

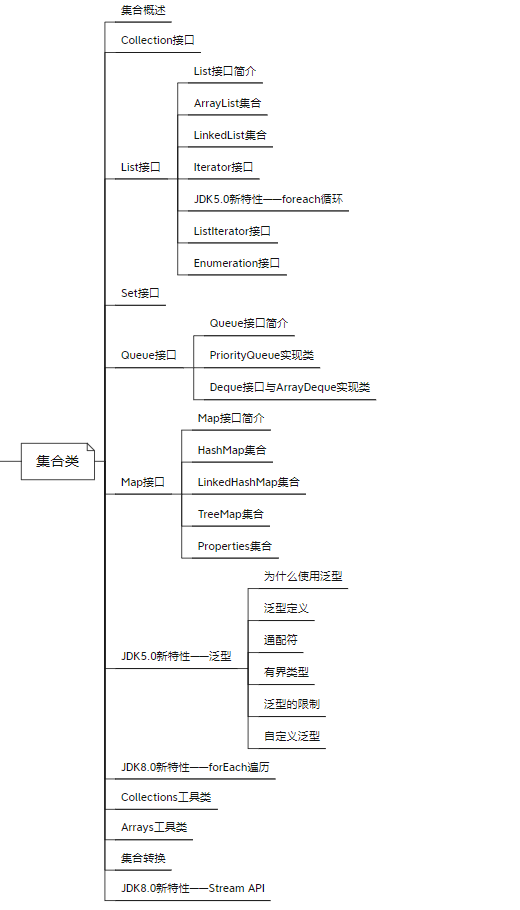
Java语言程序设计— Java中集合类的使用—集合概述、Collection接口、List接口、Set、Queue接口、Map接口、JDK5.0新特性、JDK8.0新特性

已经介绍了Java基础类库( Java语言程序设计— Java基础类库—System类与Runtime类、Math类与Random类、日期操作类、JDK7.0新特性——switch语句支持字符串类型 ),在Java开发过程中,经常需要集中存放多条数据。数据通常使用数组来保存。但在某种情况下无法确认到底需要保存多少个对象,例如,一个餐厅要统计财务信息,由于餐厅不停地有财务存入,同时餐厅也有财务支出,这时餐厅的财务信息将很难确定。为了保存这些数目不确定的对象,JDK中提供了一系列特殊的类,这些类可以存储任意类型的对象,并且长度可变,统称为集合,将带领大家学习Java中集合类的使用。

Ø 集合概述
集合类就像容器,现实生活中容器的功能,无非就是添加对象、删除对象、清空容器、判断容器是否为空等,集合类就为这些功能提供了对应的方法。
java.util包中提供了一系列可使用的集合类,称为集合框架。集合框架主要是由Collection和Map两个根接口派生出来的接口和实现类组成,如图所示。
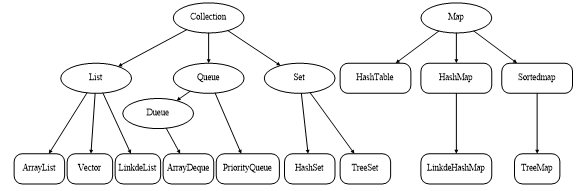
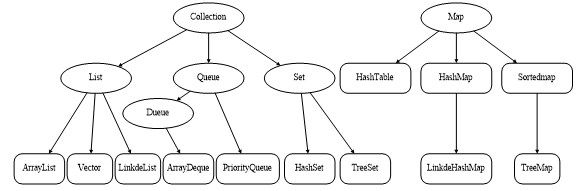
图中,椭圆区域中填写的都是接口类型,其中,List、Set和Queue是Collection的子接口。其中,List集合像一个数组,它可以记住每次添加元素的顺序,元素可以重复,不同于数组的是List的长度可变;Set集合像一个盒子,把一个对象添加到Set集合时,Set集合无法记住这个元素的顺序,所以Set集合中的元素不能重复;Queue集合就像现实中的排队一样,先进先出;Map集合也像一个盒子,但是它里面的每项数据都是成对出现的,由键-值(key-value)对形式组成。
Ø Collection接口
Collction 接口是 List、Set和Queue等接口的父接口,该接口里定义的方法既可用于操作List集合,也可用于操作Set和Queue集合。Collection接口里定义了一系列操作集合元素的方法。如表所示。
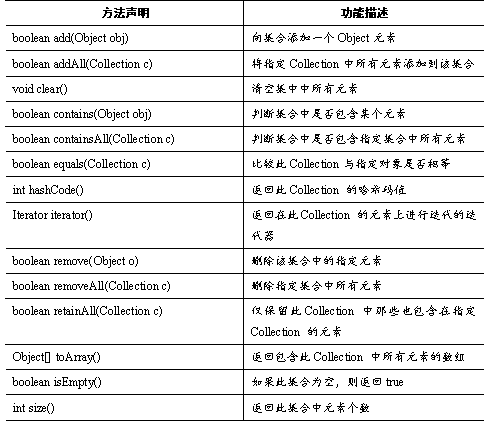
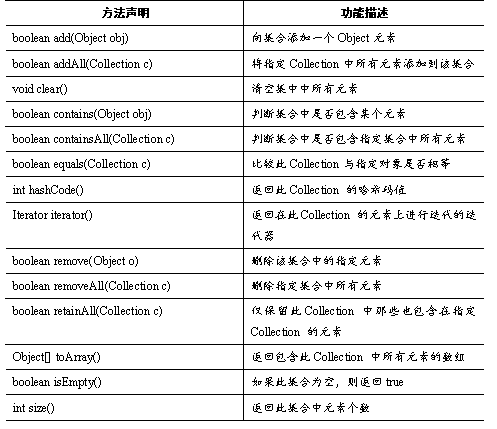
表中列出了Collection的方法,下面通过一个案例来学习这些方法的使用,如例所示。


程序的运行结果如图所示。
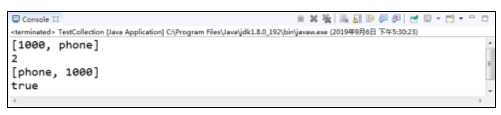
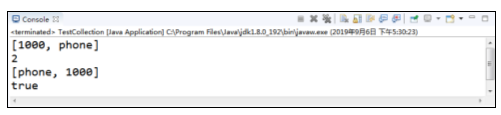
在例中,创建了两个Collection对象,一个是coll,一个是coll1,其中,coll是实现类ArrayList的实例,而coll1是实现类HashSet的实例,虽然它们实现类不同,但都可以把它们当成Collection来使用,都可以使用add方法给它们添加元素,这里使用了Java的多态性。
从运行结果可以看出,Collection实现类都重写了toString()方法,一次性输出了集合中的所有元素。
脚下留心
在编写代码时,不要忘记使用“import java.util.*;”导包语句,否则程序会编译失败,显示无法解析类型,如图所示。


List接口
Ø List接口简介
List集合中元素是有序的且可重复的,相当于数学里面的数列,有序可重复。使用此接口能够精确地控制每个元素插入的位置,用户可以通过索引来访问集合中的指定元素,List集合还有一个特点就是元素的存入顺序与取出顺序相一致。
List接口中大量地扩充了Collection接口,拥有了比Collection接口中更多的方法定义,其中有些方法还比较常用。如表所示。
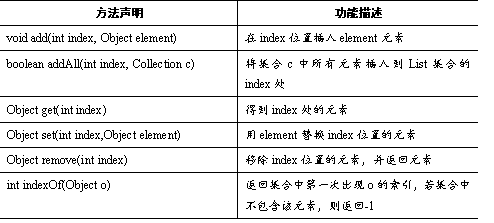
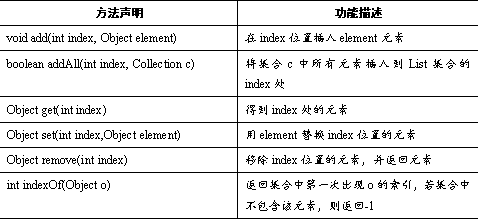
表中列出了List接口的常用方法,所有的List实现类都可以通过调用这些方法对集合元素进行操作。
Ø ArrayList集合
ArrayList 是List的主要实现类,它是一个数组队列,相当于动态数组。与Java中的数组相比,它的容量能动态增长。它继承于AbstractList,实现了List接口,提供了相关的添加、删除、修改、遍历等功能。
ArrayList集合中大部分方法都是从父类Collection和List继承过来的,其中,add()方法和get()方法用于实现元素的存取,接下来通过一个案例来学习ArrayList集合如何存取元素。如例所示。


程序的运行结果如图所示。


在例中,首先创建一个ArrayList集合,然后向集合中添加了两个元素,调用size()方法打印出集合元素的个数,又调用get(int index)方法得到集合中索引为0的元素,也就是第一个元素,并打印出来。这里的索引下标是从0开始,最大的索引是size-1,若取值超出索引范围,则会报IndexOutOfBoundsException异常。
ArrayList底层是用数组来保存元素,用自动扩容的机制实现动态增加容量,因为它底层是用数组实现,所以插入和删除操作效率不佳,不建议用ArrayList做大量增删操作,但由于它有索引,所以查询效率很高,适合做大量查询操作。
Ø LinkedList集合
前面提到ArrayList在处理增加和删除操作时效率较低,为了解决这一问题,可以使用List接口的LinkedList实现类。
LinkedList底层的数据结构是基于双向循环链表的,且头节点中不存放数据,添加元素如图所示,删除元素如图所示。对于频繁的插入或删除元素的操作,建议使用LinkedList类,效率较高。
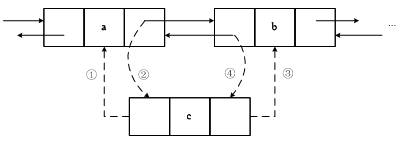
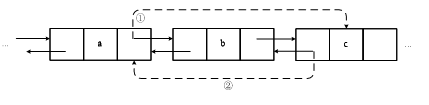
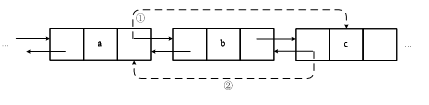
图描述了LinkedList添加元素的过程:在a和b之间添加一个元素c,只需利用指针让a记住它后面的元素是c,让b记住它前面的元素是c即可。图描述了LinkedList删除元素的过程,要删除a和c之间的元素,只需利用指针让a和c变成前后关系即可。
LinkedList除了具备增删效率高的特点,还为元素的操作定义了一些特有的常用方法,如表所示。
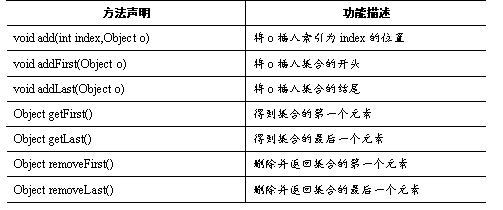
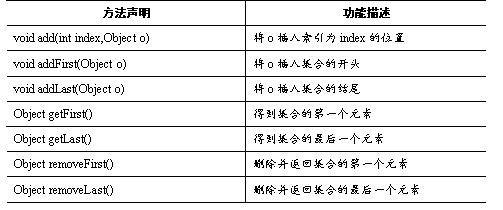
表中,列出了LinkedList一些特有的常用方法,下面通过一个案例来学习这些方法的使用,如例所示。


程序的运行结果如图所示。


例中,创建LinkedList后,先插入了两个元素,并打印出结果,然后向集合头部插入一个元素,打印结果可看出集合头部多出一个元素,最后打印出删除并返回的集合尾部元素。由此可见,LinkedList对增加和删除的操作不仅高效,而且便捷。
Ø Iterator集合
在开发过程中,经常需要遍历集合中的所有元素,针对这种需求,Java提供了一个专门用于遍历集合的接口——Iterator,它是用来迭代访问Collection中元素的,因此也称为迭代器。可以通过Collection接口中的iterator()方法得到该集合的迭代器对象,只要拿到这个对象,使用迭代器就可以遍历这个集合。
接下来通过一个案例来学习如何使用Iterator来遍历集合中元素,如例所示。


程序的运行结果如图所示。


例中,演示了使用Iterator迭代器来遍历集合。通过调用ArrayList的iterator()方法获得迭代器的对象,然后使用hasNext()方法判断集合中是否存在下一个元素,若存在,则通过next()方法取出,这里要注意,通过next()方法获取元素时,必须调用hasNext()方法检测是否存在下一个元素,否则若元素不存在,会抛出NoSuchElementException异常。
Iterator 仅用于遍历集合,如果需要创建 Iterator 对象,则必须有一个被迭代的集合。接下来通过一个图例来演示Iterator迭代元素的过程,如图所示。
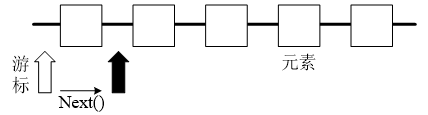
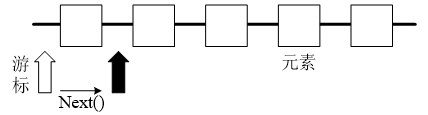
图中,在Iterator使用next()方法之前,迭代器游标索引在第一个元素之前,不指向任何元素,当第一次调用next()方法后,迭代器索引会后移一位,指向第一个元素并返回,以此类推,当hasNext()方法返回false时,则说明到达集合末尾,停止遍历。
Ø JDK5.0新特性——foreach循环
在8.3.4节中讲解了用Iterator迭代器来遍历集合,但这种方式写起来稍显复杂,Java还提供了一种很简洁的遍历方法,即使用foreach循环遍历,foreach也称为增强for循环,它既能遍历集合,也能遍历普通数组,其语法格式如下。


从以上代码可以看出,与普通for循环不同的是,它不需要获取容器长度,不需要用索引去访问容器中元素,但它能自动遍历容器中所有元素,下面通过一个案例对foreach循环进行详细讲解。如例所示。


程序的运行结果如图所示。


在例中,foreach循环遍历集合时语法非常简洁,没有循环条件,循环次数是根据容器中元素个数决定的,每次循环时foreach都通过临时变量将当前循环的元素记住,从而将集合中所有元素遍历并打印。
foreach循环代码简洁,编写方便,但是有其局限性,当使用foreach遍历数组或集合时,只能访问其中的元素,不能对元素进行修改,下面以一个案例来演示,如例所示。


程序的运行结果如图所示。


例中,第一次循环时修改了每一个取到的值,但第二次循环时,取到的依然是3个null,这说明foreach在循环遍历时,不会修改容器中的元素,原因是第6行中只是将临时变量strings指向了一个新字符串,这和数组中的元素没有关系,所以foreach并不是代替普通for循环的,只是让遍历容器变的更简洁。
Ø ListIterator接口
List接口额外提供了一个listIterator()方法,该方法返回一个ListIterator对象, ListIterator接口继承了Iterator接口,提供了一些用于操作List的方法,如表所示。


表中列举了ListIterator接口的常用方法。另外,ListIterator接口可以并发执行操作,而Iterator接口不能,Iterator接口如果并发执行操作,迭代器会出现不确定行为。
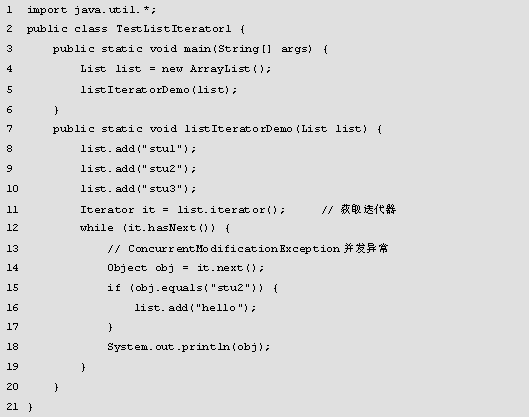
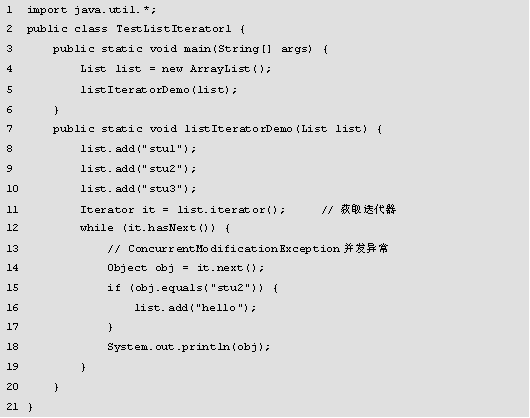
程序的运行结果如图所示。
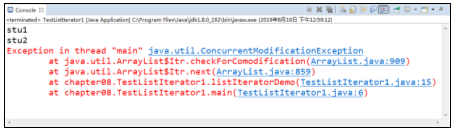
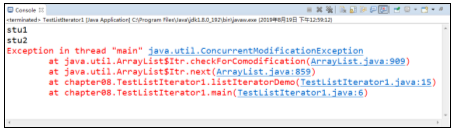
在图中,运行结果报ConcurrentModificationException异常,这是由于Iterator接口不能很好地支持并发操作,下面可以用ListIterator接口解决这个问题。
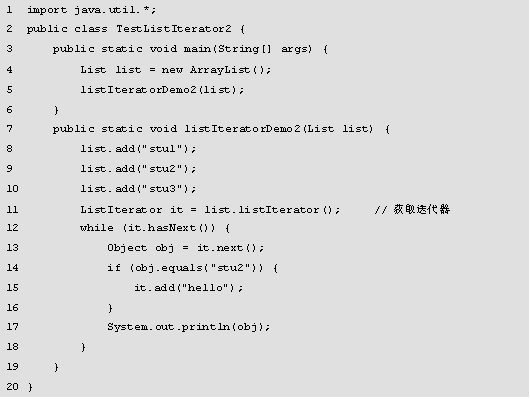
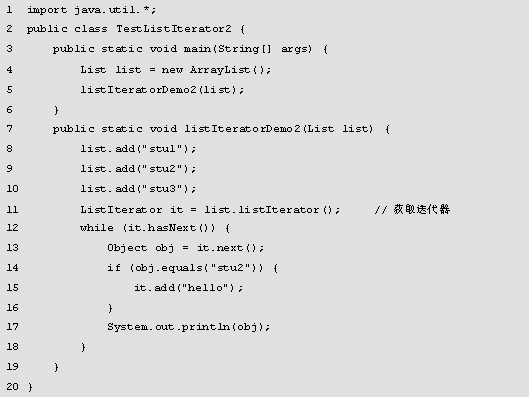
程序的运行结果如图所示。


在图中,运行结果打印了遍历出的集合元素,没有报出并发异常,可以看出ListIterator接口成功解决了Iterator接口不能很好支持并发操作的问题。
Ø Enumeration集合
在前面提到遍历集合可以使用Iterator接口,但在JDK2.0以前还没有Iterator接口,遍历集合都是使用Enumeration接口,它的用法和Iterator类似,名字长且编码略显复杂,但很多老程序中在使用,所以不能删除此接口,这里来了解一下此接口的使用。JDK早期使用Vector集合,它是List接口的一个古老实现类,线程安全但效率低。与Vector集合相比,ArrayList集合虽然高效,但是线程不安全。Vector类提供一个elements()方法用于返回Enumeration对象,然后通过Enumeration对象遍历集合中元素,下面通过一个案例来演示Enumeration接口的使用。如例所示。


程序的运行结果如图所示。


在图中,运行结果打印了遍历出的集合元素,可以看到Enumeration接口成功遍历出了Vector集合中的元素,这是一些老程序遍历集合的方式。
Set接口
Ø Set接口简介
Set集合中元素是无序的、不可重复的。Set接口也是继承自Collection接口,但它没有对Collection接口的方法进行扩充。
Set中元素有无序性的特点,这里要注意,无序性不等于随机性,无序性指的是元素在底层存储位置是无序的。Set接口的主要实现类是HashSet和TreeSet。其中HashSet是根据对象的哈希值来确定元素在集合中的存储位置,因此能高效地存取。TreeSet底层是用二叉树来实现存储元素的,它可以对集合中元素排序,接下来会围绕这两个实现类详细讲解。
Ø HashSet集合
HashSet类是Set接口的典型实现,使用Set集合时一般都使用这个实现类。HashSet按Hash算法来存储集合中的元素,因此具有很好的存取和查找性能。HashSet不能保证元素的排列顺序,且不是线程安全的。另外,集合中的元素可以为null。Set集合与List集合的存取元素方式都一样,这里就不详细讲解了,下面通过一个案例来演示HashSet集合的用法,如例所示。


程序的运行结果如图所示。
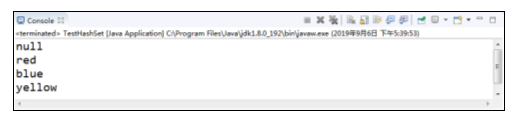
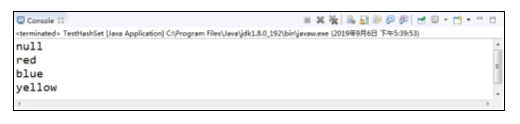
在例中存储元素时,是先存入的“yellow”,后存入的“blue”,而运行结果正好相反,证明了HashSet存储的无序性,但是如果多次运行,可以看到结果仍然不变,说明无序性不等于随机性,另外,例中存储元素时,存入了两个“red”,而运行结果中只有一个“red”,说明HashSet元素的不可重复性。
Ø TreeSet集合
TreeSet类是Set接口的另一个实现类,TreeSet集合和HashSet集合都可以保证容器内元素的唯一性,但它们底层实现方式不同,TreeSet底层是用自平衡的排序二叉树实现,所以它既能保证元素唯一性,又可以对元素进行排序。TreeSet还提供一些特有的方法。
HashSet能保证元素不重复,是因为HashSet底层是哈希表结构,当一个元素要存入HashSet集合时,首先通过自身的hashCode()方法算出一个值,然后通过这个值查找元素在集合中的位置,如果该位置没有元素,那么就存入。如果该位置上有元素,那么继续调用该元素的equals()方法进行比较,如果equals方法返回为真,证明这两个元素是相同元素,则不存储,否则会在该位置上存储两个元素(一般不可能重复),所以当一个自定义的对象想正确存入HashSet集合,那么应该重写自定义对象的hashCode()和equals()方法,例中HashSet能正常工作,是因为String类重写了hashCode()和equals()方法,下面通过一个案例来看一看将没有重写hashCode()方法和equals()方法的对象存入HashSet会出现什么情况。


程序的运行结果如图所示。


图中运行结果打印了遍历出的集合元素,可以看出运行结果中“lily23岁”明显重复了,不应该在HashSet中有重复元素出现,之所以出现这种现象,就是因为People对象没有重写hashCode()和equals()方法,接下来针对例出现的问题进行修改,修改后的代码参考。
程序的运行结果如图所示。


在例中,People对象重写了hashCode()和equals()方法,当调用HashSet的add()方法时,equals()方法返回true,HashSet发现lily23岁这个元素重复了,因此不再存入。
TreeSet类是Set接口的另一个实现类,TreeSet集合和HashSet集合都可以保证容器内元素的唯一性,但它们底层实现方式不同,TreeSet底层是用自平衡的排序二叉树实现,所以它既能保证元素唯一性,又可以对元素进行排序。TreeSet还提供一些特有的方法,如表所示。
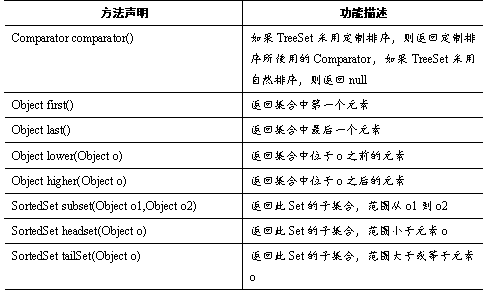
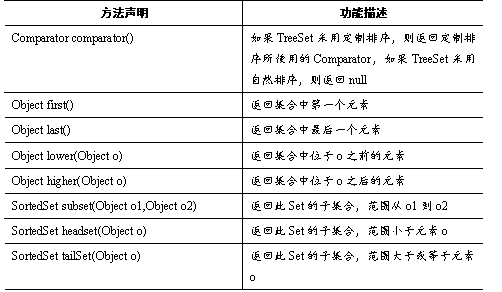
表中,列举了TreeSet类的常用方法,接下来通过一个案例来演示这些方法的使用,如例所示。


程序的运行结果如图所示。


在例中添加元素时,不是按顺序的,这说明TreeSet中元素是有序的,但这个顺序不是添加时的顺序,是根据元素实际值的大小进行排序的。另外,输出结果还演示了打印集合中第一个元素和打印集合中大于100小于500的元素,也都是按排序好的元素来打印的。
TreeSet有两种排序方法,自然排序和定制排序,默认情况下,TreeSet采用自然排序。下面来详细讲解这两种排序方式。
1.自然排序
TreeSet类会调用集合元素的compareTo(Object obj)方法来比较元素之间的大小关系,然后将集合内元素按升序排序,这就是自然排序。
Java提供了Comparable接口,它里面定义了一个compareTo(Object obj)方法,实现Comparable接口必须实现该方法,在方法中实现对象大小比较。当该方法被调用时,例如obj1.compareTo(obj2),若该方法返回0,则说明obj1和obj2相等;若该方法返回一个正整数,则说明obj1大于obj2;若该方法返回一个负整数,则说明obj1小于obj2。
Java的一些常用类已经实现了Comparable接口,并提供了比较大小的方式,比如包装类都实现了此接口。
如果把一个对象添加进TreeSet集合,则该对象必须实现Comparable接口,否则程序会抛出ClassCastException异常。下面通过一个案例来演示这种情况,如例所示。


程序的运行结果如图所示。


图中运行结果报ClassCastException异常,这是因为例中的Student类没有实现Comparable接口。
另外,向TreeSet集合中添加的应该是同一个类的对象,否则也会报ClassCastException异常,如例所示。


程序的运行结果如图所示。


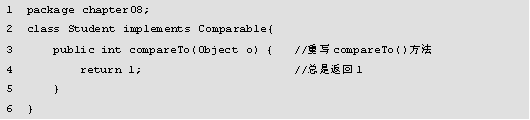
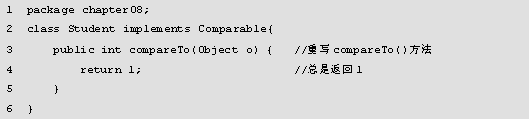
图中运行结果报ClassCastException异常,Integer类型不能转为Date类型,就是因为向TreeSet集合添加了不同类的对象。下面通过修改例的代码,新建Student类,该类实现Comparable接口,并重写compareTo()方法,使程序正确运行。
如例所示。


运行结果如图所示。


图中运行结果正确打印了集合中两个元素的地址值,添加元素操作成功,因为例中,Student类实现了Comparable接口,并且重写了compareTo(Object o)方法,这里设置了总是返回1,所以添加成功。
2.定制排序
TreeSet的自然排序是根据集合元素大小按升序排序,如果需要按特殊规则排序或者元素自身不具备比较性时,比如按降序排列,就需要用到定制排序。Comparator接口包含一个int compare(T t1,T t2)方法,该方法可以比较t1和t2大小,若返回正整数,则说明t1大于t2;若返回0,则说明t1等于t2;若返回负整数,则说明t1小于t2。
实现TreeSet的定制排序时,只需在创建TreeSet集合对象时,提供一个Comparator对象与该集合关联,在Comparator中编写排序逻辑。
程序的运行结果如图所示。


在例中,MyComparator类实现了Comparator接口,在接口的compare方法中编写了降序逻辑,所以TreeSet中的元素以降序排列,这就是定制排序。
Queue接口
Ø Queue接口简介
Queue用于模拟队列这种数据结构,队列通常是指“先进先出”(FIFO)的容器。队列的头部是保存在队列中存放时间最长的元素,队列的尾部是保存在队列中存放时间最短的元素。新元素插入(offer)到队列的尾部,访问元素(poll)操作会返回队列头部的元素。通常,队列不允许随机访问队列中的元素,接下来了解一下Queue接口的方法,如表所示。
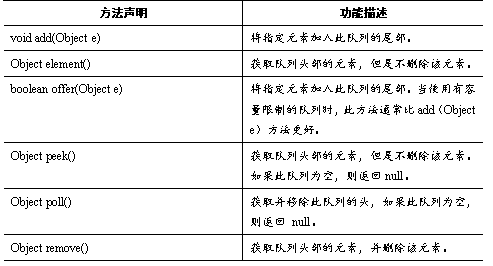
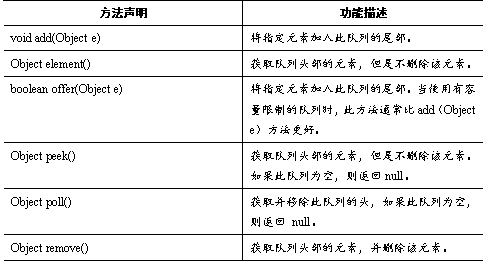
Queue接口有一个PriorityQueue实现类。除此之外,Queue还有一个Deque接口,Deque代表一个“双端队列”,双端队列可以同时从两端来添加、删除元素,因此Deque的实现类既可当成队列使用,也可当成栈使用,Java为Deque提供了实现类ArrayDeque,接下来会详细讲解Queue接口相关内容。
Ø PriorityQueue实现类
PriorityQueue是一个比较标准的队列实现类。之所以说它是比较标准的队列实现,而不是绝对标准的队列实现,是因为PriorityQueue保存队列元素的顺序并不是按加入队列的顺序,而是按队列元素的大小进行重新排序。因此当调用peek()方法或者poll()方法取出队列中的元素时,并不是取出最先进入队列的元素,而是取出队列中最小的元素。从这个意义上来看,PriorityQueue类已经违反了队列的最基本规则:先进先出(FIFO)。接下来通过一个案例演示PriorityQueue类的使用。如例所示。


程序的运行结果如图所示。


例中首先创建PriorityQueue集合,向集合中添加三个元素并打印,接着获取并移除此队列的头元素,最后再次打印集合,查看删除头元素后的集合元素。
PriorityQueue不允许插入null元素,它还需要对队列元素进行排序,PriorityQueue的元素有下列两种排序方式。
(1)自然排序:采用自然顺序的PriorityQueue集合中的元素必须实现了Comparable接口,而且应该是同一个类的多个实例,否则可能导致ClassCastException异常。
(2)定制顺序:创建PriorityQueue队列时,传入一个Comparator对象,该对象负责对队列中的所有元素进行排序。采用定制排序时不要求队列元素实现Comparator接口。
另外,PriorityQueue队列对元素的要求与TreeSet集合对元素的要求基本一致。
Ø Deque接口与ArrayDeque实现类
Deque接口是Queue接口的子接口,它代表一个双端队列,Deque接口里定义了一些双端队列的方法,这些方法允许从两端来操作队列的元素,如表所示。
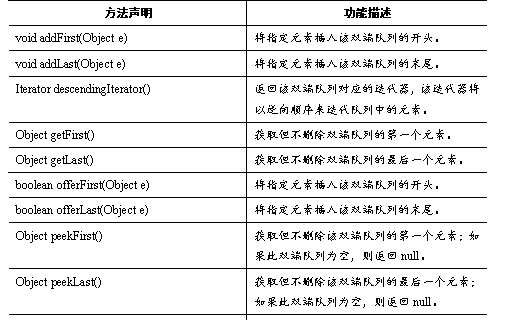
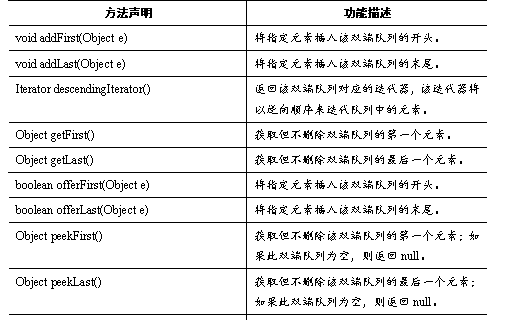
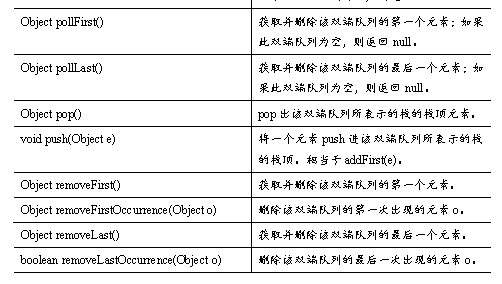
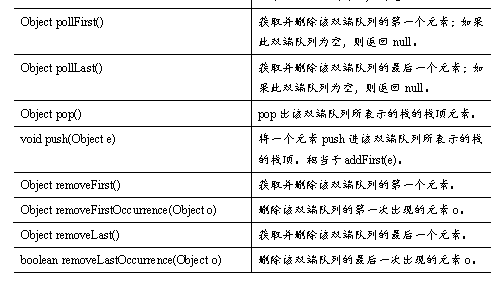
Deque的方法与Queue的方法对照表如表所示。


Deque的方法与Stack的方法对照表如表所示
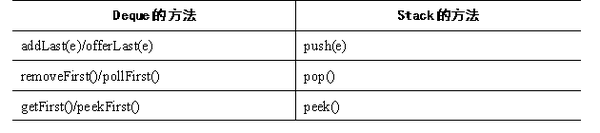
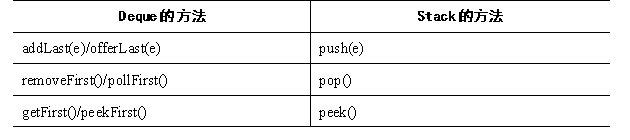
ArrayDeque是Deque接口的典型实现类,从该名称就可以看出,它是一个基于数组实现的双端队列,创建Deque时同样可指定一个numElements参数,该参数用于指定Object[]数组的长度;如果不指定numElements参数,Deque底层数组的长度为16。
ArrayList和ArrayDeque两个集合类的实现机制基本相似,它们的底层都采用一个动态的、可重分配的Object[]数组来存储集合元素,当集合元素超出了该数组的容量时,系统会在底层重新分配一个Object[]数组来存储集合元素。
接下来用一个案例来演示将ArrayDeque当成“栈”来使用,如例所示。


程序的运行结果如图所示。
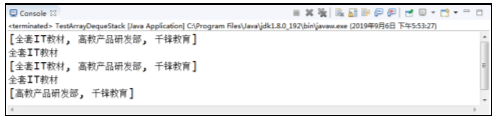
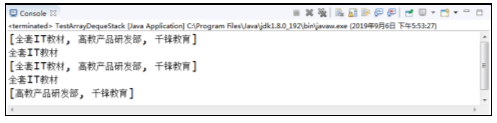
在图中,运行结果显示了ArrayDeque作为栈的行为,因此当程序中需要使用“栈”这种数据结构时,推荐使用ArrayDeque,尽量避免使用Stack——因为Stack是古老的集合,性能较差。
当然ArrayDeque也可以当成队列使用,接下来通过一个案例演示ArrayDeque按“先进先出”的方式操作集合元素。


程序的运行结果如图所示。
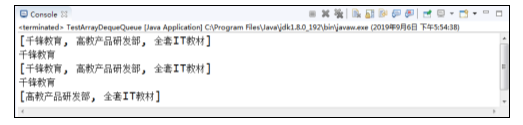
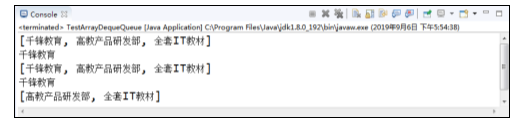
在图中,运行结果显示了ArrayDeque作为队列的行为,因此可以证明ArrayDeque不仅可以作为栈使用,也可以作为队列使用。
Map接口
Ø Map接口简介
Map接口不是继承自Collection接口,它与Collection接口是并列存在的,用于存储键值对(key-value)形式的元素,描述了由不重复的键到值的映射。
Map中的key和value都可以是任何引用类型的数据。Map 中的key用Set来存放,不允许重复,即同一个Map对象所对应的类,必须重写hashCode()方法和equals()方法。通常用String类作为Map的key,key和value之间存在单向一对一关系,即通过指定的key总能找到唯一的、确定的value。
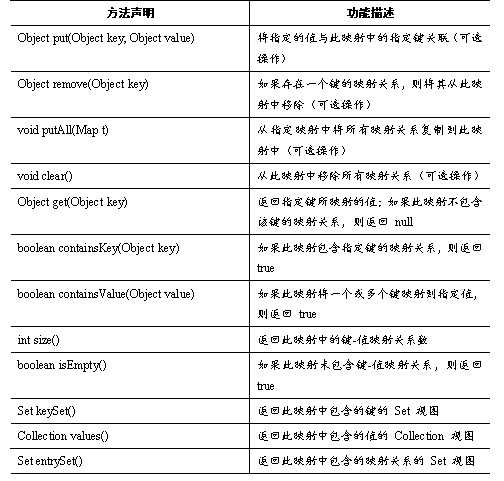
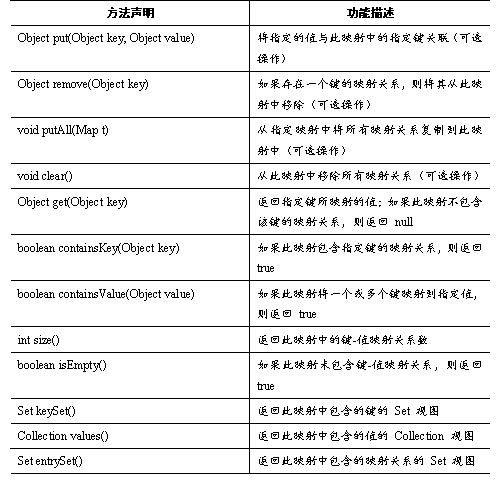
表中列举了Map接口的方法,其中最常用的是Object put(Object key, Object value)和Object get(Object key)方法,用于向集合中存入和取出元素。
Map接口有很多实现类,其中最常用的是HashMap类和TreeMap类,接下来会针对这两个类进行详细讲解。
Ø HashMap集合
HashMap类是 Map 接口中使用频率最高的实现类,允许使用null键和null值,与HashSet集合一样,不保证映射的顺序。HashMap集合判断两个key相等的标准是:两个key通过equals()方法返回true,hashCode值也相等。HashMap集合判断两个value相等的标准是:两个value通过equals()方法返回true。下面通过一个案例演示HashMap集合是如何存取元素的。如例所示。


程序的运行结果如图所示。


在图中,运行结果打印了HashMap集合的长度和所有元素,取出并打印了集合中键为“stu2”的值,这是HashMap基本的存取操作。
由于HashMap中的键是用Set来储存的,所以不可重复,下面通过一个案例来演示当“键”重复时的情况。


程序的运行结果如图所示。


在例中,先将键为“stu3”值为“Jone”的元素添入集合,后将键为“stu3”值为“Lily”的元素添入集合,当键重复时,后添加的元素的值将覆盖先添加元素的值,简单来说就是键相同,值覆盖。
前面讲解了如何遍历List,遍历Map与之前的方式有所不同,有两种方式可以实现。第一种是先遍历集合中所有的键,再根据键获得对应的值,下面通过一个案例来演示这种遍历方式。


程序的运行结果如图所示。


在例中,通过keySet()方法获取到键的集合,通过键获取迭代器,从而循环遍历出集合的键,然后通过Map的get(String key)方法,获取所有的值,最后打印出所有键和值。
Map的第二种遍历方式是先获得集合中所有的映射关系,然后从映射关系获取键和值。下面通过一个案例来演示这种遍历方式。


程序的运行结果如图所示。


在例中,创建集合并添加元素后,先获取迭代器,在循环时,先获取集合中键值对映射关系,然后从映射关系中取出键和值,这就是Map的第二种遍历方式。
Ø LinkedHashMap集合
LinkedHashMap类是HashMap的子类,LinkedHashMap类可以维护Map的迭代顺序,迭代顺序与键值对的插入顺序一致,如果需要输出的顺序与输入时的顺序相同,那么就选用LinkedHashMap集合。下面通过一个案例来学习LinkedHashMap集合的用法,如例所示。


程序的运行结果如图示。


在例中,先创建了LinkedHashMap集合,然后向集合中添加元素,遍历打印出来,这里可以发现,打印出的元素顺序和存入的元素顺序一样,这就是LinkedHashMap起到的作用,它用双向链表维护了插入和访问顺序,从而打印出的元素与存储顺序一致。
Ø TreeMap集合
Java中Map接口还有一个常用的实现类TreeMap类。TreeMap集合存储键值对时,需要根据键值对进行排序。TreeMap集合可以保证所有的键值对处于有序状态。下面通过一个案例来了解TreeMap集合的具体用法,如例所示。


程序的运行结果如图所示。


在例中,创建TreeMap集合后,先添加键为“2”值为“yellow”的元素,后添加键为“1”值为“red”的元素,但是运行结果中可以看到集合中元素顺序并不是这样,而是按键的实际值大小来升序排列的,这是因为Integer实现了Comparable接口,因此默认会按照自然顺序进行排序
另外,TreeMap还支持定制排序,根据自己的需求编写排序逻辑,接下来通过一个案例来演示这种用法。


程序的运行结果如图所示。


在例中,是按键为2、1、3的顺序将元素存入集合的,运行结果中显示集合中元素是按降序排列的,这是因为例中自定义的MyComparator类中的compare(Object o1,Object o2)方法重写了排序逻辑,这就是TreeMap的定制排序。
Ø Properties集合
Map接口中有一个古老的、线程安全的实现类——Hashtable,与HashMap集合相同的是它也不能保证其中键值对的顺序,它判断两个键、两个值相等的标准与HashMap集合一样,与HashMap集合不同的是,它不允许使用null作为键和值。
Hashtable类存取元素速度较慢,目前基本被HashMap类代替,但它有一个子类Properties在实际开发中很常用,该子类对象用于处理属性文件,由于属性文件里的键和值都是字符串类型,所以Properties类里的键和值都是字符串类型。接下来了解一下Properties类的常用方法。如表所示。
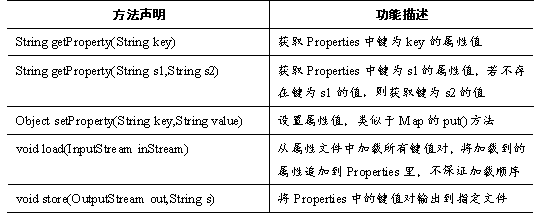
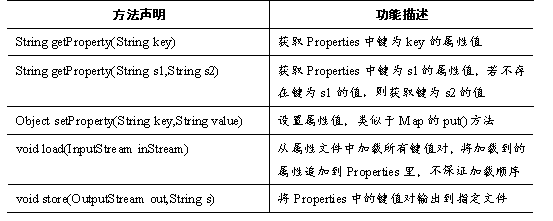
表中列出了Properties类的常用方法,其中最常用的是String getProperty(String key),可以根据属性文件中属性的键,获取对应属性的值。接下来通过一个案例来演示Properties类的用法。


上面程序运行后,会在当前目录生成一个test.ini的文件,文件内容如下。


从test.ini文件中可看到例添加的属性,以键值对的形式保存,实际开发中通常用这种方式处理属性文件。
JDK5.0新特性——泛型
Ø 为什么使用泛型
泛型是JDK5.0新加入的特性,解决了数据类型的安全性问题,其主要原理是在类声明时通过一个标识,表示类中某个属性的类型或者是某个方法的返回值及参数类型。这样在类声明或实例化时只要指定好需要的具体类型即可。
Java泛型可以保证如果程序在编译时没有发出警告,运行时就不会报ClassCastException异常,同时,代码更加简洁、健壮。
在前面几节中,编译代码时都会出现类型安全的警告,如果指定了泛型,就不会出现这种警告。
Ø 泛型的定义
泛型在定义集合类时,使用“<参数化类型>”的方式指定该集合中方法操作的数据类型,具体示例如下。


接下来,通过一个案例来演示泛型在集合中的应用,如例所示。


程序的运行结果如图所示。


在例中,创建集合的时候,指定了泛型为String类型,该集合只能添加String类型的元素,编译文件时,不再出现类型安全警告,如果向集合中添加非String类型的元素,会报编译时异常。
Ø 通配符
讲解泛型的定义后,这里要引入一个通配符的概念,类型通配符用符号“?”表示,比如List<?>,它是List<String>、List<Object>等各种泛型List的父类。


程序的运行结果如图所示。


在例中,先声明List的泛型类型为“?”,然后在创建对象实例时,泛型类型设为String或Integer都不会报错,体现了应用泛型的可扩展性,此时向集合中添加元素时会报错,因为list集合的元素类型无法确定,唯一的例外的是null,因为它是所有类型的成员。
另外,例在方法read()的参数声明中,List参数也应用了泛型类型“?”,所以使用此静态方法能接收多种参数类型。
Ø 有界类型
讲解了利用通配符“?”来声明泛型类型,Java还提供了有界类型,可以创建声明超类的上界和声明子类的下界,下面通过一个案例来详细讲解有界类型,如例所示。


在例中,将list的泛型类型定义为“? extends Person”表示只允许list的泛型类型为Person及Person的子类,若泛型为其他类型,则报编译时异常。将list2的泛型类型定义为“? super Man”表示只允许list2的泛型类型为Man及Man的父类,若泛型为其他类型,则报编译时异常。这就是泛型有界类型的基本使用。
Ø 泛型的限制
前面几节讲解了泛型的诸多用处,优点很多,但泛型也有一些限制,例如,加入集合中的对象类型必须与指定的泛型类型一致;静态方法中不能使用类的泛型;如果泛型类是一个接口或抽象类,则不可创建泛型类的对象;不能在catch中使用泛型;从泛型类派生子类,泛型类型需具体化等。
正确应用泛型,可以使程序变得更简洁、更健壮,在应用的同时,也要注意泛型的诸多限制,以免出现错误。
Ø 自定义泛型
前面讲解了泛型的一些应用,那么,如何在程序中自定义泛型呢?假设要实现一个简单的容器,用于保存某个值,这个容器应该定义两个方法:get()方法和set()方法,前者用于取值,后者用于存值,其语法格式如下。


Ø JDK8.0新特性——forEach遍历
通过之前章节的学习,读者已经了解如何使用for循环和JDK1.5的foreach方法对数据集进行遍历操作,从 JDK 8.0开始,会有多个强大的新方法可以帮助完成简化复杂的迭代。forEach()方法是JDK8.0中在集合父接口java.lang.Iterable中新增的一个default实现方法,该方法的源码如下所示。
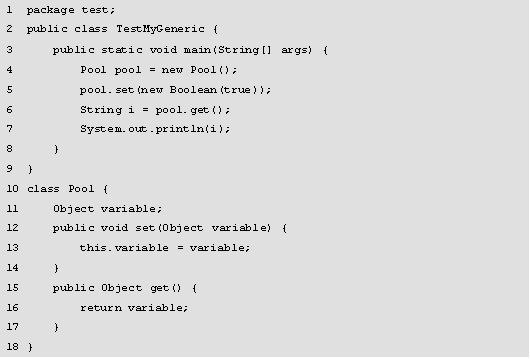
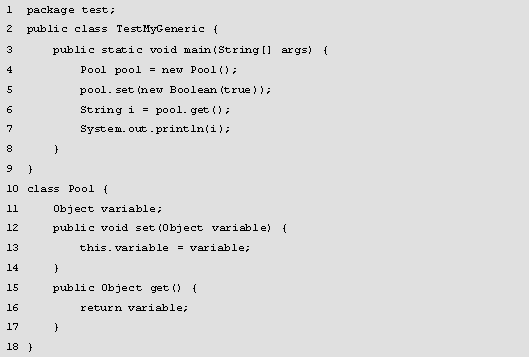
程序的运行结果如图所示。
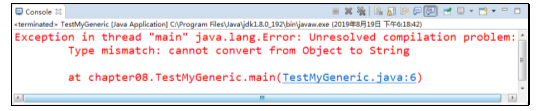
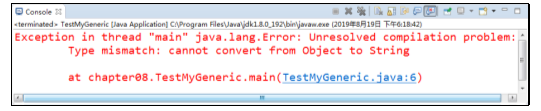
在图中,运行结果显示在编译时就报错了,这是因为代码中存入了一个Boolean类型的值,第6行取出这个值时,将其转换为了String类型,出现不兼容的类型错误,为了避免这个错误,就可以使用泛型。如果定义类Pool时使用<T>声明参数类型(T其实就是Type的缩写,这里也可以使用其他字符,为了方便理解就定义为T),将set()方法的参数类型和get()方法的返回值类型都声明为T,那么存入元素时,元素的类型就被限定了,容器中就只能存入这种T类型的元素,取出元素时也无须类型转换了。
接下类通过一个案例来演示如何自定义泛型,如例所示。


程序的运行结果如图所示。


在例中,Pool类声明泛型类型为T,其中,set()方法参数类型和get()方法返回值类型都为T,在main()方法中创建Pool对象实例时,通过<Integer>将泛型T指定为Integer类型,调用set()方法存入Integer类型的数据,调用get()方法取出的值自然时Integer类型,这样就不需要进行类型转换了。
通过之前的学习,读者已经了解如何使用for循环和JDK1.5的foreach方法对数据集进行遍历操作,从 JDK 8.0开始,会有多个强大的新方法可以帮助完成简化复杂的迭代。forEach()方法是JDK8.0中在集合父接口java.lang.Iterable中新增的一个default实现方法,该方法的源码如下所示。
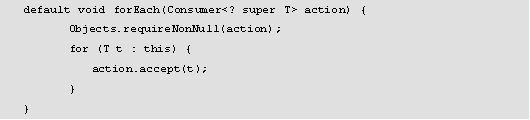
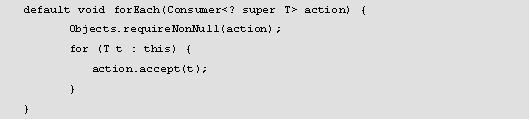
forEach()方法接受一个在JDK 8.0中新增的java.util.function.Consumer的消费行为 或者称之为动作 (Consumer action )类型;然后将集合中的每个元素作为消费行为的accept方法的参数执行;直到所有元素都处理完毕或者抛出异常即终止行为;除非指定了消费行为action的实现,否则默认情况下是按迭代里面的元素顺序依次处理。由于该方法在Iterable中,所以直接用迭代的方式遍历整个集合元素之后对每个元素,调用Consumer.accept(T)方法。
下面通过遍历Map集合和List集合中的元素,对比JDK1.8前后两种遍历方式,案例代码参考。
运行以上代码,控制台中打印的结果如图所示。
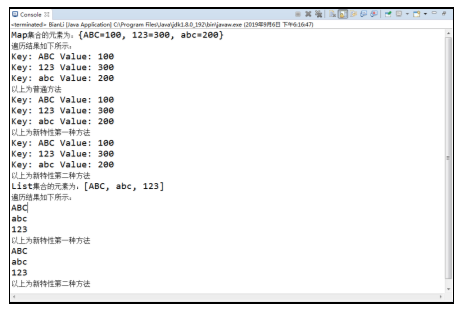
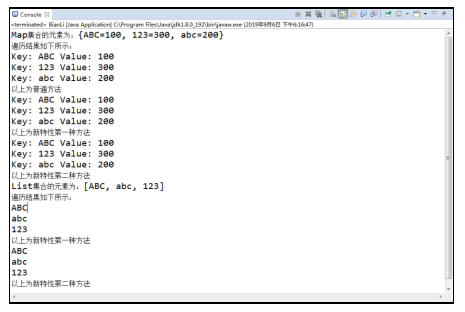
在例中,首先定义了一个Map集合,并通过put()方法向集合中添加键值对元素,然后通过JDK 8.0之前的旧方式对集合进行了遍历操作,随后又使用了JDK 8.0新特性对该集合进行了打印,通过比较可以看出,在新特性中的forEach(Consumer action)方法与Lambda表达式进行了结合,方法传递的是一个函数式接口,在该方法执行时,会自动向表达式的形参中逐个传递集合元素。在以上代码对新特性的演示中,通过Lambda表达式的语法格式和方法引用实现对Map和List集合遍历的不同方法,也是对Lambda表达式章节知识点的复习,此处不再重复讲解。
除了forEach(Consumer action)方法之外,JDK 8.0中还提供了forEachRemaining(Consumer action)方法进行遍历,不同的是forEachRemaining()方法遍历输出剩余元素,只能用一次,调用后iterator.hasNext()不再为true,等同于如下所示的while循环。


下面将通过案例代码演示如何使用forEachRemaining(Consumer action)方法遍历Iterator接口元素,如例所示。


运行结果如图所示。
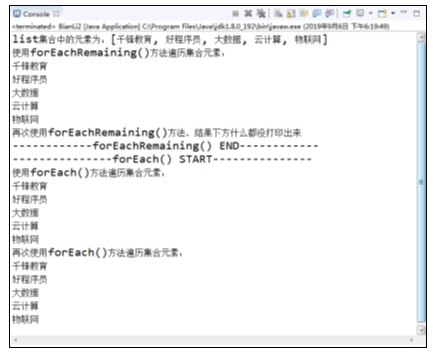
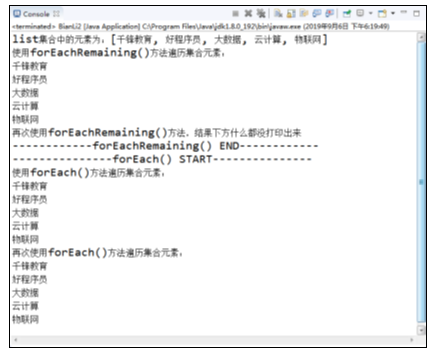
在图中,从运行结果可以看到foreach与forEachRemaining是可以依托于迭代器通过Lamdba遍历的,其中,forEachRemaining()只能使用一次,而foreach()两次都能打印出结果。
Ø Collections工具类
Collections 是一个操作 Set、List 和 Map 等集合的工具类,它提供了一系列静态的方法对集合元素进行排序、查询和修改等操作。接下来对这些常用方法详细介绍。
1.排序操作
Collections类中提供了一些对List集合进行排序的静态方法,如表所示。
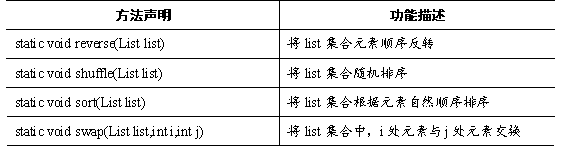
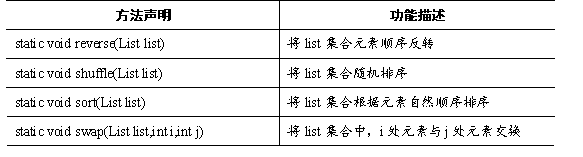
表中列出了Collections类对List集合进行排序的方法,接下来通过一个案例来演示这些方法的使用,如例所示。


程序的运行结果如图所示。
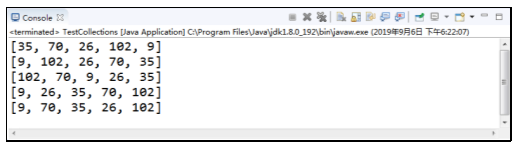
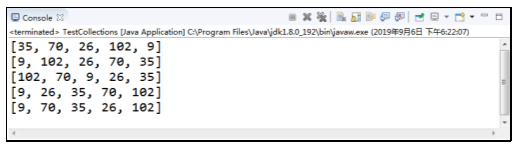
在例中,先向List集合添加了5个元素,分别为35、70、26、102、9,第一次打印集合,第二次将集合反转后打印,第三次将集合随机排序打印,第四次将集合按自然顺序排序打印,最后将索引为1的元素和索引为3的元素交换位置并打印,可以看出这里的索引也是从0开始计算的。
2.查找、替换操作
Collections类中还提供了一些对集合进行查找、替换的静态方法,如表所示。
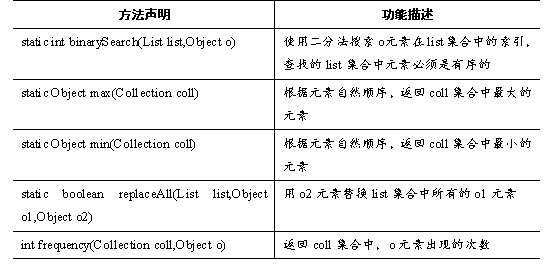
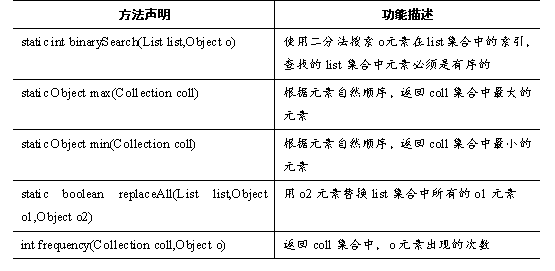
表中列出了Collections类中对集合进行查找、替换的方法,接下来通过一个案例来演示这些方法的使用,如例所示。
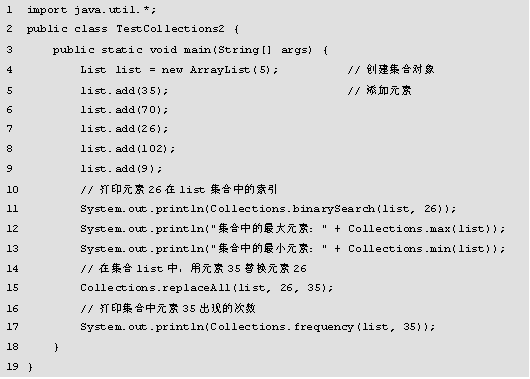
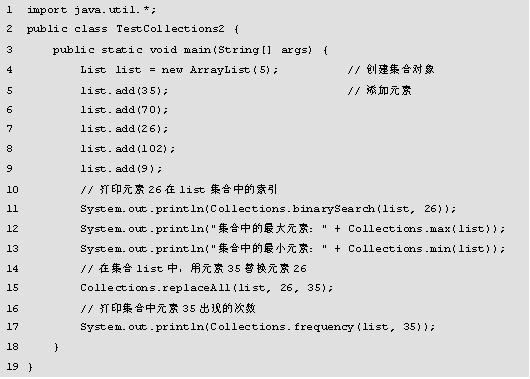
程序的运行结果如图所示。
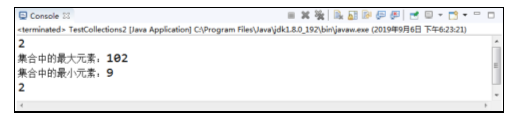
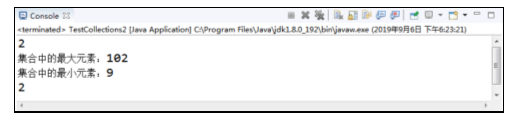
在图中,运行结果先打印了例中元素26在集合中的索引,索引为2,说明这里索引也是从0开始计算的,然后打印出了集合中按自然顺序排序后的最大元素和最小元素,最后用元素35替换掉集合里所有的元素26,打印出元素35在集合中出现的次数为2次。这是Collections类基本的查找、替换用法。
Collections工具类还提供了对集合对象设置不可变、对集合对象实现同步控制等方法,有兴趣的读者可以通过自学JDK使用文档来深入学习。
Ø Arrays工具类
java.util包中还提供了一个Arrays数组工具类,里面包含大量操作数组的静态方法。如表所示。
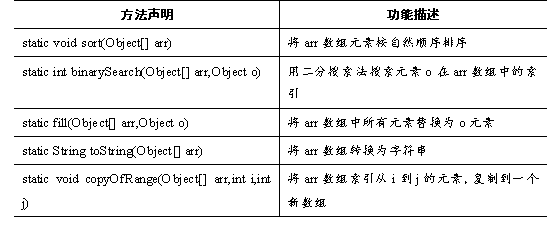
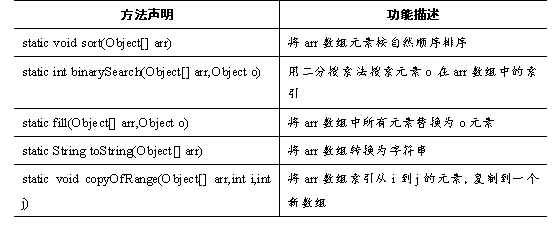
表列出了Arrays类常用方法,接下来通过一个案例来演示这些方法的使用,如例所示。


程序的运行结果如图所示。
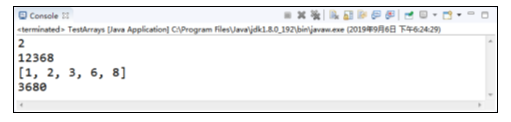
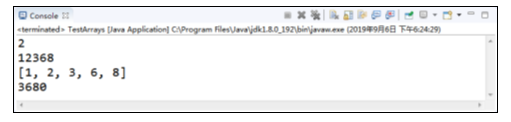
在图中,运行结果先打印出了例中arr数组元素“2”在数组中的索引位置,索引为2,然后对arr数组进行了自然排序,遍历打印出数组,排序成功。之后将arr数组转换为字符串并打印。最后将arr数组中从arr[2]到arr[6]复制到数组arr2中并打印,这是Arrays数组工具类的基本用法。
当然,Arrays工具类还有更多的方法,如果有兴趣,可以参照JDK使用文档进行深入学习。
Ø 集合转换
在开发中,可能需要将集合对象(List,Set)转换为数组对象,或者将数组对象转换为集合对象。Java提供了相互转换的方法,接下来详细讲解数组与集合的转换。
1.集合转换为数组
集合可以直接转换为数组,如例所示。


程序的运行结果如图所示。


图中运行结果打印了数组中的3个元素。在例中,先创建了集合对象并添加元素,然后调用集合的toArray()方法,将集合转换成了数组,循环遍历打印。
2.数组转换为集合
数组也可以直接转换为集合,如例所示。


程序的运行结果如图所示。


在例中,先创建了数组并初始化,然后调用Arrays工具类的asList(Object[] arr)静态方法,将数组转换为了集合,最后打印集合中所有元素。
对于int[]数组不能直接这样做,因为asList(Object[] arr)方法的参数必须是对象。应该先把int[]转化为Integer[]。
使用asList(Object[] arr)方法返回的ArrayList类是Arrays工具类里内嵌的一个私有静态类,并不是java.util.ArrayList中的ArrayList类,这个ArrayList类是固定长度的,如果对其进行add()或者remove()的操作,将会报UnsupportedOperationException异常。
Ø JDK8.0新特性——Stream API
Stream是Java 8中处理集合的关键抽象概念,它可以指定对集合进行的操作,可以执行非常复杂的查找、过滤和映射数据等操作。使用Stream API对集合数据进行操作,就类似于使用SQL执行的数据库查询。也可以使用Stream API来并行执行操作。简而言之,Stream API提供了一种高效且易于使用的处理数据的方式。
1. 理解Stream
Stream被称作流,是用来处理集合以及数组的数据的。它具有如下特点。
(1)Stream自己不会存储元素。
(2)Stream不会改变源对象,相反,它们会返回一个持有结果的新Stream。
(3)Stream操作是延迟执行的,这意味着它们会等到需要结果的时候才执行。
2. 使用Stream的三个步骤
(1)创建Stream:一个数据源(如:集合、数组),获取一个流。
(2)中间操作:一个中间操作链,对数据源的数据进行处理。
(3)终止操作:一个终止操作,执行中间操作链,并产生结果。
3. 创建Stream代码。代码参考。


4. 生成流
在 Java 8 中, 集合接口有以下两个方法来生成流。
(1)stream():为集合创建串行流。
(2)parallelStream():为集合创建并行流。


Stream 使用一种类似用 SQL 语句从数据库查询数据的直观方式来提供一种对 Java 集合运算和表达的高阶抽象。Stream API可以极大提高Java程序员的生产力,让程序员写出高效率、干净、简洁的代码。这种风格将要处理的元素集合看作一种流, 流在管道中传输, 并且可以在管道的节点上进行处理, 比如筛选, 排序,聚合等。
以上的流程转换为 Java 代码如下所示。


Stream(流)是一个来自数据源的元素队列并支持聚合操作,元素是特定类型的对象,形成一个队列。Java中的Stream并不会存储元素,而是按需计算。
数据源流的来源可以是集合,数组,I/O channel, 产生器generator 等。
聚合操作是类似SQL语句一样的操作,比如filter, map, reduce, find, match, sorted等。和以前的Collection操作不同,Stream操作还有以下两个基础的特征:
(1)Pipelining: 中间操作都会返回流对象本身。这样多个操作可以串联成一个管道,如同流式风格(fluent style)。这样做可以对操作进行优化,比如延迟执行(laziness)和短路( short-circuiting)。
(2)内部迭代:以前对集合遍历都是通过Iterator或者forEach的方式,显式地在集合外部进行迭代,这叫作外部迭代。Stream提供了内部迭代的方式,通过访问者模式(Visitor)实现。
关键代码讲解如下。
生成流,用stream()方法为集合创建串行流,代码如下所示。


Stream提供了新的方法forEach来迭代流中的每个数据。以下代码片段使用forEach输出了10个随机数。


map方法用于映射每个元素到对应的结果,以下代码片段使用map输出了元素对应的平方数。


filter方法用于通过设置的条件过滤出元素。以下代码片段使用filter方法过滤出空字符串。


limit方法用于获取指定数量的流。以下代码片段使用limit方法打印出10条数据。
sorted方法用于对流进行排序。以下代码片段使用sorted方法对输出的10个随机数进行排序。


parallelStream是流并行处理程序的代替方法。以下实例中使用parallelStream来输出空字符串的数量。


Collectors类实现了很多归约操作,例如,将流转换成集合和聚合元素。Collectors可用于返回列表或字符串,实例代码如下所示。


在JDK1.8中,引入了统计信息收集器来计算流处理时的所有统计信息。首先来了解一下IntSummaryStatistics类,这个类主要是和stream类配合使用的,在java.util包中,主要用于统计整型数组中元素的最大值,最小值,平均值,个数,元素总和等等。有兴趣读者可以通过IntSummaryStatistics类的源码了解和学习。


通过源码可以看出IntSummaryStatistics类实现了IntConsumer接口,在该类中定义了获取重量、总和、最大值、最小值和平均数的方法,在编码时直接拿来使用即可。
另外,一些产生统计结果的收集器也非常有用。它们主要用于int、double、long等基本类型上,它们可以用来产生类似如下的统计结果。
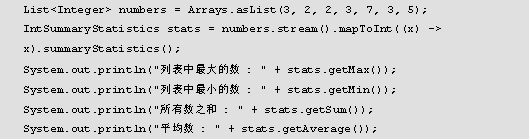
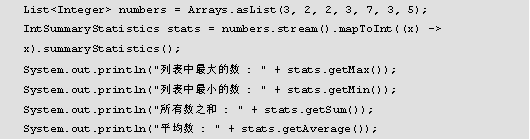
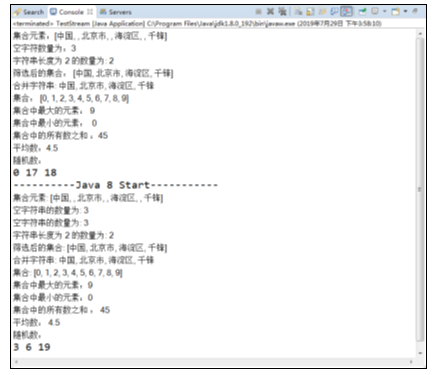
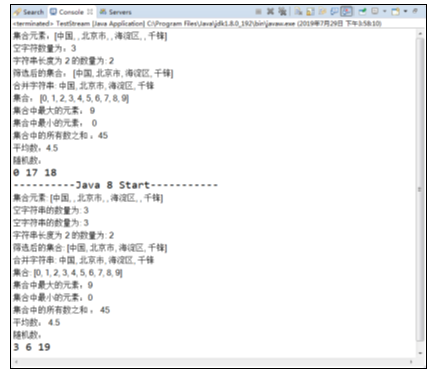
以上代码中,分别通过JDK1.8之前的方法和之后的方法分别实现了对集合元素的相关操作,运行结果如图所示。
小结:Java语言程序设计— Java中集合类的使用
通过学习,读者能够掌握Java集合框架的相关知识,了解JDK8.0的forEach遍历,掌握Java 8新特性Stream API的使用。重点要了解的是Java泛型,可以保证如果程序在编译时没有发出警告,运行时就不会报ClassCastException异常,同时,代码更加简洁、健壮。