

Pytorch入门:3 语言模型


学习语言模型,以及如何训练一个语言模型
1 语言模型: 一句话(词组合出现的概率) P(W) = P(w_{1},w_{2},w_{3},w_{4},w_{5},...., w_{n})
2 语言模型遵循 链式法则
P(A, B) = P(A)P(B| A)
P(X_{1},X_{2},X_{3},......X_{n}) = P(X_{1}) P(X_{2}|X_{1})P(X_{3}|X_{1}, X_{2})...P(X_{n}|X_{1},.... ,X_{n-1})
3 应用到 语言模型 中:
P(W) = P(w_{1},w_{2},w_{3},w_{4},w_{5},...., w_{n})
P(w_{1}w_{2}...w_{n} = \prod_{i}^{} P(w_{i}| w_{1}w_{2}w_{3}....w_{i-1})
4 Marlov 假设
:每个单词只和它之前的n个单词有关。(n = 1)
评价语言模型:perplexity (困惑度) 越低效果越好
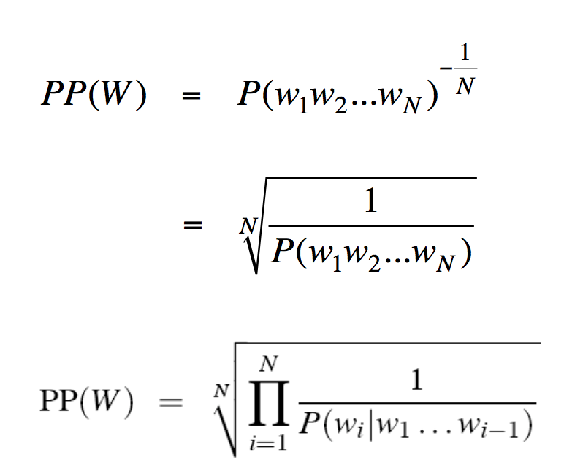

5 基于神经网络的语言模型(Neural Language Model)
根据前边的若干个单词预测后面的单词
P(w_{1}w_{2}...w_{n} = \prod_{i=1}^{m}P(w_{i}|w_{1},...,w_{i-1})\approx\prod_{i=1}^{m}P(w_{i}|w_{i-(n-1),....w_{i-1}})
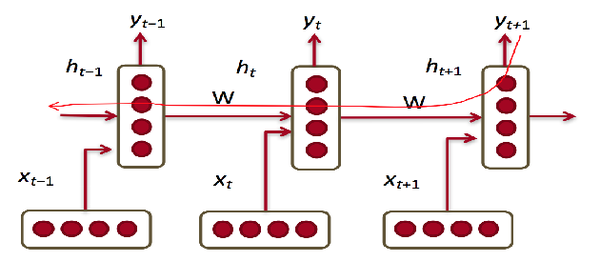
6 循环神经网络(Recurrent Nerual Network )
每一步参数W都固定
当前隐状态包含所有
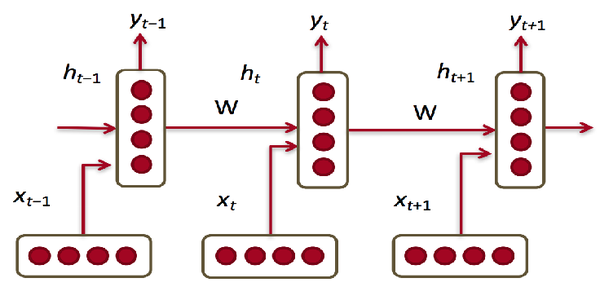

这个 y_{t-1} 为了预测 X_{t} ,拿到之后就是
给定一个单词作为输入,根据当前hidden state h_{t-1} 和 x_{t-1} 能做一个神经网络的操作,
x_{t-1} 这个单词,其实拿了上边 h_{t-2} 这个hidden state,生成 h_{t-1} 这个hidden state, 再做一个线性变换,能做一个神经网络的操作,拿到 h_{t} 可以预测下一个单词。
W2V输入矩阵和输出矩阵,但是一般保留输出矩阵,舍弃输出矩阵。
给定一列词向量
X_{1},...., X_{t-1},X_{t},X_{t+1}......X_{T}
h_{t}=\sigma(W^{(hh)}h_{t-1} + W^{hx}x_{[t]})
\tilde{y}_{t} = softmax(W^{(s)}h_{t})
\tilde{P}(x_{t+1} = v_{j}|x_{t},.....,x_{1}) = \tilde{y}_{t,j}
h_{t} :300 dim \hat{t} :50000 dim 的向量因为要在整个单词表上边进行预测 W^{(s)} : 5W * 300 维的一个向量,能把它转回到需要的单词表上
如何训练:Cross Entropy损失函数 训练损失函数,此函数需要被定义在每一个输出中。
text : 1->n
target : 2->n-1
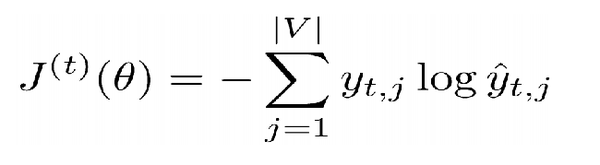

随机梯度下降 SGD,或者用ADAM ,RMSPROP 也可以
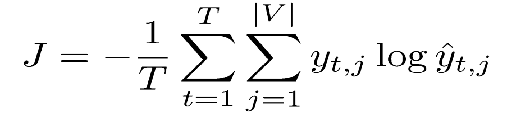

J是loss
但是训练RNN很难
梯度消失和爆炸问题

根据反向传播(链式法则),梯度会不断相乘,很容易梯度消失或者爆炸
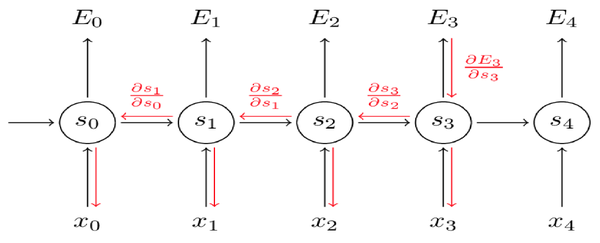

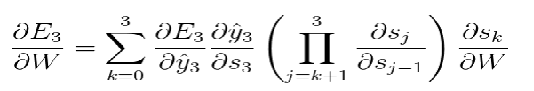

梯度消失:
深度神经网络都有这个问题,改进模型,使用ReLu(x) = max(0, x)
长期依赖问题,距离当前节点较远的信息不容易被RNN保留
7 长短记忆网络(Long Short-term Memory) [1]
LSTM是RNN的一种,大体结构几乎一样。区别是?
它的“记忆细胞”改造过。
该记的信息会一直传递,不该记的会被“门”截断。
LSTM提出的动机是为了解决上面我们提到的长期依赖问题。传统的RNN节点输出仅由权值,偏置以及激活函数决定(图3)。RNN是一个链式结构,每个时间片使用的是相同的参数。
而LSTM之所以能够解决RNN的长期依赖问题,是因为LSTM引入了门(gate)机制用于控制特征的流通和损失。对于上面的例子,LSTM可以做到在t9时刻将t2时刻的特征传过来,这样就可以非常有效的判断 t9 时刻使用单数还是负数了。LSTM是由一系列LSTM单元(LSTM Unit)组成,其链式结构如下图。
每个黄色方框表示一个神经网络层,由权值,偏置以及激活函数组成;每个粉色圆圈表示元素级别操作;箭头表示向量流向;相交的箭头表示向量的拼接;分叉的箭头表示向量的复制。
LSTM的核心部分是在图4中最上边类似于传送带的部分(图6),这一部分一般叫做单元状态(cell state)它自始至终存在于LSTM的整个链式系统中。
其中 f_t 叫做遗忘门,表示 C_{t-1} 的哪些特征被用于计算 C_t 。 f_t 是一个向量,向量的每个元素均位于 [0,1] 范围内。通常我们使用 sigmoid 作为激活函数, sigmoid 的输出是一个介于 [0, 1] 区间内的值,但是当你观察一个训练好的LSTM时,你会发现门的值绝大多数都非常接近0或者1,其余的值少之又少。其中 \otimes 是LSTM最重要的门机制,表示 f_t 和 C_{t-1} 之间的单位乘的关系。
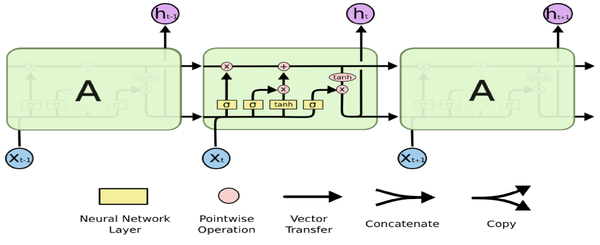

LSTM里有很多gate,
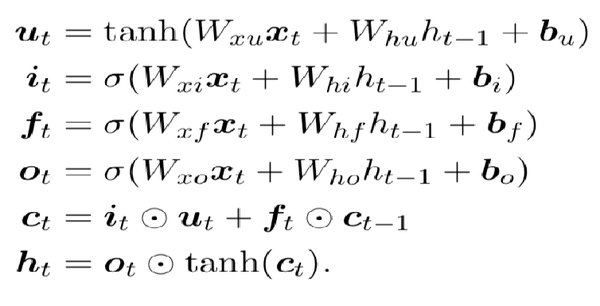

\tilde{C}_t 表示单元状态更新值,由输入数据 x_t 和隐节点 h_{t-1} 经由一个神经网络层得到,单元状态更新值的激活函数通常使用 tanh 。 i_t 叫做输入门,同 f_t 一样也是一个元素介于 [0, 1] 区间内的向量,同样由 x_t 和 h_{t-1} 经由 sigmoid 激活函数计算而成。
i_t 用于控制 \tilde{C}_t 的哪些特征用于更新 C_t ,使用方式和 f_t 相同。
最后,为了计算预测值 \hat{y}_t 和生成下个时间片完整的输入,我们需要计算隐节点的输出 h_t (图10)。
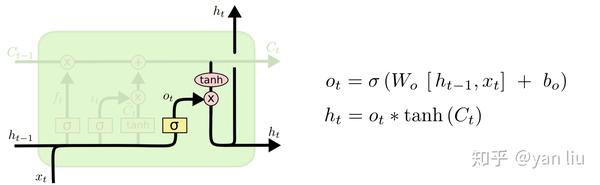
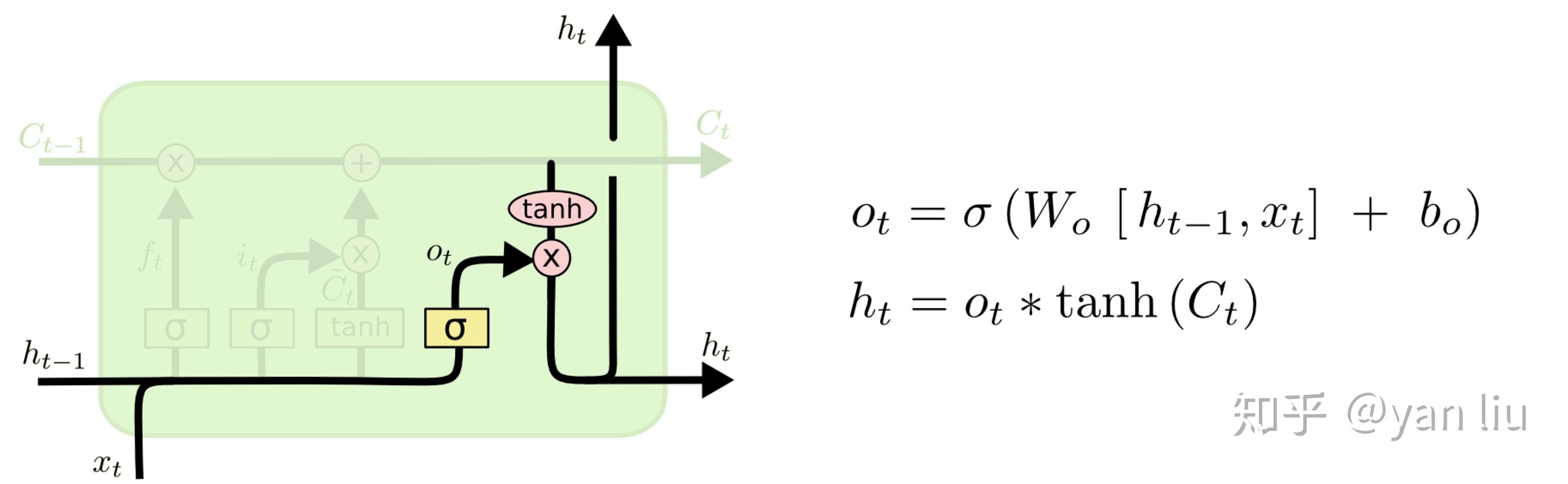
h_t 由输出门 o_t 和单元状态 C_t 得到,其中 o_t 的计算方式和 f_t 以及 i_t 相同。通过将 b_o 的均值初始化为 1 ,可以使LSTM达到同GRU近似的效果。(参考自 [2] )
LSTM同时传两个hidden state,上下有两条轨道要走。
8 Gated Recurrent Unit(GRU)


学习torchtext的基本使用方法
(见ipynb)
output.sape[2]和output.size(2)区别:圆括号和方括号区别。
构建一个 dictionary 并不难,需要:
1 build_vocab
2 把每一个单词变成一个index
