-
导入,将准备生成模板的表进行导入
-
编辑,修改
基本信息
、字段信息、
生成信息
-
基本信息中修改作者!!!
-
字段信息按需调整
-
生成信息 - 自定义路径 D:\hzsj-frame\hz-frame\frame-knife4j\src
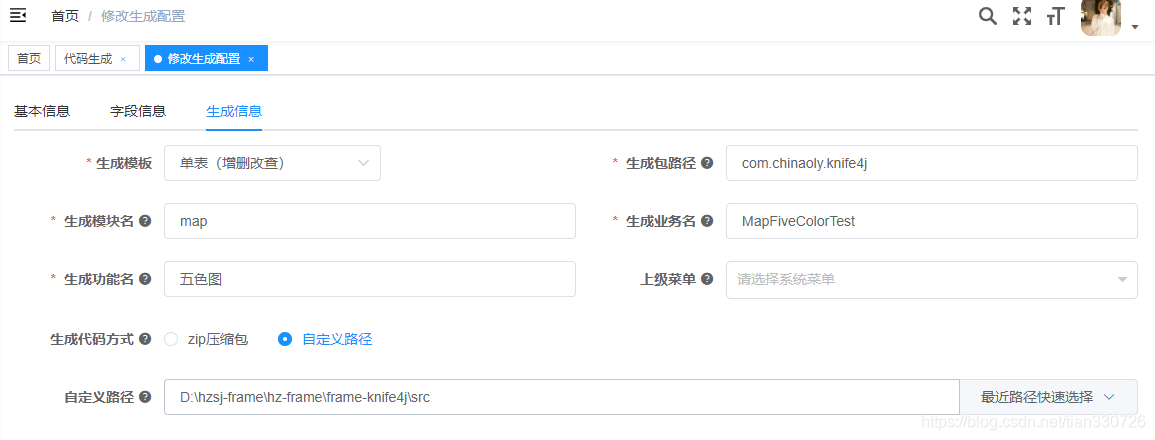
-
预览
-
生成代码
-
将自动生成的文件移动到对应的模块下(包)— 后期优化
-
后端代码中按照模块名进行分包生成
-
前端代码自动生成
主表:用户表 sys_user | 部门表 sys_dept | 角色表 sys_role | 岗位表 sys_post | 菜单表 sys_menu
关联表:用户角色表 sys_user_role | 用户岗位 sys_user_post | 角色部门表 sys_role_dept |角色菜单表sys_role_menu
参考:com.chinaoly.knife4j.controller.map.MapFiveColorController.getInfo
LoginUser loginUser = SecurityUtils.getLoginUser();
log.info("用户姓名:{}", loginUser.getUsername());
SysUser user = loginUser.getUser();
log.info("用户id:{}", user.getUserId());
log.info("用户身份证:{}", user.getIdCard());
SysDept dept = user.getDept();
log.info("部门层级:{}", dept.getLevel());
log.info("部门code:{}", dept.getDeptCode());
log.info("部门name:{}", dept.getDeptName());
knife4j 可以理解为swagger的升级版,详情见:官网
开发过程中主要将代码写在此包下!
整体项目的框架
com.chinaoly
├── common // 工具类
│ └── annotation // 自定义注解
│ └── config // 全局配置
│ └── constant // 通用常量
│ └── core // 核心控制
│ └── enums // 通用枚举
│ └── exception // 通用异常
│ └── filter // 过滤器处理
│ └── utils // 通用类处理
├── framework // 框架核心
│ └── aspectj // 注解实现
│ └── config // 系统配置
│ └── datasource // 数据权限
│ └── interceptor // 拦截器
│ └── manager // 异步处理
│ └── security // 权限控制
│ └── web // 前端控制
├── frame-generator // 代码生成
├── frame-quartz // 定时任务
├── frame-system // 系统代码
├── frame-admin // 后台服务
├── frame-knife4j // 接口调用
│ └── config // 系统配置
│ └── controller // 控制层
│ └── service // 业务逻辑层
│ └── mapper // 数据库操作层
│ └── domain // 实体对象层
│ ├─dto // 数据传输对象
│ ├─entity // 数据库对应的实体类
│ ├─param // 请求参数
│ ├─vo // 页面对象
具体逻辑 可看frame项目中有demo
注:param中可不加beginTime和endTime
<if test="params.beginTime != null and params.beginTime != ''">
and date_format(create_time,'%y%m%d') >= date_format(#{params.beginTime},'%y%m%d')</if>
<if test="params.endTime != null and params.endTime != ''">
and date_format(create_time,'%y%m%d') <= date_format(#{params.endTime},'%y%m%d')
参考官网https://doc.ruoyi.vip/ruoyi/document/htsc.html
前端实现:
queryParams: {
pageNum: 1,
pageSize: 10
后端实现:
@PostMapping("/list")
@ResponseBody
public TableDataInfo list(User user)
startPage();
List<User> list = userService.selectUserList(user);
return getDataTable(list);
* 设置请求分页数据
protected void startPage() {
PageDomain pageDomain = TableSupport.buildPageRequest();
Integer pageNum = pageDomain.getPageNum();
Integer pageSize = pageDomain.getPageSize();
if (StringUtils.isNotNull(pageNum) && StringUtils.isNotNull(pageSize)) {
String orderBy = SqlUtil.escapeOrderBySql(pageDomain.getOrderBy());
PageHelper.startPage(pageNum, pageSize, orderBy);
- 参数对象user中不需要添加pageNum、pageSize,orderBy对象也是同理。前端传入后,startPage中会自动接收,PageHelper会在sql中进行分页;
- startPage(),只会对第一个查询
(Select)语句得到的数据进行分页,栗子在官方文档中有说明; - 当service中需要分页时,继承BaseServiceImpl,调用startPage()方法
- 开发中会有遇到 一个select查询语句无法实现逻辑的情况【如要将两个查询的list进行排序或处理逻辑后分页展示】,则需要手动分页,即手动构建pageInfo对象;
https://mybatis.plus/guide/
例子:https://blog.csdn.net/tian330726/article/details/106087857
├── common // 工具类
│ └── annotation // 自定义注解
│ └── config // 全局配置
│ └── constant // 通用常量
│ └── core // 核心控制
│ └── enums // 通用枚举
:page.sync="queryParams.pageNum"
:limit.sync="queryParams.pageSize"
@pagination="getList...
分页的效果:分页处理一方面可以提高我们浏览数据的效率,符合我们浏览者的心理,减少了大量数据存在的杂乱问题;另一方面用sql进行数据查询时就实现分页,如mysql的limit,sql查询结果是第几页的数据,十分的效率;同时分页技术也可以,降低带宽使用,提高访问速度。分页的原理:前端采用参数pageNum 和pageSize;后端采用函数startPage 和getDataTable;后端分页原理的原理简析:先使用count(0)查询数据总数,再在查询语句之后加上LIMIT指令进行筛选。

