


缓存页面置换算法-LRU

Linux/Unix操作系统如何读写文件数据?
Linux/Unix系统下读写文件一般有两种方式: 传统输入输出(Input and Output,IO) 和 内存映射(Memory Map,MMAP)。
一、传统IO读写文件
传统IO的底层实现是通过调用 read() 和 write() 方法来实现的,实现的过程可以概括为图1所示的5个步骤:
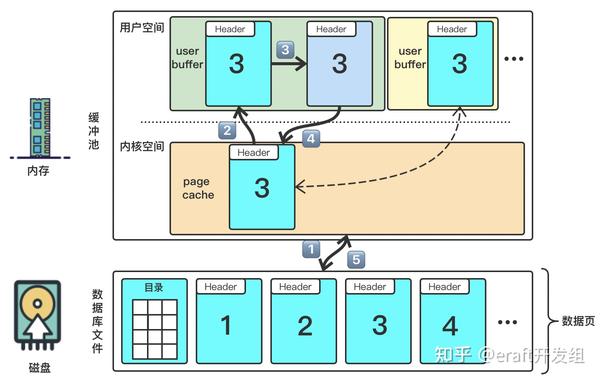
- 1⃣️:用户通过read()进程向操作系统发起调用,上下文从用户态转换到内核态,从磁盘中拷贝数据页到内核空间的页缓存(Page Cache,PC)。
- 2⃣️:由于内核空间中的页缓存不能被用户进程直接寻址,CPU需要把页缓存的数据拷贝到进程所对应用户空间的用户缓存区(User Buffer,UB),上下文由内核态转换到用户态,read()返回。
- 3⃣️:对用户缓存区中数据进行修改。
- 4⃣️:用户进程通过write()方法发起调用,上下文从用户态转为内核态,CPU将用户缓存区数据拷贝回页缓存。
- 5⃣️:内存数据写入磁盘文件,上下文由内核态再次回到用户态。
传统IO有何弊端?
- 从传统IO读取文件的过程中可以看出,用户进程读取磁盘中的数据页需要经历两次拷贝:磁盘->页缓存->用户缓存区,有没有一种方式能够在用户空间直接操作页缓存中的数据,避免页缓存->用户缓存区的拷贝呢?
- 图1中值得注意的是,当存在多个进程同时读取同一个磁盘数据页时,传统IO会在每个进程的用户缓存区中都拷贝一份数据页副本,这将造成数据页的冗余和物理内存的浪费。
二、内存映射mmap读写文件
通过内存映射的方式来读写文件可以看成是mmap和内存管理单元(Memory Management Unit, MMU)打的一套组合拳。首先由mmap完成磁盘文件到 虚拟内存地址 的映射,再通过MMU进行地址转换,将 虚拟内存地址转化为物理地址 对数据进行操作,同时,每个进程都会在用户空间中维护一张 页表 ,判断一个 虚拟页 是否已经在物理内存中存在。这种读写文件的方式无需经历”页缓存->用户缓存区“的拷贝,且由于虚拟内存的存在,每个进程无需拷贝相同的数据页副本,有效改善了传统IO读写的两个弊端,使得用户进程访问文件就像在访问内存一样,如图2所示。
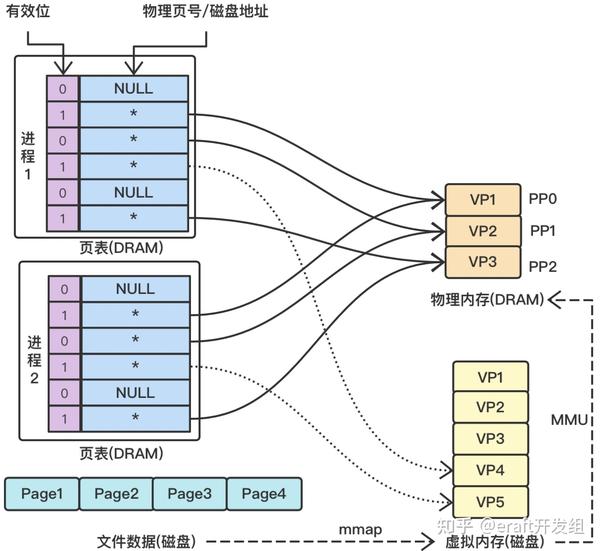
图中涉及到一些未接触过的概念,可能会带来理解上的困难,下面对这些概念做了一下总结:
- 虚拟内存 :从概念上来说,虚拟内存被组织成一个存放在磁盘中的数组,包含N个连续字节大小的单元,也就是字节数组,每个字节都有 唯一 一个虚拟地址作为数组的索引。虚拟内存将主存看成一个磁盘的高速缓存,主存中只保存活动区域,并根据需要在磁盘和主存之间来回传送数据 。 虚拟内存被分割为大小固定的 虚拟页 (Virtual Page, VP)。
- 物理内存 :物理内存是相对与虚拟内存而言的,通俗点来说就是主板内存槽上插入的内存条容量大小,类似的,物理内存被分割为固定大小的 物理页 (Physical Page, PP)。
- 页表 :包含有效位和物理页号或者磁盘地址,用来判断虚拟页是否存在于物理内存中。
数据访问流程
mmap()的调用回返回一个指针ptr,指向虚拟内存地址,但是需要注意的是,虚拟内存中并不会真的拷贝文件数据,所以接下来必须由MMU将虚拟内存地址转换为物理地址,在物理地址上进行数据拷贝,展开相关操作。通过构建的内存映射就可以像操作内存一样对磁盘文件数据进行处理,进程无需调用read()和write()方法。
缺页现象&缓存页面置换
仔细的读者通过观察图2能够发现:按照上述数据读取流程,当进程通过mmap()拿到的ptr指针指向虚拟页VP4/VP5的时候,由MMU完成地址转换,发现物理内存不够,并且找不到与ptr相对应的物理地址时,应该怎么办呢?这种现象称为 缺页 。为了把VP4从磁盘中拷贝到物理内存,需要从物理内存中调度一个 牺牲页 ,将其从物理内存拷贝到磁盘中,以保持物理内存原有大小,这个过程称之为 缓存页面置换 。如何进行牺牲页的选取,使得页面调度次数尽可能的少是衡量一个页面置换算法性能的重要指标。理想情况下,每次调换出的页面应是所有内存页面中最迟将被使用的,这可以最大限度的减少页面调度。基于这个思想,衍生出了很多页面置换算法向该理想情况靠拢,典型的页面置换算法有:OPT、FIFO、 LRU 等。
LRU页面置换算法
LRU 算法的设计原则是: 如果一个数据在最近一段时间没有被访问到,那么在将来它被访问的可能性也很小。 也就是说,当物理内存空间已存满数据时,应当把最久没有被访问到的数据淘汰,其算法工作流程如图3所示。
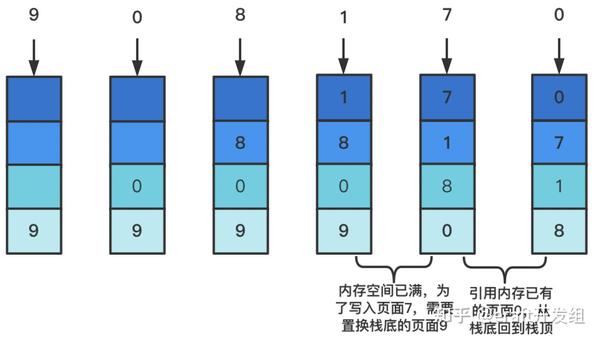
为了能够从LRU的工作流程抽象出其算法设计,将自己带入图3的流程来总结一下LRU到底做了什么:
*写入页面9、0、8、1时,都使用的是相同的逻辑:
1.先判断栈中是否已经存在需要写入的数据页,发现并不存在。
2.判断栈是否已满,发现未满,将数据页写入栈底。
*写入页面7时:
1.先判断栈中是否已经存在需要写入的数据页,发现并不存在。
2.判断栈是否已满,发现已满。
3.调出栈底数据页0,在栈顶添加数据页7。
*引用页面0时:
将页面0从原位置调出,并重新放置到栈顶。不难发现,在模拟LRU的工作流程时,可以从两个方面进行代码抽象: 数据写入 和 数据引用 ,抽象出的LRU逻辑伪代码如下:
写入数据():
if 数据页未存在于栈中:
if 栈未满:
添加数据页到栈顶;
else:
调出栈底数据页,添加数据页到栈底;
else://数据页已存在于栈
从栈中调出已存在数据页,更新数据并重新写入栈顶;
引用数据():
从栈中调出引用数据页,重新写入栈顶;
LRU算法实现(C++、Java代码)
根据上节中抽象出的LRU伪代码,通过哈希表+双向链表来进行代码实现。哈希表用来存储<key, 指向双向链表中key节点的指针>。双向链表用来模拟图3的栈结构,记录节点顺序,head最近访问的节点,tail为最久访问的节点,如图4所示:
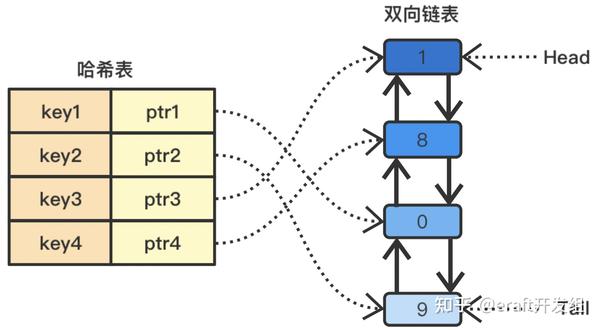
至此伪代码可具像化为:
put(key, value){
if(key in map){//key已经存在于双向链表中
removeNode(key_ptr);//调出节点
addNode(key_ptr);//添加节点至头部
}else{
Node* newNode= new Node;
if(链表长度>链表容量){//超出缓存范围需要删除尾部结点
//调出尾部结点
removeNode(Tail);//从双向链表中删除
map.erase(Tail_key);//从map中删除
delete Tail_ptr;//从缓存中删除开辟过的空间
//添加新节点
addNode(newNode);//在链表中添加新节点
map[key] = newNode;//在哈希表中添加新节点
get(key){
if(key in map){//key已经存在
removeNode(key_ptr);
addNode(key_ptr);
}else{
"返回未找到数据";
到此,LRU的代码框架已经初步成型,接下来将removeNode()、addNode等函数逐一实现后,得到完成的LRU代码:
//双向链表
struct DLinkedNode{
int key;
int value;
DLinkedNode* pre;
DLinkedNode* next;
DLinkedNode(int k, int v){
this->key = k;
this->value = v;
this->pre = NULL;
this->next = NULL;
class cache{
private:
int count;
int capacity;
DLinkedNode* Phead;//头指针
DLinkedNode* Ptail;//尾指针
map<int,DLinkedNode*> mp;
public:
//构造函数
cache(int capacity){
this->capacity = capacity;//链表容量
this->count = 0;//当前链表长度
this->Phead = NULL;
this->Ptail = NULL;
//稀构函数
~cache(){
map<int, DLinkedNode*>::iterator it = mp.begin();
for(;it!=mp.end();){
delete it->second;
it->second = NULL;
mp.erase(it++);
this->count--;
delete Phead;
Phead = NULL;
delete Ptail;
Ptail = NULL;
//调出节点
void removeNode(DLinkedNode* p){
if(p->pre==NULL){//头节点
Phead = p->next;
Phead->pre = NULL;
}else if(p->next==NULL){//尾节点
Ptail = p->pre;
Ptail->next = NULL;
}else{//中间结点
p->next->pre = p->pre;
p->pre->next = p->next;
//添加节点
void addNode(DLinkedNode* p){
p->next = Phead;
p->pre = NULL;
if(Phead==NULL){
Phead = p;
}else{
Phead->pre = p;
Phead = p;
if(Ptail==NULL){
Ptail = Phead;
int getCount(){
return this->count;
//调出节点并重新添加至头部
void moveToHead(DLinkedNode* p){
removeNode(p);
addNode(p);
int get(int k){
map<int, DLinkedNode*>:: iterator it = mp.find(k);
if(it!=mp.end()){//key已经存在
DLinkedNode* node = it->second;
removeNode(node);
addNode(node);
return node->value;
}else{//没找到
return -1;
void put(int k, int v){
map<int, DLinkedNode*>:: iterator it = mp.find(k);
if(it!=mp.end()){//key存在
DLinkedNode* node = it->second;
removeNode(node);
node->value = v;
addNode(node);
}else{//key不存在
this->count++;
DLinkedNode* newNode = new DLinkedNode(k,v);//new一个内存,记得要delete掉!!!
if(this->count>this->capacity){//超出缓存范围需要删除尾部结点
//在map中找到取出尾部key值,并删除
map<int,DLinkedNode*>::iterator it = mp.find(Ptail->key);//先取出尾部结点的迭代器
removeNode(this->Ptail);
mp.erase(it);//从map中删除
delete it->second;//从缓存中删除开辟过的空间
this->count--;
addNode(newNode);
mp[k] = newNode;
下面提供一段测试代码,读者可自行设置断点,查看详细的数据结构:
int main(){
cache* c = new cache(3);
c->put(1,1);
cout << c->getCount() << endl;//1
c->put(2,2);
cout << c->getCount() << endl;//2
c->put(3,3);
cout << c->getCount() << endl;//3
cout << c->get(1) << endl;//1
c->put(6,6);
cout << c->getCount() << endl;//3
cout << c->get(2) << endl;//-1
return 0;
};
Java代码实现(双向链表Head和Tail单独设置了一个节点):
import java.lang.invoke.VarHandle;
import java.util.concurrent.ConcurrentHashMap;
//HashMap + 双向链表
public class LRU {
class DLinkedNode {
String key;
int value;
DLinkedNode pre;
DLinkedNode next;
private ConcurrentHashMap<String, DLinkedNode> cache = new ConcurrentHashMap<String, DLinkedNode>();
private int count;
private int capacity;//缓存容量
private DLinkedNode head, tail;
public void initCapacity(int capacity) {
this.count = 0;//当时缓存容量
this.capacity = capacity;
this.head = new DLinkedNode();
head.pre = null;
this.tail = new DLinkedNode();
tail.next = null;
head.next = tail;
tail.pre = head;
public void removeNode(DLinkedNode node) {
DLinkedNode pre = node.pre;
DLinkedNode next = node.next;
pre.next = next;
next.pre = pre;
public void addNode(DLinkedNode node) {
//添加到head后面
node.next = head.next;
node.pre = head;
head.next.pre = node;
head.next = node;
public void moveToHead(DLinkedNode node) {
removeNode(node);
addNode(node);
public DLinkedNode popTail() {
DLinkedNode pop = tail.pre;
removeNode(pop);
return pop;
public int get(String k) {
DLinkedNode dLinkedNode = cache.get(k);
if (dLinkedNode == null) {
return -1;
} else {
moveToHead(dLinkedNode);
return dLinkedNode.value;
public void put(String k, int v) {
DLinkedNode dLinkedNode = cache.get(k);
if (dLinkedNode != null) {
dLinkedNode.value = v;
moveToHead(dLinkedNode);
return;
DLinkedNode dLinkedNode1 = new DLinkedNode();
dLinkedNode1.key = k;
dLinkedNode1.value = v;
cache.put(k, dLinkedNode1);
addNode(dLinkedNode1);
++count;
if (count > capacity) {
DLinkedNode pop = popTail();
cache.remove(pop.key);
count--;
public static void main(String[] args) {
LRU lru = new LRU();
lru.initCapacity(3);
lru.put("a", 1);