

chatglm2 的finetune 基于四卡24G显存平台实践
在2023年07月04日在指标性能上超出chatgpt的chatglm2的全参数量微调finetune与低资源ptuning v2进行sft训练的代码更新到了项目中。
目前阶段chatglm2的finetune主要问题集中在是使用fp16在较小的batchsize下进行训练还是使用int8在较大的batchsize下进行训练。
官方训练参数目前在四卡3090平台会出现显存溢出问题。
LR=1e-4
MASTER_PORT=$(shuf -n 1 -i 10000-65535)
deepspeed --num_gpus=4 --master_port $MASTER_PORT main.py \
--deepspeed deepspeed.json \
--do_train \
--train_file AdvertiseGen/train.json \
--test_file AdvertiseGen/dev.json \
--prompt_column content \
--response_column summary \
--overwrite_cache \
--model_name_or_path THUDM/chatglm2-6b \
--output_dir ./output/adgen-chatglm2-6b-ft-$LR \
--overwrite_output_dir \
--max_source_length 64 \
--max_target_length 64 \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 1 \
--predict_with_generate \
--max_steps 5000 \
--logging_steps 10 \
--save_steps 100 \
--learning_rate $LR \
--fp16在chatglm2的finetune参数体系中决定资源占用量比较重的一个参数是per_device_train_batch_size 参数。减小这个per_device_train_batch_size 参数后可以降低显存占用。
这里我第一个做的改变是将模型转换为int8格式的参数进行训练。在四卡3090显卡平台中可以稳定运行并保存模型。
LR=1e-4
MASTER_PORT=$(shuf -n 1 -i 10000-65535)
deepspeed --num_gpus=4 --master_port $MASTER_PORT main.py \
--deepspeed deepspeed.json \
--do_train \
--train_file AdvertiseGen/train.json \
--test_file AdvertiseGen/dev.json \
--prompt_column content \
--response_column summary \
--overwrite_cache \
--model_name_or_path THUDM/chatglm2-6b \
--output_dir ./output/adgen-chatglm2-6b-ft-$LR \
--overwrite_output_dir \
--max_source_length 64 \
--max_target_length 64 \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 1 \
--predict_with_generate \
--max_steps 5000 \
--logging_steps 10 \
--save_steps 100 \
--learning_rate $LR \
--fp16 \
--quantization_bit 8
训练过程中的显存占用如图。
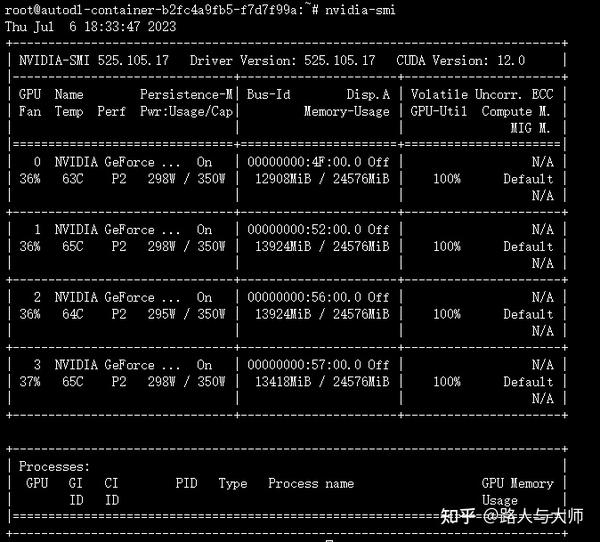
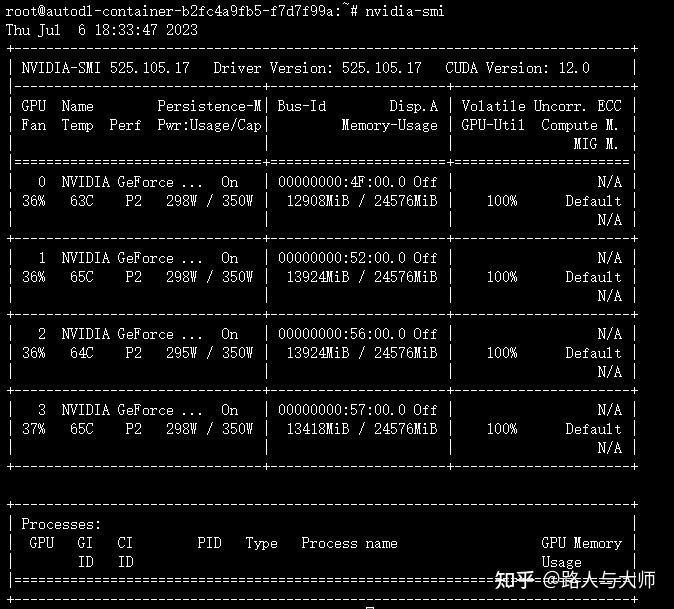
显存占用在百分之五十左右徘徊。
训练过程损失变化的截图。数据量比较小,只有108条数据。所以上面的参数选择100步保存一次模型。
{'loss': 2.3198, 'learning_rate': 9.984e-05, 'epoch': 1.43}
{'loss': 0.5186, 'learning_rate': 9.964e-05, 'epoch': 2.86}
{'loss': 0.2005, 'learning_rate': 9.944e-05, 'epoch': 4.29}
{'loss': 0.1322, 'learning_rate': 9.924e-05, 'epoch': 5.71}
{'loss': 0.0922, 'learning_rate': 9.904e-05, 'epoch': 7.14}
{'loss': 0.0708, 'learning_rate': 9.884e-05, 'epoch': 8.57}
{'loss': 0.0629, 'learning_rate': 9.864e-05, 'epoch': 10.0}
{'loss': 0.0513, 'learning_rate': 9.844000000000001e-05, 'epoch': 11.43}
{'loss': 0.0466, 'learning_rate': 9.824000000000001e-05, 'epoch': 12.86}
{'loss': 0.0396, 'learning_rate': 9.804e-05, 'epoch': 14.29}
{'loss': 0.0356, 'learning_rate': 9.784000000000001e-05, 'epoch': 15.71}
{'loss': 0.0324, 'learning_rate': 9.764000000000001e-05, 'epoch': 17.14}
{'loss': 0.0286, 'learning_rate': 9.744000000000002e-05, 'epoch': 18.57}
{'loss': 0.0277, 'learning_rate': 9.724000000000001e-05, 'epoch': 20.0}
{'loss': 0.0247, 'learning_rate': 9.704e-05, 'epoch': 21.43}
{'loss': 0.0217, 'learning_rate': 9.684000000000001e-05, 'epoch': 22.86}
{'loss': 0.0195, 'learning_rate': 9.664000000000001e-05, 'epoch': 24.29}
{'loss': 0.0193, 'learning_rate': 9.644e-05, 'epoch': 25.71}
{'loss': 0.0171, 'learning_rate': 9.624000000000001e-05, 'epoch': 27.14}
{'loss': 0.015, 'learning_rate': 9.604000000000001e-05, 'epoch': 28.57} 在int8精度下,扩大per_device_train_batch_size从4变成8,
LR=1e-4
MASTER_PORT=$(shuf -n 1 -i 10000-65535)
deepspeed --num_gpus=4 --master_port $MASTER_PORT main.py \
--deepspeed deepspeed.json \
--do_train \
--train_file AdvertiseGen/train.json \
--test_file AdvertiseGen/dev.json \
--prompt_column content \
--response_column summary \
--overwrite_cache \
--model_name_or_path THUDM/chatglm2-6b \
--output_dir ./output/adgen-chatglm2-6b-ft-$LR \
--overwrite_output_dir \
--max_source_length 64 \
--max_target_length 64 \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 1 \
--predict_with_generate \
--max_steps 5000 \
--logging_steps 10 \
--save_steps 100 \
--learning_rate $LR \
--fp16 \
--quantization_bit 8
观察显存占用和模型计算速度。
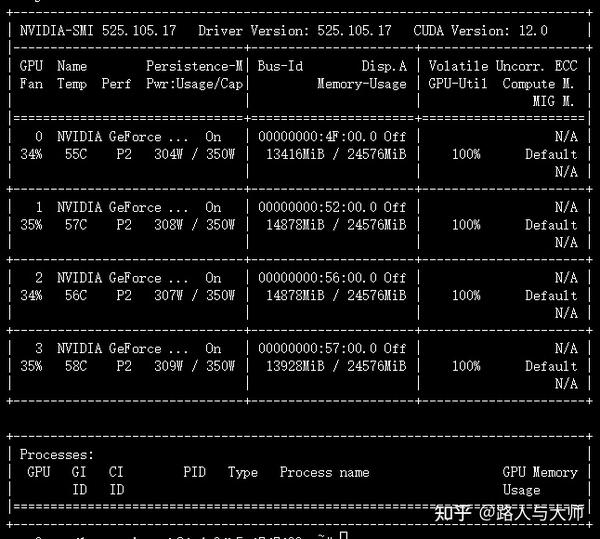
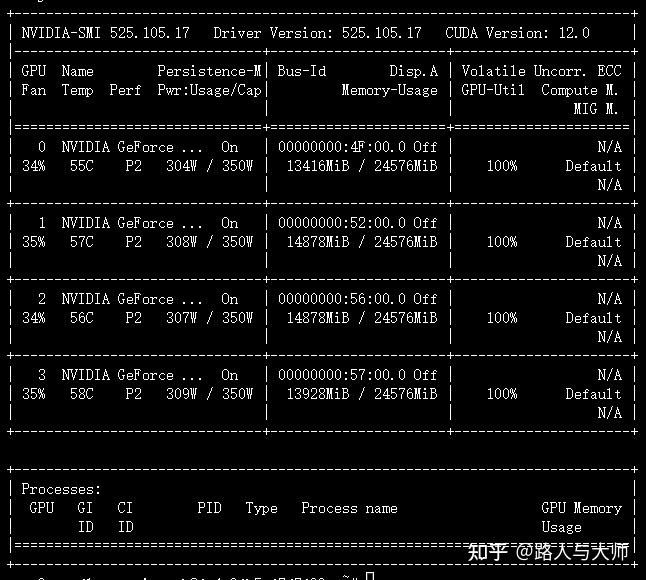
可以观察到将per_device_train_batch_size从4变成8后模型训练过程的显存占用由12.9GB变成了13.4GB显存占用。
接下来我们将per_device_train_batch_size从8变成16,观察模型训练过程中的显存占用情况。
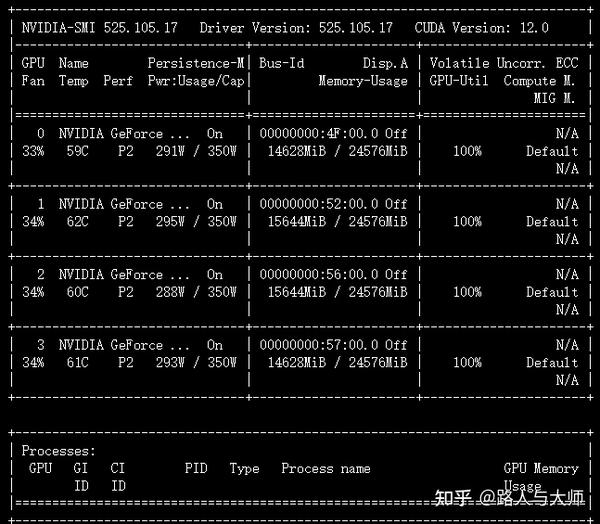
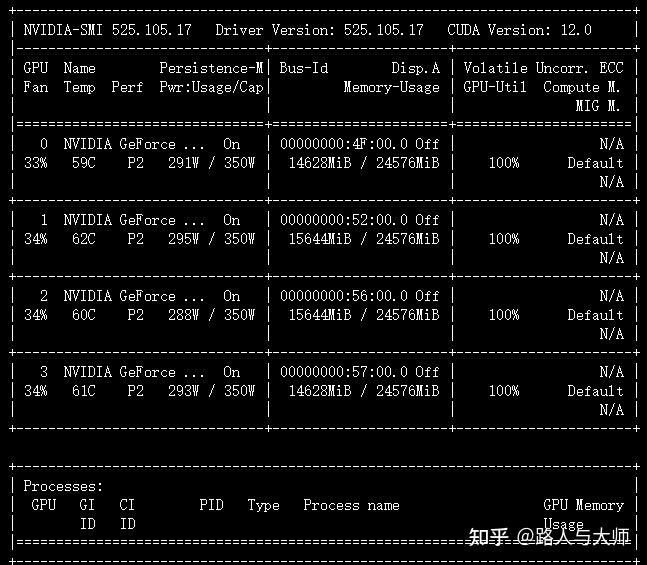
当我们将per_device_train_batch_size从8变成16之后观察到显存占用从13.4GB变成了14.6GB。
硬盘空间有限,只保存了3个check point,这里对第三个check point进行验证。因为设备是四卡的,所以这里我们的NUM_GPUS参数改成了4。同样验证过程中显存占用相关最重要的参数依旧是per_device_eval_batch_size 。
CHECKPOINT=adgen-chatglm2-6b-ft-1e-4
STEP=200
NUM_GPUS=4
torchrun --standalone --nnodes=1 --nproc-per-node=$NUM_GPUS main.py \
--do_predict \
--validation_file AdvertiseGen/dev.json \
--test_file AdvertiseGen/dev.json \
--overwrite_cache \
--prompt_column content \
--response_column summary \
--model_name_or_path ./output/$CHECKPOINT/checkpoint-$STEP \
--output_dir ./output/$CHECKPOINT \
--overwrite_output_dir \
--max_source_length 256 \
--max_target_length 256 \
--per_device_eval_batch_size 1 \
--predict_with_generate \
--fp16_full_eval
验证过程的显存占用及显卡利用率。
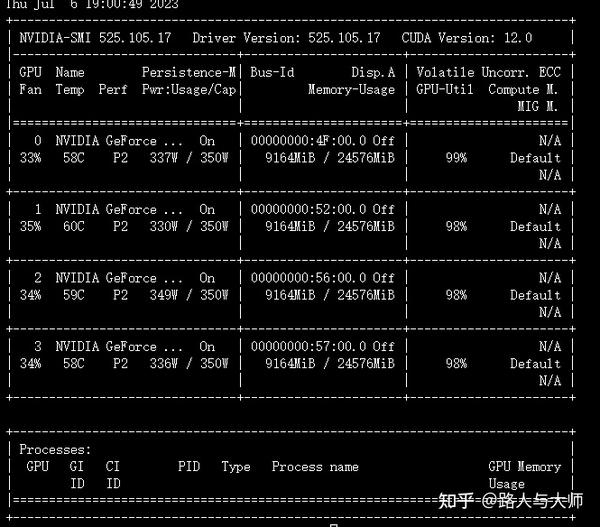
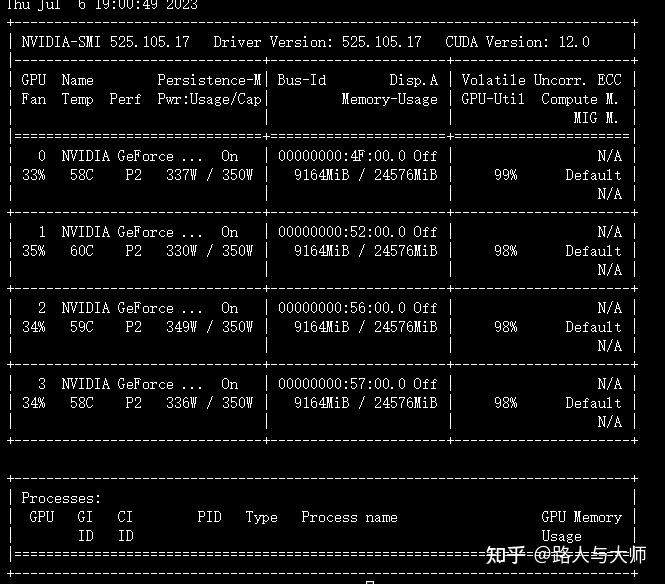
可以看出在per_device_eval_batch_size 为1的时候显存占用是9GB。
观察预测过程时间及模型训练性能如何。
***** predict metrics *****
predict_bleu-4 = 51.3677
predict_rouge-1 = 86.5608
predict_rouge-2 = 82.0982
predict_rouge-l = 70.5949
predict_runtime = 0:02:52.45
predict_samples = 108
predict_samples_per_second = 0.626
predict_steps_per_second = 0.157这里面predict_runtime 参数的含义是推理108数据所用的时间。
接下来加大per_device_eval_batch_size 参数,观察是否会提升模型验证过程的效率,减少模型验证过程的时间。
CHECKPOINT=adgen-chatglm2-6b-ft-1e-4
STEP=200
NUM_GPUS=4
torchrun --standalone --nnodes=1 --nproc-per-node=$NUM_GPUS main.py \
--do_predict \
--validation_file AdvertiseGen/dev.json \
--test_file AdvertiseGen/dev.json \
--overwrite_cache \
--prompt_column content \
--response_column summary \
--model_name_or_path ./output/$CHECKPOINT/checkpoint-$STEP \
--output_dir ./output/$CHECKPOINT \
--overwrite_output_dir \
--max_source_length 256 \
--max_target_length 256 \
--per_device_eval_batch_size 8 \
--predict_with_generate \
--fp16_full_eval
先大胆一些,将参数per_device_eval_batch_size 由之前的1改成8。可能出现的情况为显存溢出。
CHECKPOINT=adgen-chatglm2-6b-ft-1e-4
STEP=200
NUM_GPUS=4
torchrun --standalone --nnodes=1 --nproc-per-node=$NUM_GPUS main.py \
--do_predict \
--validation_file AdvertiseGen/dev.json \
--test_file AdvertiseGen/dev.json \
--overwrite_cache \
--prompt_column content \
--response_column summary \
--model_name_or_path ./output/$CHECKPOINT/checkpoint-$STEP \
--output_dir ./output/$CHECKPOINT \
--overwrite_output_dir \
--max_source_length 256 \
--max_target_length 256 \
--per_device_eval_batch_size 8 \
--predict_with_generate \
--fp16_full_eval
并没有出现显存溢出情况。对验证过程中的显存占用率和显卡计算占用率进行观察:
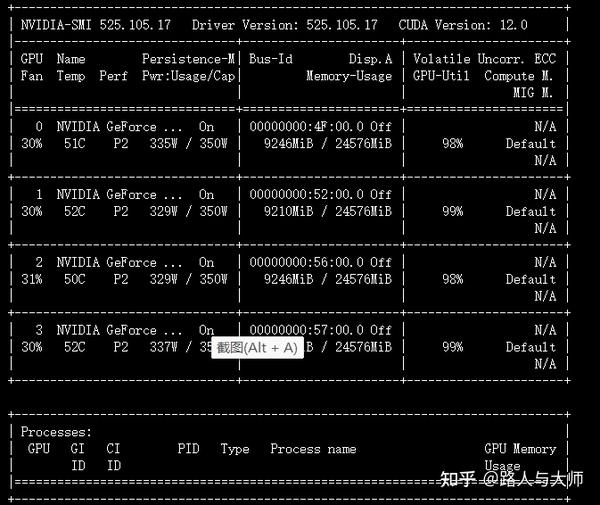
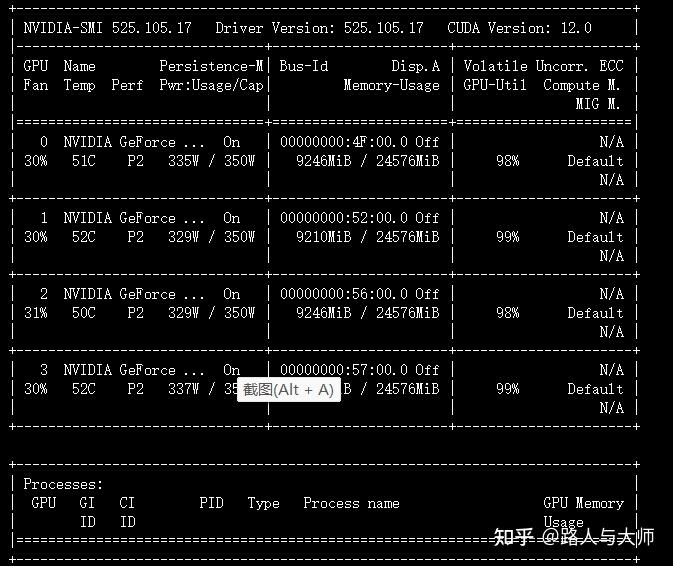
这里速度变快了,但是显存占用依旧是9GB。和之前的显存占用变大的假设相冲突。
对验证结果进行观察:
第100步的验证结果如下
***** predict metrics *****
predict_bleu-4 = 55.905
predict_rouge-1 = 87.7746
predict_rouge-2 = 83.8468
predict_rouge-l = 73.6103
predict_runtime = 0:00:53.68
predict_samples = 108
predict_samples_per_second = 2.012
predict_steps_per_second = 0.075第200步的验证结果如下
***** predict metrics *****
predict_bleu-4 = 51.2547
predict_rouge-1 = 86.4755