


Python pandas 百万级数据处理案例1:电影评分

说明:本案例基于 pandas 开发者所著的《利用Python进行数据分析》最后一章。 数据链接 Permalink: https:// grouplens.org/datasets/ movielens/1m/
- 样本数量:1,000,209;
- 数据说明:该数据集为 6000 个用户,对4000部电影的 100 万个评分,分布在用户信息、电影信息和评分信息3个表格。
import sys
sys.version
'3.8.8 (default, Apr 13 2021, 12:59:45) \n[Clang 10.0.0 ]'
import pandas
pandas.__version__
'1.3.4'1. 导入数据(大家可自行下载)
import numpy as np
import pandas as pd
pd.options.display.max_rows = 100
users = pd.read_table("/Users/brycewang/Desktop/Python-ML-AI/pandas/1_m/users.dat", sep='::',
header=None,
names=['userid', 'gender', 'age', 'occup', 'zip'])
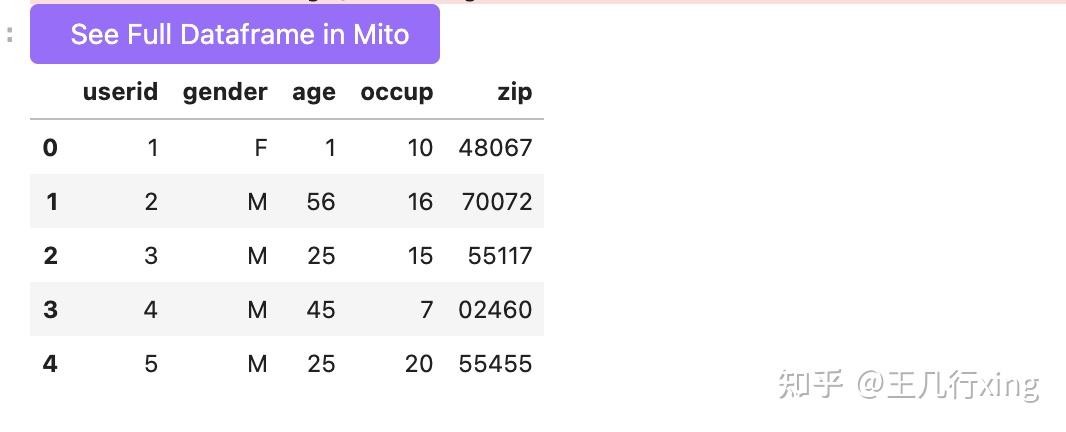
users.head()
/Users/brycewang/opt/anaconda3/lib/python3.8/site-packages/pandas/util/_decorators.py:311: ParserWarning: Falling back to the 'python' engine because the 'c' engine does not support regex separators (separators > 1 char and different from '\s+' are interpreted as regex); you can avoid this warning by specifying engine='python'.
return func(*args, **kwargs)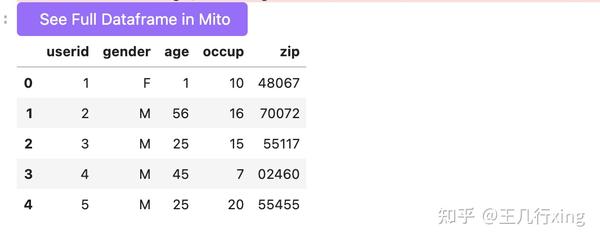
users.dtypes
userid int64
gender object
age int64
occup int64
zip object
dtype: object
users.shape
(6040, 5)
## 书中默认的 utf8 解码方式不适用于这个数据集,需要指定为“cp1252”
movies = pd.read_table("/Users/brycewang/Desktop/Python-ML-AI/pandas/1_m/movies.dat",
index_col=None, sep='::',
encoding = 'cp1252', header=None, names=['movieid', 'title', 'genres'])
/Users/brycewang/opt/anaconda3/lib/python3.8/site-packages/pandas/util/_decorators.py:311: ParserWarning: Falling back to the 'python' engine because the 'c' engine does not support regex separators (separators > 1 char and different from '\s+' are interpreted as regex); you can avoid this warning by specifying engine='python'.
return func(*args, **kwargs)
movies.dtypes
movieid int64
title object
genres object
dtype: object
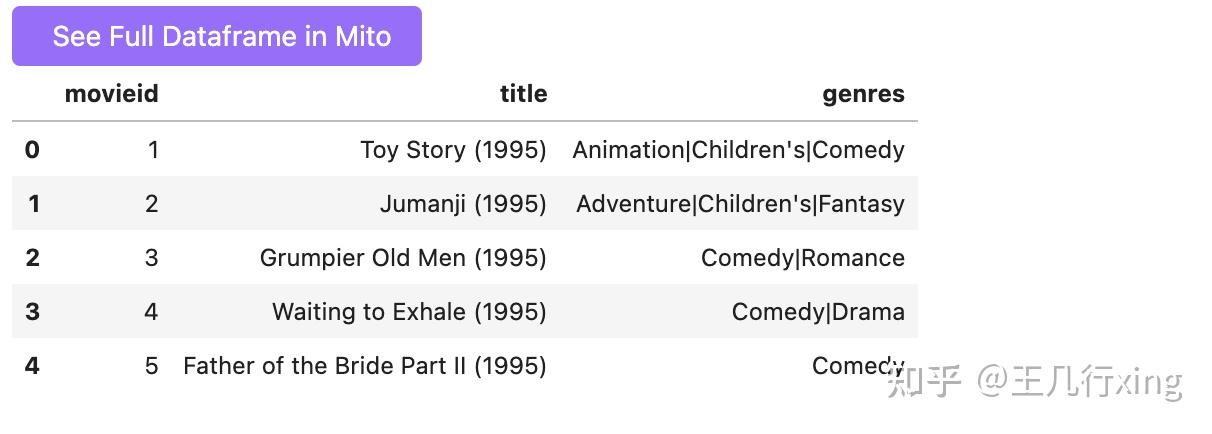
movies.shape
(3883, 3)
movies.head()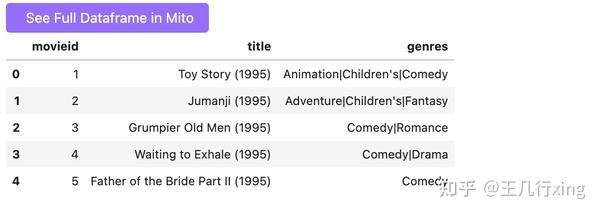
ratings = pd.read_table("/Users/brycewang/Desktop/Python-ML-AI/pandas/1_m/ratings.dat", sep='::',
header=None,
names=['userid', 'movieid', 'rating', 'timestamp'])
ratings.head()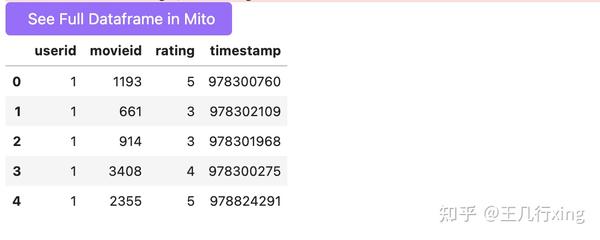
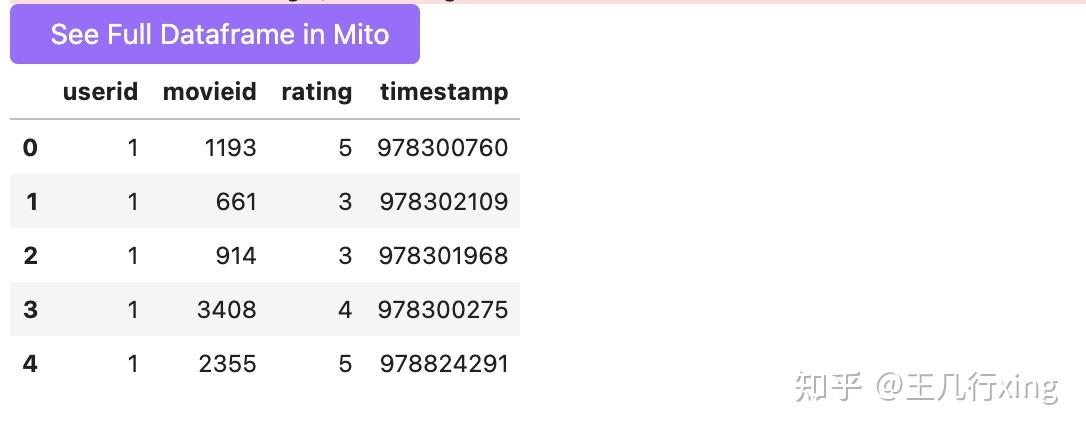
ratings.dtypes
userid int64
movieid int64
rating int64
timestamp int64
dtype: object
users.shape, movies.shape, ratings.shape
((6040, 5), (3883, 3), (1000209, 4))2. 数据的合并:merge
pandas 的数据合并用的是 merge 函数。 对应地,Stata 用的是 merge 命令(这里是 m:1),SQL 用的是 join() 函数(这里是 left_join 或 right_join)。 另外,pandas 的 merge 函数相对更加智能,可以不指定参数,自动相关字段进行匹配。
df = pd.merge(pd.merge(ratings, users), movies)
df.shape
(1000209, 10)我们拆开合并过程,分为两个步骤:
pd.merge(ratings, users, on='userid').head()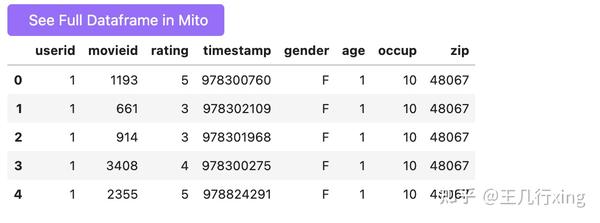
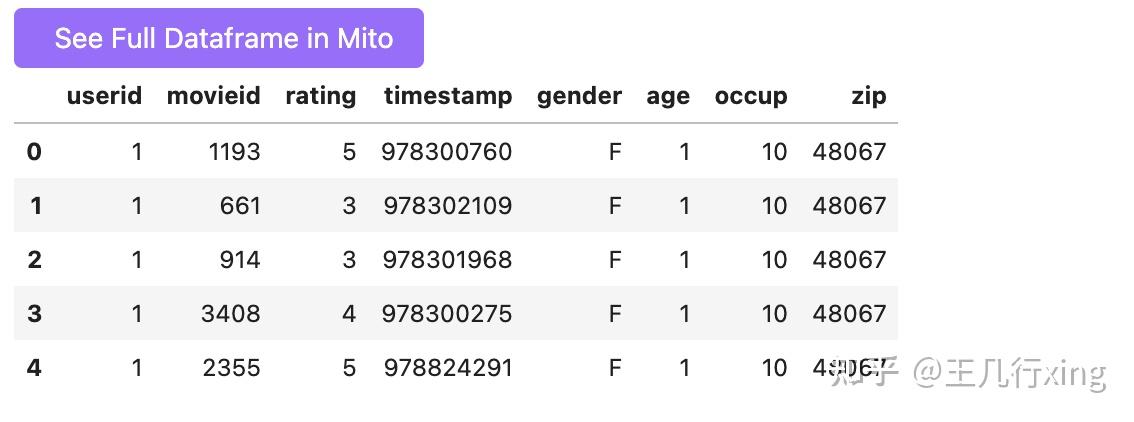
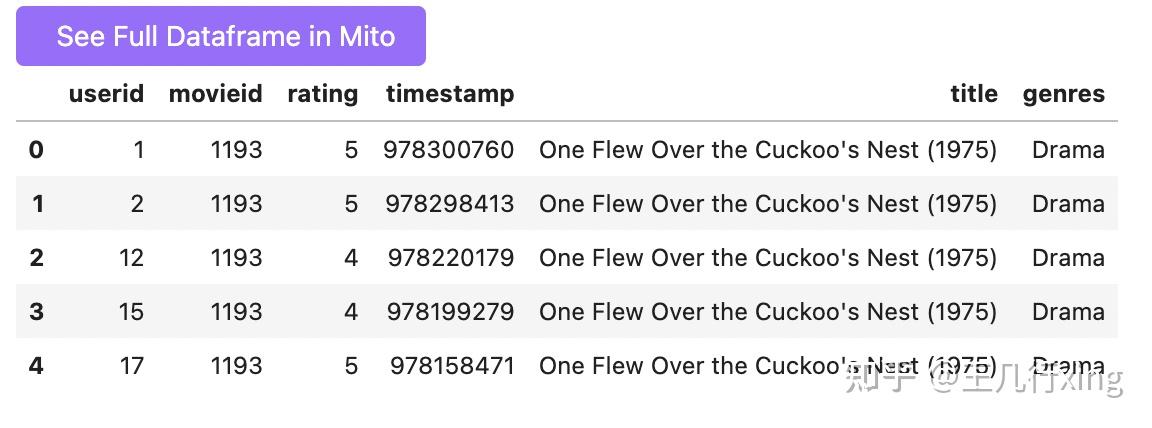
pd.merge(ratings, movies, on='movieid').head()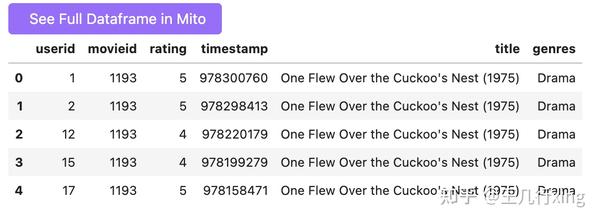
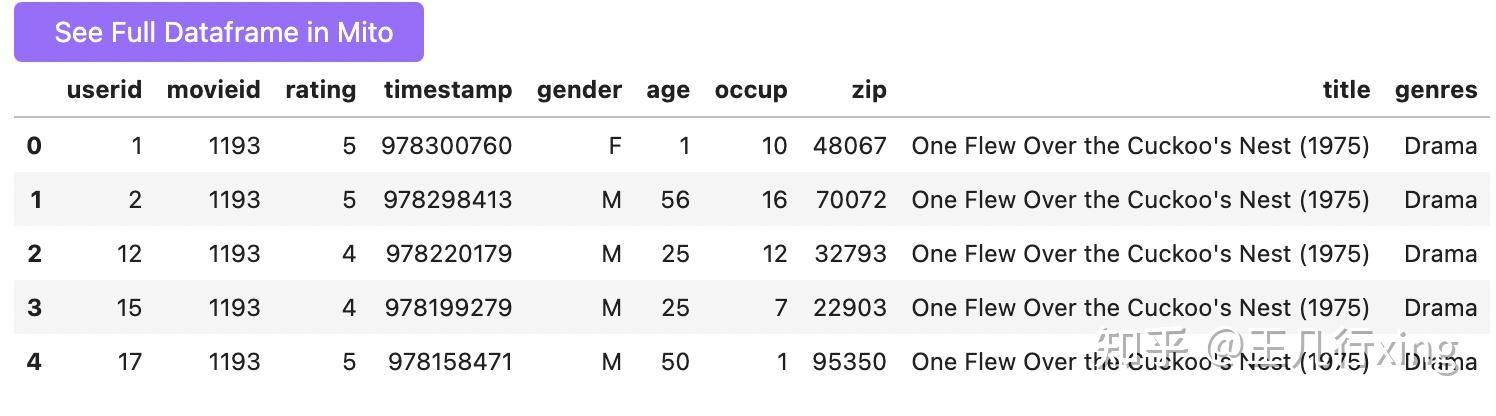
查看合并后的百万级的数据集:
df.head()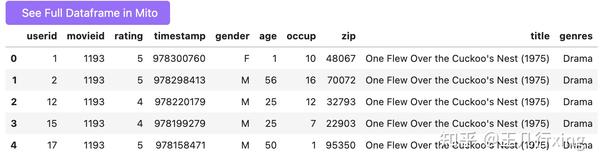
3. 按性别查看每部电影的平均评分
这是一个典型的分类统计需求。在pandas中,可以用groupby函数实现,也可以用 pivot_table(),且透视表函数展现的信息会更完整。相应地,Excel 的分组统计工具是数据透视表,Stata 的是table命令,SQL 的是group by。
df.groupby(by=['title', 'gender']).rating.mean()
title gender
$1,000,000 Duck (1971) F 3.375000
M 2.761905
'Night Mother (1986) F 3.388889
M 3.352941
'Til There Was You (1997) F 2.675676
Zero Kelvin (Kjærlighetens kjøtere) (1995) M 3.500000
Zeus and Roxanne (1997) F 2.777778
M 2.357143
eXistenZ (1999) F 3.098592
M 3.289086
Name: rating, Length: 7152, dtype: float64
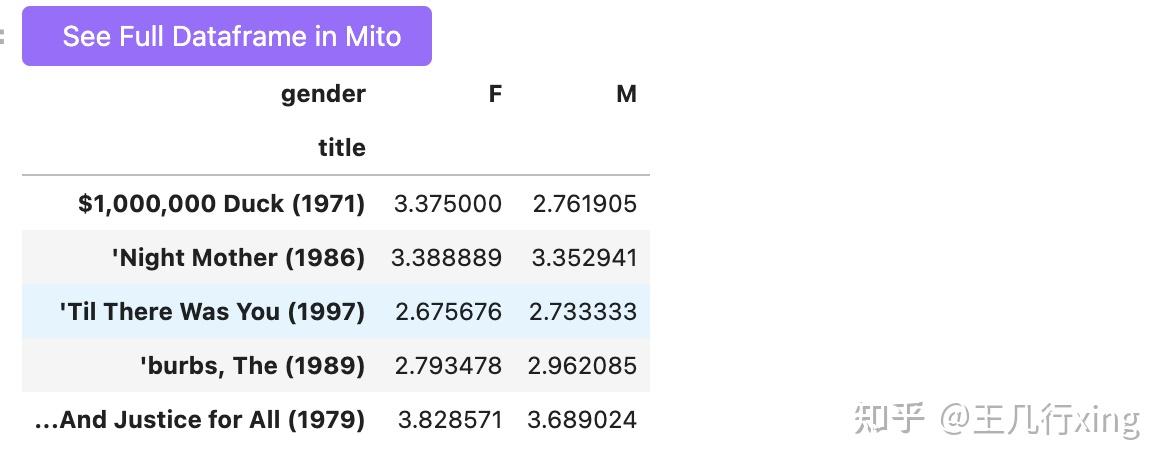
mean_ratings = df.pivot_table(index='title', columns='gender', values=
'rating', aggfunc='mean')
mean_ratings.head() #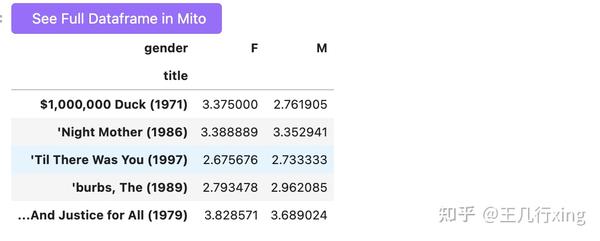
mean_ratings.columns
Index(['F', 'M'], dtype='object', name='gender')
mean_ratings.index ## 电影的标题(分组变量),变成了透视表的行索引;列分组变量性别的取值,变成了列的索引
Index(['$1,000,000 Duck (1971)', ''Night Mother (1986)',
''Til There Was You (1997)', ''burbs, The (1989)',
'...And Justice for All (1979)', '1-900 (1994)',
'10 Things I Hate About You (1999)', '101 Dalmatians (1961)',
'101 Dalmatians (1996)', '12 Angry Men (1957)',
'Young Poisoner's Handbook, The (1995)', 'Young Sherlock Holmes (1985)',
'Young and Innocent (1937)', 'Your Friends and Neighbors (1998)',
'Zachariah (1971)', 'Zed & Two Noughts, A (1985)', 'Zero Effect (1998)',
'Zero Kelvin (Kjærlighetens kjøtere) (1995)', 'Zeus and Roxanne (1997)',
'eXistenZ (1999)'],
dtype='object', name='title', length=3706)这里看上去好像透视表的结果直观,而且返回的是一个 DataFrame,方便我们进一步处理。 不过,在groupby结果的基础上,我们也可以使用 unstack 函数进行整理。
df.groupby(by=['title', 'gender']).rating.mean().unstack().head()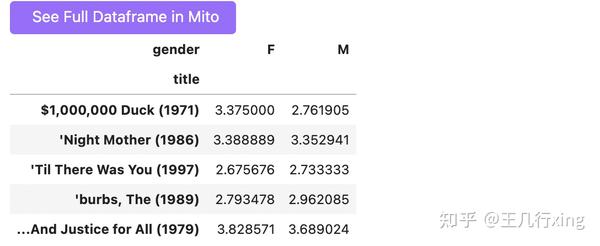
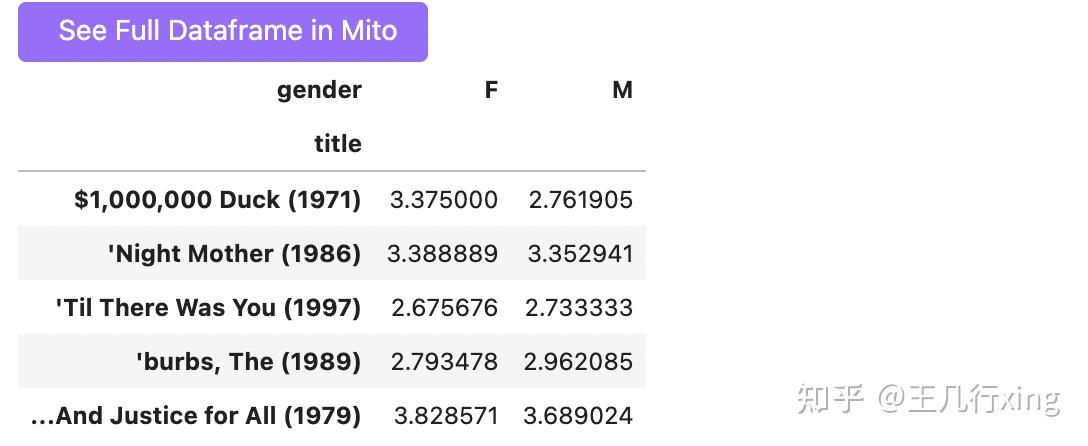
这里得到的结果,和数据透视表完全一致。
删除那些评分人数少于250的评分数据
这里用到了对 groupby 分组统计中的 size 来构造 index,并通过这个 index 到透视表中检索数据。
ratings_by_title = df.groupby('title').size()
ratings_by_title
title
$1,000,000 Duck (1971) 37
'Night Mother (1986) 70
'Til There Was You (1997) 52
'burbs, The (1989) 303
...And Justice for All (1979) 199
Zed & Two Noughts, A (1985) 29
Zero Effect (1998) 301
Zero Kelvin (Kjærlighetens kjøtere) (1995) 2
Zeus and Roxanne (1997) 23
eXistenZ (1999) 410
Length: 3706, dtype: int64
active_title = ratings_by_title.index[ratings_by_title >= 250]
active_title ## 这个电影标题数据,是分组对象的索引
Index([''burbs, The (1989)', '10 Things I Hate About You (1999)',
'101 Dalmatians (1961)', '101 Dalmatians (1996)', '12 Angry Men (1957)',
'13th Warrior, The (1999)', '2 Days in the Valley (1996)',
'20,000 Leagues Under the Sea (1954)', '2001: A Space Odyssey (1968)',
'2010 (1984)',
'X-Men (2000)', 'Year of Living Dangerously (1982)',
'Yellow Submarine (1968)', 'You've Got Mail (1998)',
'Young Frankenstein (1974)', 'Young Guns (1988)',
'Young Guns II (1990)', 'Young Sherlock Holmes (1985)',
'Zero Effect (1998)', 'eXistenZ (1999)'],
dtype='object', name='title', length=1216)
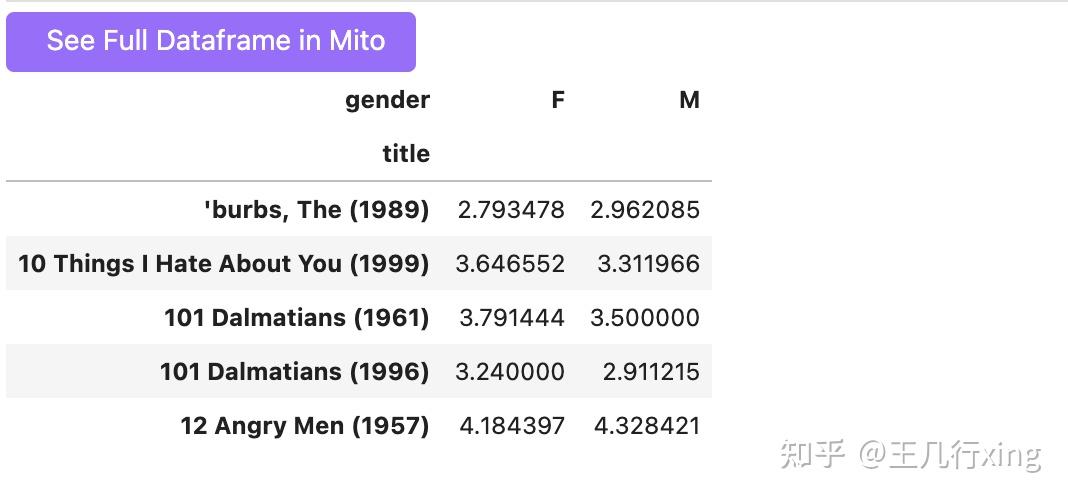
mean_ratings_active = mean_ratings.loc[active_title] ## 利用行索引进行检索
mean_ratings_active.head()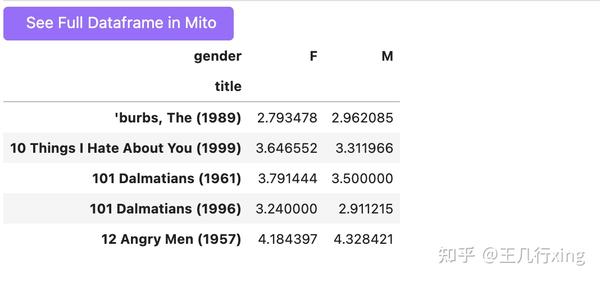
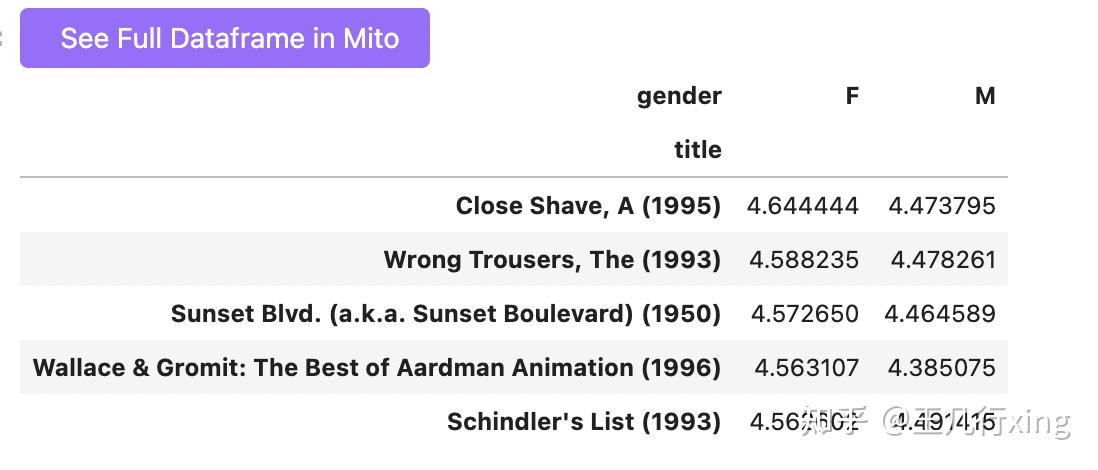
根据女性评分来排序
mean_ratings_active.sort_values('F', ascending=False).head()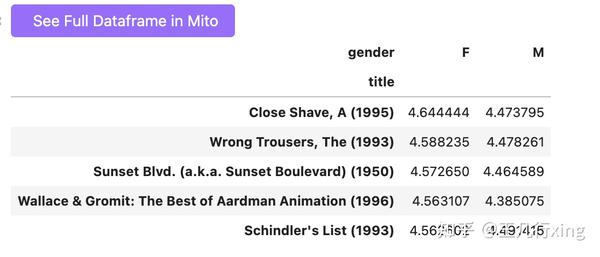
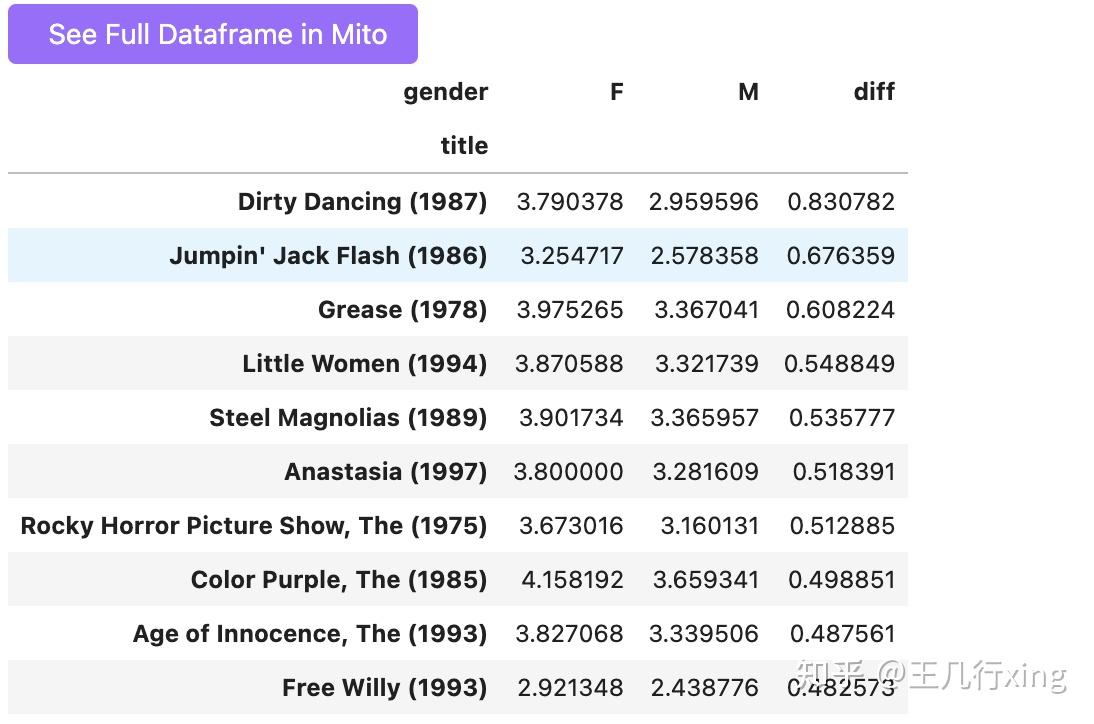
寻找按性别评分分歧最大的电影
mean_ratings_active['diff'] = mean_ratings_active.F - mean_ratings_active.M
mean_ratings_active.head()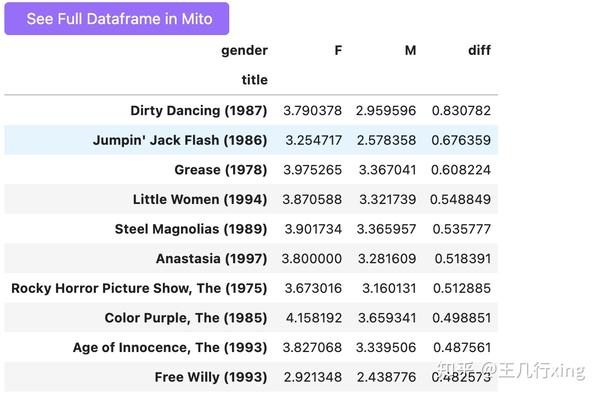
4. 寻找争议最大的10部电影
第一步,先按电影标题分组,算出评分的标准差
ratings_std = df.groupby('title').rating.std()
ratings_std
title
$1,000,000 Duck (1971) 1.092563
'Night Mother (1986) 1.118636
'Til There Was You (1997) 1.020159
'burbs, The (1989) 1.107760
...And Justice for All (1979) 0.878110
Zed & Two Noughts, A (1985) 1.052794
Zero Effect (1998) 1.042932
Zero Kelvin (Kjærlighetens kjøtere) (1995) 0.707107
Zeus and Roxanne (1997) 1.122884
eXistenZ (1999) 1.178568
Name: rating, Length: 3706, dtype: float64
第二步,筛选出评选人数超过250的电影
ratings_std_active = ratings_std.loc[active_title] ## 筛选出评选人数超过 250 的电影
ratings_std_active ## 结果只有一列,变成了 Series
title
'burbs, The (1989) 1.107760
10 Things I Hate About You (1999) 0.989815
101 Dalmatians (1961) 0.982103
101 Dalmatians (1996) 1.098717
12 Angry Men (1957) 0.812731
Young Guns (1988) 1.017437
Young Guns II (1990) 1.071959
Young Sherlock Holmes (1985) 0.891176
Zero Effect (1998) 1.042932
eXistenZ (1999) 1.178568
Name: rating, Length: 1216, dtype: float64
第三步,排序选出争议最大的10部电影:
ratings_std_active.sort_values(ascending=False).head(10)
## 评分活跃且最受争议的10部电影
title
Dumb & Dumber (1994) 1.321333
Blair Witch Project, The (1999) 1.316368
Natural Born Killers (1994) 1.307198
Tank Girl (1995) 1.277695
Rocky Horror Picture Show, The (1975) 1.260177