有时候发现读论文还是挺有意思的一件事,而且多读几回就会越来越熟练。
作为小本科也是充满了信心。
更可喜的是,在AI领域,能看到很多中国名字的学者以及中国的贡献。
SRCNN (Learning a Deep Convolutional Network for Image Super-Resolution, ECCV2014)

正所谓开山之作,现在看来这个架构是很简单的,因为只用到了三层卷积层,不过在那个时候深度神经网络刚刚兴起的时候能有这样的设计也是很不错了。此算法的步骤如下:
1:先采用Bicubic插值算法将LR图像放大成目标尺寸大小的图片:
2:接着通过三层卷积神经网络来实现端对端的非线性映射。
3:最后输出为高分辨率图像。
在论文中,作者分别将三层卷积层解释为:图像特征提取,非线性特征映射和高分辨率图像重建,其实说白了也就是。相比较于传统方法,SRCNN不仅在PSNR等方法上有了明显提升,在视觉上也有了较大的改观。
监督学习评估方法就是像素级别的L1距离。
ESPCN (Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network)

SRCNN的缺点就是现将低分辨率的图像进行上采样,来得到和目标图像同样的尺寸,再输入到网络中去进行三层卷积运算,这样带来的计算量是很巨大的,计算复杂度也提升了。
于是该方法换了一种策略,将上采样的操作放到了卷积运算的最后,先直接在LR的图像进行图像特征提取和非线性特征映射,最后再采用亚像素卷积(sub-pixel convolution)来实现上采样。由于带计算的操作都是在低分辨率空间中进行的,节省了很多网络计算,因此速度很快。
亚像素卷积(sub-pixel convolution)就是本论文最大的创新点,它实际上并不涉及到卷积运算,实际上是一种排列,是一种高效、快速、无参的像素重排列的上采样方式。由于很快,直接用在视频超分中也可以做到实时。其在Tensorflow中的实现称为depthtospace ,在Pytorch中的实现为PixelShuffle。
具体来说呢,就是最后的上采样不是通过学习得来的,没有任何参数,全程带参数需要卷积的运算都是在LR维度进行的,最后一层卷积的通道数是R * R * C,每一个特征图的尺寸和输入的LR图像是一致的,R是需要上采样放大的倍数(上采样是2倍,那么图像像素点数扩大4倍),C是最终输出图像的通道数。也就是最后一层卷积全部包含了输出图像的像素,然后按照自己的喜好习惯和方便程度,安排SR像素点和卷积图特征点的对应关系,通过监督学习,对最后一层卷积的所有像素进行映射训练,最后按照顺序排列像素点即可。
VDSR (Accurate Image Super-Resolution Using Very Deep Convolutional Networks)

从图像的架构来看,重复使用Conv 和 非线性激活(比如ReLu),也就是多加了几层而已,比SRCNN要深一些。但是一条很明显的是借鉴了残差网络的概念,将LR的特征直接引入并转换到了HR图像。
上面的黑色框,是对每个卷积层使用64个过滤器,并绘制一些示例特征图用于可视化而已,我们会发现很多特征图在运用了ReLu后是0。
在SRCNN中,输入的LR必须经过所有层,直到它到达输出层。对于许多权重层,这将成为需要非常长期记忆的端到端关系。因此,消失/爆炸梯度问题可能是关键的。我们可以简单地用残差学习来解决这个问题。
作者认为网络越深越好,且HR和LR的低频信息是一样的,因此只需要用更深的网络学习到高频的信息(这部分高频信息就是高分辨率图像和低分辨率图像的差别),而我们只需学习学习高分辨率图像和低分辨率图像之间的高频部分残差即可,然后叠加低分辨率图像图像的低频信息就可。
SRGAN(Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network)

作者创新性的使用了GAN网络来做SR任务,最终目标是训练一个生成函数G,该函数估计给定的LR输入图像其对应的HR对应图像。这样做的原因是,作者认为MSE的损失函数,很容易丢失高频信息,使用pixel-wise的MSE使得图像变得平滑,而如果先用VGG来抓取到高级特征(feature)表示,再对feature使用MSE,可以更好的抓取不变特征。
且提出了 perceptual loss(感知误差)

一些细节解读和翻译:
LR图像可以通过对SR图像进行高斯模糊来得到平滑的图像,以及还可以使用下采样的方式获得,LR的图像维度是W * H * C,那么SR的维度是(W * r)* (H * r)* C,其中r就是下采样率,也就是缩小倍数。
构造器G参数的是θ_G,它有L层,代表构造器网络也有L层,通过优化SR任务的损失函数l^SR来得到。
将感知损失定义为内容损失和对抗损失分量的加权和:
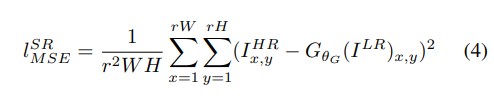
其中Content Loss我们不选像素级别的MSE,
切记,我们不选择像素级别的MSE,这种损失函数只关注低频信息,会使得产生的图像模糊。
而是自定义一个VGG LOSS,他是用预先训练好的了的VGG19来作为评判,主要是是为了特征提取,提取出来的特征图用于计算内容损失,所以VGG没有参数更新和训练。

其实就是,一方面LR经过G网络生成的图像,假SR,经过VGG网络,提取一堆特征图出来,另外一方面LR对应的真SR经过同样的VGG网络,提取出同样的一堆特征图出来,对应位置的作为一对儿。因为经过G图像生成和目标图像有相同的维度和含义,所以具有可比性。
式子中,对于每一对儿LR产生的和SR产生的特征图进行欧式距离运算,累加后计算特征差异,作为内容损失函数。试想,如果LR能通过G产生和SR一样的图片,那么不仅仅是最后的表现一样,更高频次的信息也应该是一致的,因此这就是采用在这种方式,不采用MSE这种简单版本的损失计算,MSE只能看到低频的信息。这种就称作是感受损失。
另一个是Adversarial Loss,G视图欺骗D自己生成的是SR图片,实际上是Fake SR 图片,但是D需要正确判别出哪些是Real SR图片,哪些是Fake SR 图片。这个损失就是一般的GAN的损失了,毫无疑问就是差用二进制的BCE(Binary CrossEntropyLoss)或者BCEWithLogitsLoss,损失函数。只是为了判别真假。
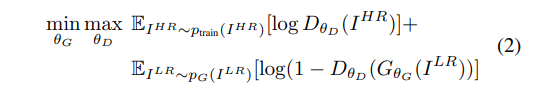
有时候发现读论文还是挺有意思的一件事,而且多读几回就会越来越熟练。作为小本科也是充满了信心。更可喜的是,在AI领域,能看到很多中国名字的学者以及中国的贡献。SRCNN (Learning a Deep Convolutional Network for Image Super-Resolution, ECCV2014)正所谓开山之作,现在看来这个架构是很简单的,因为只用到了三层卷积层,不过在那个时候深度神经网络刚刚兴起的时候能有这样的设计也是很不错了。此算法的步骤如下:1:先采用Bicubic
F
SRC
NN
(Accelerating the Super-R
es
olution Convolutional Neural Network)阅读笔记
1、
论文
地址:https://arxiv.org/abs/1608.00367
2、github上tensorflow代码: https://github.com/yifanw90/F
SRC
NN
-TensorFlow
3、
论文
介绍
3.1、
SRC
NN
的
缺点
速度太慢,速度慢的原因主要有两个方面,第一个由于使用双三次插值进行上采样将
图像
放大,在卷积的时候所用的时
本文是2020年较早的一篇关于单
图像
超分
的文章。本文针对于non-blind情况,即已知LR
图像
,下采样方法,模糊核,噪声的情况下,求对应的HR
图像
。不同于传统的方法,本文提出了一种model-based和learning-based相结合的方法,对解决
超分
辨率问题开辟了一个新的途径。
文章切入点:
当前的退化
图像
还原方法主要分为两种,一种是model-based方法,就是通过将问题公式化,然后通过不断迭代结果,最终得到一个令人较为满意的解。作者提出这种方法虽然有着一定的灵活性(可以将不同的下采样倍数,模.
时隔一年,重新回顾
超分
领域,真是读
论文
的速度赶不上发
论文
的速度,一年不见,已经出现了不少优秀的paper。先来一波,
CVPR2019中关于
超分
辨率算法的16篇
论文
压压惊。
好了,上干货,开始我们的重点,首先介绍下概念:
超分
辨率(Super R
es
olution,
SR
)
超分
辨率是一项底层
图像
处理任务,将低分辨率的
图像
映射至高分辨率,以期达到增强
图像
细节的作用。
图像
模糊不清的原因有很多...
Unified Dynamic Convolutional Network for Super-R
es
olution with Variational Degradations 作为2020年的一篇关于
超分
辨率的顶会(CVPR)文章,本文在前人的基础框架(
SR
MD)上提出了一种新的动态卷积(dynamic convolutions)方法,并以此组建了一种新的
超分
辨率框架。

