PyCodeObject 的第22个字节开始就是 Python 的 opcode 序列了,这部分是决定了程序的执行流程,它被作为 TYPE_STRING 类型的 PyObject 存到了 PyCodeObject 的 co_code 当中。
由于 pyc 文件有现成的工具( uncompyle 6 )可以还原成 Python 代码,所以说我们不了解 pyc 格式也没有关系。这样我们混淆 pyc 的思路就可以是欺骗像 uncompyle 6 这类反编译的工具,让它误以为指令的序列不合法,但是又不影响真正的Python 虚拟机执行。
Python 的虚拟机是根据 PyCodeObject 中的 co_code 这个字段中存储的 opcode 序列来决定程序的执行流程的。所以说一个混淆的手段就是修改 co_code 字段中的 opcode 序列,可以添加一些加载超出范围的变量的指令,再用一些指令去跳过这些会出错的指令,这样执行的时候就不会出错了,但是反编译工具就不能正常工作了。
其中 JUMP_ABSOLUTE 6 表示直接跳转到 offset 为6的位置去执行指令,也就是插入的第三条指令 LOAD_CONST 144 并不会被执行,所以所以也并不会报错。但是对于反编译工具来说,这就是一个错误了,直接导致了反编译的失败。
据上面的那个思路,我们可以插入许多这样类似的指令,任意的不合法指令(其实随机数据都可以),然后用一些 JUMP 指令去跳过这样的不合法指令,上面的 JUMP_ABSOLUTE 只是一个简单的例子。甚至我们可以跳转到一些自行添加的虚假分支再跳转到到真实的分支(参考 ROP 的思路)。
Python 的 opcode 中 JUMP 相关的有多条指令,具体用法及差别可查询帮助文档。
所以此处解题思路即为将JUMP指令及其后面的混淆指令删除,修改代码段长度29为23字节(python中一般三字节表示一条指令, 如71 06 00 表示JUMP
)。修改后如图:

文件反汇编即得到原码:
#!/usr/bin/env python
# visit http://tool.lu/pyc/ for more information
def check():
a = raw_input('plz input your flag:')
temp = [
0] * 43
result = [
135,
151,
102,
148,
101,
241,
160,
101,
112,
241,
176,
241,
176,
241,
112,
160,
117,
117,
244]
if len(a) != 43:
print 'error'
exit()
for i in range(len(a)):
temp[i] = ord(a[i]) ^ 50
temp[i] = (temp[i] >> 4 ^ temp[i] << 4) & 255
if temp[i] != result[i]:
print 'wrong'
exit()
continue
print 'true'
if __name__ == '__main__':
check()
一个很简单的逆向运算:
exp如下:
flag=[0]*43
f=''
for i in range(len(a)):
flag[i]=(a[i]>>4^a[i]<<4)&255
print(flag)
for i in range(len(flag)):
f+=chr(flag[i]^50)
print(f)
查阅资料发现 Python 源码有几种保护的方式:
1.生成 pyc 文件:这感觉完全不能算保护,uncompyle6 一键反编译,支持 Python 1.0 到 3.8 全部版本(恐怖)
2.py 源码混淆:一般针对 py 源码混淆就是往代码里插入一些没有意义跳转分支,修改变量名和函数名等这些操作,但是这种虽然阅读起来很难理解,但是混淆效果并不好。
3.打包成可执行的二进制文件
4.自定义 opcode 的 Python 解释器
解题成功后对python反编译工具进行了探究:
1.对于以下代码:
71 06 00 // JUMP_ABSOLUTE 6
64 ff ff // LOAD_CONST 65535
上面这段混淆的指令如果是使用uncompyle的情况下,肯定是反编译失败的,因为插入的第二条指令加载了一个不存在的常量,导致下标超出,引发异常。
如果是使用dis库直接反编译code对象,也是反编译失败的,原因是dis库在反编译code对象的时候会尝试去常量表里面把变量取出来打印。但是可以dis库的进行反编译 code.co_code 属性,就可以反编译成功,原因是这个对象为纯粹的字节码,并不会包含常量表,所以不会出现下标异常。跟本题相类似。
2.观察大佬反汇编pyc文件时直接用一行命令dump出了python字节码,并找出程序错误:
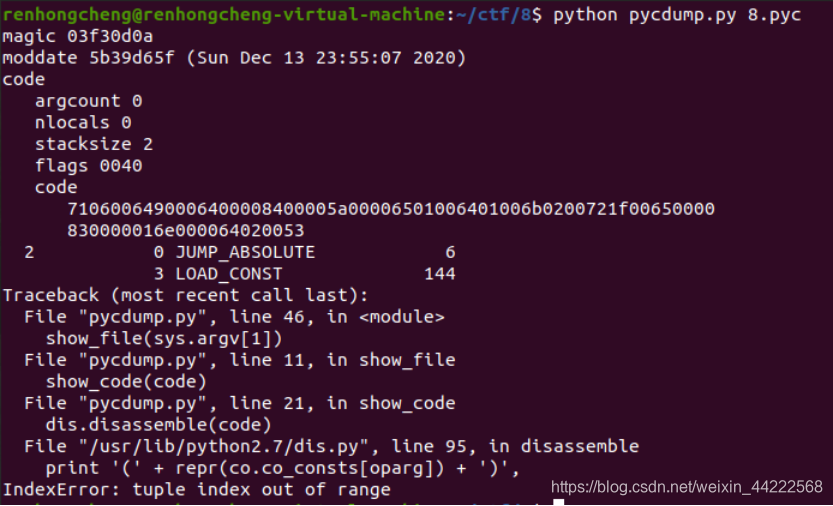
查询pycdc 是一个用于 pyc 反编译的工具 github 下载
安装 cmake apt-get install cmake
使用 在下载目录下输入 cmake CMakeList.txt
会在当前目录下生成 Makefile 文件 然后输入 make 即可进行编译安装
未完成的工作:
1.未实际操作指令的跳转,未实际操作从py文件到pyc文件的每一步,序列化反序列化等仍不清楚,心里没底https://cloud.tencent.com/developer/article/1421880
2.重叠指令pyc混淆方式不懂,大佬的博客(https://blog.csdn.net/ir0nf1st/article/details/61650984)
3.pycdc系列使用说明及安装方法尚不明
初次入门python字节码混淆,初步掌握了一点知识,待续。。。
Decompyle ++
Python字节码反汇编器/反编译器
Decompyle ++旨在将已编译的Python字节码转换回有效且易于阅读的Python源代码。 尽管其他项目也取得了不同程度的成功,但Decompyle ++的独特之处在于它寻求支持任何版本的Python的字节码。
Decompyle ++包括字节码反汇编程序(pycdas)和反编译程序(pycdc)。
顾名思义,Decompyle ++是用C ++编写的。 如果您想做出贡献,请在github上进行分叉
构建Decompyle ++
使用生成项目或makefile(有关详细信息,请参阅CMake的文档)
可以将以下选项传递给CMake以控制调试功能:
-DCMAKE_BUILD_TYPE=Debug
产生调试符号
-DENABLE_BLOCK_DEBUG=ON
启用块调试输出
-DENABLE_
Python的pyc文件
pyc文件就是由Python文件经过编译后所生成的文件,py文件编译成pyc文件后加载速度更快而且提高了代码的安全性。pyc的内容与python的版本相关,不同版本编译的pyc文件不一样
什么是pyc文件
pyc是一种二进制文件,是由Python文件经过编译后所生成的文件,它是一种byte code,Python文件变成pyc文件后,加载的速度有所提高,而且pyc还是一种跨平台的字节码,由python的虚拟机来执行的,就类似于JAVA或者.NET的虚拟机的概念。pyc的内容与pyt
long length() 返回文件的字节数
String getName() 返回对象文件或目录的名称
String getPath() 返回对象表示的文件的相对路径名
String getAbsolutePath() 返回此对
pycdc Decompyle++
Decompyle++旨在将编译后的Python字节码转换回有效的、人类可读的Python源代码。虽然其他项目取得了不同程度的成功,但Decompyle++的独特之处在于,它寻求支持来自任何版本的Python的字节码。
Decompyle++包含一个字节码反汇编器(pycda)和一个反编译器(pycdc)。
该工具需要手动编译,使用kali编译以后的样本:https://pan.baidu.com/s/1tAzVPMzFmhWko915yguO
1 什么是pyc文件
1.1 什么是pyc文件
1、pyc文件:是由Python文件经过编译后所生成的文件,它是一种字节码 byte code,因此我们直接查看就是乱码的,也对源码起到一定的保护作用,但是这种字节码byte code是可以反编译的,后面会介绍!
我们都知道计算机是不认识你在代码里写的那一行行字母的,计算机只认二进制,也只执行二进制文件,我们写的代码是需要编译器编译成二进制的。(参考)
对于Python来说你写的Python代码在执行python xxx.py时会由Python解析器翻译成Py




