


爱可可AI前沿推介(5.25)


LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
摘要:基于深度语言理解的逼真文本-图像扩散模型、面向药物结合结构预测的几何深度学习、面向神经定理证明的超树证明搜索、图像和3D场景表示的ReLU场简单方法、面向聚合物特性预测的分子集合图表示、面向无人驾驶汽车研究的开源工具、基于超适配器的多语言机器翻译、长视频灵活扩散建模、利用可行集曲率实现更快的无投影在线学习
1、[CV] Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
C Saharia, W Chan, S Saxena, L Li, J Whang, E Denton, S K S Ghasemipour, B K Ayan, S. S Mahdavi... [Google Research]
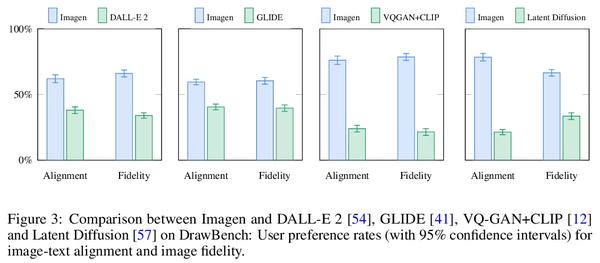
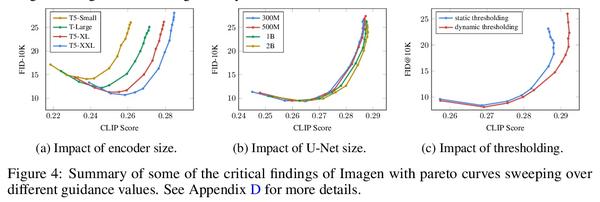
基于深度语言理解的逼真文本-图像扩散模型。本文提出Imagen,一个具有前所未有逼真度和深度的语言理解的文本到图像扩散模型。Imagen建立在大型Transformer语言模型在理解文本方面的能力之上,依赖于扩散模型在高保真图像生成方面的能力。本文的关键发现是,通用大型语言模型(如T5),在纯文本语料库上进行预训练,在为图像合成编码文本方面有惊人的效果:在Imagen中增加语言模型的大小,比增加图像扩散模型的大小更能提高样本的保真度和图像文本的一致性。Imagen在COCO数据集上实现了新的最先进FID得分7.27分,而不需要在COCO上进行训练,人工评分者发现Imagen的样本与COCO数据本身在图像-文本对齐方面是一致的。为了更深入地评估文本-图像模型,提出了DrawBench,一个全面的、具有挑战性的文本-图像模型基准。通过DrawBench,将Imagen与最近的方法,包括VQ-GAN+CLIP、Latent Diffusion Models、GLIDE和DALL-E 2进行了比较,发现无论是在样本质量还是图像-文本对齐方面,人工评分者都更喜欢Imagen。
We present Imagen, a text-to-image diffusion model with an unprecedented degree of photorealism and a deep level of language understanding. Imagen builds on the power of large transformer language models in understanding text and hinges on the strength of diffusion models in high-fidelity image generation. Our key discovery is that generic large language models (e.g. T5), pretrained on text-only corpora, are surprisingly effective at encoding text for image synthesis: increasing the size of the language model in Imagen boosts both sample fidelity and imagetext alignment much more than increasing the size of the image diffusion model. Imagen achieves a new state-of-the-art FID score of 7.27 on the COCO dataset, without ever training on COCO, and human raters find Imagen samples to be on par with the COCO data itself in image-text alignment. To assess text-to-image models in greater depth, we introduce DrawBench, a comprehensive and challenging benchmark for text-to-image models. With DrawBench, we compare Imagen with recent methods including VQ-GAN+CLIP, Latent Diffusion Models, GLIDE and DALL-E 2, and find that human raters prefer Imagen over other models in side-byside comparisons, both in terms of sample quality and image-text alignment. See imagen.research.google for an overview of the results.
https://arxiv.org/abs/2205.11487








2、[LG] EquiBind: Geometric Deep Learning for Drug Binding Structure Prediction
H Stärk, O Ganea, L Pattanaik, R Barzilay, T Jaakkola
[MIT]
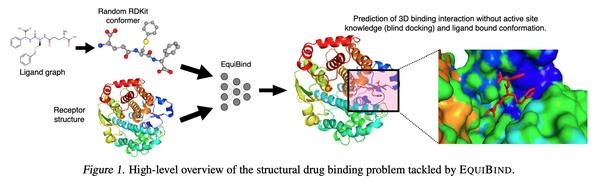
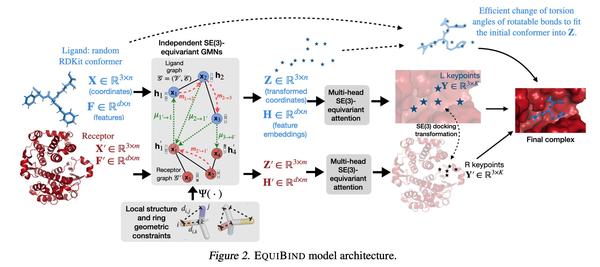
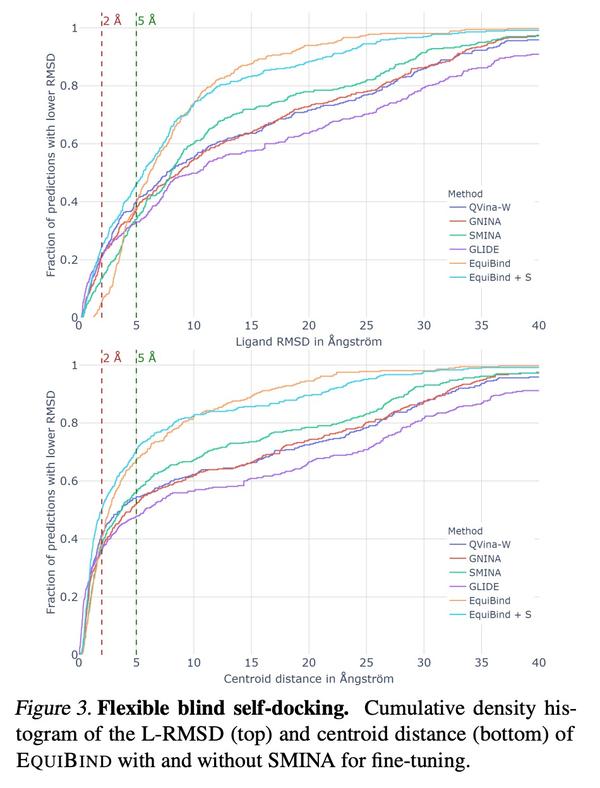
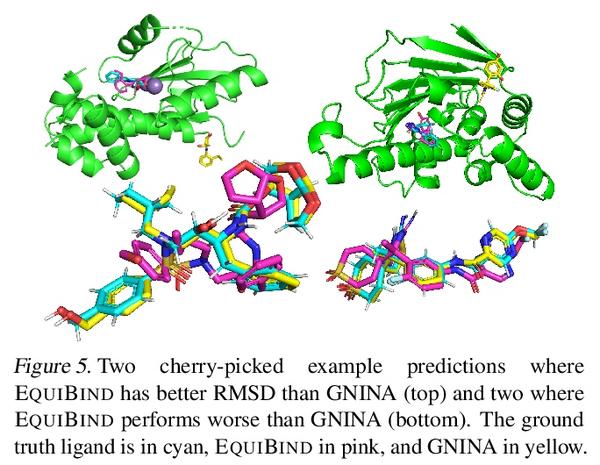
EQUIBIND:面向药物结合结构预测的几何深度学习。预测类药物分子如何与特定的蛋白质靶点结合,是药物发现中的一个核心问题。一种极快的计算结合方法,将使快速虚拟筛选或药物工程等关键应用成为可能。现有的方法在计算上是昂贵的,因为依赖于大量的候选样本,更不要说还有评分、排名和微调步骤。本文用EQUIBIND挑战这种模式,EQUIBIND是一个SE(3)等变几何深度学习模型,对:i)受体结合位置(盲对接) 和 ii)配体结合姿态和方向 进行直接样本预测。与传统和最近的基线相比,EquiBind实现了显著的速度提升和更好的质量。当它与现有的微调技术相结合时,以增加运行时间为代价,有了额外的改进。提出一种新的快速的微调模型,基于冯-米塞斯角距离与给定输入原子点云的全局最小值调整配体的可旋转键的扭角,避免了之前昂贵的能量最小化的差分进化策略。
Predicting how a drug-like molecule binds to a specific protein target is a core problem in drug discovery. An extremely fast computational binding method would enable key applications such as fast virtual screening or drug engineering. Existing methods are computationally expensive as they rely on heavy candidate sampling coupled with scoring, ranking, and fine-tuning steps. We challenge this paradigm with EQUIBIND, an SE(3)-equivariant geometric deep learning model performing direct-shot prediction of both i) the receptor binding location (blind docking) and ii) the ligand’s bound pose and orientation. EquiBind achieves significant speed-ups and better quality compared to traditional and recent baselines. Further, we show extra improvements when coupling it with existing fine-tuning techniques at the cost of increased running time. Finally, we propose a novel and fast fine-tuning model that adjusts torsion angles of a ligand’s rotatable bonds based on closed-form global minima of the von Mises angular distance to a given input atomic point cloud, avoiding previous expensive differential evolution strategies for energy minimization.
https://arxiv.org/abs/2202.05146






3、[CL] HyperTree Proof Search for Neural Theorem Proving
G Lample, M Lachaux, T Lavril, X Martinet, A Hayat, G Ebner, A Rodriguez, T Lacroix
[Meta AI Research & Vrije Universiteit Amsterdam]
面向神经定理证明的超树证明搜索。本文为基于Transformer的自动定理证明器提出一种在线训练程序。所提出方法利用一种新的搜索算法——超树证明搜索(HTPS),其灵感来自于最近AlphaZero的成功。该模型通过在线训练从之前的证明搜索中学习在线训练提供了比专家迭代更高的速度,使其能推广到远离训练分布的域。通过研究三种复杂度越来越高的环境下的性能,报告了该管线主要组成部分的详细消融情况。仅用HTPS,一个在标注证明上训练的模型就能证明65.4%的Metamath定理,大大超过了之前GPT-f的56.5%的水平。对这些未被证明的定理进行的在线训练将准确性提高到82.6%。在类似的计算预算下,将基于Lean的miniF2F-curriculum数据集的技术水平从31%提高到42%的证明精度。
We propose an online training procedure for a transformer-based automated theorem prover. Our approach leverages a new search algorithm, HyperTree Proof Search (HTPS), inspired by the recent success of AlphaZero. Our model learns from previous proof searches through online training, allowing it to generalize to domains far from the training distribution. We report detailed ablations of our pipeline’s main components by studying performance on three environments of increasing complexity. In particular, we show that with HTPS alone, a model trained on annotated proofs manages to prove 65.4% of a held-out set of Metamath theorems, significantly outperforming the previous state of the art of 56.5% by GPT-f. Online training on these unproved theorems increases accuracy to 82.6%. With a similar computational budget, we improve the state of the art on the Lean-based miniF2F-curriculum dataset from 31% to 42% proving accuracy.
https://arxiv.org/abs/2205.11491







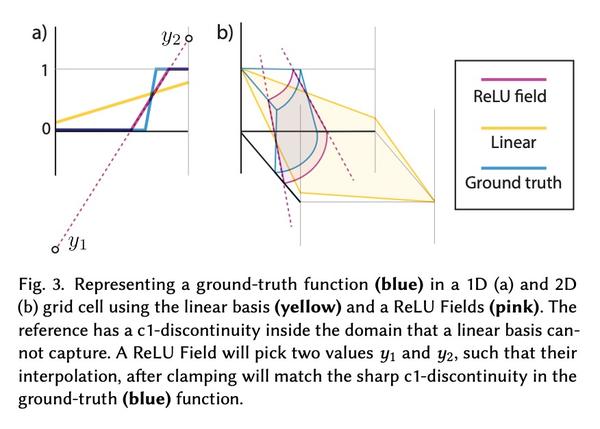
4、[CV] ReLU Fields: The Little Non-linearity That Could
A Karnewar, T Ritschel, O Wang, N J. Mitra
[University College London & Adobe Research]
ReLU场:图像和3D场景表示的简单方法。在最近的许多工作中,多层感知(MLP)已被证明适合于对复杂空间变化函数进行建模,包括图像和3D场景。尽管MLP能以前所未有的质量和内存占用来表示复杂的场景,但是MLP的这种表现力,是以漫长的训练和推理时间为代价的。另一方面,基于常规网格的双线性/三线性插值可以提供快速的训练和推理时间,但在不需要大量额外内存的情况下,无法与MLP的质量相匹配。本文研究了对基于网格的表示的最小变化是什么,既可以保留MLP的高保真结果,同时实现快速重建和渲染时间。本文提出一种出乎意料的简单变化来实现该任务:在N维网格上存储无界数据,并在线性插值后应用一个ReLU。这种变化可以在几乎没有计算成本或复杂性的情况下纳入现有的基于网格的方法,并稳定提高其表示能力。该方法只包含网格顶点的值,这些值可以通过梯度下降直接优化;不依赖任何学习参数、特殊初始化或神经网络;与最先进的方法相比,只需要一小部分时间就可以完成。
In many recent works, multi-layer perceptions (MLPs) have been shown to be suitable for modeling complex spatially-varying functions including images and 3D scenes. Although the MLPs are able to represent complex scenes with unprecedented quality and memory footprint, this expressive power of the MLPs, however, comes at the cost of long training and inference times. On the other hand, bilinear/trilinear interpolation on regular grid based representations can give fast training and inference times, but cannot match the quality of MLPs without requiring significant additional memory. Hence, in this work, we investigate what is the smallest change to grid-based representations that allows for retaining the high fidelity result of MLPs while enabling fast reconstruction and rendering times. We introduce a surprisingly simple change that achieves this task -- simply allowing a fixed non-linearity (ReLU) on interpolated grid values. When combined with coarse to-fine optimization, we show that such an approach becomes competitive with the state-of-the-art. We report results on radiance fields, and occupancy fields, and compare against multiple existing alternatives. Code and data for the paper are available at this https URL .
https://arxiv.org/abs/2205.10824









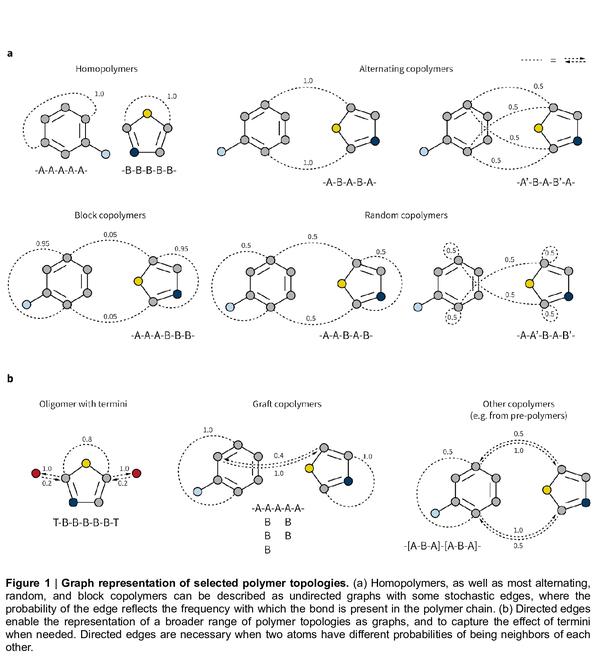
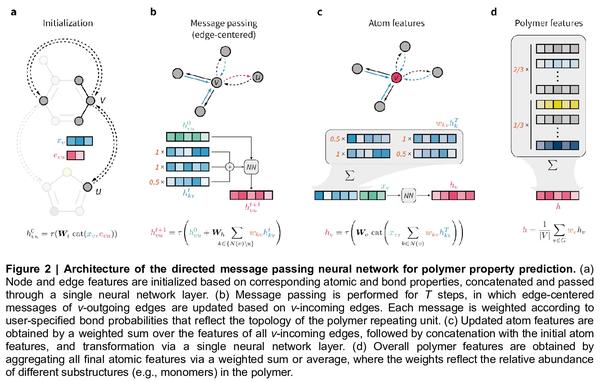
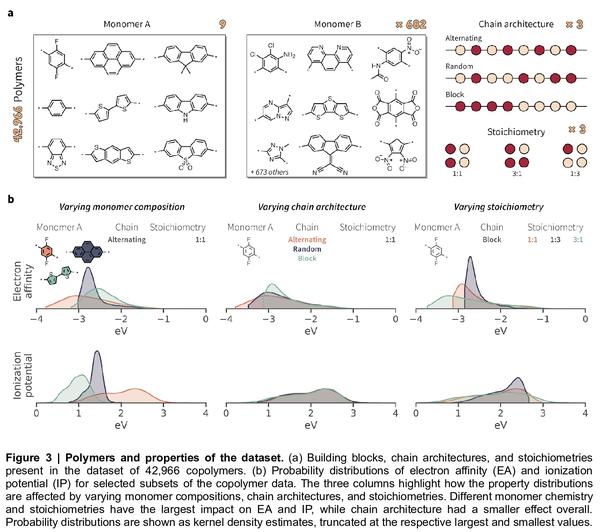
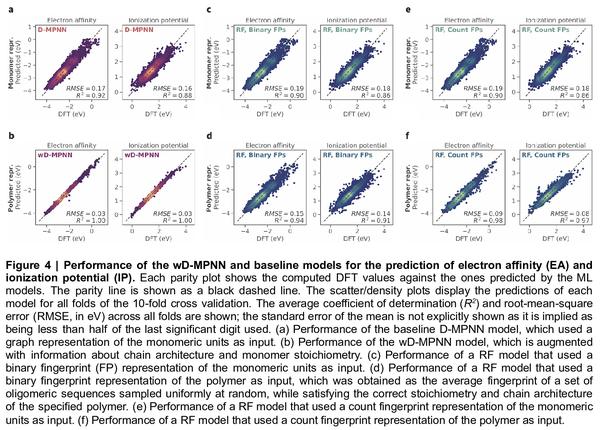
5、[LG] A graph representation of molecular ensembles for polymer property prediction
M Aldeghi, C W. Coley
[MIT]
面向聚合物特性预测的分子集合图表示。合成高分子是多功能和广泛使用的材料。与小的有机分子类似,这类材料有一个很大的化学假设空间。计算式特性预测和虚拟筛选可通过优先考虑预期具有有利性能的候选材料来加速聚合物设计。然而,与有机分子相比,聚合物往往不是定义明确的单一结构,而是类似分子的集合体,这对传统的化学表示和机器学习方法构成了独特的挑战。本文提出一种分子集合的图表示法和一种相关的图神经网络架构,该架构是为聚合物特性预测而定制的。本文证明了这种方法能捕捉到聚合物材料的关键特征,如链结构、单体化学计量和聚合度,并取得了优于现成化学信息学方法的准确度。同时,建立了一个模拟电子亲和力和电离电位值的数据集,适用于具有不同单体组成、化学计量和链结构的4万多种聚合物,可用于开发其他定制的机器学习方法。
Synthetic polymers are versatile and widely used materials. Similar to small organic molecules, a large chemical space of such materials is hypothetically accessible. Computational property prediction and virtual screening can accelerate polymer design by prioritizing candidates expected to have favorable properties. However, in contrast to organic molecules, polymers are often not well-defined single structures but an ensemble of similar molecules, which poses unique challenges to traditional chemical representations and machine learning approaches. Here, we introduce a graph representation of molecular ensembles and an associated graph neural network architecture that is tailored to polymer property prediction. We demonstrate that this approach captures critical features of polymeric materials, like chain architecture, monomer stoichiometry, and degree of polymerization, and achieves superior accuracy to off-the-shelf cheminformatics methodologies. While doing so, we built a dataset of simulated electron affinity and ionization potential values for >40k polymers with varying monomer composition, stoichiometry, and chain architecture, which may be used in the development of other tailored machine learning approaches. The dataset and machine learning models presented in this work pave the path toward new classes of algorithms for polymer informatics and, more broadly, introduce a framework for the modeling of molecular ensembles.
https://arxiv.org/abs/2205.08619






另外几篇值得关注的论文:
[RO] OpenPodcar: an Open Source Vehicle for Self-Driving Car Research
OpenPodcar:面向无人驾驶汽车研究的开源工具
F Camara, C Waltham, G Churchill, C Fox
[University of Leeds & University of Lincoln]
https://arxiv.org/abs/2205.04454








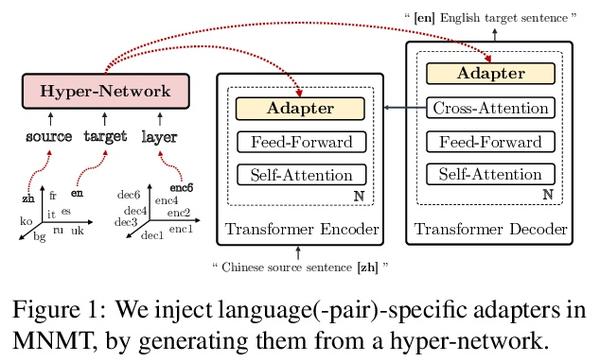
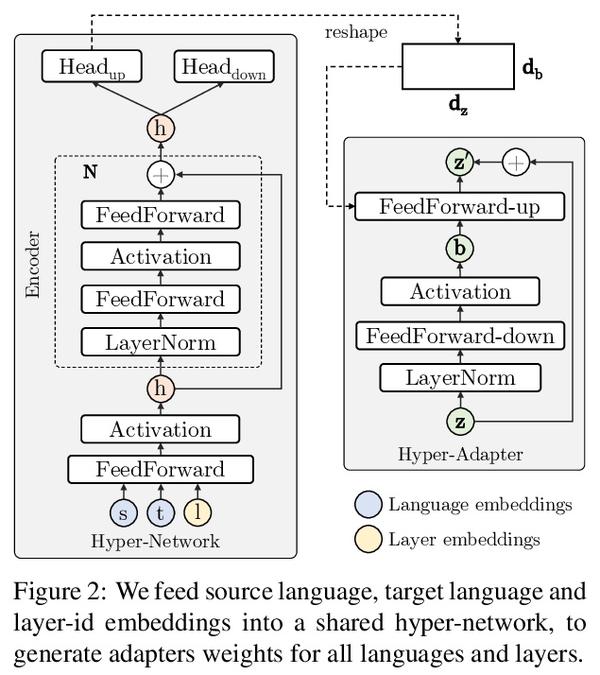
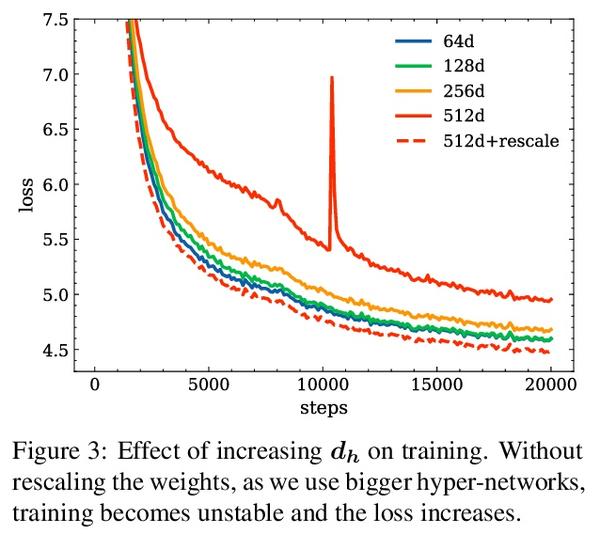
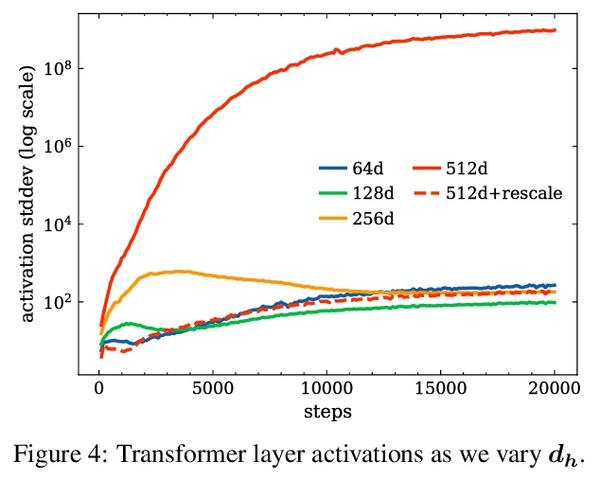
[CL] Multilingual Machine Translation with Hyper-Adapters
基于超适配器的多语言机器翻译
C Baziotis, M Artetxe, J Cross, S Bhosale
[University of Edinburgh & Meta AI Research]
https://arxiv.org/abs/2205.10835






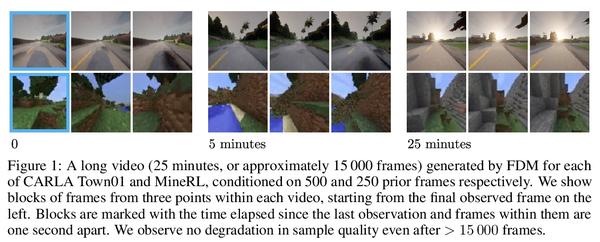
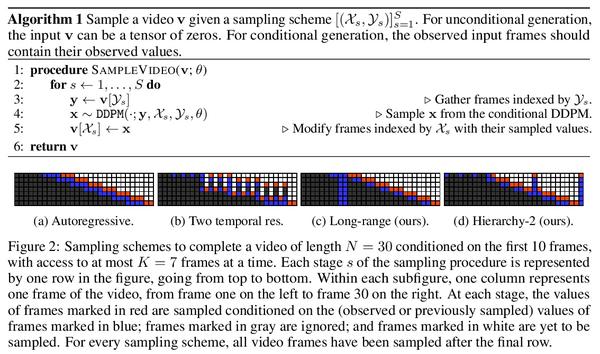
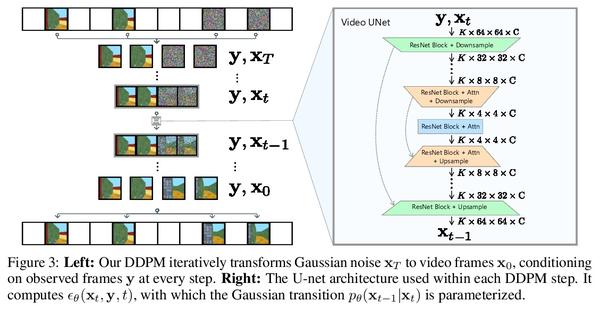
[CV] Flexible Diffusion Modeling of Long Videos
长视频灵活扩散建模
W Harvey, S Naderiparizi, V Masrani, C Weilbach, F Wood
[University of British Columbia]
https://arxiv.org/abs/2205.11495







[LG] Exploiting the Curvature of Feasible Sets for Faster Projection-Free Online Learning
利用可行集曲率实现更快的无投影在线学习
Z Mhammedi
[MIT]
https://arxiv.org/abs/2205.11470


