

ZMQ源码详细解析 之 进程内通信流程

一、背景
系列文章为多年前所写,zmq虽然因为应用门槛等问题,在这几年可能有沉寂趋势,但其很多设计理念还是值得参考的。虽然版本经过了多次迭代,文章中的分析还是有一定参考价值,特别整理到这里。
二、开始
本文分析内容基本限定在zmq提供的进程内通信功能上,尽量不涉及主要流程中无关的类和函数,实现基本功能的对象大部分不展开。(zmq的源码完全深度展开后,真是千头万绪,分而治之是我学习zmq的策略!哈哈,我会告诉你写文章的时候进一步深入的分析我也没理出来吗)进程内通信是zmq guild中吹嘘的一大功能,有哪些特点我这边就不重复吹嘘。这部分功能在源码中涉及的内容不特别深,但涉及的面并不窄,先学习这部分内容主要是为了先和zmq源码混个脸熟。
先最简单的说一下zmq处理进程内通信的原理,如下图:
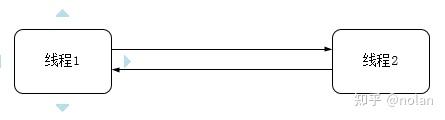
这是啥?其实就是线程之间通过两个队列来交互,对于每个线程来说都是通过其中一个队列发消息给对方,从另一个队列中读取对方发送的消息。这两个队列根据源码用的名称,我称之为pipe,后面会反复提到。zmq所做的就是把pipe绑定到对应的线程上,然后在send和recv的时候通过pipe来发出、获取信息。是的,就是这么简单~
那么我们就来看看具体的源码实现吧!这里通过一个我写的示例程序的运转流程来展开源码的工作流程。进程内通信实验程序:
#include "zmq.h"
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <assert.h>
#include <pthread.h>
static void* client_func(void* context)
sleep(5);
void* client = zmq_socket(context, ZMQ_REQ);
zmq_connect(client, "inproc://hello");
sleep(30);
while(1)
char buffer[10];
printf("Client: Sending Hello...\n");
zmq_send (client, "Hello", 5, 0);
zmq_recv (client, buffer, 10, 0);
printf("Client: Received World!\n");
zmq_close(client);
return NULL;
int main()
void* context = zmq_ctx_new();
void* responder = zmq_socket(context, ZMQ_REP);
int rc = zmq_bind(responder, "inproc://hello");
assert(rc == 0);
pthread_t client;
pthread_create (&client, NULL, client_func, context);
while (1)
char buffer[10];
zmq_recv(responder, buffer, 10, 0);
printf("I am responder server! Recv Hello\n");
sleep(1);
zmq_send(responder, "World", 5, 0);
zmq_close(responder);
zmq_ctx_destroy(context
);
return 0;
没错!又是低小下、俗气烂大街的 hello world。加了两个sleep是为了跟着流程分析zmq源码的时候代码有明确的执行顺序和明显的阻塞,也就某些程度上掩盖了zmq的一个重要特性,这个重要特性留在以后专门分析吧。从main函数的 void* context = zmq_ctx_new(); 开始。
zmq_ctx_new()这个函数可以轻易从源码中看出其实就是调用了ctx_t类的构造函数,因此这里就讲这个上下文类及其构造函数。
class ctx_t
public:
ctx_t ();
// 创建socket都是调用ctx中的函数哦
zmq::socket_base_t *create_socket (int type_);
// 发送“命令”给目标线程
void send_command (uint32_t tid_, const command_t &command_);
// 管理zmq中很重要的概念“endpoint”的函数
int register_endpoint (const char *addr_,
endpoint_t &endpoint_);
void unregister_endpoints (zmq::socket_base_t *socket_);
endpoint_t find_endpoint (const char *addr_);
~ctx_t ();
private:
uint32_t tag;
// 进程内所有的socket都能在此找到
typedef array_t <socket_base_t> sockets_t;
sockets_t sockets;
// 还没用到的slot在此集合
typedef std::vector <uint32_t> empty_slots_t;
empty_slots_t empty_slots;
bool starting;
bool terminating;
// slot相关参数需要同步保护的,这个就是互斥锁
mutex_t slot_sync;
// 指向进程内所有“mailbox”的东西就是这些slot
uint32_t slot_count;
mailbox_t **slots;
// 进程内所有“endpoint”在此
typedef std::map <std::string, endpoint_t> endpoints_t;
endpoints_t endpoints;
// 访问endpoint是需要同步的
mutex_t endpoints_sync;
// 这货其实是个产生唯一id的东西,一会见
static atomic_counter_t max_socket_id;
// 最大socket数量
int max_sockets;
// I/O 线程的数量,这类线程暂时被我黑掉了。。。
int io_thread_count;
// Is IPv6 enabled on this context?
bool ipv6;
// ctx选项也是需要同步保护的
mutex_t opt_sync;
// 复制构造函数、等号在此私有化限制,想乱用也不行啦
ctx_t (const ctx_t&);
const ctx_t &operator = (const ctx_t&);
。。。//这是?
ctx才这么点内容?好吧,其实我把一些和今天主题无关的以及特别讨厌的家伙都发配到最后那个。。。里面去了。剩下的东西大部分很快就会展现他们的作用,我简单注释了一下。下面看构造函数吧:
zmq::ctx_t::ctx_t () :
tag (ZMQ_CTX_TAG_VALUE_GOOD), // 这货就是证明自己身份用的
starting (true), // 表明第一次创建socket时需要初始化
terminating (false),
reaper (NULL),
slot_count (0),
slots (NULL),
max_sockets (ZMQ_MAX_SOCKETS_DFLT),
io_thread_count (ZMQ_IO_THREADS_DFLT),
ipv6 (false)
#ifdef HAVE_FORK
pid = getpid();
#endif
目前还看不出太多内容,因此我们继续看zmq_socket(context, ZMQ_REP);这个函数的核心是调用ctx->create_socket (int type_),type_是socket的类型,zmq中有req、rep、router、dealer等等,都有不同的特性,zmq架构中与socket相关的部分是以此为中心来设计的。
zmq::socket_base_t *zmq::ctx_t::create_socket (int type_)
slot_sync.lock ();
// 示例程序中此处starting值为false
if (unlikely (starting)) {
starting = false;
// 初始化mailbox队列
opt_sync.lock ();
int mazmq = max_sockets;
int ios = io_thread_count;
opt_sync.unlock ();
slot_count = mazmq + ios + 2;
slots = (mailbox_t**) malloc (sizeof (mailbox_t*) * slot_count);
alloc_assert (slots);
。。。 //省略了一些暂时用不到的过程
// 收集空的slot编号
for (int32_t i = (int32_t) slot_count - 1;
i >= (int32_t) ios + 2; i--) {
empty_slots.push_back (i);
slots [i] = NULL;
// 空的slot用完了,返回错误信息
if (empty_slots.empty ()) {
slot_sync.unlock ();
errno = EMFILE;
return NULL;
// Choose a slot for the socket.
uint32_t slot = empty_slots.back ();
empty_slots.pop_back ();
// Generate new unique socket ID.
int sid = ((int) max_socket_id.add (1)) + 1;
// 这里才真正开始创建socket
socket_base_t *s = socket_base_t::create (type_, this, slot, sid);
if (!s) {
empty_slots.push_back (slot);
slot_sync.unlock ();
return NULL;
sockets.push_back (s);
slots [slot] = s->get_mailbox ();
slot_sync.unlock ();
return s;
根据starting(见ctx构造函数)标志第一次创建socket时需要做好初始化工作,其实比较重要的是启动I/O线程,进程内通信的时候暂时没用到这个线程,所以这里先忽略之。代码里面另一个重点是slot,这个东西是指向mailbox的指针,前面简单注释过mailbox是用来接收命令的,后面构建起连接的时候就可以看到这个mailbox的真正作用了。此外上面程序值得参考的是创建socket失败后zmq的处理方式。socket_base_t::create函数代码很简单,就是根据type_创建不同类型的socket,根据示例程序我们目前创建的是rep_t类的socket,其构造函数需要的参数有context、tid、sid,分别是上下文、slot集合中的序号,为socket产生的唯一id,这三个参数其实前面的程序里都有介绍。rep_t的构造函数这里不展开了,传递的信息主要是rep_t与router_t这两类socket之间的关系,以及几个功能变量的赋值。rep_t继承自router_t,router_t继承自socket_base_t。socket_base_t的继承关系就比较复杂了,后面涉及到的地方会进行解释。构造函数还涉及各类socket发挥特性用到的参数的初值,这部分在后面的流程中看起来会更清晰,因此这里暂时无视了。这里最重要的信息还是rep_t是基于router_t的实现的,后面可以看到其实rep_t是对router_t的相关功能函数做了限制性调用来达到应答特性的。(slot可以见上面ctx的构造函数,最终分配到slot上面的其实是mailbox的指针)
三、连接的构建
目前程序走到int rc = zmq_bind(responder, "inproc://hello");这行,用过的同学都知道,这里是用来绑定“inproc://hello”这个端点的,容易推测:此后其他socket就可以通过连接此端点来建立前面提到的两个线程内socket之间的通信队列的。看源码前不妨简单思考一下,这个要绑定的端点信息应该保存在哪里才能在目前的情况下由不同线程访问。其实前面给出ctx_t类的定义的时候已经给出明确答案了,那里面有个endpoint的集合,其实endpoint就是这里我说的“端点”。这个端点是zmq内部通用的地址,有一定的格式。ctx_t不同线程共同持有一个,一个进程一般只有一个。前面的源码中其实可以看出ctx_t中包含很多“集合”信息,其实使用zmq库开始创建socket时,我们就开始在zmq的多线程框架下开始工作了。ctx_t的作用我们会在后面的分析中一次又一次的深化的。废话不多说了,先看程序再说吧。
int zmq::socket_base_t::bind (const char *addr_)
// 这边是判断进程状态的,如果已经是无效的,那就不用再麻烦了
if (unlikely (ctx_terminated)) {
errno = ETERM;
return -1;
// 处理遗留的“命令”,命令从哪里来到哪里去,这个问题稍后解释
// 从流程上看,这里是我们对刚建立的socket的操作,其他进程被我刻意拖延了,
// 此时不会有需要处理的“命令”,所以可以先跳过这麻烦的东东啦
int rc = process_commands (0, false);
if (unlikely (rc != 0))
return -1;
// 我们绑定时用的“地址”其实分两部分,“ipc”,“tcp”,“inproc”这些其实是协议
// 后面我们自己定的才是纯粹的地址,下面的函数就是将其正确划分开的
std::string protocol;
std::string address
;
rc = parse_uri (addr_, protocol, address);
if (rc != 0)
return -1;
// 检查一下协议是否合法,如果随便填一个“hi”之类的单词,再这里会被打回去的
rc = check_protocol (protocol);
if (rc != 0)
return -1;
if (protocol == "inproc") {
// 这边开始是针对进程内通信的操作,endpoint的定义我贴在下面了
endpoint_t endpoint = {this, options};
int rc = register_endpoint (addr_, endpoint);
if (rc == 0) {
// 这边是处理挂起的连接,在我们的流程中暂时不经历到,以后讲zmq几个有趣的
// 的特性的时候再来看这一段
connect_pending(addr_, this);
last_endpoint.assign (addr_);
return rc;
struct endpoint_t
socket_base_t *socket;
options_t options;
// 这里是endpoints_t的定义,在ctx中我们已经见过了,知道了这个下面的register函数
// 就没有任何难度了
typedef std::map <std::string, endpoint_t> endpoints_t;
endpoints_t endpoints;
int zmq::ctx_t::register_endpoint (const char *addr_, endpoint_t &endpoint_)
endpoints_sync.lock ();
bool inserted = endpoints.insert (endpoints_t::value_type (
std::string (addr_), endpoint_)).second;
endpoints_sync.unlock ();
if (!inserted) {
errno = EADDRINUSE;
return -1;
return 0;
上面的程序直接跳到了socket的bind那边,api进来的流程不多啰嗦了。其实这个进程内通信的bind就做了一件事情:注册endpoint到ctx中,目的就像我们平时绑定ip:port一样,为了让通信的对端可以找到我们。此后只要有人找这个地址,找到的就是现在绑定成功的这个socket。上面的程序里注册endpoint的时候又用到了锁,我想很多同学看zmq guild的时候都留意到了作者说zmq的无锁性质,而从我们开始看源码到现在,这才看了几行啊,怎么这么多锁?这就要谈谈zmq的关键路径的概念,所谓关键路径,是运用zmq库反复调用的那些代码路径, zmq的应用更多的是面向长期存在的连接的,所以说反复调用的路径主要是和收发信息相关的部分,而不是那些有限次数的操作。zmq把优化集中到了关键路径上,而不是第一次创建socket,socket绑定这些有限次调用的过程中,我们运用zmq的程序如果长期运行,那么运用zmq的部分应该是运行在zmq的关键路径上的,否则就需要再好好考虑一下我们的方案了。只优化关键路径,而不对一次性操作进行过度的优化,也是我们自己设计程序值得参考的一点哦!
接下来我们该看connect了吗?可是看我写的那个程序,主线程貌似直接recv了啊,也没有监听之类的函数,这时候另外一个线程应该还在sleep才对啊!既然这样,我们就直接看recv,想必recv一定会阻塞在某个地方,我们就正好看看在没有任何连接过来的情况下怎么recv的。recv调用实际上是以msg_t为基本单元来进行的,msg_t是zmq中的消息,目前按照字面意思理解就ok,msg就是存储信息的,可能还可以根据信息的类型打上一些标记吧。我们直接看recv核心的函数。
int zmq::socket_base_t::recv (msg_t *msg_, int flags_)
// Check whether the library haven't been shut down yet.
if (unlikely (ctx_terminated)) {
errno = ETERM;
return -1;
// Check whether message passed to the function is valid.
if (unlikely (!msg_ || !msg_->check ())) {
errno = EFAULT;
return -1;
// 这里简单可以认为是随着时间的推移,需要每几个回合去处理一下命令了
// ticks默认是0,这一行之后就是1,这个if是走不到的,我们还是先不看命令了
if (++ticks == inbound_poll_rate) {
if (unlikely (process_commands (0, false) != 0))
return -1;
ticks = 0;
// 这里是接收信息的部分,调用的是实际子类的xrecv函数,这里就是rep_t::xrecv
int rc = xrecv (msg_);
if (unlikely (rc != 0 && errno != EAGAIN))
return -1;
// 取到msg了,就直接返回了,这里我们应该返回不了吧
if (rc == 0) {
extract_flags (msg_);
return 0;
暂时只贴一半,因为中间有个巨大的xrecv核心函数,影响了下面的流程。xrecv是用来接收消息根据现在进程的情况,推测这程序,要么是在xrecv这行阻塞了,要么xrecv返回非0值,且errno被设置成EAGAIN了,然后进程跑下半部分的程序。看来我们非得看看xrecv了。前面简单介绍了一下socket_base_t和其子类的关系,从socket的创建也可以看出来一点眉目。socket基类中的函数可以说是模板方法,制定好了流程,关键的实现是由子类的对应方法来完成的。rep_t派生自router_t,对其收发做了限制以达到自己的特性,因此看代码之前可以想到rep_t中必定调用了router_t的xrecv。
int zmq::rep_t::xrecv (msg_t *msg_)
// 已经开始回复消息了,那么rep_t是不能再接收消息的,这是rep的特性
if (sending_reply) {
errno = EFSM;
return -1;
// 果然主要还是调用router的xrecv啦
if (request_begins) {
while (true) {
int rc = router_t::xrecv (msg_);
if (rc != 0)
return rc;
int zmq::router_t::xrecv (msg_t *msg_)
// 预先取出?啥意思?反正看默认构成函数这里肯定是false啦,先不管
if (prefetched) {
if (!identity_sent) {
int rc = msg_->move (prefetched_id);
errno_assert (rc == 0);
identity_sent = true;
else {
int rc = msg_->move (prefetched_msg);
errno_assert (rc == 0);
prefetched = false;
more_in = msg_->flags () & msg_t::more ? true : false;
return 0;
pipe_t *pipe = NULL;
// 是从fq这东东里面取出来的,那fq是啥?看来是现在的关键问题了
int rc = fq.recvpipe (msg_, &pipe);
while (rc == 0 && msg_->is_identity ())
rc = fq.recvpipe (msg_, &pipe);
if (rc != 0)
return -1;
上面的代码里的信息主要就两个:一个是rep_t果然是依赖于router_t::xrecv的,流程控制从一开始就在做了;二是router的接收消息需要根据一个叫fq的对象的情况来执行。那么下面自然是要研究一下这个fq了。看一下源码,fq是router的router的私有成员,是fq_t类的。再看fq_t类,又是该死的默认构造函数:
zmq::fq_t::fq_t () :
active (0),
current (0),
more (false)
}信息还是很少,不过根据前面的经验,默认构造函数里面的这三个变量应该是要对后面函数执行流程有关。只要完整看下这个类了。
class fq_t
public:
fq_t ();
~fq_t ();
void attach (pipe_t *pipe_);
void activated (pipe_t *pipe_);
void pipe_terminated (pipe_t *pipe_);
int recv (msg_t *msg_);
int recvpipe (msg_t *msg_, pipe_t **pipe_);
bool has_in ();
private:
// Inbound pipes.
typedef array_t <pipe_t, 1> pipes_t;
pipes_t pipes;
// Number of active pipes. All the active pipes are located at the
// beginning of the pipes array.
pipes_t
::size_type active;
// Index of the next bound pipe to read a message from.
pipes_t::size_type current;
// If true, part of a multipart message was already received, but
// there are following parts still waiting in the current pipe.
bool more;
fq_t (const fq_t&);
const fq_t &operator = (const fq_t&);
这边的源码,我连注释都没有动就搬过来了,因为第一次看的时候对这个类真的只能是完全拼推测来认知。首先从名字看,看过zmq guild的同学,不难推测,这个fq_t很可能是和guild里面说的router接收消息时的“公平队列”有关的一个类,在看注释,“Inbound pipes”,估计这个就是一系列的接收消息的通道了,那么active就是现在可以接收消息的pipe数量,current就是现在正在接收消息的pipe编号了,相比current会随着消息的接收在active范围内遍历吧。more的注释正好可以让我们肯定这一点,因为一条管道开始接收消息,那么总得收完再换吧。简单推测后我们来看关系到我们的recv_pipe函数。
int zmq::fq_t::recvpipe (msg_t *msg_, pipe_t **pipe_)
// Deallocate old content of the message.
int rc = msg_->close ();
errno_assert (rc == 0);
// Round-robin over the pipes to get the next message.
while (active > 0) {
// Try to fetch new message. If we've already read part of the message
// subsequent part should be immediately available.
bool fetched = pipes [current]->read (msg_);
// Note that when message is not fetched, current pipe is deactivated
// and replaced by another active pipe. Thus we don't have to increase
// the 'current' pointer.
if (fetched) {
if (pipe_)
*pipe_ = pipes [current];
more = msg_->flags () & msg_t::more? true: false;
if (!more)
current = (current + 1) % active;
return 0;
// Check the atomicity of the message.
// If we've already received the first part of the message
// we should get the remaining parts without blocking.
zmq_assert (!more);
active--;
pipes.swap (current, active);
if (current == active)
current = 0;
// No message is available. Initialise the output parameter
// to be a 0-byte message.
rc = msg_->init ();
errno_assert (rc == 0);
errno = EAGAIN;
return -1;
这里我又把整个源码贴上来了,在这里就算我们一眼就能看出来,active为0,最后必然是走到errno置为EAGAIN这个我们之前预想的可能上,但是我想大部分程序员是一定会想通过这个函数的剩余部分来确认自己刚看到这个类时,直觉上的推测是否准确的。很明显我前面说的那些推测,从这个函数的流程和注释中来看,真是太TM准了。。。得到了结果,我们迅速回去看前面的主线吧。这一段推测不小心暴露了我平时看源码时真实的思维方法,幸好这个类比较小其实针对前面的几个重大类,先脱离流程来分析是很累人的。。。
这里直接调回socket_base_t的recv函数了,因为中间的经过在我贴的代码中就是显而易见的了。当时推测的两种可能,看来第二种是正确的了。接下去只能看recv的下半部分了,因为我们预计的阻塞还没有到来。
int zmq::socket_base_t::recv (msg_t *msg_, int flags_)
// 如果recv设置为非阻塞,如下处理,我们这边显然不是。
// flags==0,options.rcvtimeo==-1
if (flags_ & ZMQ_DONTWAIT || options.rcvtimeo == 0) {
if (unlikely (process_commands (0, false) != 0))
return -1;
ticks = 0;
rc = xrecv (msg_);
if (rc < 0)
return rc;
extract_flags (msg_);
return 0;
// 设置后面处理命令需要用到的超时时间
int timeout = options.rcvtimeo;
uint64_t end = timeout < 0 ? 0 : (clock.now_ms () + timeout);
// 阻塞模式下,只有新的命令才能拯救我们脱离recv的苦海了,看那个unlikely
bool block = (ticks != 0);
while (true) {
if (unlikely (process_commands (block ? timeout : 0, false) != 0))
return -1;
rc = xrecv (msg_);
if (rc == 0) {
ticks = 0;
break;
if (unlikely (errno != EAGAIN))
return -1;
block = true;
if (timeout > 0) {
timeout = (int) (end - clock.now_ms ());
if (timeout <= 0) {
errno = EAGAIN;
return -1;
extract_flags (msg_);
return 0;
options的初始化,感兴趣的同学可以去创建socket的地方在查看一下,顺便再过一边socket的创建过程吧。这里我就直接给出了关键的那个options.rcvtimeo的值。看到这里大家都能预测出来这次那个process_commands非得给个交代了,要阻塞也是这里阻塞了,timeout传进去的值是-1。这个函数我不直接贴出来了,直接告诉大家归根到底就是调用mailbox的recv函数。这个函数是zmq中难点之一,因为伴随着作者定义线程状态概念而改变流程,各种状态也在这之中切换。目前我们尽量以轻松的方式看看这个函数。
int zmq::mailbox_t::recv (command_t *cmd_, int timeout_)
// 活动状态,尝试直接取命令
if (active) {
bool ok = cpipe.read (cmd_);
if (ok)
return 0;
// 取命令失败切换到休眠态
active = false;
signaler.recv ();
// 这个函数正常返回代表命令来了
int rc = signaler.wait (timeout_);
if (rc != 0 && (errno == EAGAIN || errno == EINTR))
return -1;
// 得知命令到来,再次切换到active状态
active = true;
// 这里是取出命令的操作
errno_assert (rc == 0);
bool ok = cpipe.read (cmd_);
zmq_assert (ok);
return 0;
整个函数除了状态切换外,两个重点是signaler是什么,cpipe又是什么东东。signaler的构造函数很简单,就是调一个叫make_fdpair的函数,有经验的同学肯定知道这是要干什么了。我简单整理一下make_fdpair的代码:
int zmq::signaler_t::make_fdpair (fd_t *r_, fd_t *w_)
#if defined ZMQ_HAVE_EVENTFD
// Create eventfd object.
fd_t fd = eventfd (0, 0);
errno_assert (fd != -1);
*w_ = fd;
*r_ = fd;
return 0;
我想大部分人现在用的linux版本下这个函数就会跑这几行。用到一个eventfd的知识点,在这里就是个线程同步的工具,一端写这个eventfd,一端就可以读到,就是socketpair类似的功能。自然把这个fd用来做事件驱动是非常舒服的一件事,多路复用机制可以随便选了。再说cpipe,看名字很像管道、队列之类的,这东西和我开始画的那个线程间的两条管道是一类。这是zmq中的基本组件,以后会专门讲,这里给个介绍,这东西是个无锁队列,本质上是一写一读的无锁队列,而mailbox使用时,由于ctx_t的存在,看起来就是个“多写一读”的无锁队列了。其实看到fd和管道很多同学已经明白这个mailbox的基本运作原理了:对端往pipe里面写东西,同时向这个fd也写一个很短的信息来触发用多路复用机制监听这个fd的mailbox的激活。上面程序里int rc = signaler.wait (timeout_);这一行,timeout_的值为-1,是在socket的recv函数那里带进来的,自然程序就阻塞在这个多路复用的wait这里了。至于signaler是怎么和多路复用机制结合的,后面有机会再讲,反正说到这里应该不难理解了吧。至此,期盼已久的阻塞终于出现了,因为当前的状态,recv函数期盼socket能够收到一个命令来处理,来改变目前没有东西可接收的状态。那么我们终于可以看看发送端这时候怎么做才能连上端点,再发送消息出来了。
发送线程成功创建socket以后就开始视图连接端点了,从上面的分析看,连接成功以后接收端的fq对象队列里面应该会有对应的pipe。下面我们就来看下connect函数。
int zmq::socket_base_t::connect (const char *addr_)
if (unlikely (ctx_terminated)) {
errno = ETERM;
return -1;
// 这边的处理命令目前是无果的,timeout传的是0,不会阻塞哦
int rc = process_commands (0, false);
if (unlikely (rc != 0))
return -1;
// 这边前面解释过了,一样的
std::string protocol;
std::string address;
rc = parse_uri (addr_, protocol, address);
if (rc != 0)
return -1;
rc = check_protocol (protocol);
if (rc != 0)
return -1;
if (protocol == "inproc") {
// 这里明显是要到ctx里面去找的,目前的情况,可以顺利找到我们绑定的那个
endpoint_t peer = find_endpoint (addr_);
// HWM:high water mark,具体作用看guild才能了解了,这里执行完两个值都是2000
int sndhwm = 0;
if (peer.socket == NULL)
sndhwm = options.sndhwm;
else if (options.sndhwm != 0 && peer.options.rcvhwm != 0)
sndhwm = options.sndhwm + peer.options.rcvhwm;
int rcvhwm = 0;
if (peer.socket == NULL)
rcvhwm = options.rcvhwm;
else if (options.rcvhwm != 0 && peer.options.sndhwm != 0)
rcvhwm = options.rcvhwm + peer.options.sndhwm;
// 这边开始是创建双向平行pipe的步骤了,后面详细看
object_t *parents [2] = {this, peer.socket == NULL ? this : peer.socket};
pipe_t *new_pipes [2] = {NULL, NULL};
bool conflate = options.conflate &&
(options.type == ZMQ_DEALER ||
options.type == ZMQ_PULL ||
options.type == ZMQ_PUSH ||
options.type == ZMQ_PUB ||
options.type == ZMQ_SUB);
int hwms [2] = {conflate? -1 : sndhwm, conflate? -1 : rcvhwm};
bool conflates [2] = {conflate, conflate};
// 创建出来的new_pipes数组里的东西其实是最早那图上的两条pipe的local end
int rc = pipepair (parents, new_pipes, hwms, conflates);
errno_assert (rc == 0);
// 这里是把创建出来的new pipe“登记”到socket自己这儿,具体怎么操作和
// socket的类型有很大关系
attach_pipe (new_pipes [0]);
if (!peer.socket)
endpoint_t endpoint = {this, options};
pending_connection_t pending_connection = {endpoint, new_pipes [0], new_pipes [1]};
pend_connection (addr_, pending_connection);
// 我们走的肯定是这里啦,我们的对端是rep_t类型的,这个变量值为true
// 这边可以去看下构造函数,因为这个特性其实是router_t里的
if (peer.options.recv_identity) {
msg_t id;
rc = id.init_size (options.identity_size);
errno_assert (rc == 0);
// 这里别怀疑,如果我们没什么特别的操作,这里拷贝的真的是个空的东东
// options.identity在socket构造时是空的,这边我们没有设置,还是空的
memcpy (id.data (), options.identity, options.identity_size);
// 这边给msg设置了一个特殊的标志,关于msg的标志,目前是哪里用到说哪里
id.set_flags (msg_t::identity);
// 终于看到往pipe里写消息的地方了,我们稍后仔细看
bool written = new_pipes [0]->write (&id);
zmq_assert (written);
new_pipes [0]->flush ();
// 这边暂时走不到
if (options.recv_identity) {
msg_t id;
rc = id.init_size (peer.options.identity_size);
errno_assert (rc == 0);
memcpy (id.data (), peer.options.identity, peer.options.identity_size);
id.set_flags (msg_t::identity);
bool written = new_pipes [1]->write (&id);
zmq_assert (written);
new_pipes [1]->flush ();
// 这里就是朝思暮想的把创建的pipe信息传给对端的地方,通过发送命令
send_bind (peer.socket, new_pipes [1], false);
// 这边两个函数很简单,功能以后用到了再看好了
last_endpoint.assign (addr_);
inprocs.insert (inprocs_t::value_type (std::string (addr_), new_pipes[0]));
return 0;
其中connect函数是到目前我们遇到的最麻烦的一个函数了,主要里面调用的东西比较多,只好耐着性子慢慢看了,因为这里有很多不能跳过的部分。第一个就是pipepair了,从上面的注释可以大概了解一下,从这里开始我们要创建两个socket之间的连接通道了。
int zmq::pipepair (class object_t *parents_ [2], class pipe_t* pipes_
[2],
int hwms_ [2], bool conflate_ [2])
// 其实ypipe_t才是最早图上的那两条管道,pipe_t和其的关系见下
typedef ypipe_t <msg_t, message_pipe_granularity> upipe_normal_t;
typedef ypipe_conflate_t <msg_t, message_pipe_granularity> upipe_conflate_t;
pipe_t::upipe_t *upipe1;
if(conflate_ [0])
upipe1 = new (std::nothrow) upipe_conflate_t ();
upipe1 = new (std::nothrow) upipe_normal_t ();
alloc_assert (upipe1);
pipe_t::upipe_t *upipe2;
if(conflate_ [1])
upipe2 = new (std::nothrow) upipe_conflate_t ();
upipe2 = new (std::nothrow) upipe_normal_t ();
alloc_assert (upipe2);
// 注意下面两个函数里,两个ypipe参数的位置换了一下,parents则是对应的socket
// 每个socket后面会attach上自己的pipe_t对象
pipes_ [0] = new (std::nothrow) pipe_t (parents_ [0], upipe1, upipe2,
hwms_ [1], hwms_ [0], conflate_ [0]);
alloc_assert (pipes_ [0]);
pipes_ [1] = new (std::nothrow) pipe_t (parents_ [1], upipe2, upipe1,
hwms_ [0], hwms_ [1], conflate_ [1]);
alloc_assert (pipes_ [1]);
// 这里的重要目的是告诉每个pipe_t它所“拥有”的ypipe对象还有别的拥有者,没有这
// 个拥有者的允许,可别想对ypipe为所欲为哦
pipes_ [0]->set_peer (pipes_ [1]);
pipes_ [1]->set_peer (pipes_ [0]);
return 0;
到这个函数,代码里面的注释已经有些无力了。ypipe_t其实才是我们前面说的无锁队列的本尊,zmq的这类队列其实都是一写一读的,多一个对端就要多一组这样的平行pipe。多写多读也有办法实现无锁队列,但实际上采用的算法实质上都是把锁的粒度减小,在循环中尝试原子操作。zmq放弃发现新算法这种很难成功的道路,转化降级了这个问题来优化性能。因为只能一写一读,所以哪个线程控制这个ypipe的读端,哪个控制写端需要确定。上面的函数,主要做的其实就是这事。在pipe_t的构造函数里面,传入了这连个ypipe_t对象,把其中一个作为读端、一个作为写端,将来对pipe_t的读写,都会找到对应的ypipe_t上,所以ypipe_t才是真正的队列,pipe_t并不包含ypipe_t,更确切的说,这之间是一种引用关系。两个pipe_t都引用了同一对ypipe_t,只是放在了不同的位置上。pipe_t创建成功以后,还需要确定这一对pipe_t与我们的socket之间的关系,看这架势肯定是一个socket要有一个了。attach_pipe (new_pipes [0]);明显是要把新建的pipe_t同socket关联起来了。这个函数还是需要看一下的。
void zmq::socket_base_t::attach_pipe (pipe_t *pipe_, bool subscribe_to_all_)
// 这边是为了将来socket关闭时候使用
pipe_->set_event_sink (this);
pipes.push_back (pipe_);
// 具体attach的方法和socket类型有关
xattach_pipe (pipe_, subscribe_to_all_);
if (is_terminating ()) {
register_term_acks (1);
pipe_->terminate (false);
void zmq::dealer_t::xattach_pipe (pipe_t *pipe_, bool subscribe_to_all_)
// 这个参数对dealer来说是无用的
(void) subscribe_to_all_;
zmq_assert (pipe_);
。。。//中间这个if目前走不到,不看了吧
fq.attach (pipe_);
lb.attach (pipe_);
req_t派生自dealer_t,因此这里主要调用 dealer_t::xattach_pipe,其实就是把pipe传给fq和lb两个对象。fq前面我们遇到过了,是个公平队列,router_t也是用这个来接收消息的。对于dealer_t来说,要做的事情是均衡的发送请求,公平的接收回应;对于router_t来说要做的是
公平的接收请求,根据明确的目标发送响应。看过zmq guild的同学一定能明白这里的意思,
简单来说,lb是用来发送请求的,现在把pipe加入其中,这个pipe就会成为将来发送消息时的
选择之一。fq是用来接收消息的,把pipe加入其中后,当轮到这个pipe读取的时候,会从这个
pipe中读取。因为dealer_t的性质,这两个对象都是必需的,在后面的send和recv中,他们就会出场了。
之后是根据对端socket的性质决定是否发送标识给对端。这里是我们第一次看到正式向pipe_t里面写入消息。注释里我写了,这时候其实写的是个空的msg_t,就是没有date的msg_t。这里的write函数可以按照写入队列来理解。flush函数则是实现无锁队列的关键,有兴趣的同学这时候就可以去看下了,因为这里面内容比较复杂,而且不会影响到本文主题,我这里还是把这个函数作为zmq基础类附带的一个功能来对待,给大家交代:经过flush函数之后前面write的内容才能够被对端读到。对于这里去看flush源码的同学,我这里也先给一点提示,cas仍然是无锁的关键,对端从未读过的情况下,这时候flush是检测不出对端是否处于休眠状态的,这里不会向对方的mailbox发送命令。另外前面没有强调,pipe_t构造的时候,socket作为一个参数传进去了,再看一步pipe_t用的是socket的tid,也就是同一个mailbox。发送完这个消息后,由于对端pipe_t还没有关联上具体的socket,因此不会有对象去读取。接下来自然是告诉对端socket把另一个为其创建的socket给attach上了,而这本身就是一个线程间的通信,联想到前面我们的对端还阻塞在接收mailbox的命令来上,那么这个函数的关键任务是可想而知的。
void zmq::object_t::send_bind (own_t *destination_, pipe_t *pipe_,
bool inc_seqnum_)
if (inc_seqnum_)
destination_->inc_seqnum ();
command_t cmd;
cmd.destination = destination_;
cmd.type = command_t::bind;
cmd.args.bind.pipe = pipe_;
send_command (cmd);
inc_seqnum_其实是告诉对方,又多了一个和你有联系的对象了,你释放的时候需要注意了。这里已经用不上了,因为前面find_endpoint的时候已经增加过这个值了。发送命令是一个完整的体系,这里仍然是作为基础功能来看待。其中的关键自然是发送命令的同时会去激活mailbox的eventfd,这样signaler那边的等待就解除了。我们发出的命令种类是bind,参数是pipe,是让对方对绑定参数里的这个pipe。
回来以后是mailbox的recv函数,这里就非常顺利了,因为可以直接看到,socket处理这个命令的方式就是attach_pipe,对于router来说,也就是把pipe加入到fq的active列表中。此外,router_t的attach,还要即刻处理identity那个消息。因为router_t要求连接时传递identity,那个消息。这里至少会得到一个空的identity消息。router_t需要对每个连接对应的pipe_t做一个标识,接收来自这个pipe_t的消息的时候会自动在消息前面加上一个标识,发送的时候则根据消息组中第一个消息确定这组消息是要发送给哪个pipe_t的。自此connect需要做的事情已经完成了,对方会收到命令,然后处理之。因此我们又可以返回去看接收端socket的处理情况了。如果发过来的identity是个空的消息,router_t就会自己给这个连接创建一个唯一标识。至此两个线程间的连接就完成了。我们需要更新一下图1来表明目前的状况。
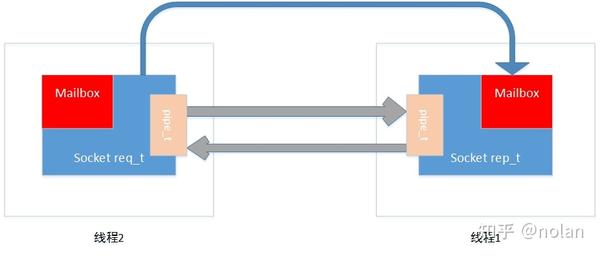
pipe_t掌握的是实际无锁队列的读端和写端;mailbox的功能远不止我们一开始设想的同pipe配合使用,pipe的搭建就是依靠mailbox来进行的。能够往对端的mailbox发命令是因为socket创建出来的时候,就把mailbox的注册回ctx对象中,而每个socket都能引用ctx。只要在endpoints集合中找到对端端点,那么发送命令到对方的mailbox就可以实现了。至此,线程间沟通的桥梁已经搭建完毕了,现在req一方的发送队列中的identity消息已经被处理,rep这边如果开始读取,第一次应该无法从pipe中读出任何数据,下面我们就从这里开始。
五、通信流程
示例代码中我在req发送消息之前加了sleep,我们回来看rep的recv的时候,pipe中的数据应该只有identity这个消息,Mailbox中命令也仅处理了一个bind_pipe。此时socket_bast_t::recv再次调用xrecv函数,也就是rep_t::xrecv。由于示例中的那个sleep(30),情况和刚开始是一样的,这里返回的仍然是-1,errno为EAGAIN。
while (true) {
if (unlikely (process_commands (block ? timeout : 0, false) != 0))
return -1;
rc = xrecv (msg_);
if (rc == 0) {
ticks = 0;
break;
if (unlikely (errno != EAGAIN))
return -1;
block = true;
// timeout为-1,阻塞继续进行
if (timeout > 0) {
timeout = (int) (end - clock.now_ms ());
if (timeout <= 0) {
errno = EAGAIN;
return -1;
在上面这个循环里面,recv函数又回到了阻塞在处理命令阶段了。另外值得一提的是在已经有pipe的情况下,接收失败会引起fq把失败的pipe从active队列中移出。这次的阻塞要等的是激活pipe的命令。现在切换回req所在的线程,看看发送消息的时候是否如我们所想的,发出相应的命令。
zmq_send函数处理阻塞的结构上和recv有些相似,核心仍然是调用rep_t::xsend函数,我们这次直接来看xsend函数。
int zmq::req_t::xsend (msg_t *msg_)
// req的特性是收到上一个回复之前不能发送下一个请求
if (receiving_reply) {
if (strict) {
errno = EFSM;
return -1;
if (reply_pipe)
reply_pipe->terminate (false);
receiving_reply = false;
message_begins = true;
// 每次开始发送请求,需要发一个bottom消息,后面才是真正带有信息的消息
if (message_begins) {
reply_pipe = NULL;
msg_t bottom;
int rc = bottom.init ();
errno_assert (rc == 0);
bottom.set_flags (msg_t::more);
// req_t需要调用dealer的机制来发送消息
rc = dealer_t::sendpipe (&bottom, &reply_pipe);
if (rc != 0)
return -1;
assert (reply_pipe);
message_begins = false;
// 如果有之前收到的其他回应消息,这里要先丢弃,否则收到的回复可能是很早以前的
msg_t drop;
while (true) {
rc = drop.init ();
errno_assert (rc == 0);
rc = dealer_t::xrecv (&drop);
if (rc != 0)
break;
drop.close ();
bool more = msg_->flags () & msg_t::more ? true : false;
// 这里发出去的是带有信息的消息部分
int rc = dealer_t::xsend (msg_);
if (rc != 0)
return rc;
// 如果没有后续消息要发送了就进入接收回应状态,同时重置message_begins
// 标识,下次发送请求的时候需要进入begins的流程
if (!more) {
receiving_reply = true;
message_begins = true;
return 0;
这里值得注意的是开始发送一段消息之前,先发送一个空的bottom消息出去,接收方根据这个规则,处理接收到的消息的时候会把bottom作为处理消息的分隔符,在不同类型的socket中处理这个分隔符的方法有所不同,稍后我们就可以看到rep_t对此的精妙处理了。其实这个bottom本质上可以说是处理多层消息的关键,在直接应用router_t接收、发送消息的时候,使用者可以直接体验。dealer::xsend函数这里不展开讲了,但里面有一步关键操作:向管道写入消息并刷新,这个刷新会发送激活读线程的命令,解除recv的阻塞。这类操作的原理其实很相似,写的时候可以通过原子操作的结果判断对方上一次是不是进入到休眠状态,再决定是否发送命令来激活对方。send函数在线程间的pipe中写入了两个消息,一个是空的bottom,一个是带有内容的消息。回到接收方,命令处理的阻塞会被发送方通过mailbox解除,router_t重新把对应的pipe_t加到active列表中,再次开始尝试接收消息。这时候再来看rep_t和router_t的recv函数就比较有意思了。
int zmq::rep_t::xrecv (msg_t *msg_)
// 应答没有完成时,不能收下一条请求
if (sending_reply) {
errno = EFSM;
return -1;
// 从接收到请求开始,rep就确定了下一步发送消息的对象了
if (request_begins) {
while (true) {
int rc = router_t::xrecv (msg_);
if (rc != 0)
return rc;
if ((msg_->flags () & msg_t::more)) {
// bottom之前的消息都是用来回溯发送方的
bool bottom = (msg_->size () == 0);
// 发送方相关的消息注定要用于下一次的发送,这里就填入队列了
rc = router_t::xsend (msg_);
errno_assert (rc == 0);
if (bottom)
break;
else {
// 这里收到的信息如果不是预期的,那就找不到发送方了
// 需要做的是丢弃已经放入发送队列中的消息
rc = router_t::rollback ();
errno_assert (rc == 0);
// 做完这事后面就可以正常接收消息了,把这个变量改掉
request_begins = false;
// 这里收到的消息是要回复给调用者的
int rc = router_t::xrecv (msg_);
if (rc != 0)
return rc;
// 如果不需要继续接收新的消息了,rep的状态机就可以切到应答状态了
if (!(msg_->flags () & msg_t::more)) {
sending_reply = true;
request_begins = true;
return 0;
int zmq::router_t::xrecv (msg_t *msg_)
// 第二次调用的时候会进入这个if
if (prefetched) {
if (!identity_sent) {
int rc = msg_->move (prefetched_id);
errno_assert (rc == 0);
identity_sent = true;
else {
int rc = msg_->move (prefetched_msg);
errno_assert (rc == 0);
prefetched = false;
more_in = msg_->flags () & msg_t::more ? true : false;
return 0;
pipe_t *pipe = NULL;
int rc = fq.recvpipe (msg_, &pipe);
// 只有在重连的情况下,这里才有可能收到identity
// 第一次连接发生的时候,identity在连接建立的时候就完成了接收过程
while (rc == 0 && msg_->is_identity ())
rc = fq.recvpipe (msg_, &pipe);
if (rc != 0)
return -1;
zmq_assert (pipe != NULL);
// more_in这个名字取的很巧妙,代表已经有消息进来了,而且还有一些消息要进来
// 还没有消息进来的时候是false,第一次调用后就是true了,知道明确没有后续
// 消息到来再变为false。这样就把第一次收取消息区分开来了。
if (more_in)
more_in = msg_->flags () & msg_t::more ? true : false;
else {
// 程序走到这里必然是收到一组新的消息
// router需要把对方的identity拿出来加到消息头上,以便调用者可以回复
// 所以这时候不管实际收到的消息是什么,都只是暂时放到prefetched中
rc = prefetched_msg.move (*msg_);
errno_assert (rc == 0);
prefetched = true;
// 用找到的identity来代替实际收到的消息,回给调用者
blob_t identity = pipe->get_identity ();
rc = msg_->init_size (identity.size ());
errno_assert (rc == 0);
memcpy (msg_->data (), identity.data (), identity.size ());
msg_->set_flags (msg_t::more);