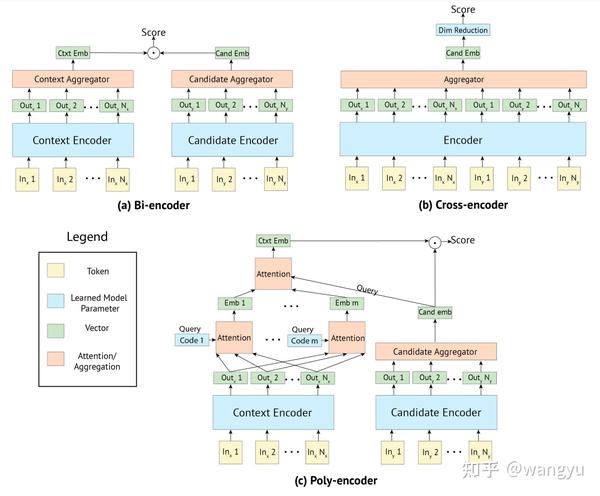
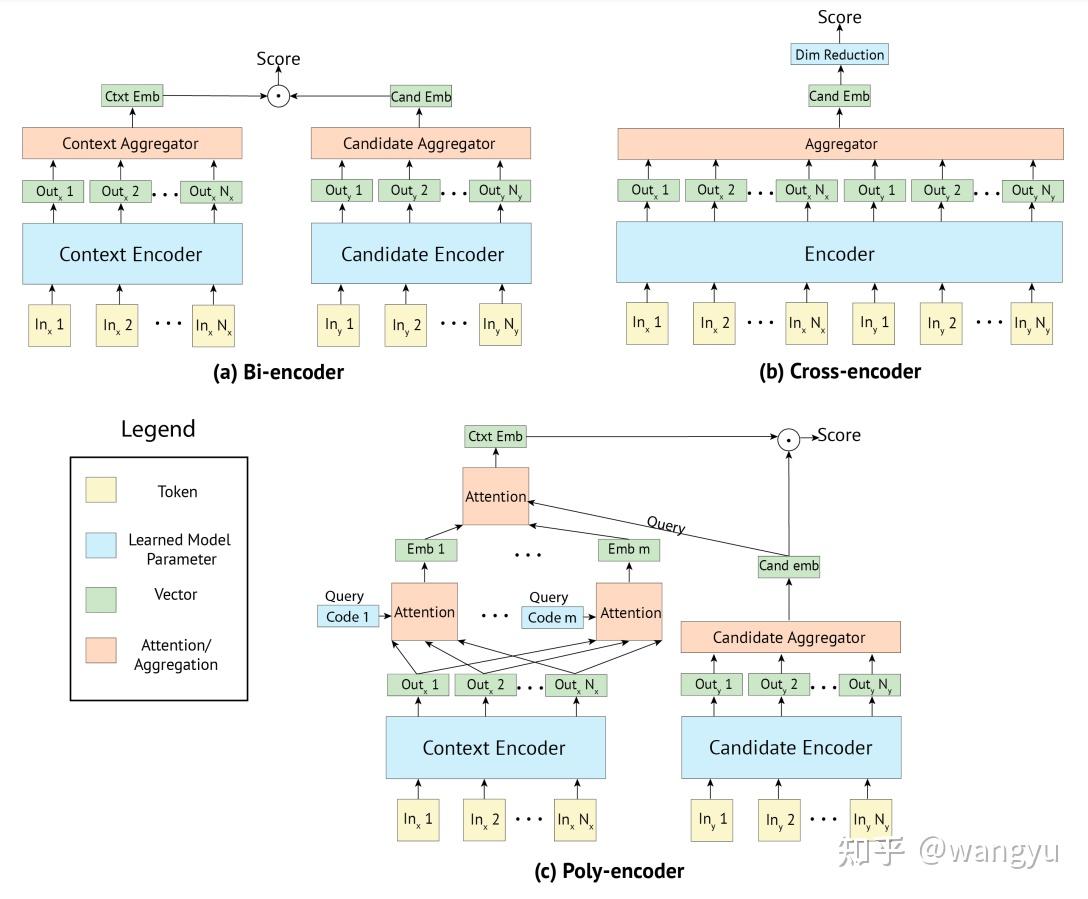
介绍主要框架:bi-encoder(准确率的说,应该是poly-encoder)、BERT、Transformer
1.2 Present Work
我们基于ERNIE训练并设计一个语义召回系统,针对上述各challenge,我们解决方案如下:
- To C1:
- 用Ernie训练一个poly-encoder,改模型能够cover更细粒度语义信息
- 创造性地设计出有效地样本构造策略
- To C2:提出四阶段训练范式,多种类样本+多目标训练
- To C3:设计检索系统架构,merge文本匹配+语义匹配,轻模型统一过滤两路doc
2.Related Work
2.1 Semantic Retrieval in Web Search
DSSM
离线计算doc embeddings
interaction-based methods
2.2 Pretrained Language Models
PLM:ELMO、BERT、ERNIE
transformer
unsupervised pretraining
缺少应用于搜索系统的workflow
3.Retrieval Model
这部分主要是介绍我们训练任务定义,以及如何实现的。
3.1 Task definition
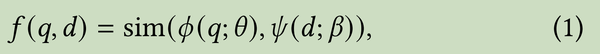
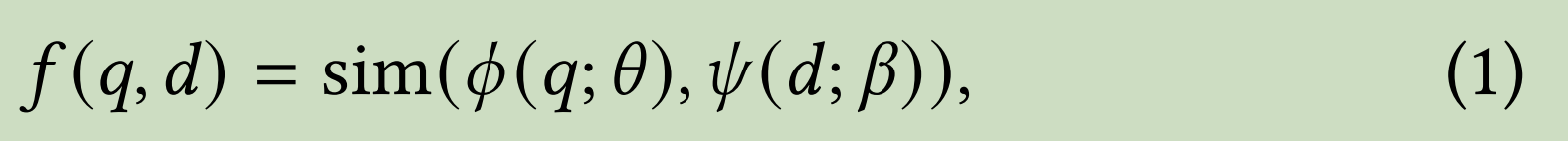
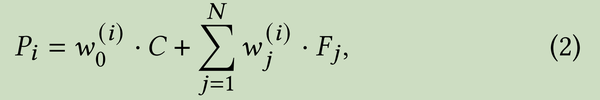
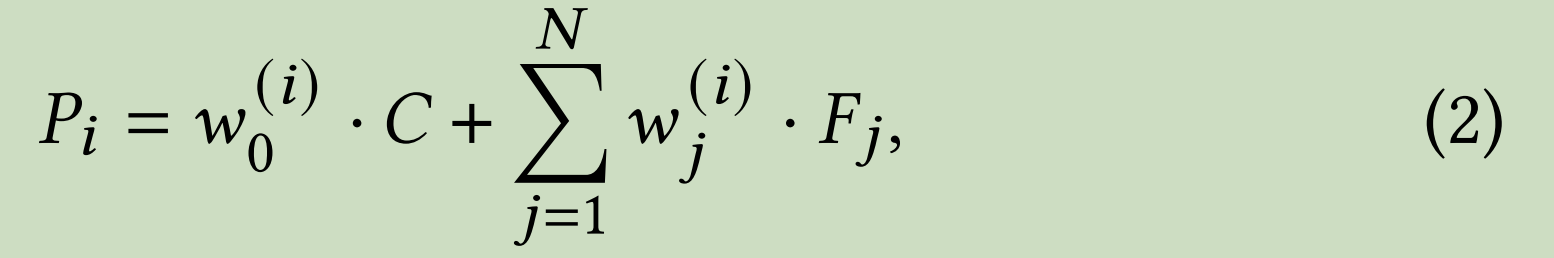
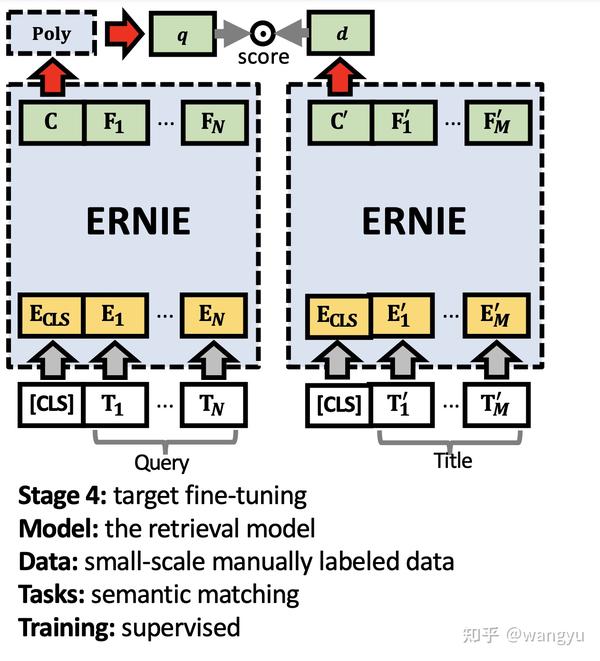
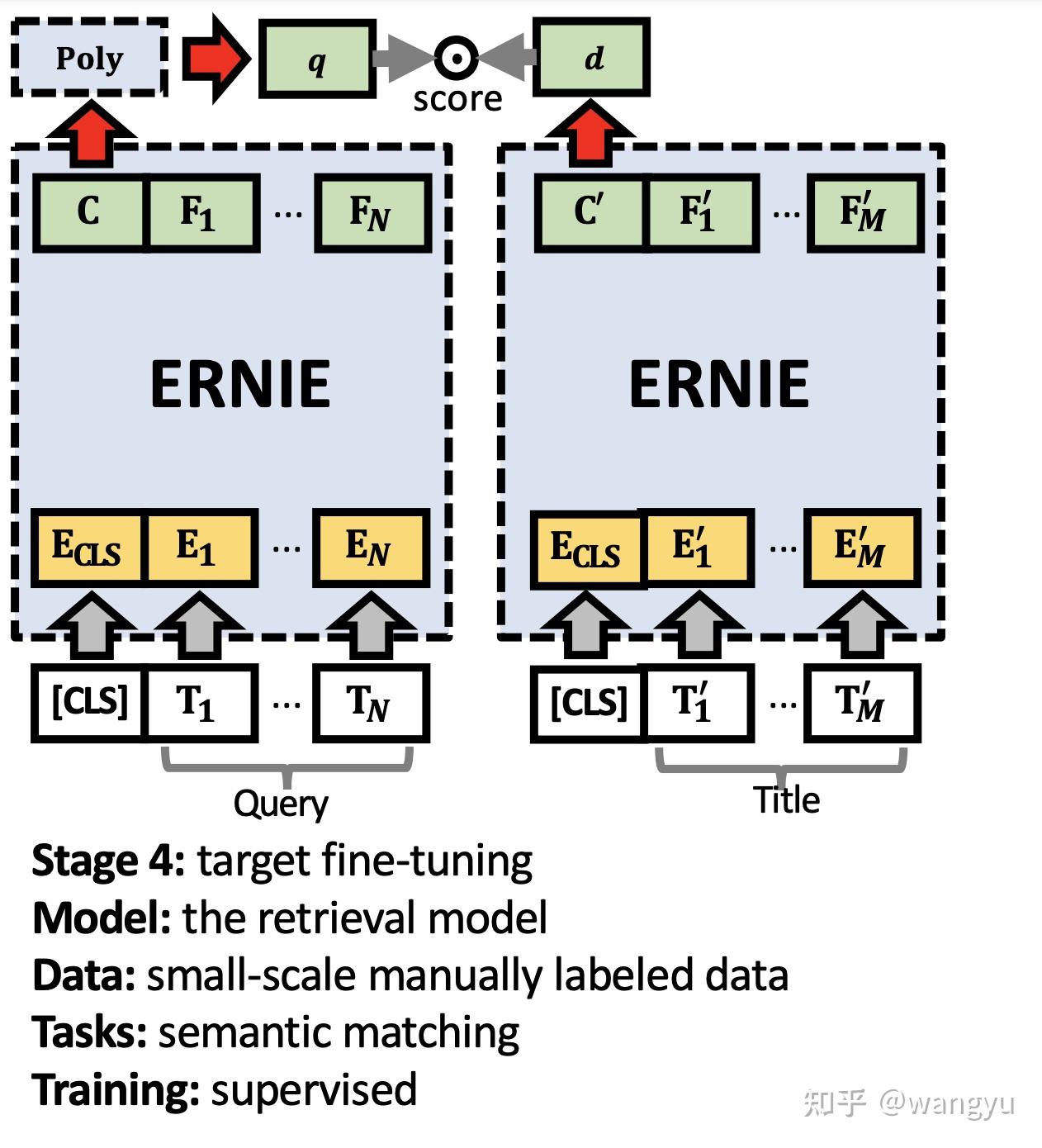
3.2 Model Architecture
bi-encoder,其中query和doc的transformer参数共享
poly attention,训练和预测的时候diff。其实就是训练的时候用max,于的时候先mean后compute 我认为是这样能够减少计算,提升效率
→ 为什么用mean而不是max?因为线上使用大规模检索工具依赖Faiss工具,不支持复杂计算
→ 什么是poly-encoder?
Train: 怀疑下图doc encoder中的En' 是不是写错了,应该是Em' ?
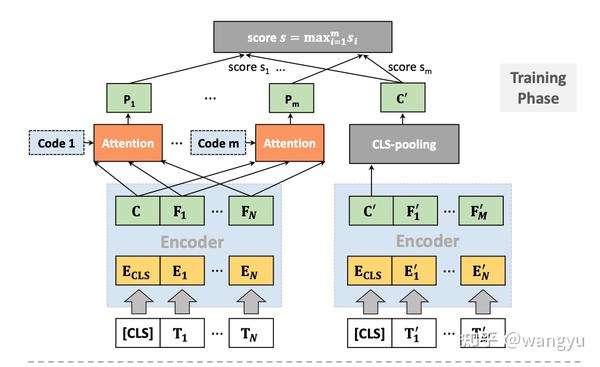
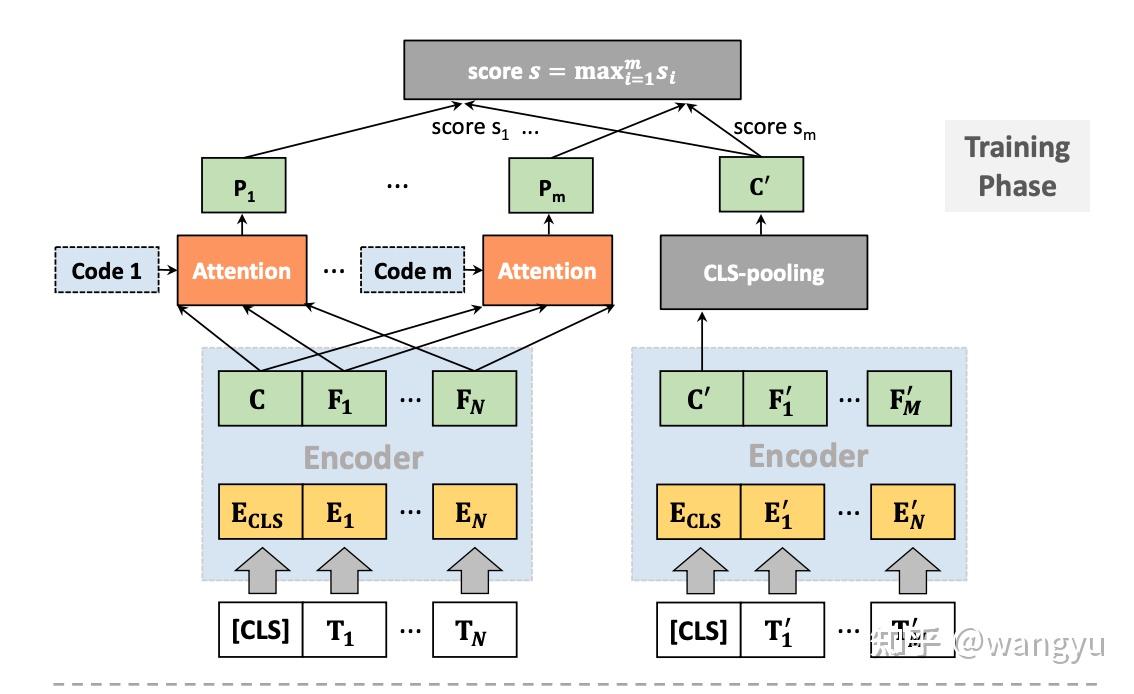
Predict:
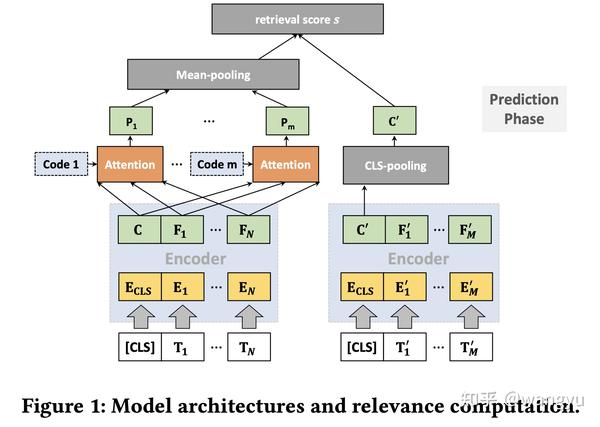
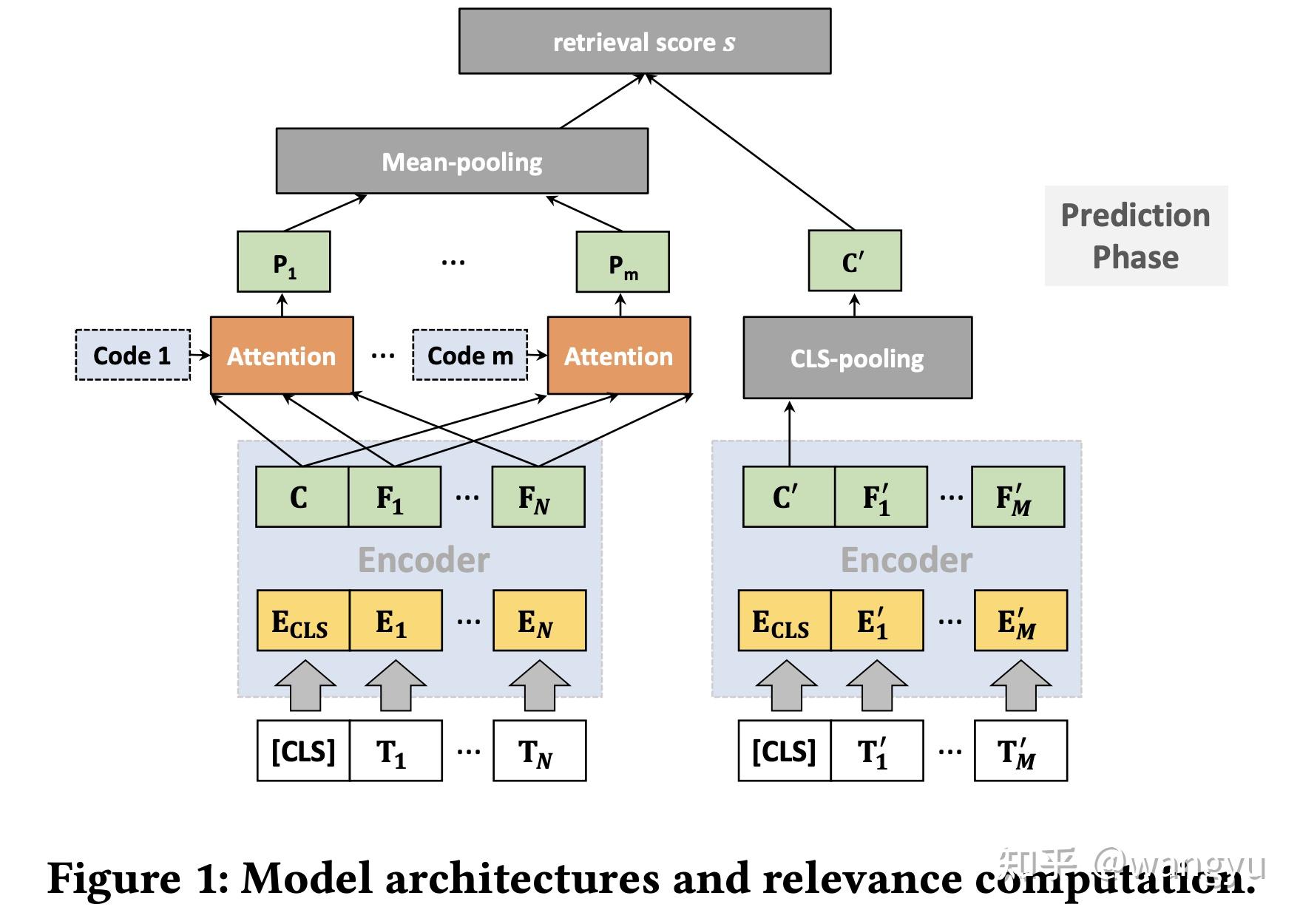
作者说此diff不会影响模型效果,具体Appendix做了实验验证
3.3 Optimization
理想方案
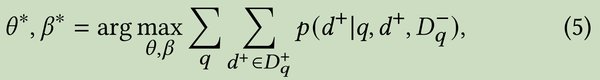
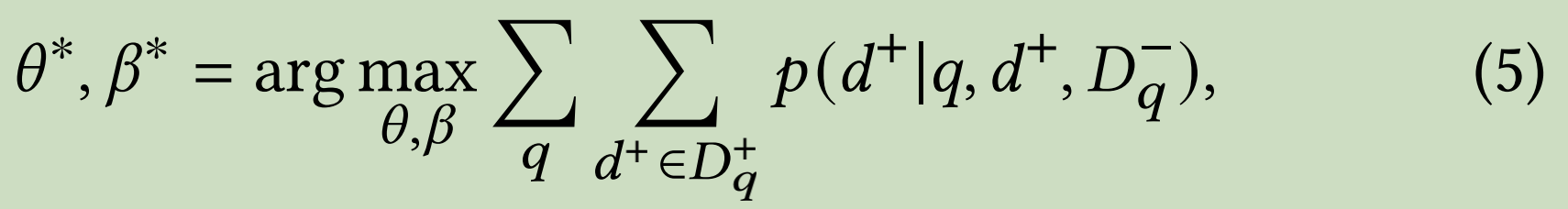

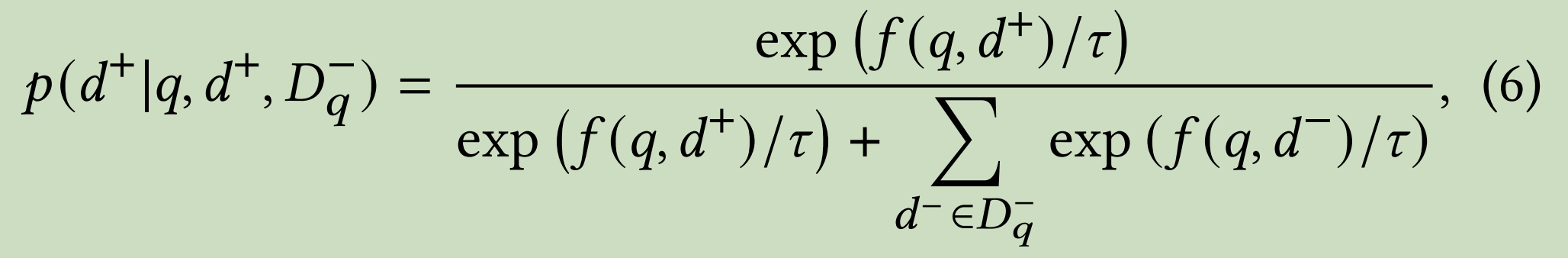
由于真实情况拿不到准确的Dq+,于是
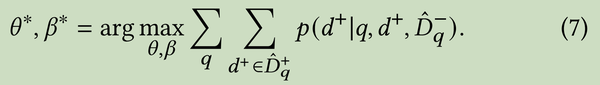
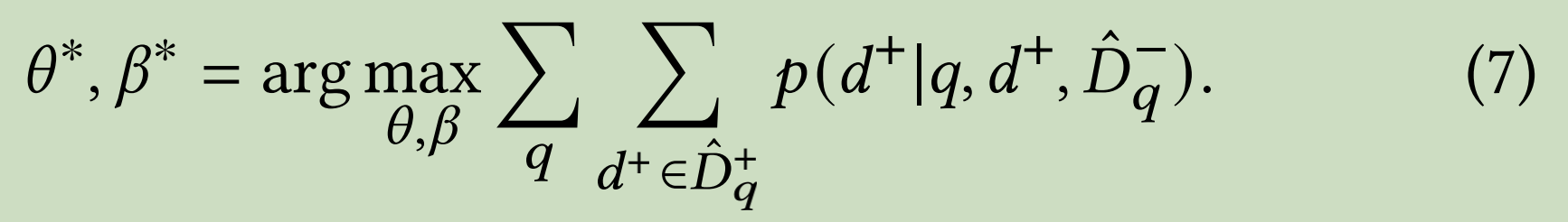
这是模型训练优化目标,问题难点就是如何sample 出训练的样本集合
3.4 Training Data Mining
主要是如何构建正样本集合和负样本集合。
Positives and negatives in different data sources
- 点展日志
- 人工标注数据
In-batch negative mining
relevant、strong negative、random negative
hardest_negative_loss_bul: Batch Uniform Loss(bul)
输入<q, d+, d-> 其中q表示query,d+表示与q相关的doc,反之d-表示与q不相关的doc。为了引入更多的负样本参与模型优化,所以采用batch内负采样,其中q1的负样本是q2....qn的正样本,所以每一个q有batch-1个负样本。基于此,进一步引入强负样本(d-),同理,q1的强负样本可以是q2的随机负样本,所以一个q含有2*batch-1的负样本。
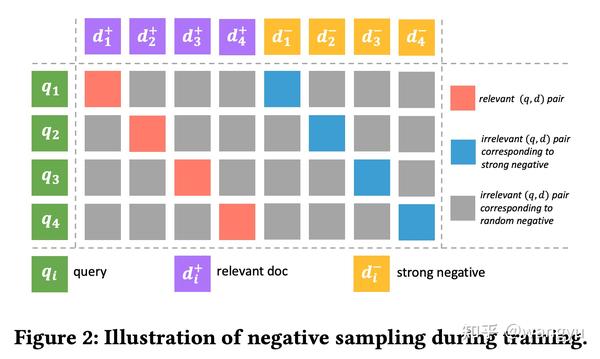
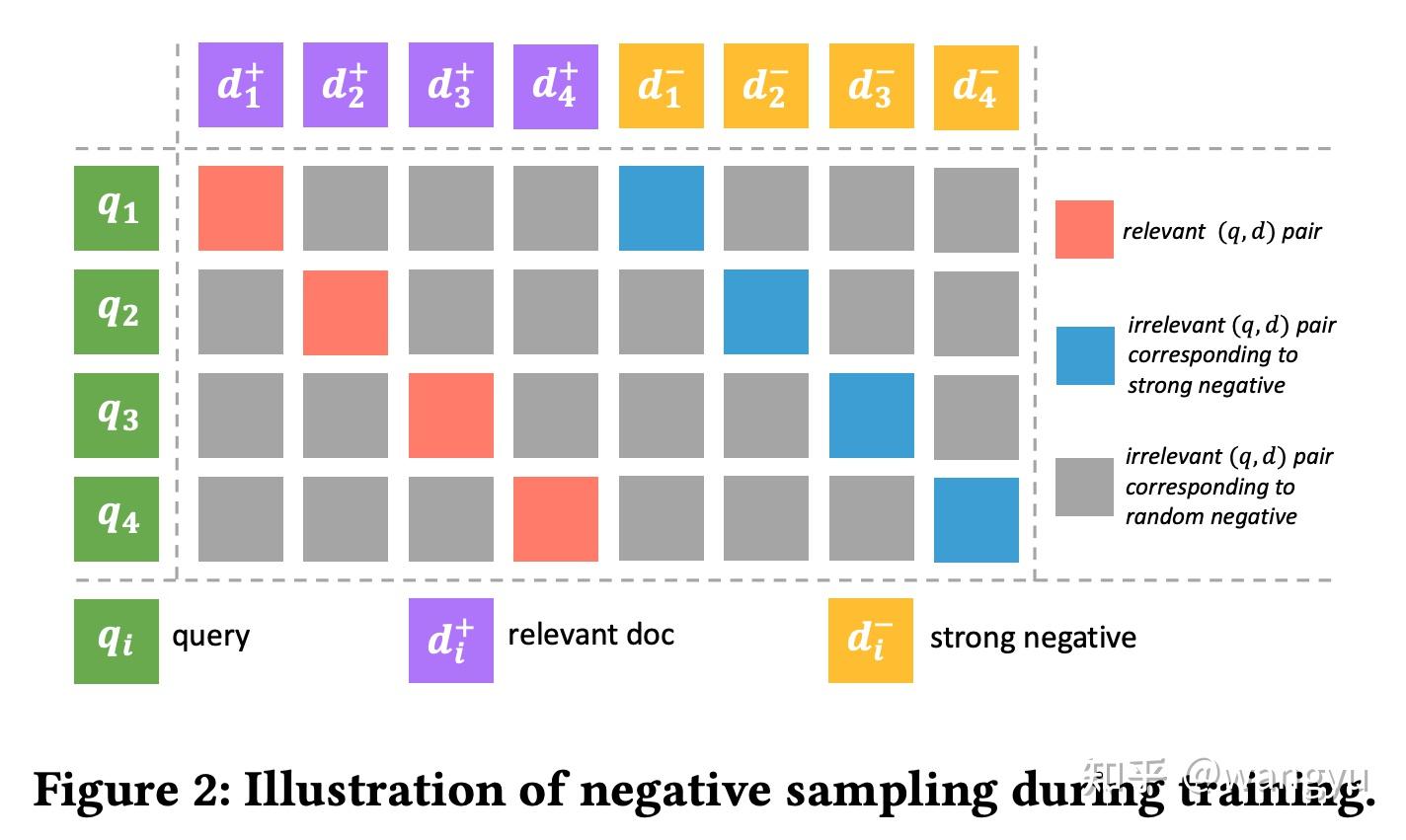
hardest_negative_loss_circle_random
输入<q, d+>,q表示query,d+表示与q相关的doc,batch内其他q对应的d+为负样本。计算q和负样本之间的分数,选择负样本中得分最高的样本最为最终负样本,然后计算circle loss。
4.Training Paradigm
4.1 Stage 1: Pretraining
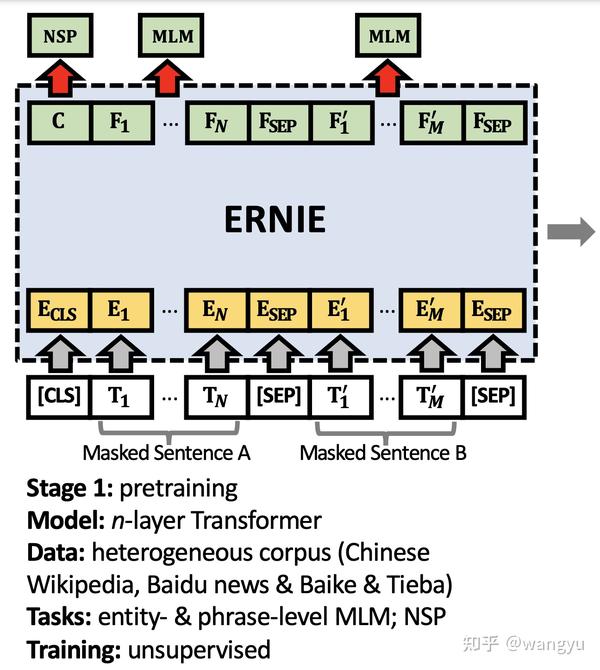
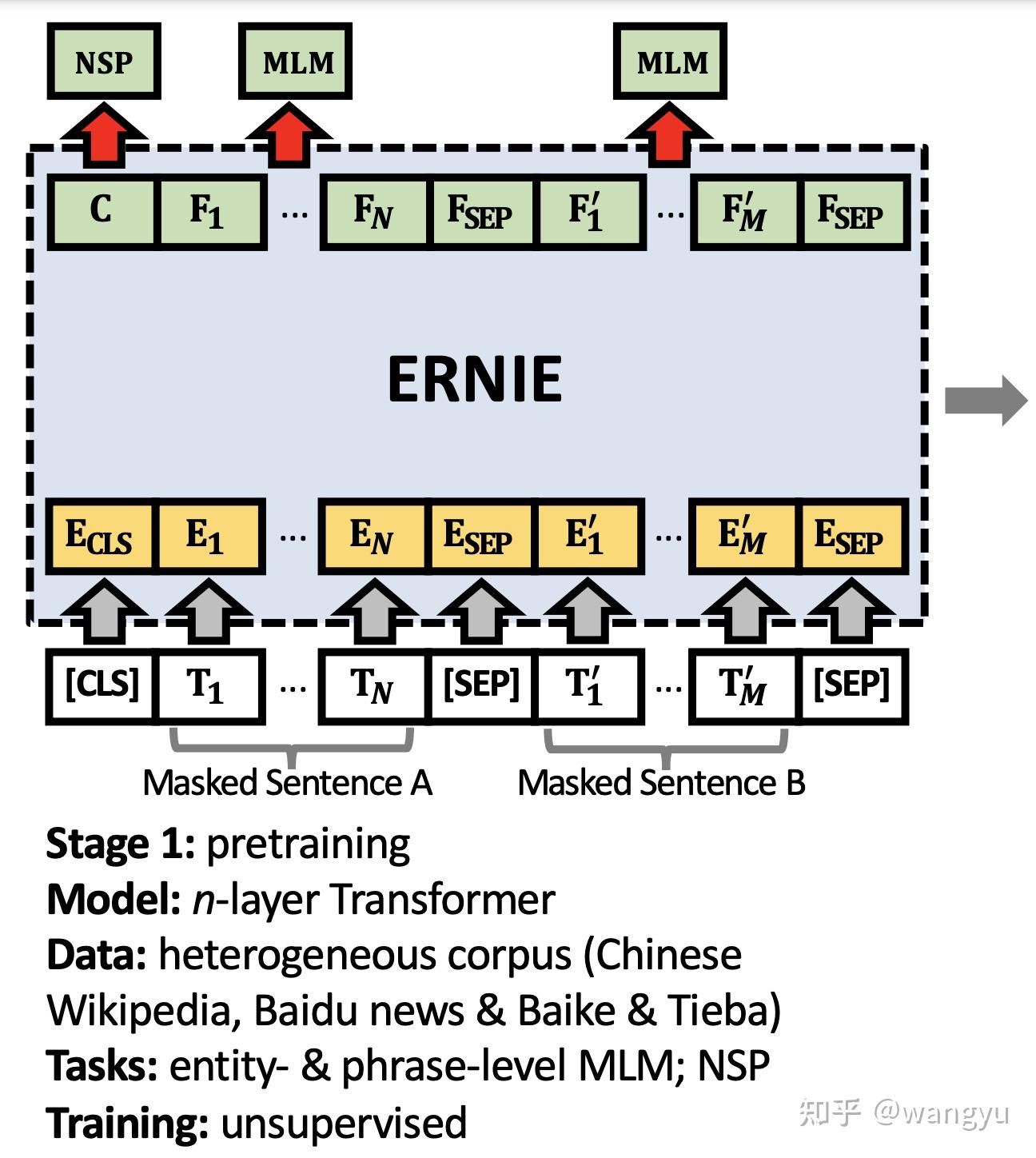
4.2 Stage 2: Post-pretraining
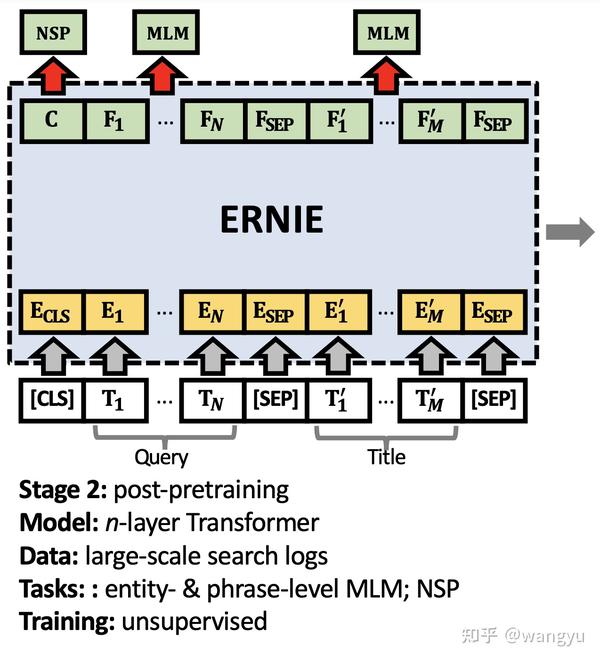
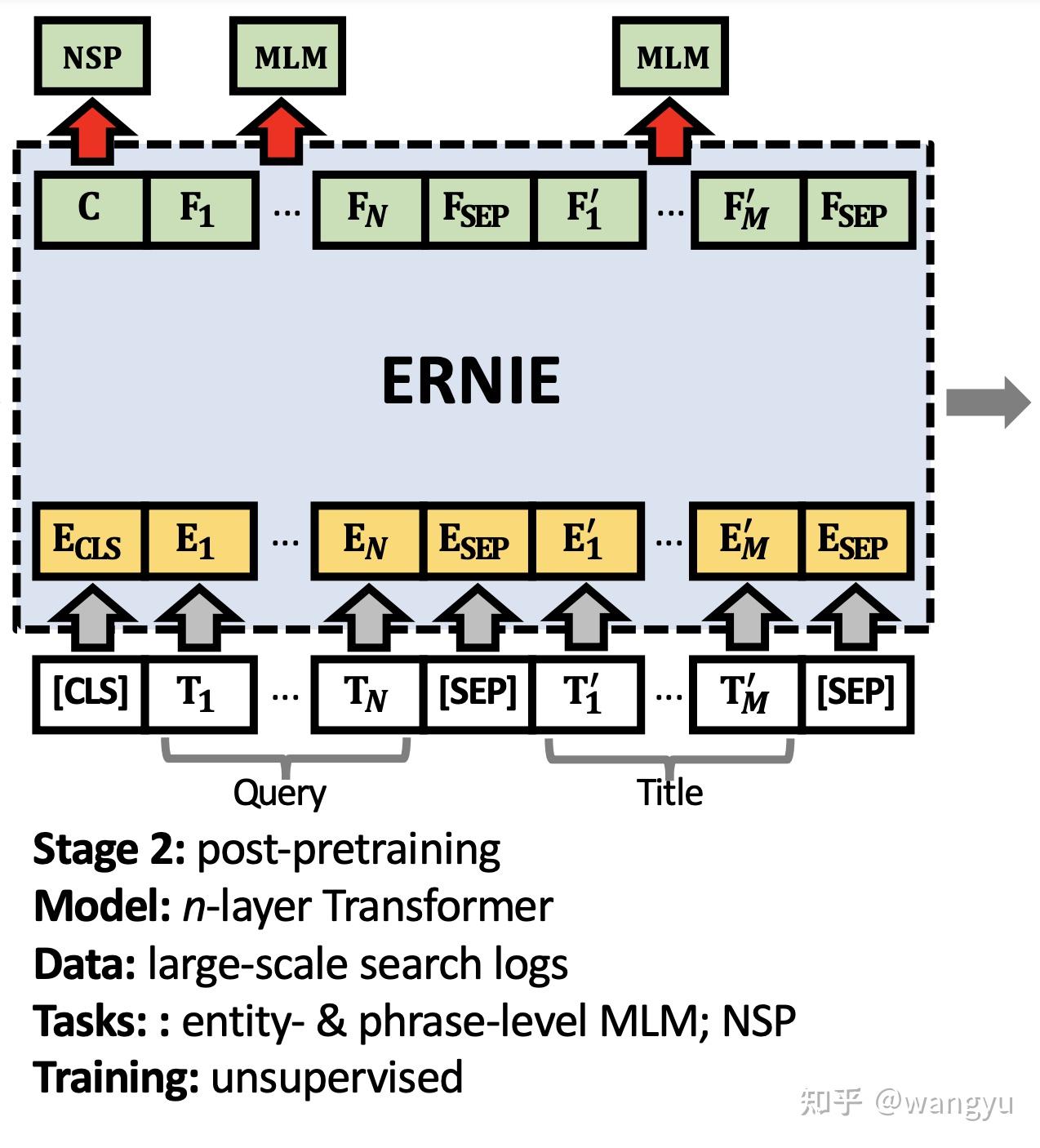
4.3 Stage 3: Intermediate Fine-tuning
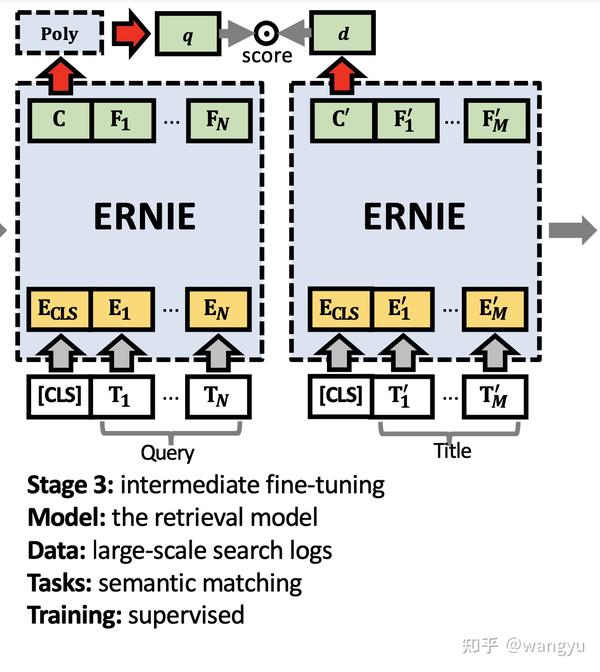
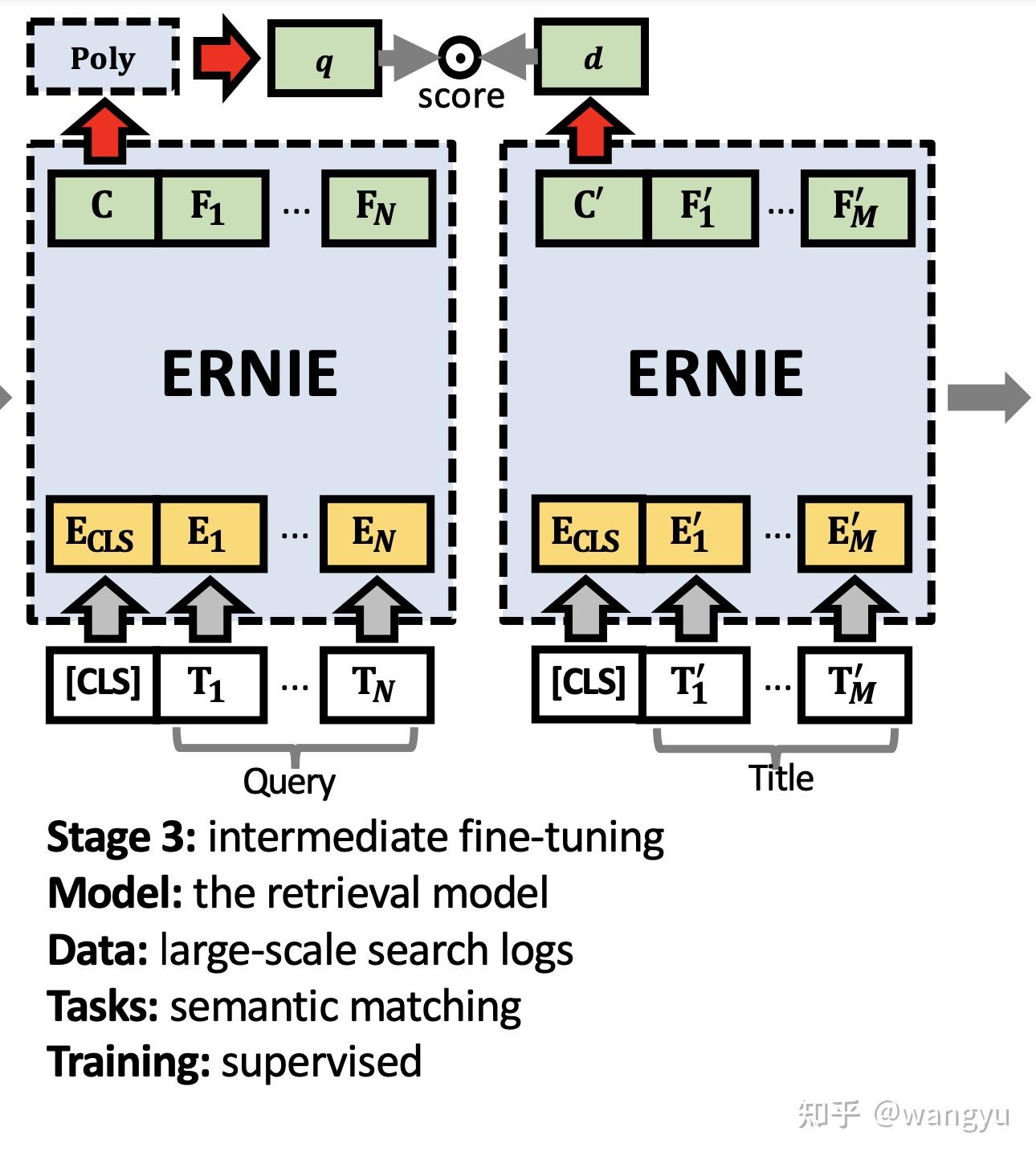
4.4 Stage 4: Target Fine-tuning
5.Deployment
5.1 Embedding Compression and Quantization
生成的embedding会经过压缩和量化作为最后的embedding
5.2 System Workflow
总览:
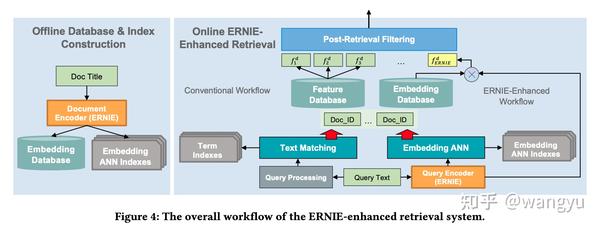
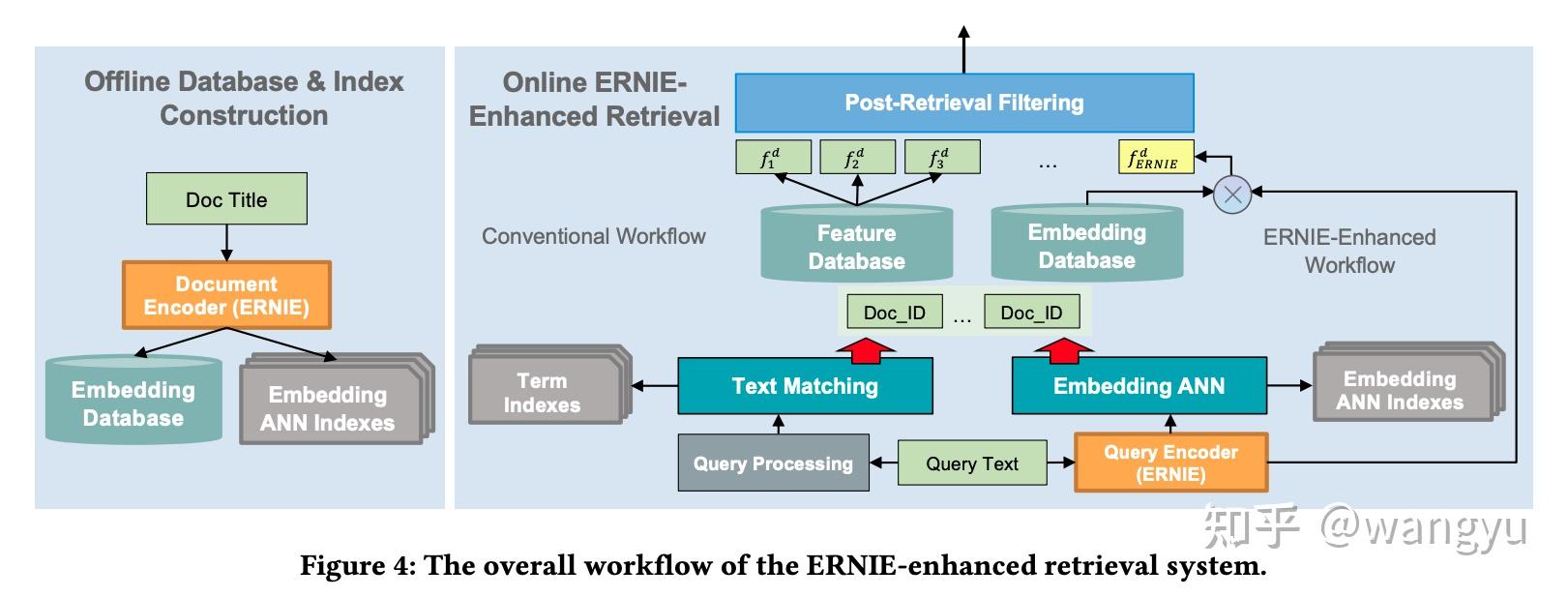
Offline database and index construction
线下建库时候计算好doc的embeddings,也为后续由文本匹配召回的doc填补ann-embedding,最终用于post-retrieval filtering。
Online integrated retrieval
两条通路:
- conventional retrieval
- the novel ERNIE-based semantic retrieval
Online post-retrieval filtering
两路召回merge并且过滤,一般采用GBRank或RankSVM。
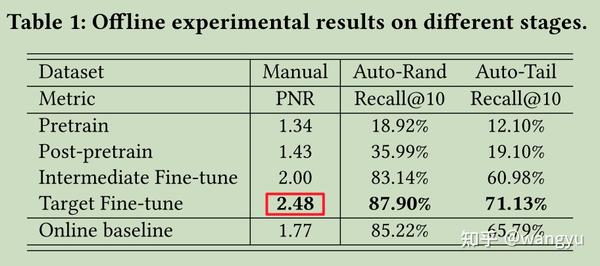
6.Offline Evaluation
离线指标
6.1 Datasets
Manually-labeled dataset (Manual)
人工标注query-doc相关性0-4
Automatic-annotated datasets (Auto)
随机+长冷
- 正样本:top-10结果
- 负样本:其他query下top-10结果。( 注:我认为这里有点问题,如果相似的query下top-10结果也应相似,那么这10条负样本中应该有正样本 )
6.2 Evaluation Metrics
Positive-Negative Ratio
PNR
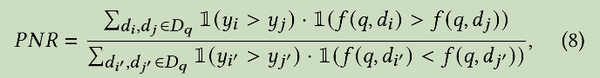
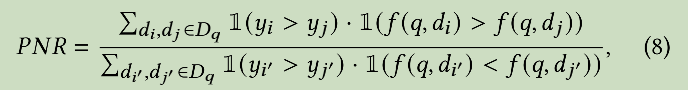
Recall@10
模型召回的top-10结果集合 交 真实样本集合 / 10
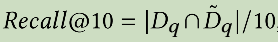
这里有些疑问, 真实样本集合是怎么圈选出来的?我觉得不如人工评估模型召回的top-10结果,统计召回的准确率?但是这样评估成本很高
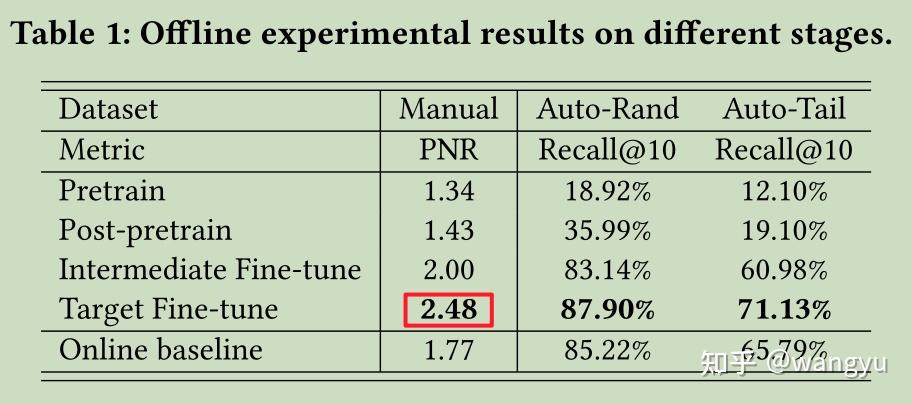
6.3 Offline Experimental Results
根据6.2设计的评估规则,经过实验如下:
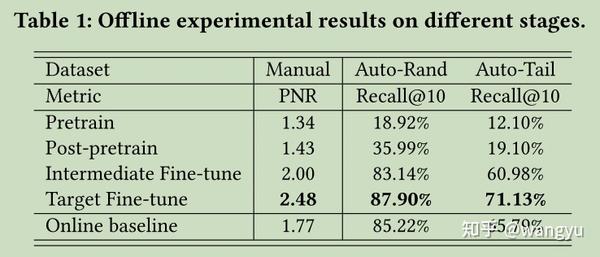
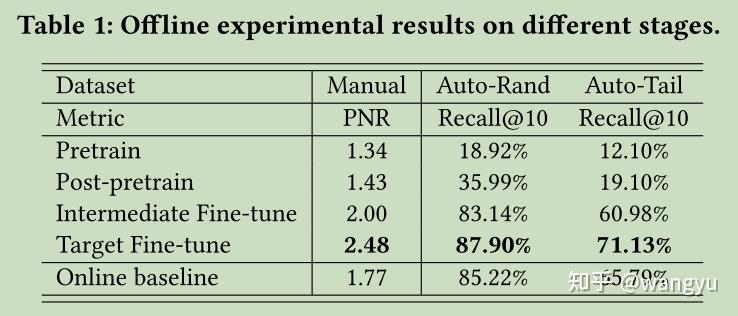
在长冷query效果较为显著。
7.Online Evalution
7.1 Interleaved Comparison
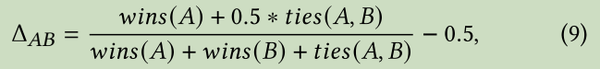
或者考虑加上停留时间权重:sigmoid(post-click dwell time)
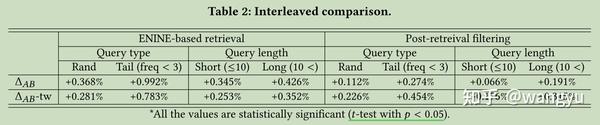
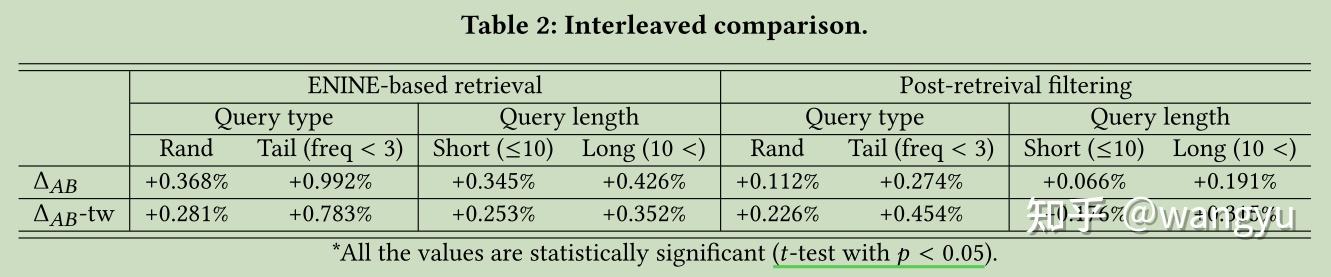
7.2 Online A/B Test
click behaviors:+0.31%
click-and-stay behavior:+0.57%
average postclick dwell time:+0.62%
click-through rate:+0.3%
7.3 Manual Evaluation for Online Cases
评估DCG和GSB
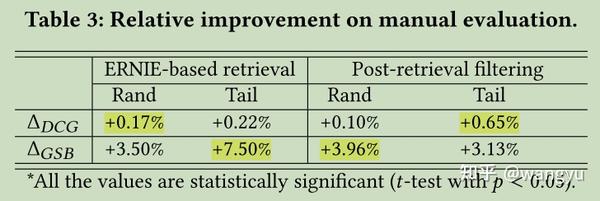
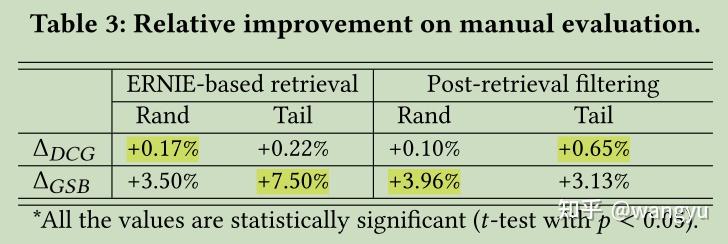
8.Conclusion
三点贡献。
9.Appendix
9.1 Implementation Details
Computation resources
- PaddlePaddle (version 1.6.2)
- pretrained and finetuned with 32 and 8 NVIDIA V100 GPUs (32GB Memory)
- an Adam optimizer
Parameter settings
- layer of transformer:6
- input embedding vector size:768
- hidden token representation dimensional(d_k):768
- multi-head of self-attention:12
- number of context codes:16
- compression d_k:256
- learning rate:2e-5
- batch size:160
- each training rate,warm up steps:4000
- decay rate:0.01
- dropout rate:0.1 → to drop the attention weights
- others:the same as vanilla ERNIE model
Implementations
放了一部分伪代码
in-batch random negative sampling via matrix multiplication
用了矩阵运算
9.2 Details of Embedding Quantization
作用:将向量表示由float32→uint8
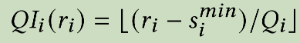
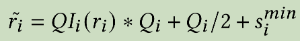
主要是说,
- 对于doc:可以降低storage cost,大约降低至1/4
- 对于query:可以降低transmission cost,因为query会经过多个模块处理,因此尽量保证传输成本低,降低至1/4
9.3 Offline Ablation Study
9.3.1 Comparison with vanilla bi-encoder
search log size:30w q-u pairs
对比vanilla ERNIE-based bi-encoder, our retrieval model:
- 引入 poly attention
- in-batch negative sampling strategy
- compression & quantization
- loss diff
- vanilla ..:hinge loss
- our ..:hardest_negative
实验结论:这些实验在训练的第3阶段后
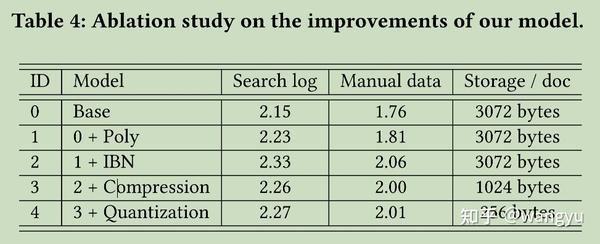
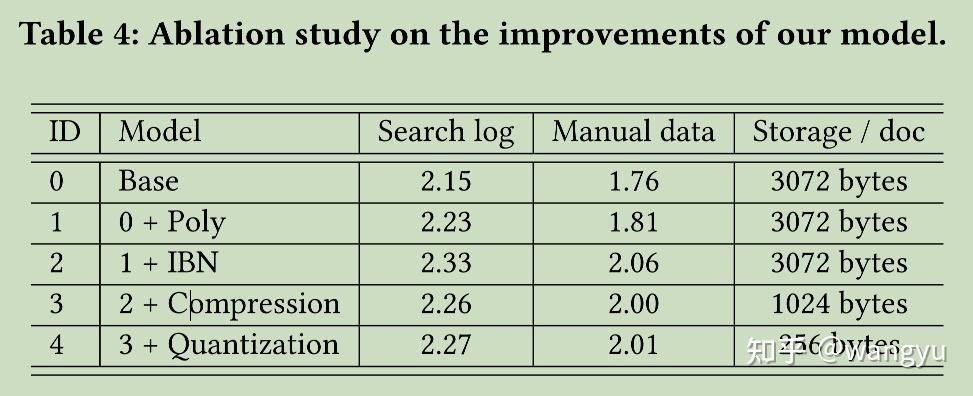
在正文中提到的,在训练4阶段后,
9.3.2 The training-prediction inconsistency

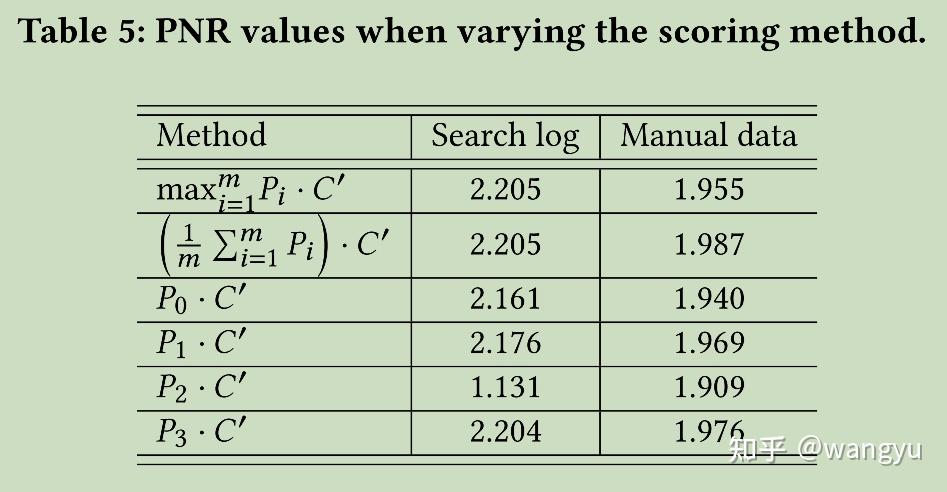
通过实验,认为训练取max和predict取mean的机制diff并不会对model效果带来不可接受的loss。
其中P0、P1、P2、P3是随机sample 从16个context codes。