获取数据 n 个 m 维的数据
随机生成 K 个 m 维的点
while(t)
for(int i=0;i < n;i++)
for(int j=0;j < k;j++)
计算点 i 到类 j 的距离
for(int i=0;i < k;i++)
1. 找出所有属于自己这一类的所有数据点
2. 把自己的坐标修改为这些数据点的中心点坐标
时间复杂度: ,其中,t 为迭代次数,k 为簇的数目,n 为样本点数,m 为样本点维度。
,其中,t 为迭代次数,k 为簇的数目,n 为样本点数,m 为样本点维度。
空间复杂度: ,其中,k 为簇的数目,m 为样本点维度,n 为样本点数。
,其中,k 为簇的数目,m 为样本点维度,n 为样本点数。
2. 优缺点
2.1. 优点
- 容易理解,聚类效果不错,虽然是局部最优, 但往往局部最优就够了;
- 处理大数据集的时候,该算法可以保证较好的伸缩性;
- 当簇近似高斯分布的时候,效果非常不错;
- 算法复杂度低。
2.2. 缺点
- K 值需要人为设定,不同 K 值得到的结果不一样;
- 对初始的簇中心敏感,不同选取方式会得到不同结果;
- 对异常值敏感;
- 样本只能归为一类,不适合多分类任务;
- 不适合太离散的分类、样本类别不平衡的分类、非凸形状的分类。
3. 算法调优与改进
针对 K-means 算法的缺点,我们可以有很多种调优方式:如数据预处理(去除异常点),合理选择 K 值,高维映射等。以下将简单介绍:
3.1. 数据预处理
K-means 的本质是基于欧式距离的数据划分算法,均值和方差大的维度将对数据的聚类产生决定性影响。所以未做归一化处理和统一单位的数据是无法直接参与运算和比较的。常见的数据预处理方式有:数据归一化,数据标准化。
此外,离群点或者噪声数据会对均值产生较大的影响,导致中心偏移,因此我们还需要对数据进行异常点检测。
3.2. 合理选择K值
K 值的选取对 K-means 影响很大,这也是 K-means 最大的缺点,常见的选取 K 值的方法有:手肘法、Gap statistic 方法。
当 K < 3 时,曲线急速下降;当 K > 3 时,曲线趋于平稳,通过手肘法我们认为拐点 3 为 K 的最佳值。
手肘法的缺点在于需要人工看不够自动化,所以我们又有了 Gap statistic 方法,这个方法出自斯坦福大学的几个学者的论文:Estimating the number of clusters in a data set via the gap statistic
其中 为损失函数,这里
为损失函数,这里 指的是
指的是 的期望。这个数值通常通过蒙特卡洛模拟产生,我们在样本里所在的区域中按照均匀分布随机产生和原始样本数一样多的随机样本,并对这个随机样本做 K-Means,从而得到一个 。如此往复多次,通常 20 次,我们可以得到 20 个 。对这 20 个数值求平均值,就得到了的近似值。最终可以计算 Gap Statisitc。而 Gap statistic 取得最大值所对应的 K 就是最佳的 K。
的期望。这个数值通常通过蒙特卡洛模拟产生,我们在样本里所在的区域中按照均匀分布随机产生和原始样本数一样多的随机样本,并对这个随机样本做 K-Means,从而得到一个 。如此往复多次,通常 20 次,我们可以得到 20 个 。对这 20 个数值求平均值,就得到了的近似值。最终可以计算 Gap Statisitc。而 Gap statistic 取得最大值所对应的 K 就是最佳的 K。
由图可见,当 K=3 时,Gap(K) 取值最大,所以最佳的簇数是 K=3。
Github 上一个项目叫 gap_statistic ,可以更方便的获取建议的类簇个数。
3.3. 采用核函数
基于欧式距离的 K-means 假设了了各个数据簇的数据具有一样的的先验概率并呈现球形分布,但这种分布在实际生活中并不常见。面对非凸的数据分布形状时我们可以引入核函数来优化,这时算法又称为核 K-means 算法,是核聚类方法的一种。核聚类方法的主要思想是通过一个非线性映射,将输入空间中的数据点映射到高位的特征空间中,并在新的特征空间中进行聚类。非线性映射增加了数据点线性可分的概率,从而在经典的聚类算法失效的情况下,通过引入核函数可以达到更为准确的聚类结果。
3.4. K-means++
我们知道初始值的选取对结果的影响很大,对初始值选择的改进是很重要的一部分。在所有的改进算法中,K-means++ 最有名。
K-means++ 算法步骤如下所示:
- 随机选取一个中心点
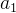 ;
; - 计算数据到之前 n 个聚类中心最远的距离
 ,并以一定概率
,并以一定概率 选择新中心点
选择新中心点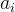 ;
; - 重复第二步。
简单的来说,就是 K-means++ 就是选择离已选中心点最远的点。这也比较符合常理,聚类中心当然是互相离得越远越好。
但是这个算法的缺点在于,难以并行化。所以 k-means II 改变取样策略,并非按照 k-means++ 那样每次遍历只取样一个样本,而是每次遍历取样 k 个,重复该取样过程log(n)次,则得到klog(n)个样本点组成的集合,然后从这些点中选取 k 个。当然一般也不需要log(n)次取样,5 次即可。
3.5. ISODATA
ISODATA 的全称是迭代自组织数据分析法。它解决了 K 的值需要预先人为的确定这一缺点。而当遇到高维度、海量的数据集时,人们往往很难准确地估计出 K 的大小。ISODATA 就是针对这个问题进行了改进,它的思想也很直观:当属于某个类别的样本数过少时把这个类别去除,当属于某个类别的样本数过多、分散程度较大时把这个类别分为两个子类别。
4. 收敛证明
我们先来看一下 K-means 算法的步骤:先随机选择初始节点,然后计算每个样本所属类别,然后通过类别再跟新初始化节点。这个过程有没有想到之前介绍的 EM 算法 。
我们需要知道的是 K-means 聚类的迭代算法实际上是 EM 算法。EM 算法解决的是在概率模型中含有无法观测的隐含变量情况下的参数估计问题。在 K-means 中的隐变量是每个类别所属类别。K-means 算法迭代步骤中的 每次确认中心点以后重新进行标记 对应 EM 算法中的 E 步 求当前参数条件下的 Expectation 。而 根据标记重新求中心点 对应 EM 算法中的 M 步 求似然函数最大化时(损失函数最小时)对应的参数 。
首先我们看一下损失函数的形式:
为了求极值,我们令损失函数求偏导数且等于 0:
k 是指第 k 个中心点,于是我们有:
可以看出,新的中心点就是所有该类的质心。
EM 算法的缺点就是,容易陷入局部极小值,这也是 K-means 有时会得到局部最优解的原因。
5. 开源库
5.1. sklearn
import pandas as pd
# 参数初始化
inputfile = r'F:\...\consumption_data.xls' # 销量及其他属性数据
outputfile = r'F:\...\data_type.xls' # 保存结果的文件名
k = 3 # 聚类的类别
iteration = 500 # 聚类最大循环次数
data = pd.read_excel(inputfile, index_col = 'Id') # 读取数据
data_zs = 1.0*(data - data.mean())/data.std() # 数据标准化
from sklearn.cluster import KMeans
model = KMeans(n_clusters = k, n_init = 4, max_iter = iteration,random_state=1234) # 分为k类,并发数4
model.fit(data_zs) # 开始聚类
# 简单打印结果
r1 = pd.Series(model.labels_).value_counts() # 统计各个类别的数目
r2 = pd.DataFrame(model.cluster_centers_) # 标准化数据的聚类中心
r2.columns=data.mean().index #修改r2的列,方便逆标准化计算
r_1 = pd.concat([r2*data.std()+data.mean(), r1], axis = 1) # 横向连接(0是纵向),得到聚类中心对应的类别下的数目
r_1.columns = list(data.columns) + ['类别数目'] # 重命名表头
print(r_1)
# 详细输出原始数据及其类别
r = pd.concat([data, pd.Series(model.labels_, index = data.index)], axis = 1) # 详细输出每个样本对应的类别
r.columns = list(data.columns) + ['聚类类别'] # 重命名表头
# r.to_excel(outputfile) # 保存结果
#同时保存两个结果到xls中
with pd.ExcelWriter(outputfile) as writer: # doctest: +SKIP
r_1.to_excel(writer, sheet_name='聚类中心及数目')
r.to_excel(writer, sheet_name='原始数据聚类类别')
def density_plot(data): # 自定义作图函数
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
p = data.plot(kind='kde', linewidth = 2, subplots = True, sharex = False)
[p[i].set_ylabel('密度') for i in range(k)]
plt.legend()
plt.tight_layout()
return plt
pic_output = r'F:\...\分群'
# 概率密度图文件名前缀
for i in range(k):
density_plot(data[r['聚类类别']==i]).savefig('%s%s.png' %(pic_output, i+1))
5.2. pyclustering
from pyclustering.cluster.kmeans import kmeans
from pyclustering.utils.metric import type_metric, distance_metric
user_function = lambda point1, point2: point1[0] + point2[0] + 2
metric = distance_metric(type_metric.USER_DEFINED, func=user_function)
# create K-Means algorithm with specific distance metric
start_centers = [[4.7, 5.9], [5.7, 6.5]];
kmeans_instance = kmeans(sample, start_centers, metric=metric)
# run cluster analysis and obtain results
kmeans_instance.process()
clusters = kmeans_instance.get_clusters()
【机器学习】K-means(非常详细) - 知乎
K-means聚类算法-CSDN博客
K-means聚类自定义距离计算的开源算法选择_小小她爹的博客-CSDN博客
K-means 是我们最常用的基于欧式距离的聚类算法,其认为两个目标的距离越近,相似度越大。本文大致思路为:先介绍经典的牧师-村名模型来引入 K-means 算法,然后介绍算法步骤和时间复杂度,通过介绍其优缺点来引入算法的调优与改进,最后我们利用之前学的 EM 算法,对其进行收敛证明。
AtCoder Beginner Contest 178 E 题,https://atcoder.jp/contests/abc178/tasks/abc178_e。
Problem Statement
There are N points on the 2D plane, i-th of which is located on (xi,yi). There can be multiple points that share the same coordinate. What i
聚类算法(Clustering Algorithms)常用于进行非监督学习(unsupervised learning),即它处理的是没有事先标记分类的数据。一共介绍五种常见聚类算法:
K-means
Hierarchical
DBSCAN(基于密度的聚类算法)
基于网格Grid的聚类算法
在了解聚类算法如何实现之前,需要先了解几种常见的距离计算公式,因为聚类算法会通过距离判断两...
在许多领域的研究与应用中,通常需要对含有多个变量的数据进行观测,收集大量数据后进行分析寻找规律。多变量大数据集无疑会为研究和应用提供丰富的信息,但是也在一定程度上增加了数据采集的工作量。更重要的是在很多情形下,许多变量之间可能存在相关性,从而增加了问题分析的复杂性。如果分别对每个指标进行分析,分析往往是孤立的,不能完全利用数据中的信息,因此盲目减少指标会损失很多有用的信息,从而产生错误的结论。
因此需要找到一种合理的方法,在减少需要分析的指标同时,尽量减少原指标包含信息的损失,以达到对所收集数据进行全面

