

SQL高级功能:窗口函数

1.什么是窗口函数
窗口函数可以进行排序,生成序列号等一般的聚合函数无法实现的高级操作。
窗口函数也叫OLAP(Online Analytical Processing)函数,即对数据库数据进行实时分析处理,窗口函数就是为了实现OLAP而添加的标准SQL功能
窗口函数语法:
<窗口函数> over ([partition by <用于分组的列名>])
order by <用于排序的列名>)窗口函数可以放以下两种函数:
1.rank , dense_ rank , row _number等专用窗口函数
2.能够作为窗口函数的聚合函数(sum , avg , count , max , min等)
由于窗口函数是对where或者group by子句处理后的结果进行操作,所以窗口函数原则上只能写在select字句中
2.如何使用窗口函数
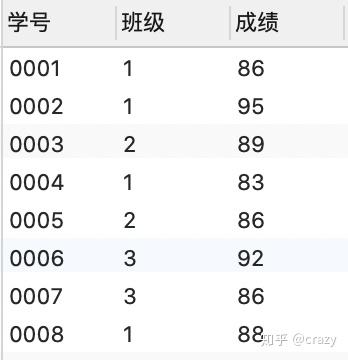
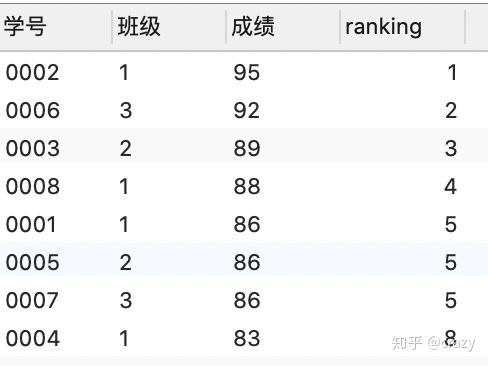
在每个班级内按成绩排名:
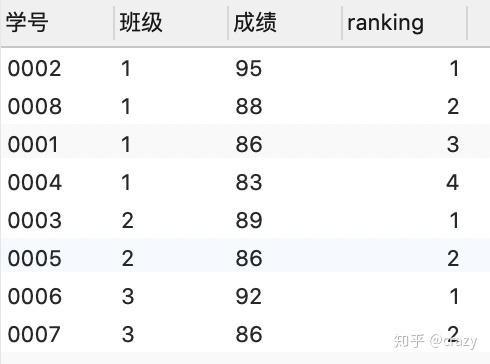
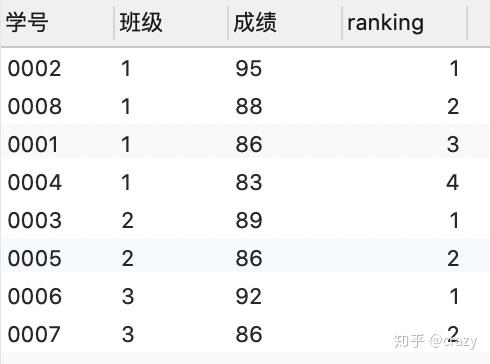
select*, rank() over (partition by 班级 order by 成绩 desc) as ranking
from 班级表;
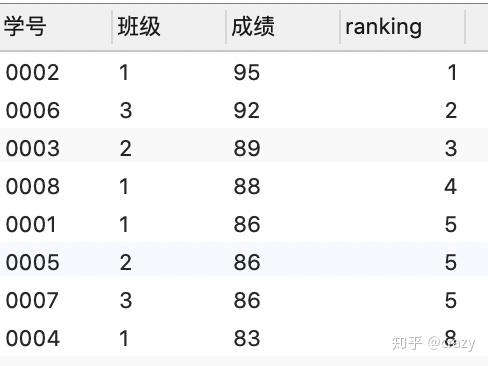
select*, rank() over (order by 成绩 desc) as ranking
from 班级表;partition by:功能类似于group by,对表进行分组即按班级来进行分组,若省略partition by子句,则将会对所有成绩排序
order by:对分组后的结果进行排序,desc表示降序排序
结果如下
窗口函数group by子句分组和order by字句排序的功能,但是,使用group by分组汇总后改变了表的行数,相当于根据分组的类别将同类的行合并了。同样使用班级表为初始表,具体代码及结果如下:
select 班级,count(学号)
from 班级表
group by 班级;
select 班级, count(学号) over (partition by 班级 order by 班级) as current_count
from 班级表;

总的来说,窗口函数在具有分组及排序的功能的同时还不会减少原表的行数。
3.其他专用窗口函数
窗口函数中关于排序三个窗口函数为rank , dense_ rank , row _number,这三个专用窗口函数的区别如下:
select*,rank() over (order by 成绩 desc) as ranking
from 班级表;
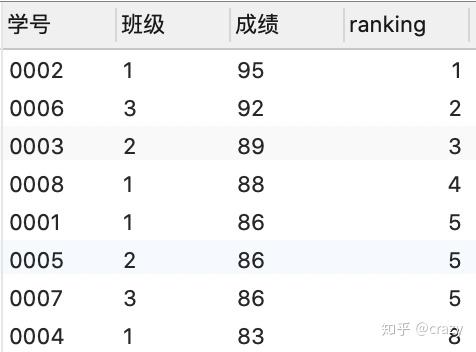
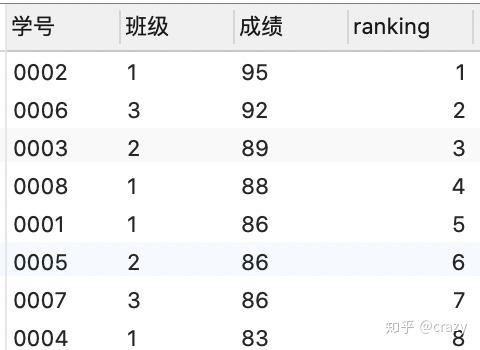
select*,dense_rank() over (order by
成绩 desc) as ranking
from 班级表;
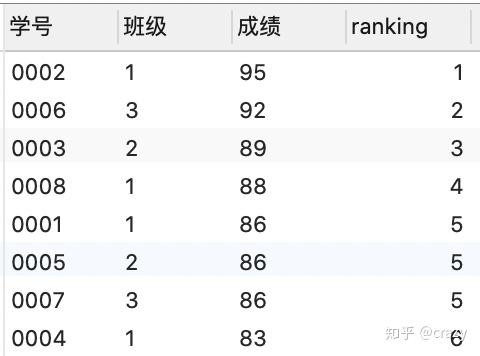
select*,row_number() over (order by 成绩 desc) as ranking
from 班级表;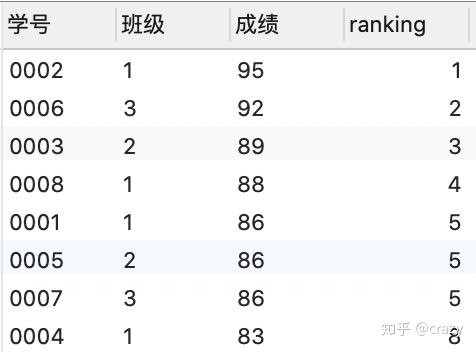

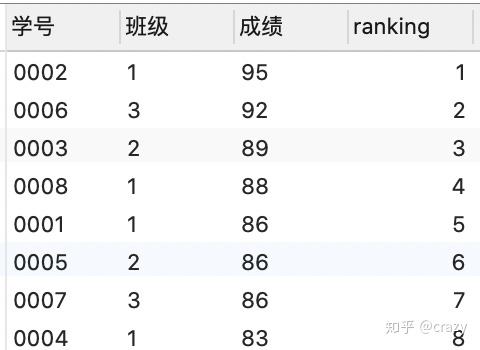
rank函数:若排名时有并列名次的行,会占用下一名次的位置,即如结果1所示,会有3个第五名但第五名之后就是第八名了。
dense_rank函数:若有并列名次的行,不占用下一名次的位置,即如结果2所示,即在3个第五名之后是第六名。
row_number函数:不考虑并列名次的情况,排名会对三个相同的成绩根据其他列的情况重新排名。
最后,在上述这三个专用窗口函数中,函数后面的括号不需要任何参数,保持()空着就可以了。
面试经典topN问题:

按课程号分组取成绩最大值所在行的数据
select*
from score as a
where 成绩 = (select max(成绩)
from score as b
where a.课程号= b.课程号 group by 课程号);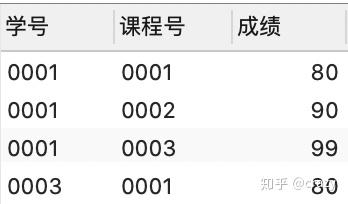
使用关联子查询可以达到目的,注意,子查询中必须添加where a.课程号 = b.课程号 的条件,否则,子查询返回多行的数据,会报错。程序无法运行。
-- 错误示范
select*
from score
where 成绩 = (select max(成绩) from score group by 课程号);

按课程号分组取成绩最小值所在行的数据
select*
from score as a
where 成绩 = (select min(成绩) from score as b where a.课程号 = b.课程号 group by 课程号);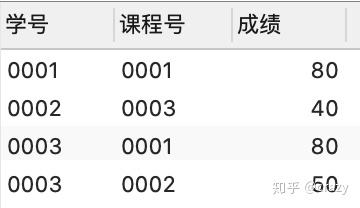
同样适用关联子查询可以达到目的。
查询每名学生成绩前两名的纪录
方法一:先使用group by 将课程分组,之后再通过order by对成绩排序,并用limit限制输出的行数,将每个学生最高的两门课的成绩取出来
(select*
from score
where 学号 = '0001'
order by 成绩 desc
limit 2)
union
(select*
from score
where 学号 = '0002'
order by 成绩 desc
limit 2)
union
(select*
from score
where 学号 = '0003'
order by 成绩 desc
limit 2);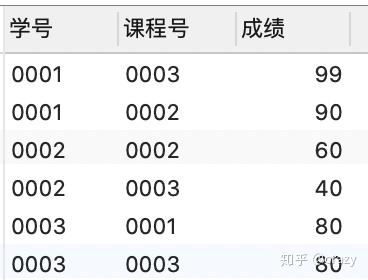
方法二:使用窗口函数
select*,row_number() over (partition by 学号 order by 成绩 desc) as ranking
from score;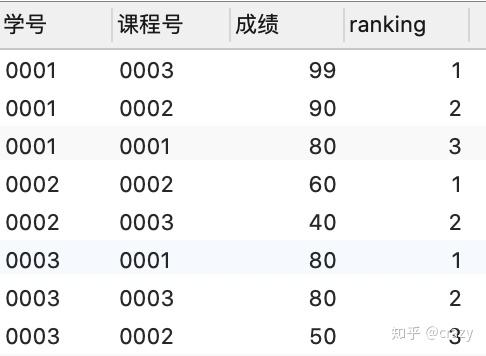
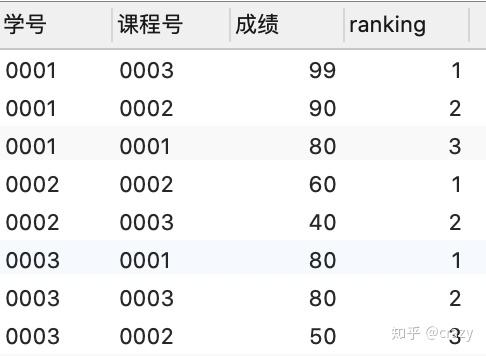
为得到每个学生成绩最高的两门课的成绩,需要加ranking<=2的条件
select *,row_number() over (partition by 学号 order by 成绩 desc) as ranking
from score
where ranking <=2;

直接在where之后加ranking<=2的条件是错误的,报错信息如上。这是因为select子句的运行顺序是在where子句之后的,在where子句运行时ranking这一列还没被定义。
正确代码如下:
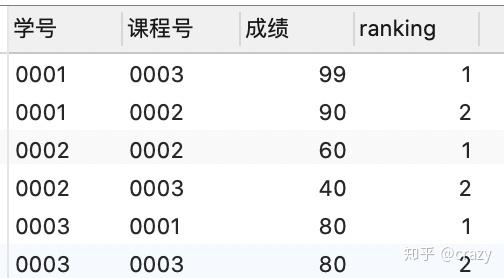
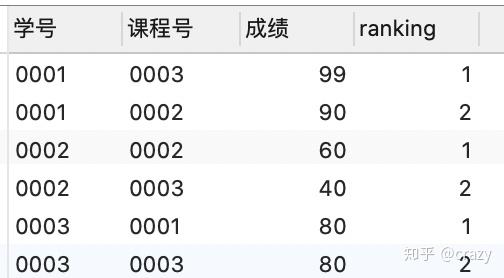
select *
from (select*,row_number() over (partition by 学号 order by 成绩 desc) as ranking
from score) as a
where ranking <=2;这里在from子句里使用了子查询,相当于通过窗口函数建立了一个新表
然后在新表中查找ranking<=2的行,得到的结果如下:
将此题的代码改一下,可以作为此类问题的常用解法,格式如下:
select*
from (select*,row_number() over
(partition by <要分组的列名> order by <要排序的列名> desc)
from <表名>) as a
where ranking [<=N];代码块中[]内的部分可以根据问题修改,查询每组最大/最小的N条记录
关于MySQL 8.0版本的其他窗口函数,具体介绍见:
4.聚合函数作为窗口函数
聚合窗口函数和上面提到的专用窗口函数用法完全相同,只需把聚合函数写在窗口函数的位置即可,但是函数后面括号不能为空,需要指定聚合的列名
以班级表为例:
-- 聚合函数的窗口函数
select*,
sum(成绩) over (order by 学号) as current_sum,
avg(成绩) over (order by 学号) as current_avg,
max(成绩) over (order by 学号) as current_max,
min(成绩) over (order by 学号) as current_min,
count(成绩) over (order by 学号) as current_count
from 班级表;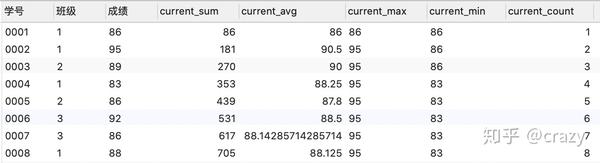
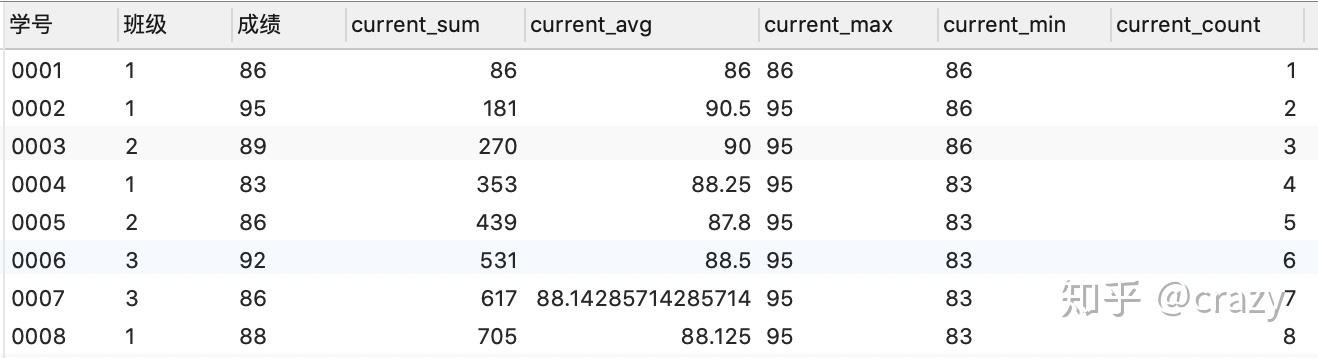
以sum函数举例, sum的窗口函数相当于是在对自身这一行的记录及位于自己记录之上的记录进行求和 ,比如:对于学号0005的这一行来说,current_sum就是对0001,0002,0003,0004,0005这五个学生的成绩求和,可得这五名学生的总成绩。
avg,max,min,count这些聚合函数的窗口函数都是同样的原理, avg(成绩)就是查询包括自身这一行在内以上所有行的平均值,max(成绩)就是查询包括自身一行在内以上所有行的最大值,min(成绩)就是查询包括自身一行在内以上所有行的最小值,count(成绩)就是查询包括自身一行在内以上所有行的行数
当我在窗口函数中加入基于班级的分组时,可得在对班级分组后在各班级内分别求和,求平均,查询最大,最小值以及计数。,结果如下:
select*,
sum(成绩) over (partition by 班级 order by 学号) as current_sum,
avg(成绩) over (partition by 班级 order by 学号) as current_avg,
max(成绩) over (partition by 班级 order by 学号) as current_max,
min(成绩) over (partition by 班级 order by 学号) as current_min,
count(成绩) over (partition by 班级 order by 学号) as current_count
from 班级表;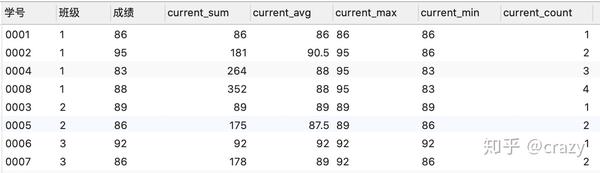
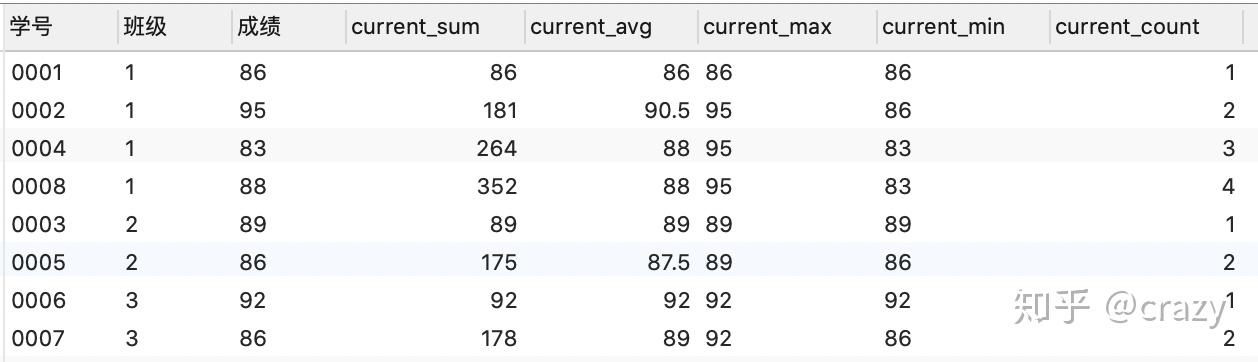
当没有order by时,代码及结果如下:
select*,
sum(成绩) over (partition by 班级) as current_sum,
avg(成绩) over (partition by 班级) as current_avg,
max(成绩) over (partition by 班级) as current_max,
min(成绩) over (partition by 班级) as current_min,
count(成绩) over (partition by 班级) as current_count
from 班级表;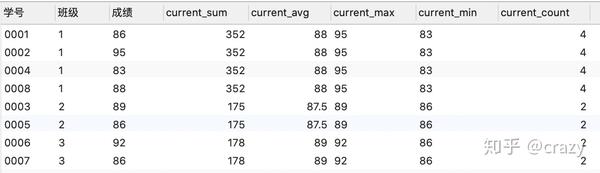
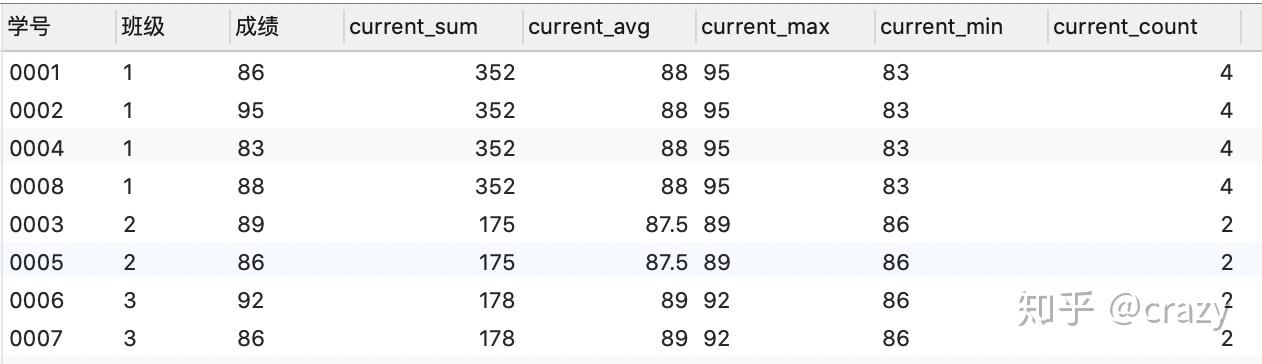
当无order by之后,窗口函数会在分组之后直接对每组的所有数据计算,又由于窗口函数并不会缩减行数,故每行的窗口函数结果相同。
聚合函数作为窗口函数,可以在每一行的数据里直观的看到,截止到本行数据,统计数据是多少(最大值,最小值等)。同时可以看到每一行数据,对整体统计数据的影响。
练习:
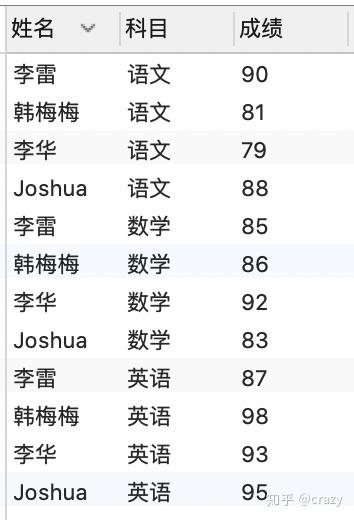
问题:查找单科成绩高于该科平均成绩的学生名单
此题的解题方法与求topN的问题的解法类似,都需要先重新查询建立一个新表,然后在新表中查询。具体代码,及结果如下:
-- 查询各科成绩高于该科目平均成绩的学生名单
-- 1.先找出各科的平均成绩
select*,avg(成绩) over (partition by 科目) as avg_socre
from 各科成绩表;
-- 2.找出各科高于平均成绩的学生
select*
from (
select*,avg(成绩) over (partition by 科目) as avg_score
from 各科成绩表) as a. -- 建立新表
where 成绩 > avg_score; -- 在新表中查询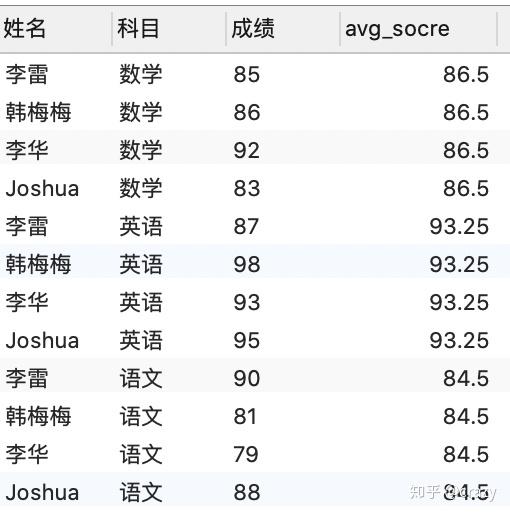
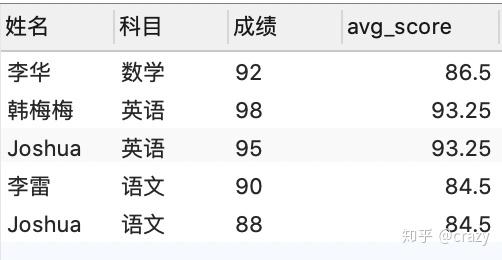
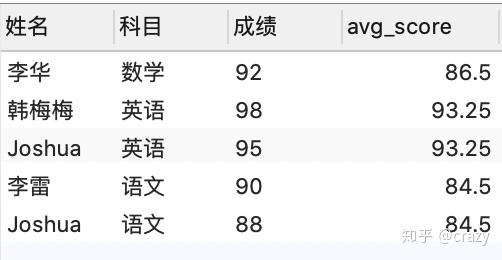
还有一种方法就是使用关联子查询,同样可以查询各科高于平均成绩的学生,代码及结果如下:
select*
from 各科成绩表 as a
where 成绩 >(select avg(成绩)
from 各科成绩表 as b
where a.科目 = b.科目