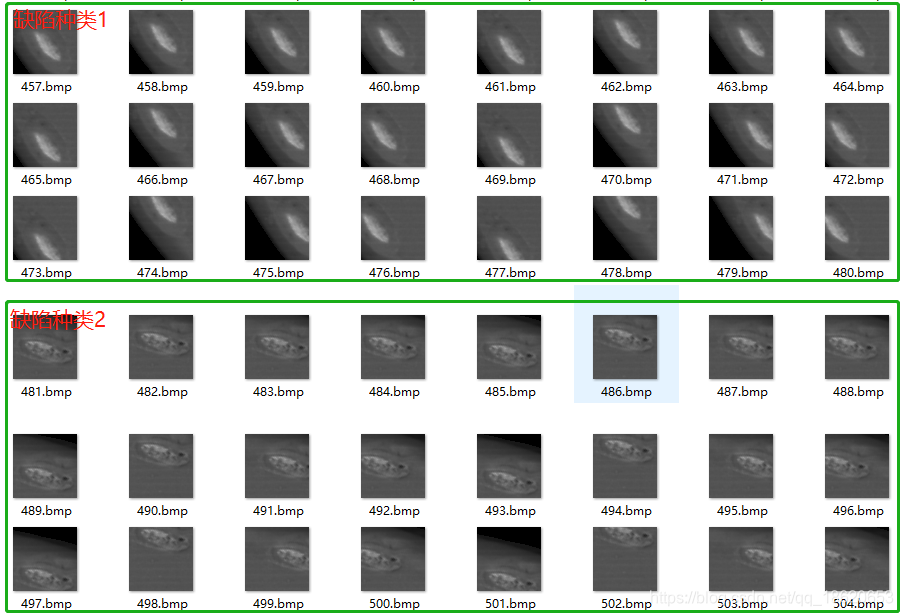
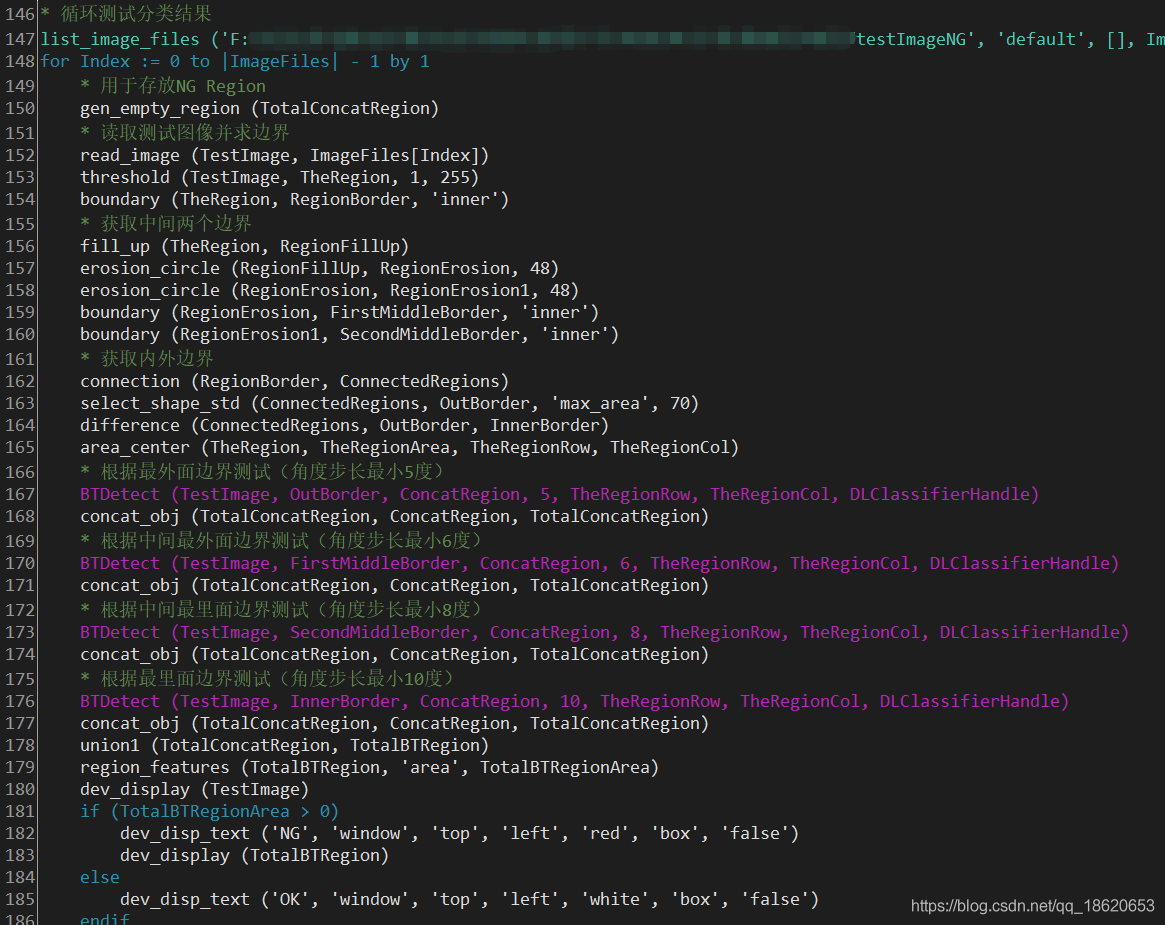
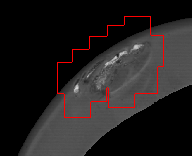
|
|
|
相关文章推荐

|
耍酷的墨镜 · 【错误记录】Android 命令行执行 ...· 3 月前 · |
|
|
紧张的小熊猫 · scRNA分析|自定义你的箱线图-统计检验, ...· 2 月前 · |
|
|
傻傻的馒头 · 高性能异步框架Celery入坑指南-阿里云开 ...· 1 月前 · |
|
|
低调的马克杯 · Vue生成PDF文件攻略:html2canv ...· 4 天前 · |
|
|
乐观的灭火器 · (篇八)C语言在母串删子串、输入位置截取子串 ...· 1 年前 · |
|
|
酒量小的登山鞋 · 搜索结果_javascript鎬庝箞鑾峰緱s ...· 2 年前 · |
|
|
重感情的水煮肉 · commons-lang3(常用) - 简书· 2 年前 · |
|
|
爱热闹的海豚 · QCustomPlot基础教程(十三)——Q ...· 3 年前 · |
|
|
从容的火锅 · jQuery通过Ajax向PHP服务端发送请 ...· 3 年前 · |