



US Accidents 美国交通事故分析

数据来源
从2016/02到2019/12美国49州所有交通事故数据集,包含300万行,一共49列,1个G的数据.
分析目的
①哪个州事故发生的最多?
②哪个时间最容易发生事故,发生的事故是怎么样一个变换趋势?
③事故与天气有什么样的关系?
数据理解
通过在Kaggle中的详情知道数据各个字段的含义如下.
ID 事故标识符 。 Source 事故数据来源。 TMC 交通事故可能具有交通消息通道(TMC)代码,该代码可提供事件的更详细描述 。Severity 显示事故的严重程度,1最小,4最严重的的影响 。 Start_Time 在本地时区显示事故的开始时间。 End_Time 在当地时区显示事故的结束时间。 Start_Lat 在起点的GPS坐标中显示纬度。 Start_Lng 在起点的GPS坐标中显示经度。 End_Lat 在终点的GPS坐标中显示纬度。 End_Lng 在终点的GPS坐标中显示经度。 Distance(mi) 受事故影响的道路范围的长度(英里)。 Description 显示事故的自然语言描述。 Number 在地址栏中显示街道号码。 Street 在地址字段中显示街道名称。 Side 在地址字段中显示街道的相对侧(右/左)。 City 在地址字段中显示城市。 County 在地址栏中显示县 State 在地址字段中显示状态。 Zipcode 在地址字段中显示邮政编码。 Country 在地址字段中显示国家。 Timezone 根据事故地点(东部,中部等)显示时区。 Airport_Code 表示一个基于机场的气象站,它离事故地点最近。 Weather_Timestamp 显示天气预报的时间戳(以当地时间为单位)。 Temperature(F) 显示温度(以华氏度为单位)。 Wind_Chill(F) 显示风寒(华氏度)。 Humidity(%) 显示湿度(百分比)。 Pressure(in) 显示气压(以英寸为单位)。 Visibility(mi) 显示可见性(以英里为单位)。 Wind_Direction 显示风向。 Wind_Speed(mph) 显示风速(以英里/小时为单位)。 Precipitation(in) 显示降水量(以英寸为单位)(如果有)。 Weather_Condition 显示天气状况(雨,雪,雷暴,雾等)。 Amenity 兴趣点(POI)批注,指示附近有便利设施。 Bump 一个POI注释,指示附近有减速带或驼峰。 Crossing 一个POI注释,指示附近有交叉路口。 Give_Way 一个POI注释,指示在附近位置存在Give_way标志。 Junction 一个POI注释,指示附近有交界处。 No_Exit 指示附近位置存在no_exit标志的POI注释。 Railway 一个POI注释,指示附近有铁路。 Roundabout 一个POI注释,指示附近有回旋处。 Station 一个POI注释,指示附近位置有车站(公交车,火车等)。 Stop 一个POI注释,指示在附近位置存在停车标志。 Traffic_Calming 指示在附近位置存在traffic_calming装置的POI注释。 Traffic_Signal 一个POI注释,指示在附近位置存在交通标识。 Turning_Loop 一个POI注释,指示在附近的位置是否存在转弯提示。 Sunrise_Sunset 根据日出/日落显示白天(即白天或晚上)。 Civil_Twilight 显示基于民间暮光的白天时段(即白天或晚上)。 Nautical_Twilight 显示基于航海暮光的白天时段(即白天或晚上)。 Astronomical_Twilight 根据天文暮光显示白天(即白天或晚上)。
可以看出,数据量十分巨大,不适合使用Excel进行分析。选择Python进行处理,IDE选择Jupyter Notebook。
数据处理
1.导入数据
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_csv("./US_Accidents_Dec19.csv", sep=',')#使用逗号分隔各列数据,不传sep这个参数会导致打开的数据只有一列
直接使用pandas进行CSV读取
2.查看数据行列数
data.shape
#输出 (2974335, 49)
#数据集大概300W行,49列
3.查看数据概述信息
data.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 2974335 entries, 0 to 2974334 Data columns (total 49 columns):
ID object
Source object
TMC float64
Severity int64
Start_Time object
End_Time object
Start_Lat float64
Start_Lng float64
End_Lat float64
End_Lng float64
Distance(mi) float64
Description object
Number float64
Street object
Side object
City object
County object
State object
Zipcode object
Country object
Timezone object
Airport_Code object
Weather_Timestamp object
Temperature(F) float64
Wind_Chill(F) float64
Humidity(%) float64
Pressure(in) float64
Visibility(mi) float64
Wind_Direction object
Wind_Speed(mph) float64
Precipitation(in) float64
Weather_Condition object
Amenity bool
Bump bool
Crossing bool
Give_Way bool
Junction bool
No_Exit bool
Railway bool
Roundabout bool
Station bool
Stop bool
Traffic_Calming bool
Traffic_Signal bool
Turning_Loop bool
Sunrise_Sunset object
Civil_Twilight object
Nautical_Twilight object
Astronomical_Twilight object
dtypes: bool(13), float64(14), int64(1), object(21) memory usage: 853.8+ MB
49列数据的列名,数据类型,但未能从此概述信息中看出缺失信息。选择另外一个函数查看。
4.查看数据缺失值
data.isnull().sum()
ID 0
Source 0
TMC 728071
Severity 0
Start_Time 0
End_Time 0
Start_Lat 0
Start_Lng 0
End_Lat 2246264
End_Lng 2246264
Distance(mi) 0
Description 1
Number 1917605
Street 0
Side 0
City 83
County 0
State 0
Zipcode 880
Country 0
Timezone 3163
Airport_Code 5691
Weather_Timestamp 36705
Temperature(F) 56063
Wind_Chill(F) 1852623
Humidity(%) 59173
Pressure(in) 48142
Visibility(mi) 65691
Wind_Direction 45101
Wind_Speed(mph) 440840
Precipitation(in) 1998358
Weather_Condition 65932
Amenity 0
Bump 0
Crossing 0
Give_Way 0
Junction 0
No_Exit 0
Railway 0
Roundabout 0
Station 0
Stop 0
Traffic_Calming 0
Traffic_Signal 0
Turning_Loop 0
Sunrise_Sunset 93
Civil_Twilight 93
Nautical_Twilight 93
Astronomical_Twilight 93
dtype: int64
可以看出缺失值较多,不适合使用通用填充法填充。选择不填充,等需要用到该列数据时单独进行缺失值填充。
数据分析
①事故发生最多的州
data.State.value_counts()
CA 663204
TX 298062
FL 223746
SC 146689
NC 142460
NY 137799
PA 90395
MI 88694
IL 86390
GA 83620
VA 79957
OR 70840
MN 62727
AZ 62330
WA 61367
TN 58289
OH 55863
LA 52481
OK 51297
NJ 49942
MD 43328
UT 41385
CO 40124
AL 36369
MA 33014
IN 30040
MO 29012
CT 22803
NE 22505
KY 19122
WI 17580
RI 10483
IA 10346
NV 9524
NH 7064
KS 6887
MS 5961
NM 5020
DE 4434
DC 3653
WV 2274
ME 2065
ID 1757
AR 1749
VT 585
MT 504
WY 492
SD 60
ND 43
Name: State, dtype: int64
可以看出,简称为CA的州的交通事故最多。通过查询美国各州的简称,可以知道CA意指加利福尼亚。其为美国最大的州,经济总量约等于世界第五大经济体,而其他几个交通事故排名靠前的州也是美国经济较为发达的州。判断经济活动较多的州发生交通事故越多。
2.哪个时间最容易发生事故,发生的事故是怎么样一个变化趋势?
#查看每年的事故发生 #先将发生事故的时间转换为时间格式
data["time"]=pd.to_datetime(data.Start_Time, format='%Y-%m-%d %H:%M:%S')
#查看每年事故数量
pd.DatetimeIndex(data["time"]).year.value_counts()
2019 953630
2018 892615
2017 717483
2016 410600
2020 6
2015 1
Name: time, dtype: int64数据来源于2016/2至2019/12月份数据,明显2020年和2015年的数据异常。前文计划需要使用某列数据时发现异常值进行现场处理。在这里将年份2015数据归于2016年,2020年数据归于2019年,即:
#处理异常值
data[pd.DatetimeIndex(data["time"]).year == 2015]="2016"
data[pd.DatetimeIndex(data["time"]).year == 2020]="2019"
#再次查看年份数据
pd.DatetimeIndex(data["time"]).year.value_counts()
2019 953636
2018 892615
2017 717483
2016 410601
Name: time, dtype: int64
#年份数据变化趋势
pd.DatetimeIndex(data["time"]).year.value_counts().plot(kind='line',title="accident count by year")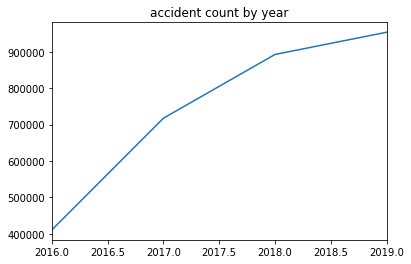
随着年份的增长,事故呈现上升的趋势,其中2016年到2017事故增长率最高,同时,2016年的事故大概只有2019年的一半(2016年缺失一个月的数据,2月到12月)。
对月份进行分析
#按月份事故的分布,并用条形图表示
pd.DatetimeIndex(data["time"]).year.value_counts().plot(kind='bar',title="accident by month")
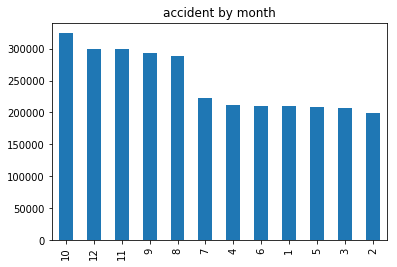
可以看出后半年的事故前半年的事故多,下半年时间开车更需要注意安全。
按照每周的上班时间的进行分析
#每周事故异常
pd.DatetimeIndex(data["time"]).weekday.value_counts().plot(kind = "bar",title="accident by weekday")
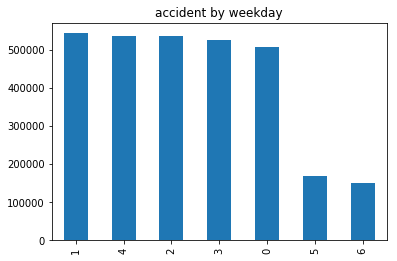
由上图,发生在周二的事故最多,平均上班时间的事故远远多于周末时间的交通事故。
对每天事故发生时间段数据分析
#每天各个时间段的事故数量 pd.DatetimeIndex(data["time"]).hour.value_counts().plot(kind = "bar",title="accident by DayHour") #输出
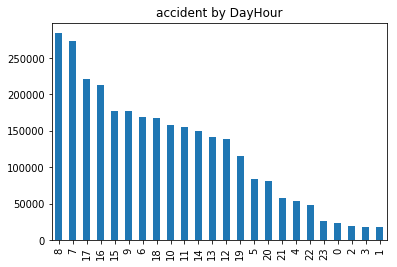
如上图,事故发生比较集中在早晚高峰,人流上线班的时间。事故发生的最多。
3.事故与天气有什么样的关系?
根据上述信息,我们需要观察weather_condition与事故的关系,但是字段weather__condition有较多的缺失值。需要进行空值处理。
#在数据集中我们可以明显的看到,数据集的事故是根据事故发生的时间进行排序的,所以我们可以使用后值填充前值进行,向前填充
data["Weather_Condition"]=data["Weather_Condition"].fillna(method='bfill')#使用空值后面的值向前填充,同理也可以向前填充
#数值填充后对字段进行空值检查
data["Weather_Condition"].isnull().sum()
0从上述可以看出,字段weather_condition已经没有空值了,可以对其进行后续分析。
#事故发生时前二十大天气
data["Weather_Condition"].value_counts().head(20).plot(kind = "bar",title = "The accident counts by Weather_Condition",color="orange")
#输出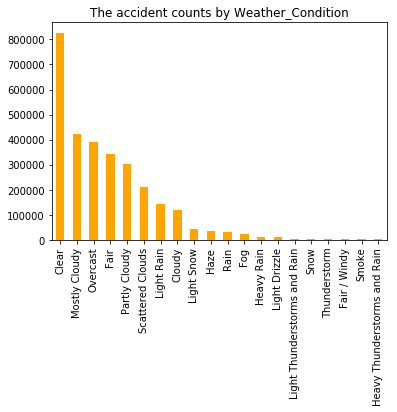
可以看出,事故发生时大都是有良好的天气条件下。而这些天气对事故具体有哪些影响?我们选取排名前五的事故天气和五个极端的天气条件,分别观察这些天气下各种事故占比.
for s in ["Clear","Mostly Cloudy","Overcast","Fair","Partly Cloudy","Fog","Light Rain","Rain","Heavy Rain","Snow"]:
plt.subplots(1,2,figsize=(20,8))
plt.suptitle('accident count by' + s,fontsize=20)
plt.subplot(1,2,1)
data.loc[data["Weather_Condition"] == s]['Severity'].value_counts().plot.bar()
plt.xlabel('Severity',fontsize=20)