import pandas as pd
empty_df = pd.DataFrame(columns=['A','B','C','D'])
创建了四列,每一列的内容都是空的
df.shape
df.groupby('column_name').count()
a=pd.DataFrame({'a':[1,2,3],'b':[2,3,4]})
b=pd.DataFrame({'a':[11,22,33],'c':[22,33,44]})
c=pd.merge(a,b)
a和b的同名列表被合并,但是都是空说明默认连接形式是内连接,即二者默认把相同列名作为查找的条件,若是查找不到相同的值返回空。
c=pd.merge(a,b,how='outer',on='a')
pd.concat(a,b)
pd.concat([a,b], axis=1)
pd.concat([a,b], axis=0)
TypeError: first argument must be an iterable of pandas objects, you passed an object of type "DataFrame"
使用pandas.concat(a,b)进行合并的时候,需要是list的形式
pd.concat([a,b])

它把a,b两个表完全拼接在一起,默认拼接形式是并集,我们可以通过修改参数来修改拼接模式,以及拼接方向,也可以重述索引。
d=pd.concat([a,b])
d.index=list(range(0,6))
通过赋值语句可以使得单列数据的拼接。
e=pd.Series(list('abc'))
a['c']=e
a.join(b)
ValueError: columns overlap but no suffix specified: Index(['a', 'c'], dtype='object')
列表不能有重名
- iterrows(): 按行遍历,将DataFrame的每一行迭代为(index, Series)对,可以通过row[name]对元素进行访问。
- itertuples(): 按行遍历,将DataFrame的每一行迭代为元祖,可以通过row[name]对元素进行访问,比iterrows()效率高。
- iteritems():按列遍历,将DataFrame的每一列迭代为(列名, Series)对,可以通过row[index]对元素进行访问。
inp = [{'c1':10, 'c2':100}, {'c1':11, 'c2':110}, {'c1':12, 'c2':123}]
df = pd.DataFrame(inp)
row[‘name’]
for index, row in df.iterrows():
print(index, row['c1'], row['c2'])
0 10 100
1 11 110
2 12 123
getattr(row, ‘name’)
for row in df.itertuples():
print(getattr(row, 'c1'), getattr(row, 'c2'))
10 100
11 110
12 123
row[index]
for index, row in df.iteritems():
print(index, row[0], row[1], row[2])
c1 10 11 12
c2 100 110 123
https://blog.csdn.net/sinat_29675423/article/details/87972498
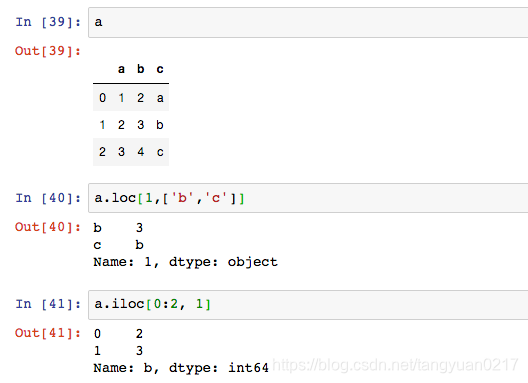
pandas提供了专门的用于索引DataFrame的方法,如果要是用标签,最好使用loc方法,如果使用下标,最好使用iloc方法:
基础知识总结
https://www.jianshu.com/p/8024ceef4fe2
初始化空的DataFrameimport pandas as pdempty_df = pd.DataFrame(columns=['A','B','C','D'])创建了四列,每一列的内容都是空的展示数据规模1、行数和列数df.shape2、按某一列名统计数据df.groupby('column_name').count()DataFrame数据拼接合并pd.merge()a=pd.DataFrame({'a':[1,2,3],'b':[2,3,4]})b=pd.Data
Python零基础速成班,适用于入门或初级学习人群,采用Jupyter Notebook原装教程,.ipynb格式拷贝到Jupyter Notebook目录下即可运行,网页交互式可视化Python编程,全中文注解,下载即用,对初学者非常友好,也可作为Python程序员基础知识的补充再学习材料。
本教程由专业老师设计,由浅入深,带你扎实学习Python知识,附带的课后练习题精心设计,作为学习后知识的巩固和提升。
本教程设置3级标题,对知识点进行分类,内容上由基础+进阶的方式呈现,练习题也设置了必做和挑战项目,分别适用于初学者和进阶学习者。
整个教程大概有80个学时,同时也引入图像识别基础、算法基础、小游戏、爬虫、API设计基础、Excel文档操作、Numpy、Pandas、Matplotlib画图、数据库基础、网页WEB编程和Flask框架基础等,完成后将达到初级Python程序员水平。
import pandas as pd
import numpy as np
df = pd.DataFrame(np.arange(12).reshape(3,4),columns = list('甲乙丙丁'),
index = ["one","two","three"])
2.查看行索引,列索引
df.index
df.columns
3.增加、删除列
import pandas as pd
impor
文章目录一.简介二.创建三.操作1.查看
DataFrame是一个二维的表格型结构,可以视为Series的容器,规定每一列所有元素的数据类型必须相同,不同列的元素数据类型可以不同
DataFrame有行索引和列索引,分别可以用index和columns进行查看
库的导入:
import numpy as np
import pandas as pd
利用DataFrame函数进行创建
参数可以为:
①python字典型
dict={
"时间":pd.date_range("
属性和数据
DataFrame.axes #index: 行标签;columns: 列标签
DataFrame.as_matrix([columns]) #转换为矩阵
DataFrame.dtypes #返回数据的类型
DataFrame.f
index: Optional[Axes]=None, # 行标
columns: Optional[Axes]=None, # 列标
dtype: Optional[Dtype]=None, # 存储的数据类型
copy: bool=False)
我们可以直接创建空的dataframe,也可以在创造时就输入数据。
创建一个简单的dataframe:
import panda
遍历 dataframe 可以使用 pandas 库提供的 iterrows() 方法。iterrows() 方法会返回一个包含每行数据的迭代器,每一行数据包含该行的索引和所有列的值,可以使用 for 循环遍历这个迭代器并处理每一行的数据。
例如,假设有一个名为 df 的 dataframe,可以按如下方式遍历每一行:
import pandas as pd
# 创建示例 dataframe
df = pd.DataFrame({
'姓名': ['张三', '李四', '王五'],
'年龄': [20, 30, 40],
'性别': ['男', '男', '女']
# 使用 iterrows() 方法遍历每一行
for index, row in df.iterrows():
print(f'第 {index+1} 行数据:')
print(f'姓名:{row["姓名"]}')
print(f'年龄:{row["年龄"]}')
print(f'性别:{row["性别"]}')
输出结果为:
第 1 行数据:
姓名:张三
年龄:20
第 2 行数据:
姓名:李四
年龄:30
第 3 行数据:
姓名:王五
年龄:40


